PyQT5&QT Designe+crnn/PaddleOCR+YOLO+传统OpenCV矫正算法。可视化的车牌识别系统项目。
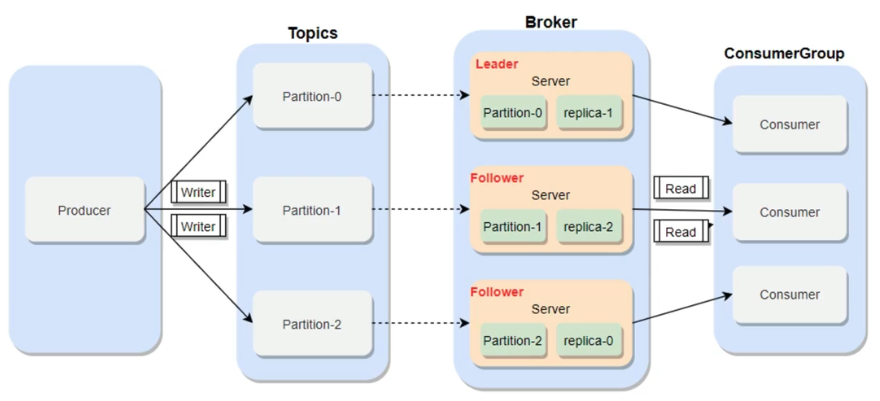
车牌号识别系统
- 项目绪论
- 1.项目展示
- 2.视频展示
- 3.整体思路
- 一、PyQT5 和 QT Designer
- 1.简介
- 2.安装
- 3.使用
- 二、YOLO检测算法
- 三、OpenCV矫正算法
- 四、crnn/PaddleOCR字符识别算法
- 五、QT界面中对得到的检测结果进行展示
- 六、源码获取
- 附录
- 1.安装包国内镜像
项目绪论
1.项目展示
要实现的效果如下图所示

2.视频展示
视频展示链接(展示的另一个瓶盖生产日期检测项目):https://www.bilibili.com/video/BV1K1421673E/
3.整体思路
还是先给出整体思路
1.第一步需要用QT把界面呈现出来
2.第二步用YOLO把车牌位置检测出来
3.第三步,由于第二步检测出来的车牌不一定是正的,所以采用简单的传统OpenCV算法把歪的车牌矫正一下
4.第四步,使用字符识别算法如PaddleOCR或crnn等对矫正后的车牌图像进行字符识别
5.第五步,在QT界面上把识别出的内容展示出来
一、PyQT5 和 QT Designer
1.简介
PyQt5是Python编程语言的一个GUI(图形用户界面)工具包,它允许开发人员使用Python语言创建桌面应用程序。PyQt提供了许多用于创建丰富多样的用户界面的类和功能,以及用于处理用户输入和交互的工具。
而Qt Designer是PyQt程序UI界面的实现工具,使用Qt Designer可以拖拽、点击完成GUI界面设计,并且设计完成的.ui程序可以转换成.py文件供python程序调用。
因此结合PyQT5和QT Designer,可以采用直接拖拽和写代码二者结合的方式,快速实现界面的设计。
2.安装
在PyCharm里面安装PyQt5和QT工具包(如果报错可以切别的镜像源,更多镜像源在附录第一节),其中PyQT5-tools中就包括QT Designer
pip install PyQt5 -i https://pypi.douban.com/simple
pip install PyQt5-tools -i https://pypi.douban.com/simple
3.使用
下载完成之后,在虚拟环境的文件夹下,找到
\Lib\site-packages\qt5_applications\Qt\bin,点击designer.exe,即可直接进入QT Designer设计界面。
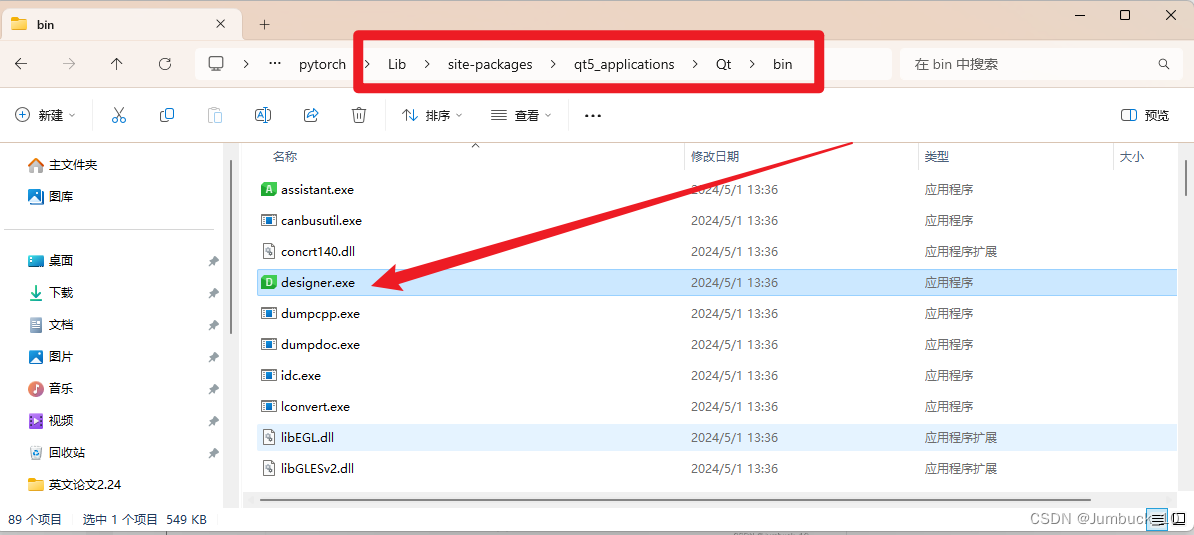
在此界面中,选择默认的Widget,然后直接创建即可
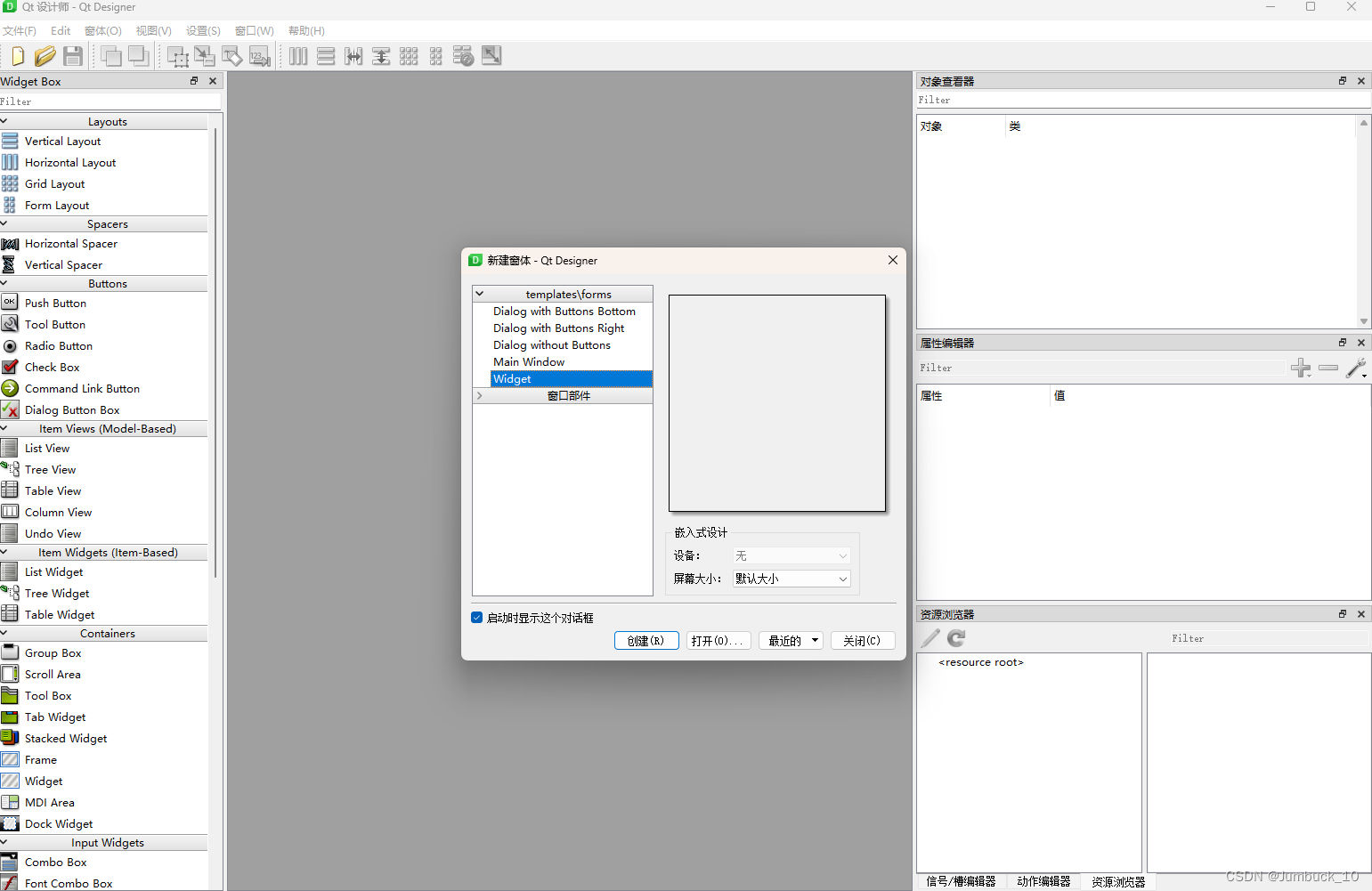
左侧栏可以选择一些插件,其中最常用的插件如下:
QLabel可以显示图像、文本等等(可以放文字)
QPushButton是按钮,用于响应事件
通过上述插件,我们已经通过可视化界面设计出一个简易的可视化界面了。
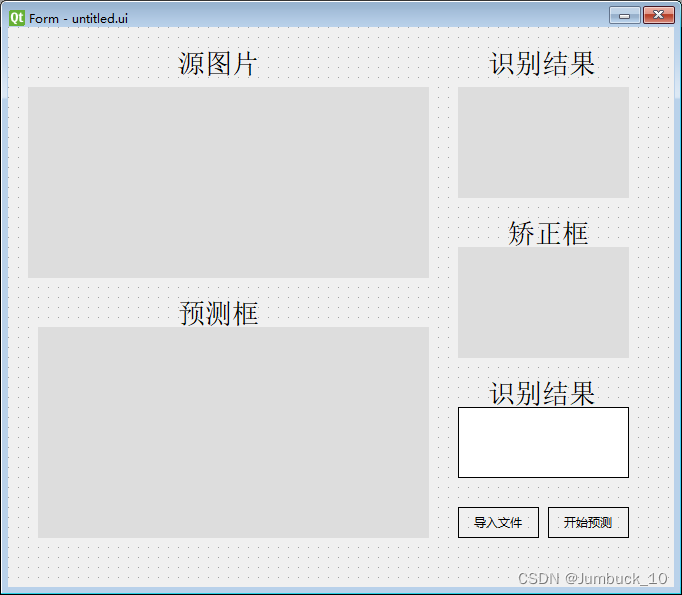
ctrl+s保存直接生成一份.ui为后缀的文件(文件默认名称为untitled.ui),
然后再使用如下指令:
pyuic5 -o untitled.py untitled.ui
将untitled.ui变为可以通过编译器执行的untitled.py。
生成的文件中,基础结构如下:
class Ui_Form(object):
def setupUi(self, Form):
Form.setObjectName("Form")
Form.resize(666, 560)
......
# 定义的几个按钮
self.pushButton = QtWidgets.QPushButton(Form)
self.pushButton.setGeometry(QtCore.QRect(450, 480, 81, 31))
self.pushButton.setStyleSheet("border:1px solid black")
self.pushButton.setObjectName("pushButton")
......
# 对应的按钮响应方法
# 导入文件
self.pushButton.clicked.connect(self.browse_image)
# 开始预测
self.pushButton_2.clicked.connect(self.predict_image)
随后我们在setupUi即定义各种组件的相应方法,如上代码的最后两行。
其中pushButton_2为代码中定义的按钮,predict_image为下方我们自己定义的相应方法。即:现在已经把predict_image和pushButton_2进行链接了,点击pushButton_2对应的按钮,响应predict_image方法
二、YOLO检测算法

使用标注过的数据集对车牌区域进行识别,识别效果如下图所示

YOLO算法本身也属于老生常谈的技术了,因此不在这里过多赘述,有疑问的同学可以翻一下博主之前的博客。
三、OpenCV矫正算法
识别出来的车牌可能非正,如下图所示,这样会给后续的字符识别工作带来困难

因此我们使用OpenCV的矫正算法,对其进行校正

我们这里使用透视矫正:在图像中存在透视变换时,矫正算法可以将图像中的对象转换为在一个平面上的投影,以消除透视效应,从而更容易进行后续的分析和处理。透视矫正通常用于计算机视觉、机器人导航、虚拟现实等领域。
矫正的具体代码如下所示
import cv2
import numpy as np
# 读取图像
imgPath = "D:\PythonCode\pyQT\warpMethods\data\\2.png"
image = cv2.imread(imgPath)
cv2.imshow('dilated Box', image)
cv2.waitKey(0)
# 将图像转换为灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv2.imshow('dilated Box', gray)
cv2.waitKey(0)
# 二值化处理
_, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU)
# 膨胀操作,用于连接相邻的文字
kernel = np.ones((5,5), np.uint8)
dilated = cv2.dilate(binary, kernel, iterations=3)
cv2.imshow('dilated Box', dilated)
cv2.waitKey(0)
# 腐蚀操作,用于消除细小的噪声
eroded = cv2.erode(dilated, kernel, iterations=3)
cv2.imshow('eroded Box', eroded)
cv2.waitKey(0)
# 查找轮廓
contours, hierarchy = cv2.findContours(eroded, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 获取所有文本区域的最小外接矩形
boxes = []
for contour in contours:
rect = cv2.minAreaRect(contour)
box = cv2.boxPoints(rect)
box = np.int0(box)
boxes.append(box)
# 将所有文本区域的矩形框合并为一个大矩形框
merged_box = cv2.minAreaRect(np.concatenate(boxes))
# 提取矩形框的角点
rect_points = cv2.boxPoints(merged_box)
# 将角点转换为整数类型
rect_points = np.int0(rect_points)
print(rect_points)
# 在图像上绘制合并后的矩形框
cv2.drawContours(image, [rect_points], 0, (0, 255, 0), 2)
# 显示结果
cv2.imshow('Merged Box', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 提取矩形框的角点并转换为浮点数类型的 NumPy 数组
src_pts = cv2.boxPoints(merged_box)
src_pts = np.float32(src_pts)
# 定义目标点
dst_pts = np.float32([[0, merged_box[1][1]-1],
[0, 0],
[merged_box[1][0]-1, 0],
[merged_box[1][0]-1, merged_box[1][1]-1]])
# 获取透视变换矩阵
M = cv2.getPerspectiveTransform(src_pts, dst_pts)
# 执行透视变换,校正文本区域
corrected_image = cv2.warpPerspective(image, M, (int(merged_box[1][0]), int(merged_box[1][1])))
# 检查纵向长度是否比横向长度长,如果是则翻转图像
if corrected_image.shape[0] > corrected_image.shape[1]:
corrected_image = cv2.rotate(corrected_image, cv2.ROTATE_90_CLOCKWISE)
# 显示结果
cv2.imshow('Corrected Image', corrected_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
四、crnn/PaddleOCR字符识别算法
文本识别是图像领域的一个常见任务,场景文字识别OCR任务中,需要先检测出图像中文字位置,再对检测出的文字进行识别,文节介绍的CRNN模型可用于后者, 对检测出的文字进行识别。

crnn存在不足的地方是它只能预测一行数据,因此多行数据不能进行预测,我们这里的车牌仅一行,但是如果有同学是识别多行的任务,则需要写个脚本对图像的进行分离,具体代码如下所示:
# 将图像分成上下两段
height = img.shape[0]
half_height = height // 2
upper_img = img[:half_height, :]
lower_img = img[half_height:, :]
# 对上半部分进行预测
upper_img = Image.fromarray(upper_img)
upper_image = upper_img.convert('L')
upper_image = transformer(upper_image)
if torch.cuda.is_available():
upper_image = upper_image.cuda()
upper_image = upper_image.view(1, *upper_image.size())
upper_image = Variable(upper_image)
model.eval()
upper_preds = model(upper_image)
_, upper_preds = upper_preds.max(2)
upper_preds = upper_preds.transpose(1, 0).contiguous().view(-1)
upper_preds_size = Variable(torch.IntTensor([upper_preds.size(0)]))
upper_raw_pred = converter.decode(upper_preds.data, upper_preds_size.data, raw=True)
upper_sim_pred = converter.decode(upper_preds.data, upper_preds_size.data, raw=False)
print('Upper prediction: %-20s => %-20s' % (upper_raw_pred, upper_sim_pred))
# 对下半部分进行预测
lower_img = Image.fromarray(lower_img)
lower_image = lower_img.convert('L')
lower_image = transformer(lower_image)
if torch.cuda.is_available():
lower_image = lower_image.cuda()
lower_image = lower_image.view(1, *lower_image.size())
lower_image = Variable(lower_image)
lower_preds = model(lower_image)
_, lower_preds = lower_preds.max(2)
lower_preds = lower_preds.transpose(1, 0).contiguous().view(-1)
lower_preds_size = Variable(torch.IntTensor([lower_preds.size(0)]))
lower_raw_pred = converter.decode(lower_preds.data, lower_preds_size.data, raw=True)
lower_sim_pred = converter.decode(lower_preds.data, lower_preds_size.data, raw=False)
print('Lower prediction: %-20s => %-20s' % (lower_raw_pred, lower_sim_pred))
words = upper_sim_pred + "\n" + lower_sim_pred
如果只是为了方便我们也可以使用paddleocr提供的远端服务方式进行访问。这样精度更高且不用配置环境,博主试了一下精度特别高,基本能满足简易条件下的数据。
访问方法如下所示:
import base64
import json
import urllib
import requests
def main():
url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic?access_token
# image 可以通过 get_file_content_as_base64("C:\fakepath\1.bmp",True) 方法获取
payload = '&detect_language=false¶graph=false&probability=false'
headers = {
'Content-Type': 'application/x-www-form-urlencoded',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
result_str = response.text
# 解析 JSON 字符串
data = json.loads(result_str)
# 提取出 words 后的两个字符串
if "words_result" in data:
words_result = data["words_result"]
if len(words_result) >= 2:
word1 = words_result[0]["words"]
word2 = words_result[1]["words"]
print("提取结果:", word1, word2)
else:
print("Error: 'words_result' 中的元素数量不足 2")
else:
print("Error: 没有找到 'words_result' 键")
result_str = word1+'\n' + word2
print(result_str)
def get_file_content_as_base64(path, urlencoded=False):
"""
获取文件base64编码
:param path: 文件路径
:param urlencoded: 是否对结果进行urlencoded
:return: base64编码信息
"""
with open(path, "rb") as f:
content = base64.b64encode(f.read()).decode("utf8")
if urlencoded:
content = urllib.parse.quote_plus(content)
return content
if __name__ == '__main__':
main()
其中token需要替换成自己的(需要的同学多的话可以专门出一期PaddleOCR部署的博文)
五、QT界面中对得到的检测结果进行展示
具体逻辑为:
- 点击图片预测后,把图像路径传给predict_image( self.file_path定义为公共,因此可以直接访问)
- 使用YOLOv5Detect 中的predict方法,使用该文件路径,对其进行一系列的预测(具体方法如上文所示),即,先用yolo检测、再用opencv进行校正、最后使用paddleocr进行字符识别
- 拿到返回的数据,使用setPixmap显示到QT界面上。
from YOLOv5Detect import predict
def predict_image(self):
try:
if self.file_path:
# 这里执行图像预测的逻辑,例如调用预测模型
print("预测图片路径:", self.file_path)
# 在这里使用 self.file_path 进行图像预测
predImg,cropped_image,warpImg,words = predict(self.file_path) # 假设 predict 函数返回处理后的图像数组
if predImg is not None and isinstance(predImg, np.ndarray):
pixmap = self.convert_array_to_pixmap(predImg)
self.output_img.setPixmap(pixmap.scaled(self.output_img.size(), Qt.KeepAspectRatio))
if cropped_image is not None and isinstance(cropped_image, np.ndarray):
pixmap = self.convert_array_to_pixmap(cropped_image)
self.yucekuang_img.setPixmap(pixmap.scaled(self.yucekuang_img.size(), Qt.KeepAspectRatio))
if warpImg is not None and isinstance(warpImg, np.ndarray):
pixmap = self.convert_array_to_pixmap(warpImg)
self.jiaozhenghou_img.setPixmap(pixmap.scaled(self.yucekuang_img.size(), Qt.KeepAspectRatio))
if words:
self.shibiejieguo_kuang.setText(words)
else:
print("预测函数返回无效的图像数组")
else:
print("请先选择图片")
except Exception as e:
print("预测图像时发生异常:", str(e))
六、源码获取
为了方便大家文档及论文撰写,博主更新了一篇五千字的技术细节文档,有需要可以联系.
<1831255794---q>制备数据集和写算法耗费了大量时间精力,因此收取点小费希望理解!!!
可接项目,大作业,毕设等
价格略贵,技术够硬,认真负责,保证质量

附录
1.安装包国内镜像
清华大学镜像源:
https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云镜像源:
http://mirrors.aliyun.com/pypi/simple/
中国科技大学镜像源:
https://pypi.mirrors.ustc.edu.cn/simple/
华中科技大学镜像源:
http://pypi.hustunique.com/simple/
上海交通大学镜像源:
https://mirror.sjtu.edu.cn/pypi/web/simple/
豆瓣镜像源:
http://pypi.douban.com/simple/
山东理工大学镜像源:
http://pypi.sdutlinux.org/
百度镜像源:
https://mirror.baidu.com/pypi/simple
使用方法:
pip install <安装包> -i <镜像源>