二叉树
1 二叉树部分的一些新知
(1)二叉树的定义,C++方法一定要知道,相对于链表而言,二叉树就是多了两个指针,即左右子节点
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};
(2)第二个是二叉搜索树和平衡二叉搜索树,这里预计五一放假回来后补坑(已经有栈和队列在STL的底层、优先队列、大小顶堆、KMP算法的笔记总结要补了,一定补上!)
2 二叉树的遍历
(1)递归遍历:
前序、中序、后序。(这里就是根节点遍历的位置区别)
每次写递归,都按照这三要素来写,可以保证大家写出正确的递归算法!
确定递归函数的参数和返回值: 确定哪些参数是递归的过程中需要处理的,那么就在递归函数里加上这个参数,并且还要明确每次递归的返回值是什么进而确定递归函数的返回类型。
确定终止条件: 写完了递归算法,
运行的时候,经常会遇到栈溢出的错误,就是没写终止条件或者终止条件写的不对,操作系统也是用一个栈的结构来保存每一层递归的信息,如果递归没有终止,操作系统的内存栈必然就会溢出。确定单层递归的逻辑: 确定每一层递归需要处理的信息。在这里也就会重复调用自己来实现递归的过程。
void pre_traversal(TreeNode* cur, vector<int>& vec){
if(cur == NULL) return;
vec.push_back(cur->val);
traversal(cur->left,vec);
traversal(cur->right,vec);
}
void mid_traversal(TreeNode* cur, vector<int>& vec){
if(cur == NULL) return;
traversal(cur->left,vec);
vec.push_back(cur->val);
traversal(cur->right,vec);
}
void behind_traversal(TreeNode* cur, vector<int>& vec){
if(cur == NULL) return;
traversal(cur->left,vec);
traversal(cur->right,vec);
vec.push_back(cur->val);
}
以上就是递归遍历了,但是这不是最难的。
(2)二叉树的迭代遍历
迭代法的前序遍历:
递归的本质就是每一次递归调用都会将函数的局部变量、参数值和返回地址等压入调用栈中,然后递归返回的时候,从栈顶弹出上一次递归的各项参数。
那么前序遍历首先需要处理的是中间节点,那么先将根节点压入栈中,然后弹出根节点,再压入这个根节点的右子,再加入左子。最后按照顺序进行弹出。
但是要注意如果是空节点不应该压入栈中,需要跳过这个节点。
vector<int> preorderTraversal(TreeNode *root){
stack<TreeNode*> st;
vector<int> result;
if(root == NULL) return result;
st.push(root);
while(!st.empty()){
TreeNode* node = st.top();
st.pop();
result.push_back(node->val);
if(node->right) st.push(node->right);
if(node->left) st.push(node->left);
}
return result;
}
迭代法的中序遍历
中序遍历是左中右的顺序,因此需要从树的顶点开始一层一层向下遍历,直到访问到左树的最底部,然后再处理节点。因此处理顺序和访问顺序并不相同。
vector<int> inorderTraversal(TreeNode *root){
vector<int> result;
stack<TreeNode*> st;
TreeNode* cur = root;
while(cur != NULL || !st.empty()){ //条件变化的原因是现在遍历和存储要分开,因此cur用于进行遍历
if(cur != NULL){
st.push(cur); //从顶部开始,一路向最左遍历过去
cur = cur->left; //左节点
}
else {
cur = st.top(); //如果已经到了最左了,那么会进入这个分支,此时开始存储,即弹出左节点
st.pop();
//到了这个分支,我们可以发现也就是遍历到的这个cur节点一定没有左子节点,因此要存入result
result.push_back(cur->val);//此时应该把这个节点当作中间节点来看待,那么这个节点被弹出之后,要看一下有没有右子节点。
cur = cur->right;
//那么此时的顺序就是左中右
}
}
return result;
}
迭代法的后序遍历
后序遍历实际上是前序遍历的反面顺序,所以只需要先进行前序遍历,然后再反转数组。
vector<int> postorderTraversal(TreeNode* root) {
stack<TreeNode*> st;
vector<int> result;
if (root == NULL) return result;
st.push(root);
while (!st.empty()) {
TreeNode* node = st.top();
st.pop();
result.push_back(node->val);
if (node->left) st.push(node->left); // 相对于前序遍历,这更改一下入栈顺序 (空节点不入栈)
if (node->right) st.push(node->right); // 空节点不入栈
}
reverse(result.begin(), result.end()); // 将结果反转之后就是左右中的顺序了
return result;
}
3 二叉树的层序遍历
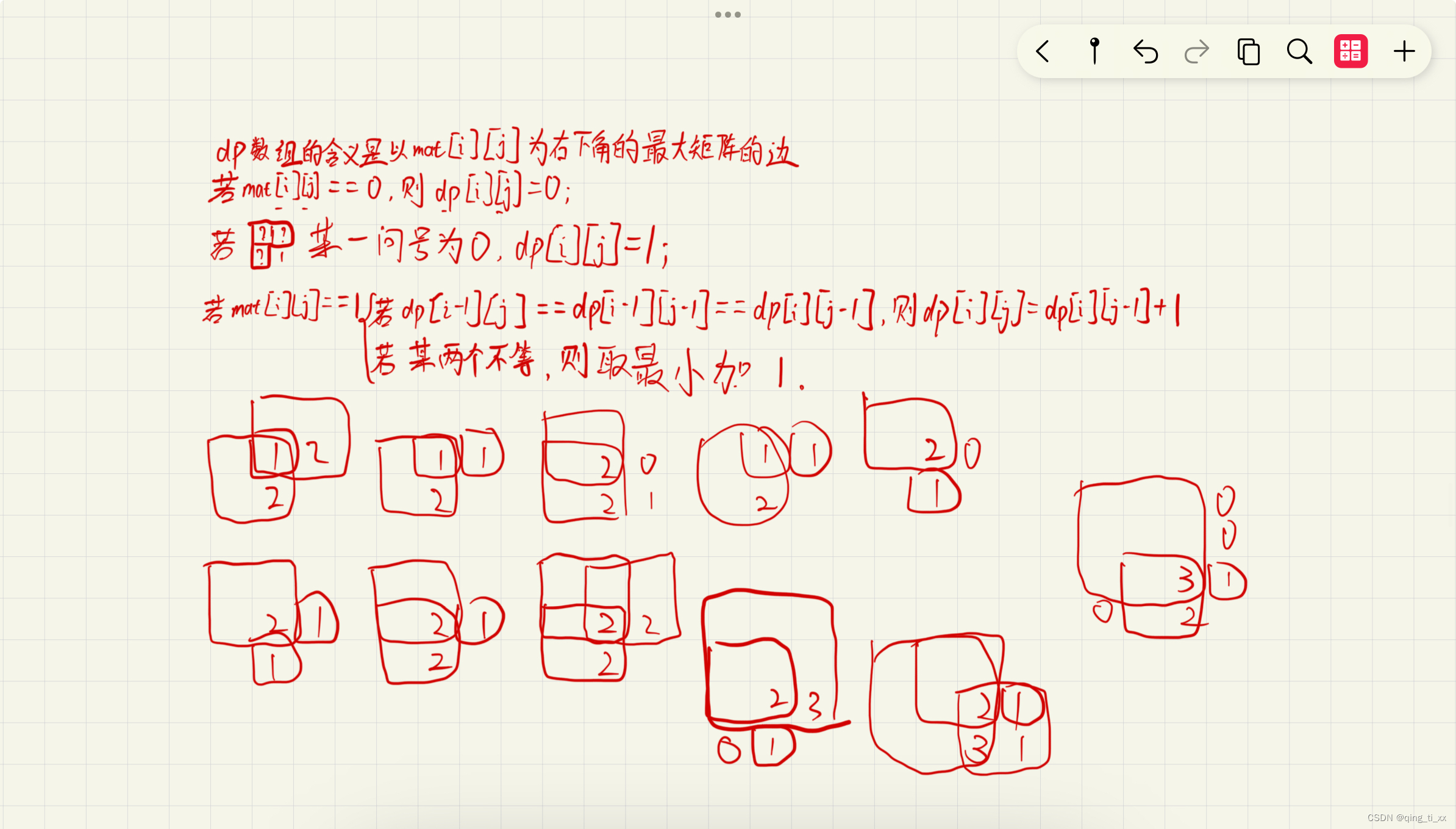
3.1 二叉树的最大深度
可以使用递归法对此题进行求解,其实二叉树的深度可以选择左子树的深度与右子树的深度的最大值+1。因此可以使用递归法,求解每一个根节点对应的深度,再递归回去。
- 二叉树节点的深度:指从根节点到该节点的最长简单路径边的条数或者节点数(取决于深度从0开始还是从1开始)
- 二叉树节点的高度:指从该节点到叶子节点的最长简单路径边的条数或者节点数(取决于高度从0开始还是从1开始)
使用后序遍历来计算树的高度。参数需要传入这个树的根节点,返回这个根的高度。分别求取左右子树的深度,最后取左右深度最大的数值再+1。
class Solution {
public:
int getdepth(TreeNode* node) {
if (node == NULL) return 0;
int leftdepth = getdepth(node->left); // 左
int rightdepth = getdepth(node->right); // 右
int depth = 1 + max(leftdepth, rightdepth); // 中
return depth;
}
int maxDepth(TreeNode* root) {
return getdepth(root);
}
};
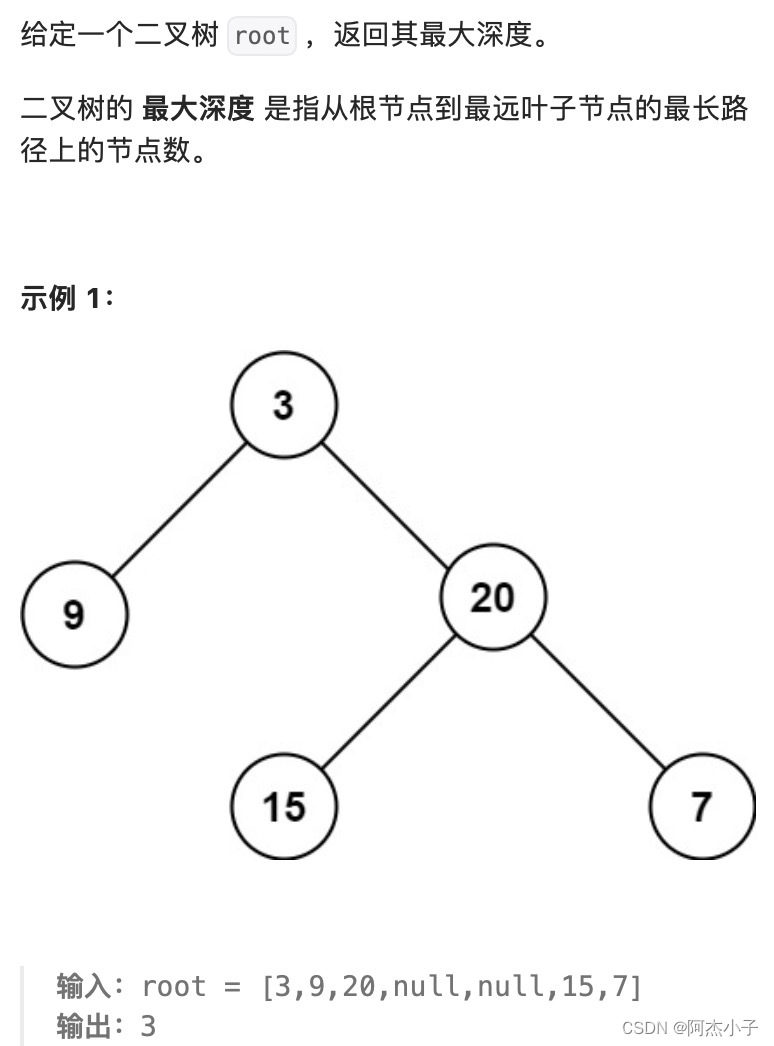
3.2 二叉树的层序遍历
层序遍历一个二叉树。就是从左到右一层一层的去遍历二叉树。这种遍历的方式和我们之前讲过的都不太一样。
需要借用一个辅助数据结构即队列来实现,队列先进先出,符合一层一层遍历的逻辑,而用栈先进后出适合模拟深度优先遍历也就是递归的逻辑。
而这种层序遍历方式就是图论中的广度优先遍历,只不过我们应用在二叉树上。
遍历节点时,当这个节点要出去的时候,就应该查询其左右子,并放入队列。
vector<vector<int>> levelOrder(TreeNode* root) {
queue<TreeNode*> que;
if (root != NULL) que.push(root);
vector<vector<int>> result;
while (!que.empty()) {
int size = que.size();
vector<int> vec;
// 这里一定要使用固定大小size,不要使用que.size(),因为que.size是不断变化的
for (int i = 0; i < size; i++) {
TreeNode* node = que.front();
que.pop();
vec.push_back(node->val);
if (node->left) que.push(node->left);
if (node->right) que.push(node->right);
}
result.push_back(vec);
}
return result;
}
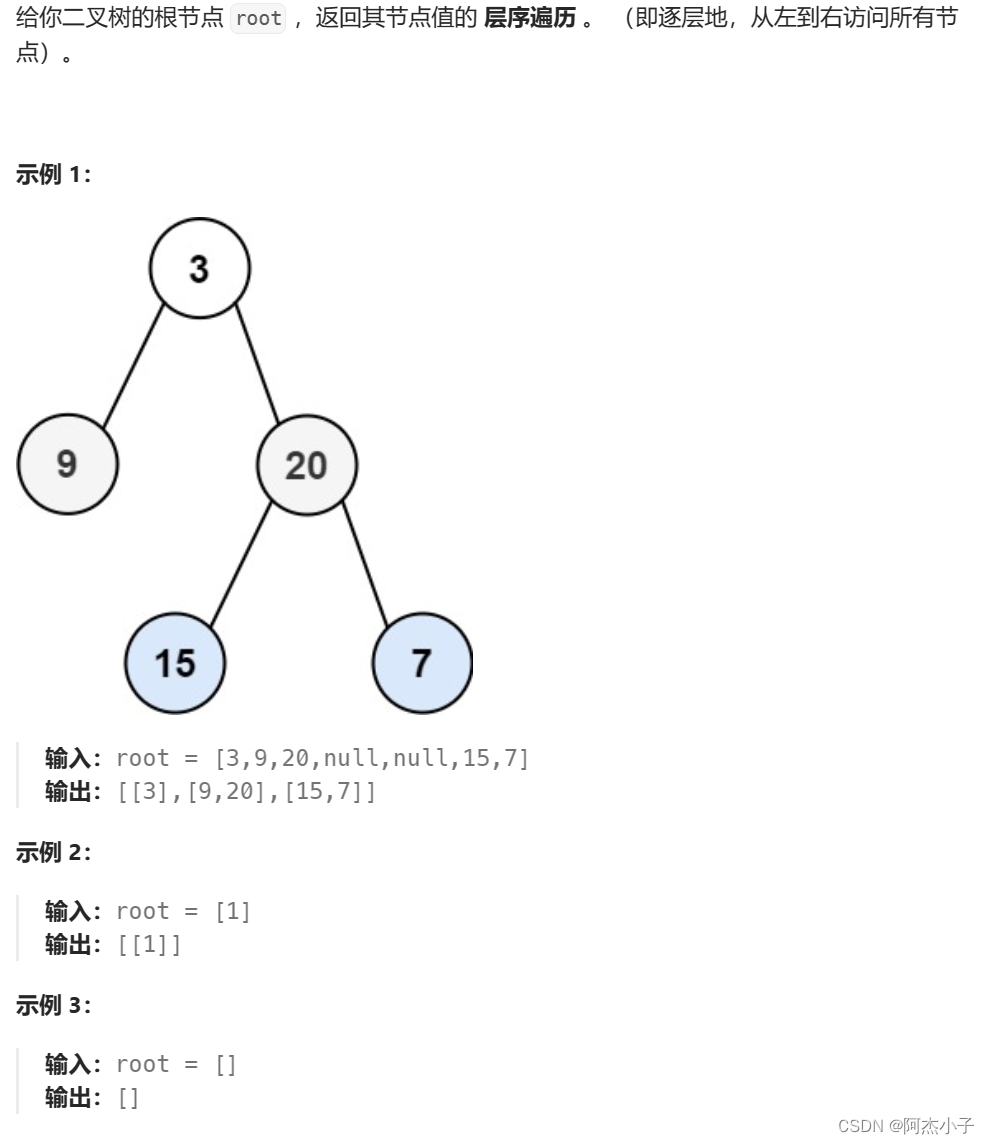
3.4 翻转二叉树
换个思路来看,就是将二叉树的层序遍历顺序颠倒,即先右后左,然后继续按队列的方式进行遍历
递归方法
- 确定递归函数的参数和返回值
参数就是要传入节点的指针,不需要其他参数了,通常此时定下来主要参数,如果在写递归的逻辑中发现还需要其他参数的时候,随时补充。
返回值的话其实也不需要,但是题目中给出的要返回root节点的指针,可以直接使用题目定义好的函数,所以就函数的返回类型为TreeNode*。
TreeNode* invertTree(TreeNode* root)
- 确定终止条件
当前节点为空的时候,就返回if (root == NULL) return root; - 确定单层递归的逻辑
因为是先前序遍历,所以先进行交换左右孩子节点,然后反转左子树,反转右子树。
swap(root->left, root->right);
invertTree(root->left);
invertTree(root->right);
因此可以得到最后的代码:
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
if (root == NULL) return root;
swap(root->left, root->right); // 中
invertTree(root->left); // 左
invertTree(root->right); // 右
return root;
}
};
迭代方法
可以利用前序遍历,对代码结构进行调整:
TreeNode* invertTree(TreeNode* root){
stack<TreeNode*> st;
if(root != NULL) st.push(root);
while(!st.empty()){
TreeNode* node = st.top();
if(node != NULL){
st.pop();
// 可以这么去理解,前序遍历中我们是从左到右进行遍历,那么我们需要由根节点获得左右子树,然后对左子树和右子树进行翻转即可。
// 体现在代码当中就是push右子和左子之后将根放回去,然后在根前面夹一个NULL使得条件转移到交换代码当中,完成左右结点的交换。
if(node->right) st.push(node->right);
if(node->left) st.push(node->left);
st.push(node);
st.push(NULL);
}
else{
st.pop();
node = st.top();
st.pop();
swap(node->left,node->right);
}
}
return root;
}
广度优先遍历
TreeNode* invertTree(TreeNode* root) {
queue<TreeNode*> que;
if (root != NULL) que.push(root);
while (!que.empty()) {
int size = que.size();
for (int i = 0; i < size; i++) {
TreeNode* node = que.front();
que.pop();
swap(node->left, node->right); // 节点处理
if (node->left) que.push(node->left);
if (node->right) que.push(node->right);
}
}
return root;
}
3.5 对称二叉树
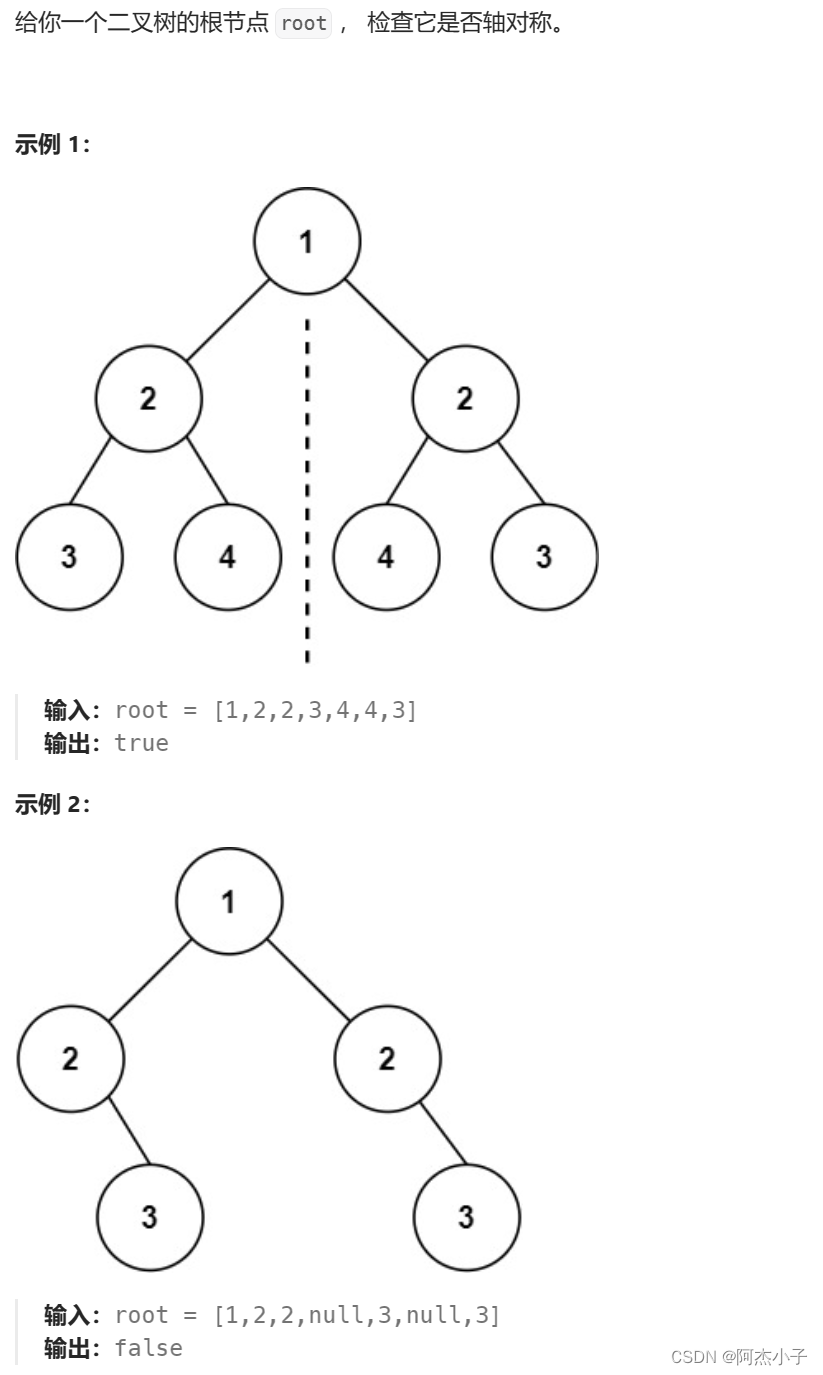
对于二叉树是否对称,要比较的是根节点的左子树与右子树是不是相互翻转的,理解这一点就知道了其实我们要比较的是两个树(这两个树是根节点的左右子树),所以在递归遍历的过程中,也是要同时遍历两棵树。
因此我们只需要对左子和右子进行比较即可,采用后序遍历。正是因为要遍历两棵树而且要比较内侧和外侧节点,所以准确的来说是一个树的遍历顺序是左右中,一个树的遍历顺序是右左中。
递归三部曲(参考代码随想录)
- 确定递归函数的参数和返回值
- 因为我们要比较的是根节点的两个子树是否是相互翻转的,进而判断这个树是不是对称树,所以要比较的是两个树,参数自然也是左子树节点和右子树节点。
- 返回值自然是bool类型。代码如下:
bool compare(TreeNode* left, TreeNode* right)
- 确定终止条件
- 要比较两个节点数值相不相同,首先要把两个节点为空的情况弄清楚!否则后面比较数值的时候就会操作空指针了。
- 节点为空的情况有:(注意我们比较的其实不是左孩子和右孩子,所以如下我称之为左节点右节点)
- 左节点为空,右节点不为空,不对称,return false
- 左不为空,右为空,不对称 return false
- 左右都为空,对称,返回true
- 此时已经排除掉了节点为空的情况,那么剩下的就是左右节点不为空:
- 左右都不为空,比较节点数值,不相同就return false
- 此时左右节点不为空,且数值也不相同的情况我们也处理了。
代码如下:
if (left == NULL && right != NULL) return false;
else if (left != NULL && right == NULL) return false;
else if (left == NULL && right == NULL) return true;
else if (left->val != right->val) return false; // 注意这里我没有使用else
注意上面最后一种情况,我没有使用else,而是else if, 因为我们把以上情况都排除之后,剩下的就是 左右节点都不为空,且数值相同的情况。
- 确定单层递归的逻辑
此时才进入单层递归的逻辑,单层递归的逻辑就是处理 左右节点都不为空,且数值相同的情况。- 比较二叉树外侧是否对称:传入的是左节点的左孩子,右节点的右孩子。
- 比较内侧是否对称,传入左节点的右孩子,右节点的左孩子。
- 如果左右都对称就返回true ,有一侧不对称就返回false 。
代码如下:
bool outside = compare(left->left, right->right); // 左子树:左、 右子树:右
bool inside = compare(left->right, right->left); // 左子树:右、 右子树:左
bool isSame = outside && inside; // 左子树:中、 右子树:中(逻辑处理)
return isSame;
最终代码
bool compare(TreeNode* left, TreeNode* right) {
// 首先排除空节点的情况
if (left == NULL && right != NULL) return false;
else if (left != NULL && right == NULL) return false;
else if (left == NULL && right == NULL) return true;
// 排除了空节点,再排除数值不相同的情况
else if (left->val != right->val) return false;
// 此时就是:左右节点都不为空,且数值相同的情况
// 此时才做递归,做下一层的判断
bool outside = compare(left->left, right->right); // 左子树:左、 右子树:右
bool inside = compare(left->right, right->left); // 左子树:右、 右子树:左
bool isSame = outside && inside; // 左子树:中、 右子树:中 (逻辑处理)
return isSame;
}
bool isSymmetric(TreeNode* root) {
if (root == NULL) return true;
return compare(root->left, root->right);
}