文章目录
- Java对象内置结构
- 1.Java对象的三个部分
- 1.1.对象头
- 1.2.对象体
- 1.3.对齐字节
- 2.对象结构中核心字段的作用
- 2.1.MarkWord(标记字)
- 2.2.Class Pointer(类对象指针)
- 2.3.Array Length(数组长度)
- 2.4.对象体
- 2.5.对齐字节
- 3.Mark Word的结构信息
- 3.1.不同锁状态下的Mark Word字段结构
- 3.2.Mark Word的构成
- 4.使用JOL工具查看对象的布局
- 4.1.引入依赖
- 4.2.编写对象布局分析的测试代码
- 4.3.输出结果解读
- 4.4.大小端问题
- 5.Java中的内置锁
- 5.1.无锁状态
- 5.2.偏向锁状态
- 5.3.轻量级锁状态
- 5.4.重量级锁状态
Java对象内置结构
Java对象很多重要信息都存放在对象结构中,在学习Java内置锁之前,先来了解一下Java对象结构
1.Java对象的三个部分
1.1.对象头
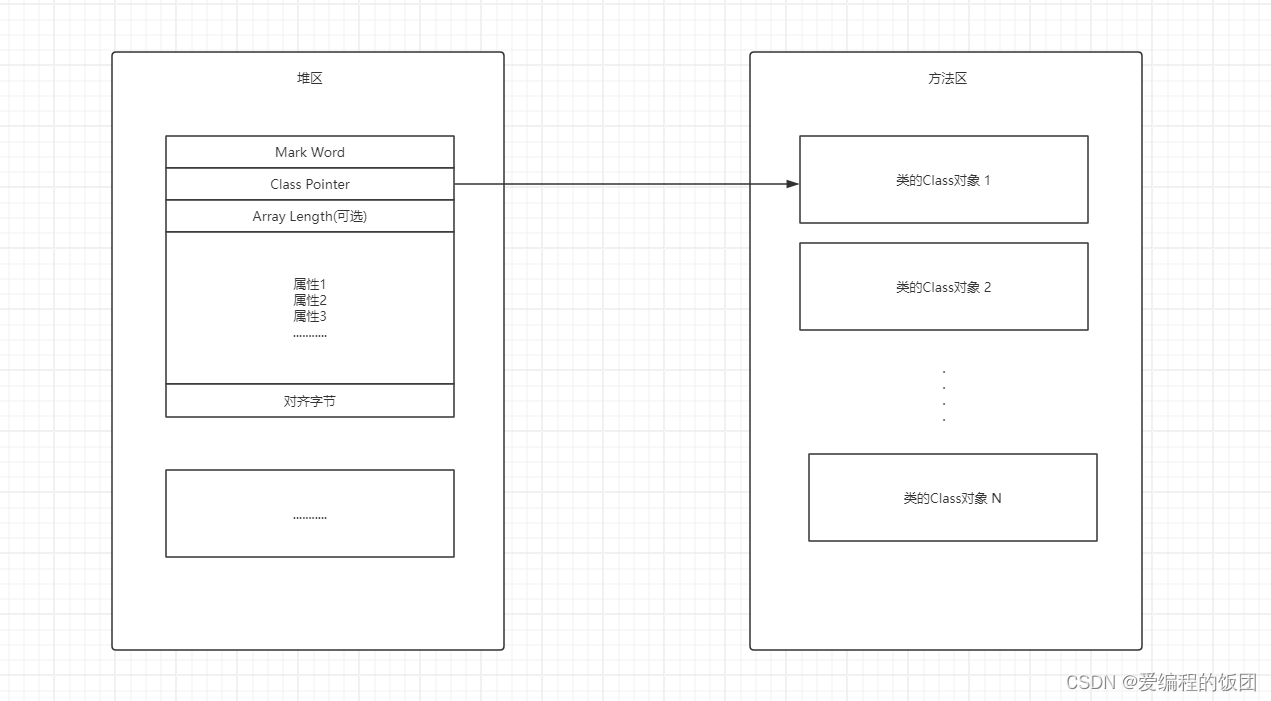
对象头一共包括三个字段【Mark Word】【Class Pointer】【 Array Length】
- MarkWord(标记字),用于存储自身运行时的一些数据,例如GC标志位,哈希码,锁状态等信息。
- Class Pointer(类对象指针),用于存放此对象的元数据(InstanceKlass)的地址,虚拟机可以通过此指针确当这个对象是那个类的实例
- Array Length(数组长度),如果对象是一个Java数组,那么此字段必须有,用于记录数组长度的数据,如果不是数组,那么此字段不存在
1.2.对象体
对象体包含了,对象的实例变量(成员变量),用于成员属性值,包括父类的成员属性值,这部分内存按照4字节对齐
1.3.对齐字节
对齐字节(Alignment Byte)是为了优化内存访问效率而在Java中自动添加的额外字节。它确保对象和数组字段的对齐,提高内存访问的效率和性能。开发人员无需手动处理对齐字节,由Java虚拟机自动处理。
其中,对齐字节也称为填充对齐,作用就是用来保证Java对象在所占用内存字节数为8的倍数(8N Bytes),HotSopt VM内存管理要求,对象的起始地址必须是8字节的整数倍
2.对象结构中核心字段的作用
下面我们来对Object实例结构中的几个重要字段作一些简单说明
2.1.MarkWord(标记字)
在Java对象头部的一部分内存空间用于存储对象的元数据和状态信息,被称为MarkWord。MarkWord包含了对象的哈希码、锁信息、GC标记等信息。它的具体结构和内容在不同的JVM实现中可能会有所差异。
2.2.Class Pointer(类对象指针)
在Java对象头部的另一部分内存空间用于存储指向该对象所属类的指针,被称为Class Pointer。这个指针指向对象的类的元数据,包括类的方法、字段等信息。通过Class Pointer,可以在运行时获取对象所属的类,并进行相应的操作。
2.3.Array Length(数组长度)
对于数组对象,Java对象头部的一部分内存空间用于存储数组的长度信息。这个长度信息在创建数组时被初始化,之后无法被修改。
2.4.对象体
象体是Java对象的实际数据部分,包含了对象的字段值。对象体的大小取决于对象中定义的字段及其类型。对象体紧跟在对象头部之后,占据连续的内存空间。
2.5.对齐字节
在Java对象的内存布局中,为了对齐数据而添加的额外字节被称为对齐字节。对齐字节的存在是为了提高内存访问的效率和性能。它确保对象和数组字段的对齐,使得数据能够被高效地加载到寄存器或缓存中。
3.Mark Word的结构信息
Java内置锁涉及了很多的重要信息,这些都存放在对象结构中,放放于对象头的MarkWord字段中,MarkWord长度为JVM的一个Word大小,也就说32位JVM MakrWord 为32位 ,64位的Mark Word为64位,MarkWord的位长度并不会受到OOP对象指针压缩的影响。
Java内置锁的状态一共分为4种,【无锁】->【偏向锁】->【轻量级锁】->【重量级锁】,四种锁的状态会随着竞争的情况逐渐升级,而且过程是不可逆的(不可降级),锁只会升级,不会降级。
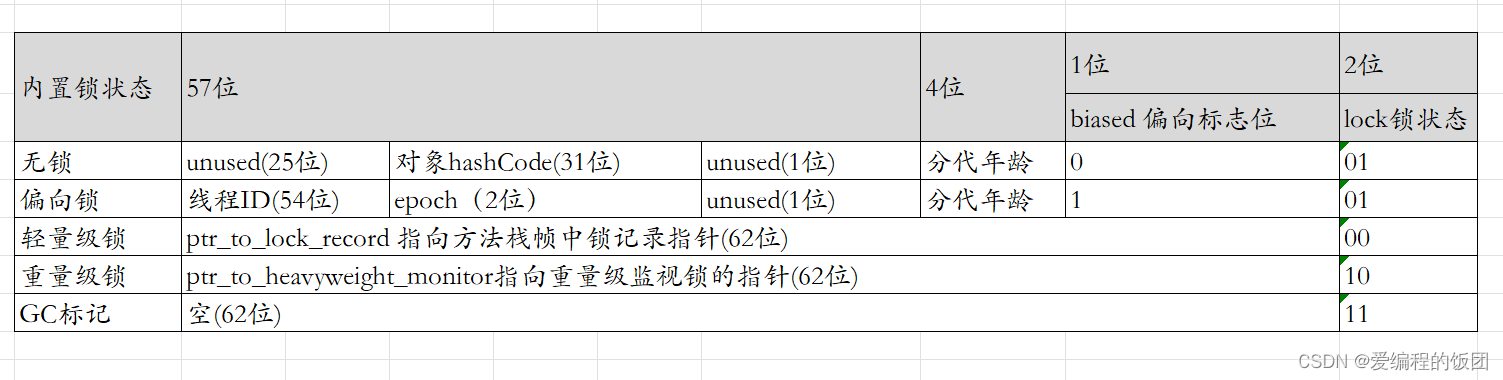
3.1.不同锁状态下的Mark Word字段结构
Mark Word 字段的结构和Java内置锁的结构 强相关,为了让Mark Word字段存储更多的信息,JVM将Mark Word的最低两个位置设置为Java内置锁状态
下面通过图来了解一下Mark Word 结构
3.2.Mark Word的构成
目前主流的JVM都是64位,使用64位的Mark Word 下面对64位的Mark Word的各部分进行简单介绍下
- **lock(锁状态):**lock字段用于表示对象的锁状态。它包含了对象的锁信息,可以标识对象是否被锁定,以及锁的类型(如无锁、偏向锁、轻量级锁、重量级锁等)。锁状态的具体取值和意义在不同的JVM实现中可能会有所差异。
- biased_lock(偏向锁标记):biased_lock字段用于表示对象是否启用了偏向锁。偏向锁是一种针对无竞争的情况下优化的锁机制,用于提高单线程访问同步块的性能。当对象启用偏向锁时,biased_lock字段的值为1,表示该对象已经偏向于某个线程,不需要进行锁的竞争。
- **age(对象年龄):**age字段用于表示对象的年龄。在垃圾回收的过程中,JVM会根据对象的年龄来决定是否将对象晋升为老年代。对象的年龄通过age字段进行记录,当对象经过一次Minor GC(年轻代垃圾回收)而没有被回收时,其年龄会增加。
- **identity_hashcode(标识哈希码):**identity_hashcode字段用于存储对象的标识哈希码。标识哈希码是对象的一个唯一标识,与对象的内容无关。它在需要比较对象的引用是否相等时起到重要的作用。
- **thread(持有锁的线程):**thread字段用于记录当前持有锁的线程。在多线程环境下,当一个线程获得对象的锁时,该字段会记录该线程的引用,以便在锁的释放或竞争时进行相应的操作。
- **epoch(锁记录的版本号):**epoch字段用于记录锁记录的版本号。它在偏向锁撤销和轻量级锁升级为重量级锁时起到重要作用。当锁状态发生变化时,会更新epoch字段的值,以确保锁记录的有效性。
- **ptr_to_lock_record(指向锁记录的指针):**ptr_to_lock_record字段用于指向对象的锁记录。锁记录是在竞争过程中创建的数据结构,用于记录锁的状态和竞争情况等信息。
- **ptr_to_heavyweight_monitor(指向重量级监视器的指针):**ptr_to_heavyweight_monitor字段用于指向重量级监视器的指针。当对象的锁升级为重量级锁时,会创建一个重量级监视器来管理锁的竞争。
这些字段在MarkWord中扮演着重要的角色,用于管理对象的锁状态、偏向锁、年龄、哈希码等信息。它们的具体含义和使用方式在不同的JVM实现中可能会有所不同,但它们都对对象的同步和垃圾回收起到了重要的作用。
4.使用JOL工具查看对象的布局
如何在Java程序中查看Object对象头的结构呢?我们可以使用OpenJDK提供的JOL工具
JOL是分析JVM中对象的结构布局的工具,该用具大量使用了Unsafe ,JVMTI来解码内部布局情况,分析结果还是比较准确的。
4.1.引入依赖
<!-- https://mvnrepository.com/artifact/org.openjdk.jol/jol-core -->
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.10</version>
</dependency>
4.2.编写对象布局分析的测试代码
public class JOLTest {
private static final Logger log = LoggerFactory.getLogger(JOLTest.class);
@Test
@DisplayName("测试JOL的使用")
public void testJOL() {
// 创建一个示例对象
Student student = new Student();
student.name = "喜羊羊";
// 打印JVM信息
log.error("JVM详细信息: {}", VM.current().details());
// 打印对象布局信息
log.error("对象布局:");
log.error(ClassLayout.parseInstance(student).toPrintable());
}
}
class Student{
public String name;
}
运行结果
4.3.输出结果解读
常见的Java数据类型及其在内存中所占用的字节数
| 数据类型 | 字节数 | 范围 | 备注 |
|---|---|---|---|
| boolean | 1 | true 或 false | 布尔类型只占用一个字节,但实际取值范围为 true 或 false。 |
| byte | 1 | -128 到 127 | 有符号的8位整数类型。 |
| short | 2 | -32,768 到 32,767 | 有符号的16位整数类型。 |
| char | 2 | 0 到 65,535 | 无符号的16位Unicode字符类型。 |
| int | 4 | -2,147,483,648 到 2,147,483,647 | 有符号的32位整数类型。 |
| float | 4 | IEEE 754 单精度浮点数(有效位数约为 6-7 位) | 单精度浮点数类型,用于表示小数。 |
| long | 8 | -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 | 有符号的64位整数类型。 |
| double | 8 | IEEE 754 双精度浮点数(有效位数约为 15 位) | 双精度浮点数类型,用于表示小数。 |
| reference | 4 / 8 | 对象引用,取决于操作系统位数(32位操作系统为 4 字节,64位操作系统为 8 字节) | 表示对Java对象的引用,指向对象在堆中的内存地址。 |
| 对象头部(Object Header) | 12 | 对象的元数据和状态信息 | 对象头部包含标记字段、哈希码、锁信息等,具体结构和大小可能会因Java虚拟机实现的不同而有所差异。 |
需要注意的是,数据类型的字节数可能会因特定的编译器、操作系统和硬件架构而有所不同。引用类型的大小取决于操作系统的位数,32位操作系统上为4字节,64位操作系统上为8字节。对象头部(Object Header)的大小也可能因不同的Java虚拟机实现而有所不同。
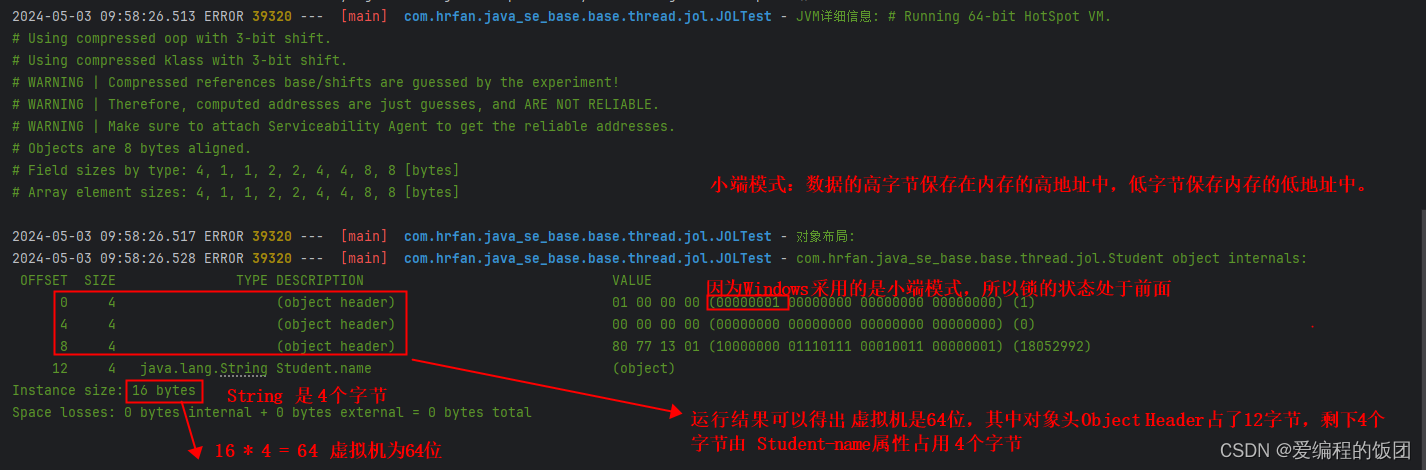
通过结果我们可以得到
- 对象头部(object header)占据了前12个字节(0-11字节)的空间:
- 第一个字段(偏移量0):值为
01 00 00 00,十六进制形式对应的二进制为00000001 00000000 00000000 00000000。这是对象的标记字段,表示对象的状态和锁信息。 - 第二个字段(偏移量4):值为
00 00 00 00,十六进制形式对应的二进制为00000000 00000000 00000000 00000000。这个字段也是对象头部的一部分,具体含义可能是保留字段或其他元数据。 - 第三个字段(偏移量8):值为
80 77 13 01,十六进制形式对应的二进制为10000000 01110111 00010011 00000001。这个字段是对象头部的一部分,可能是用来存储对象的哈希码或其他标识信息。
- 第一个字段(偏移量0):值为
com.hrfan.java_se_base.base.thread.jol.Student对象的实例大小为16字节。com.hrfan.java_se_base.base.thread.jol.Student对象的字段中,只有一个字段是java.lang.String类型的,即Student对象的name字段。该字段位于偏移量为12的位置,占据了4个字节的空间。- 对象的空间损失为0字节,既没有内部损失也没有外部损失。
4.4.大小端问题
有关字节序列存放格式,目前有两大主流阵营,一个阵营是PowerPC系列的CPU,采用大端模式进行存放数据,第二大阵营是X86系列的CPU采用小端模式存放数据
大小端(Endianness)是指在多字节数据类型存储时,字节的存放顺序。在计算机中,多字节数据类型(如整数、浮点数等)通常由多个字节组成,而字节本身是按照一定的顺序进行存储的。具体来说,大小端指的是最低有效字节(即最右边的字节)和最高有效字节(即最左边的字节)的存放顺序。
在大端字节序(Big Endian)中,最高有效字节存储在最低的地址,而最低有效字节存储在最高的地址。这意味着在多字节数据类型中,字节的存放顺序与它们的值相对应。例如,对于16位整数值0x1234,它的最高有效字节是0x12,最低有效字节是0x34,在大端字节序中,它们将按照如下顺序存储:0x12(高地址)和0x34(低地址)。
在小端字节序(Little Endian)中,最低有效字节存储在最低的地址,而最高有效字节存储在最高的地址。这意味着在多字节数据类型中,字节的存放顺序与它们的值相反。以同样的例子,对于16位整数值0x1234,在小端字节序中,它们将按照如下顺序存储:0x34(低地址)和0x12(高地址)。
| 内存地址 | 大端字节序 | 大端字节序(二进制) | 小端字节序 | 小端字节序(二进制) |
|---|---|---|---|---|
| 0x1000 | 0x12 | 0001 0010 | 0x34 | 0011 0100 |
| 0x1001 | 0x34 | 0011 0100 | 0x12 | 0001 0010 |
在大端字节序中,高位字节(0x12)存储在低地址(0x1000),低位字节(0x34)存储在高地址(0x1001)。二进制表示为0001 0010(高位字节)和0011 0100(低位字节)。
在小端字节序中,低位字节(0x34)存储在低地址(0x1000),高位字节(0x12)存储在高地址(0x1001)。二进制表示为0011 0100(低位字节)和0001 0010(高位字节)。
5.Java中的内置锁
在JDK1.6之前,所有的锁都是重量级锁,重量级锁会造成CPU在用户态和核心态之间频繁切换,所以代价高效率地下。所以在JDK1.6以后,引入【偏向锁】,【轻量级锁】的实现。
当涉及到多线程并发访问共享资源时,Java中的锁状态会根据不同的情况进行动态调整。
5.1.无锁状态
无锁状态表示对象没有被任何线程锁定,多个线程可以同时访问该对象而不会发生互斥或同步等操作。这种情况通常在没有竞争的情况下发生。例如,以下代码片段展示了一个无锁状态的示例:
int counter = 0;
// 线程1
counter++;
// 线程2
counter++;
在这个示例中,两个线程可以同时对counter变量进行递增操作,因为没有竞争发生。
5.2.偏向锁状态
偏向锁状态是一种针对无竞争情况下的优化。当一个线程获取了一个对象的锁,并且在之后连续多次访问该对象时,JVM会将该对象升级为偏向锁状态。偏向锁的目的是为了提高无竞争情况下的性能。以下是一个偏向锁状态的示例:
class Counter {
private int count = 0;
}
public class Test m {
public static void main(String[] args) {
Counter counter = new Counter();
// 线程1获取锁并连续多次访问
synchronized (counter) {
counter.count++;
counter.count++;
// ...
}
// 线程2再次获取锁并访问
synchronized (counter) {
counter.count++;
// ...
}
}
}
在这个示例中,线程1获取了counter对象的锁,并连续多次访问了count字段。由于没有其他线程竞争该锁,counter对象会被升级为偏向锁状态,线程2再次获取锁时会直接进入偏向锁状态,从而避免了同步操作。
5.3.轻量级锁状态
轻量级锁状态适用于多个线程竞争同一个对象的锁的情况。在轻量级锁状态下,锁的获取和释放使用CAS操作来实现,避免了传统的互斥量机制,从而提高了性能。以下是一个轻量级锁状态的示例:
class Counter {
private int count = 0;
}
public class Test {
public static void main(String[] args) {
Counter counter = new Counter();
// 线程1获取锁
synchronized (counter) {
// ...
}
// 线程2尝试获取锁
synchronized (counter) {
// ...
}
}
}
在这个示例中,线程1获取了counter对象的锁,此时counter对象处于轻量级锁状态。当线程2尝试获取锁时,它会使用CAS操作进行自旋尝试获取锁,如果竞争不激烈,线程2可以快速获取到锁,避免了进入重量级锁状态。
5.4.重量级锁状态
重量级锁状态适用于竞争激烈的情况,它使用操作系统的互斥量机制来进行锁的获取和释放。重量级锁确保了线程的互斥访问,但在竞争激烈的情况下可能导致线程的频繁切换和性能下降。以下是一个重量级锁状态的示例:
class Counter {
private int count = 0;
}
public class Test {
public static void main(String[] args) {
Counter counter = new Counter();
while(true){
// 线程1获取锁
synchronized (counter) {
// ...
}
// 线程2获取锁
synchronized (counter) {
// ...
}
// 特定条件下退出循环
// .......
}
}
}
在这个示例中,线程1和线程2同时竞争获取counter对象的锁。由于竞争激烈,JVM会将counter对象升级为重量级锁状态,这时锁的获取和释放会涉及到操作系统的互斥量机制。
注意,具体的锁状态转换和升级过程由JVM自动管理,开发者在编写代码时无需显式处理锁状态的转换。锁状态的调整是根据实际的并发情况自动进行的。
后面我们会专门对偏向锁,轻量级锁,重量级锁进行分析



![[UDS][OTA] 自定义 IntelHEX (IHEX) format read/write library in C](https://img-blog.csdnimg.cn/direct/d5db2a16c7b24cd2838761ea8a4740a8.png)