Unsloth 高效微调大模型的工具,通过Unsloth微调Llama3, Mistral, Gemma 速度提升2-5倍,内存减少70%!
Codelab 创建一个jupyter notebook
选择 T4 GPU
安装Fine tune 相关的lib
%%capture
import torch
major_version, minor_version= torch.cuda.get_device_capability()
# Must install separately since Colab has torch 2.2.1, which breaks packages
!pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
if major_version >= 8:
# Use this for new GPs like Ampere, Hopper GPUs(RTX 30xx. RIX 40xx, A100. H100. L40)
!pip install -no-deps packaging ninja einops flash-attn xformers trl peft accelerate bitsandbytes
else:
# Use this for older GPUs (V100, Tesla T4, RTX 20xx)
!pip install --no-deps xformers trl peft accelerate bitsandbytes
pass
下载llama3
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be False
# 4bit pre quantized models we support for 4x faster downloading + no OOMs
fourbit_models = [
"unsloth/mistral-7b-bnb-4bit",
"unsloth/mistral-7b-instruct-bnb-4bit",
"unsloth/llama-2-7b-bnb-4bit",
"unsloth/gemma-7b-bnb-4bit",
"unsloth/gemma-7b-it-bnb-4bit",
"unsloth/gemma-2b-bnb-4bit",
"unsloth/gemma-2b-it-bnb-4bit",
"unsloth/llama-3-8b-bnb-4bit",
] # More models at https://huggingface.co/unsloth
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/llama-3-8b-bnb-4bit",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)
model = FastLanguageModel.get_peft_model(
model,
r = 16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 3407,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None # And LoftQ
)
加载hugging face数据集
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}
"""
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, input, output in zip(instructions, inputs, outputs):
# Must add EOS_TOKEN, otherwise your generation will go on forever!
text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN
texts.append(text)
return { "text": texts, }
pass
from datasets import load_dataset
dataset = load_dataset("pinzhenchen/alpaca-cleaned-zh", split="train")
dataset = dataset.map(formatting_prompts_func, batched=True,)
HuggingFace 官网, 点击数据集 Datasets
搜索数据集 alpaca-cleaned-zh
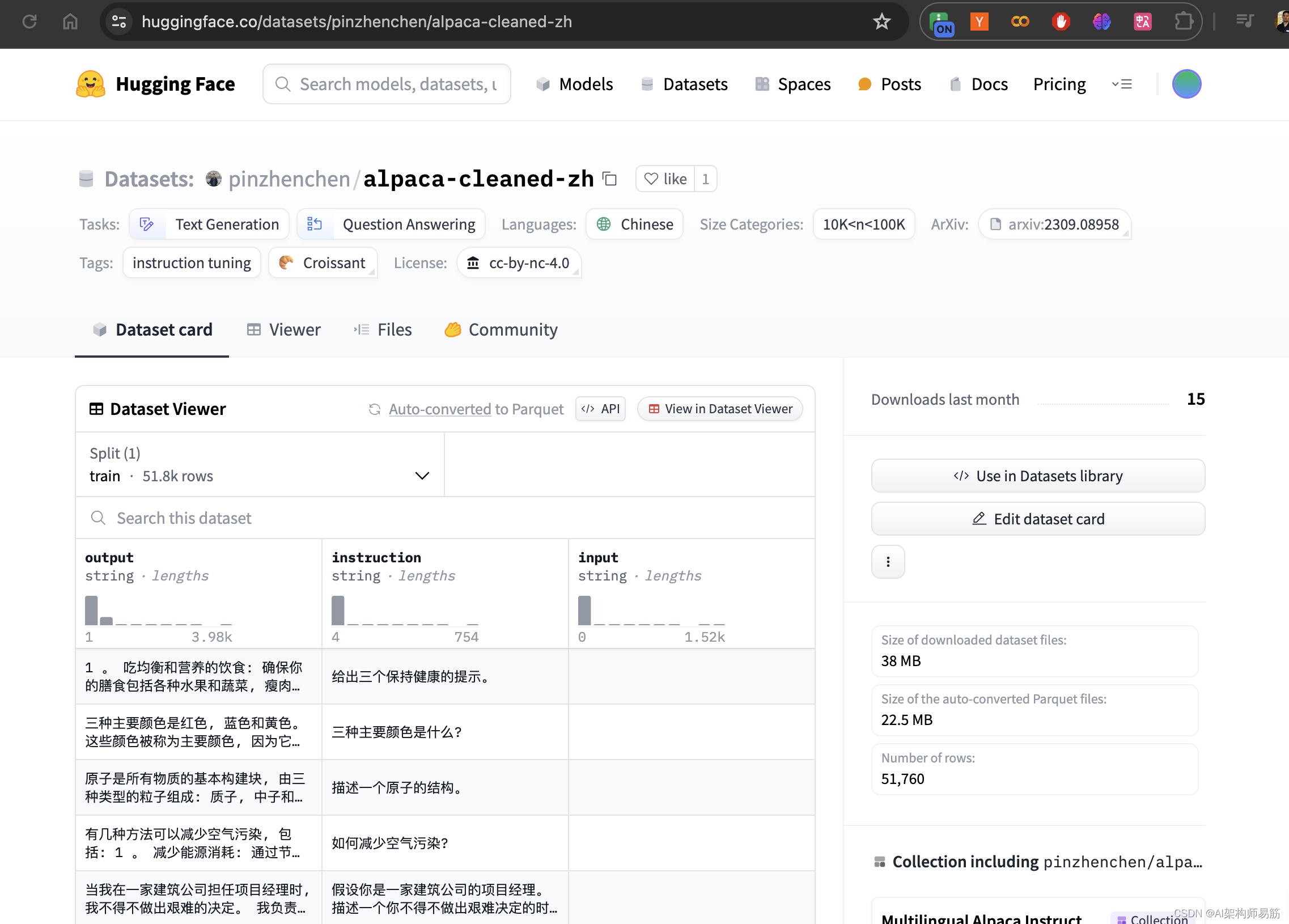
复制数据集的名字 pinzhenchen/alpaca-cleaned-zh
定义training 方法
from trl import SFTTrainer
from transformers import TrainingArguments
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False, # Can make training 5x faster for short sequences.
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 60,
learning_rate = 2e-4,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
),
)
打印显存使用情况
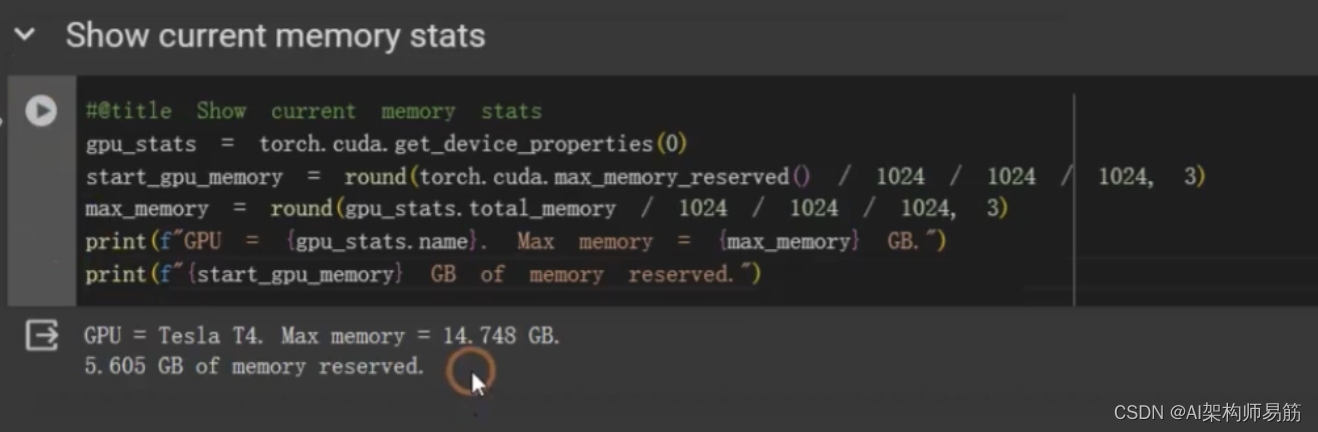
#@title Show current memory stats
gpu_stats = torch.cuda.get_device_properties(0)
start_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)
print(f"GPU = (gpu_stats.name). Max memory = (max_memory) GB.")
print(f"(start_gpu_memory) GB of memory reserved.")
开始FineTune
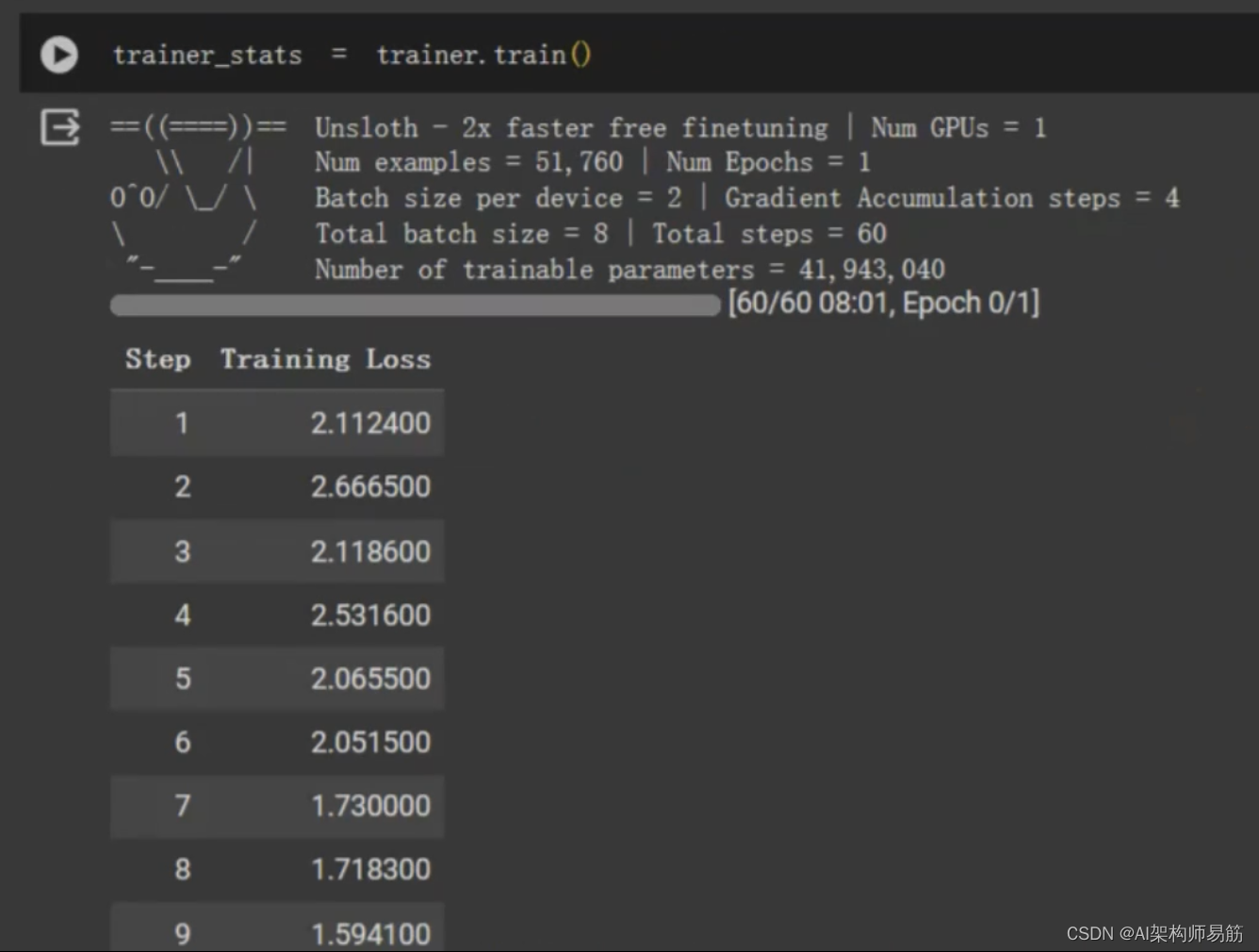
trainer_stats = trainer.train()
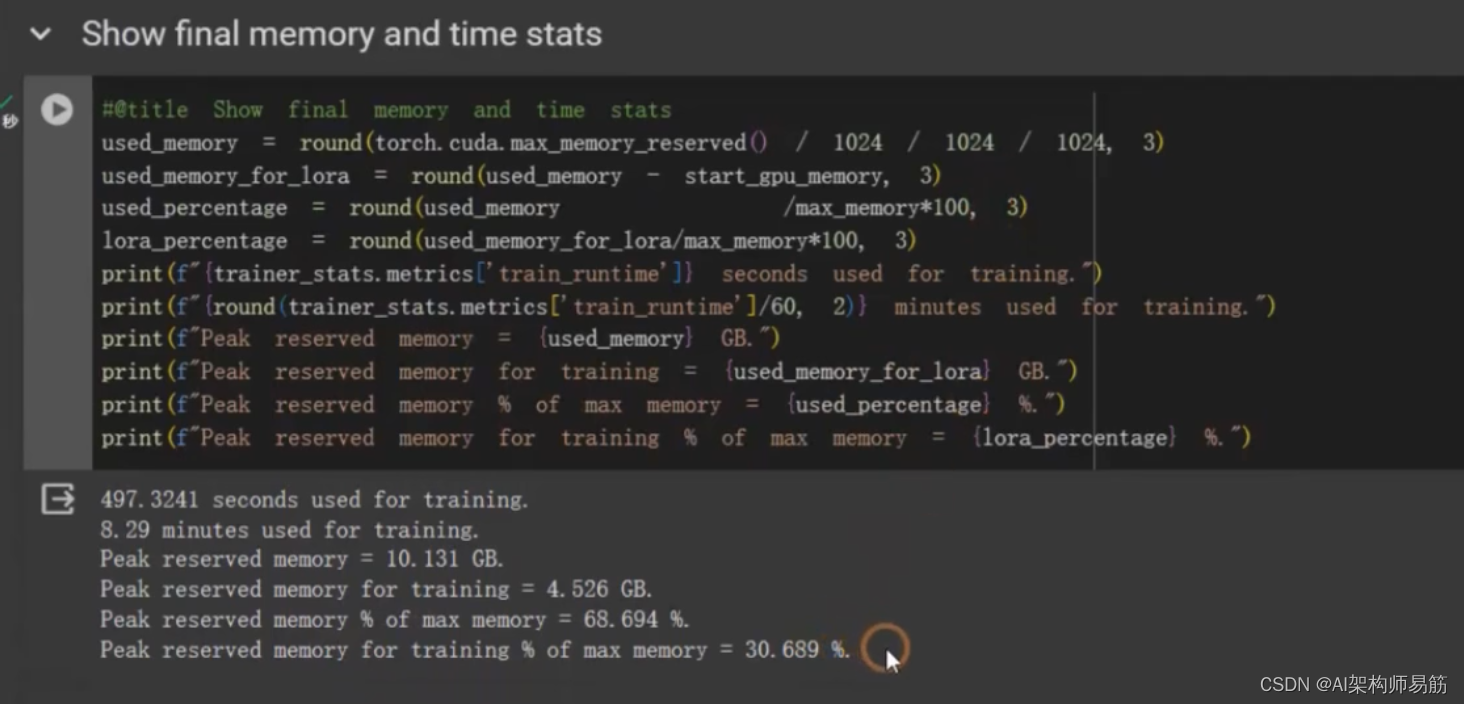
#@title Show final memory and time stats
used_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
used_memory_for_lora = round(used_memory - start_gpu_memory, 3)
used_percentage = round(used_memory / max_memory*100, 3)
lora_percentage = round(used_memory_for_lora / max_memory*100, 3)
print(f"{trainer_stats.metrics['train_runtime']} seconds used for training.")
print(f"{round(trainer_stats.metrics['train_runtime']/60, 2)} minutes used for training.")
print(f"Peak reserved memory = {used_memory} GB.")
print(f"Peak reserved memory for training = {used_memory_for_lora} GB.")
print(f"Peak reserved memory % of max memory = {used_percentage} %.")
print(f"Peak reserved memory for training % of max memory = {lora_percentage} GB.")
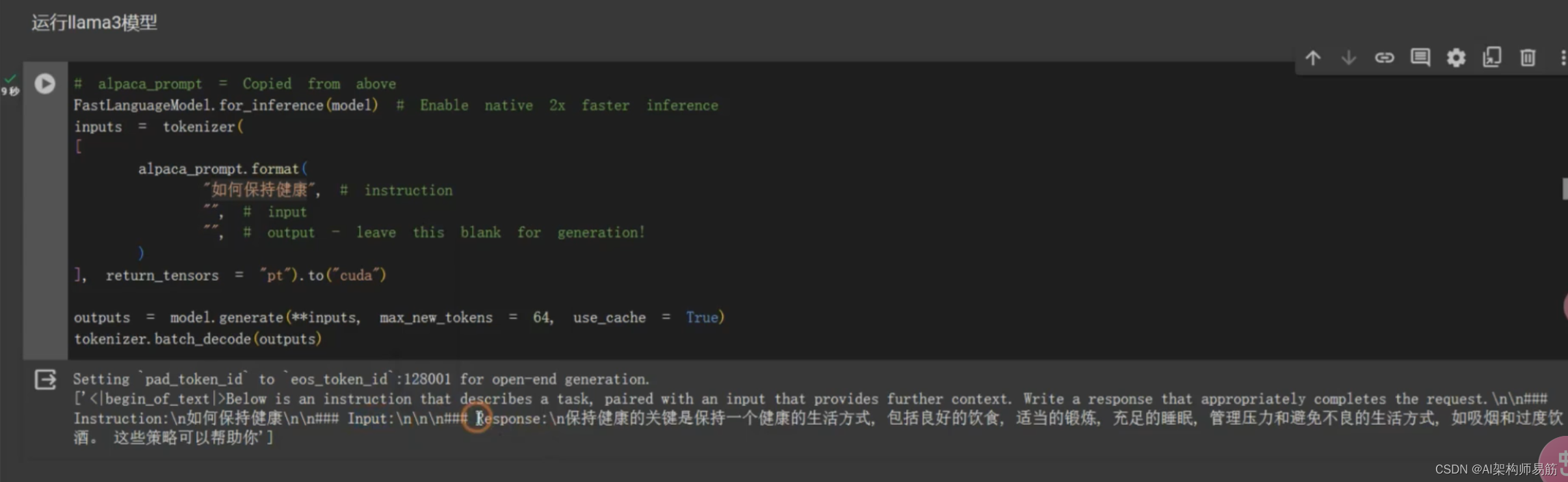
用fineTune 过的model,做问答
# alpaca_prompt = Copied from above
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
inputs = tokenizer(
[
alpaca_prompt.format(
"如何保持健康", # instruction
"", # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt"
).to("cuda")
outputs = model.generate(**inputs, max_new_tokens = 64, use_cache=True)
tokenizer.batch_decode(outputs)
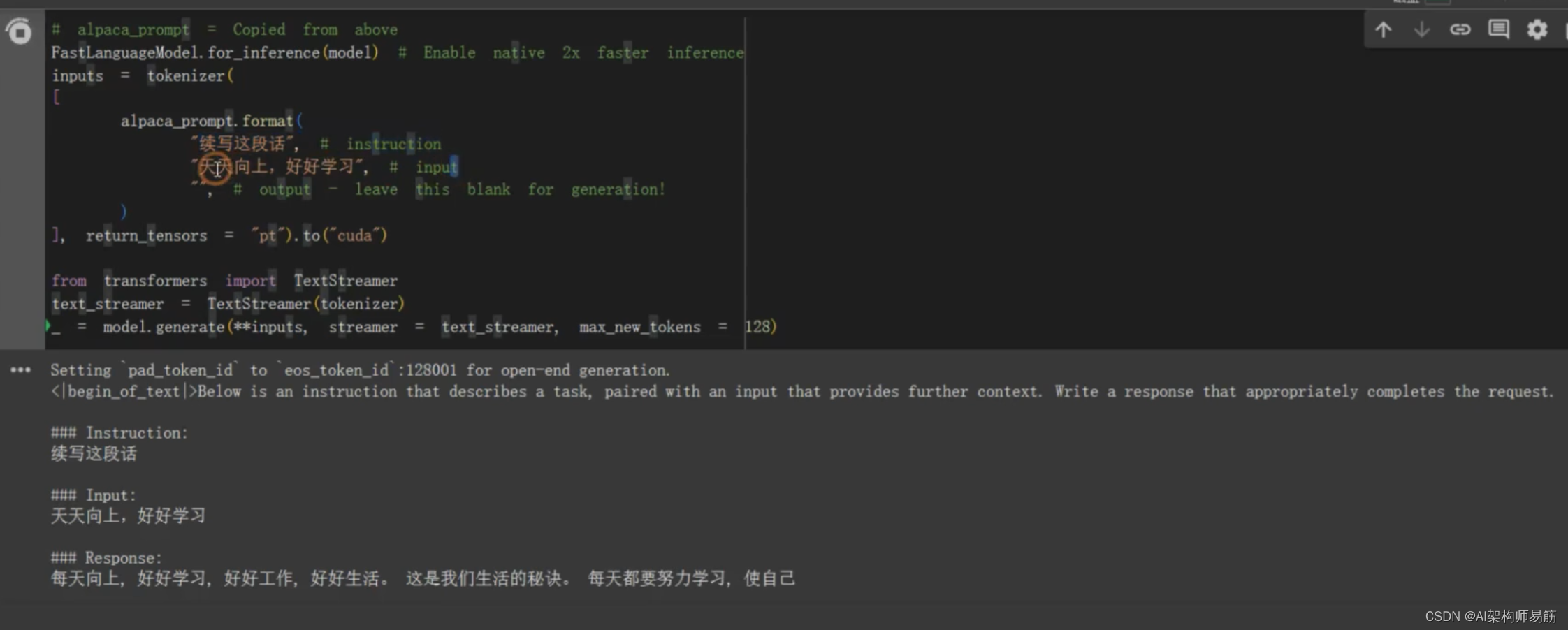
TextStreamer 流式一个字一个字地打印结果
# alpaca_prompt = Copied from above
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
inputs = tokenizer(
[
alpaca_prompt.format(
"续写这段话", # instruction
"天天向上,好好学习", # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt"
).to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens=128)
保存model到google drive 和 HuggingFace
model.save_pretrained("lora_model") # local saving
model.push_to_hub("zgpeace/lora_model", token="####") # online saving
google drive





![[Linux][网络][TCP][三][超时重传][快速重传][SACK][D-SACK][滑动窗口]详细讲解](https://img-blog.csdnimg.cn/direct/a03ba758341e430c9475772028fd3e59.png)