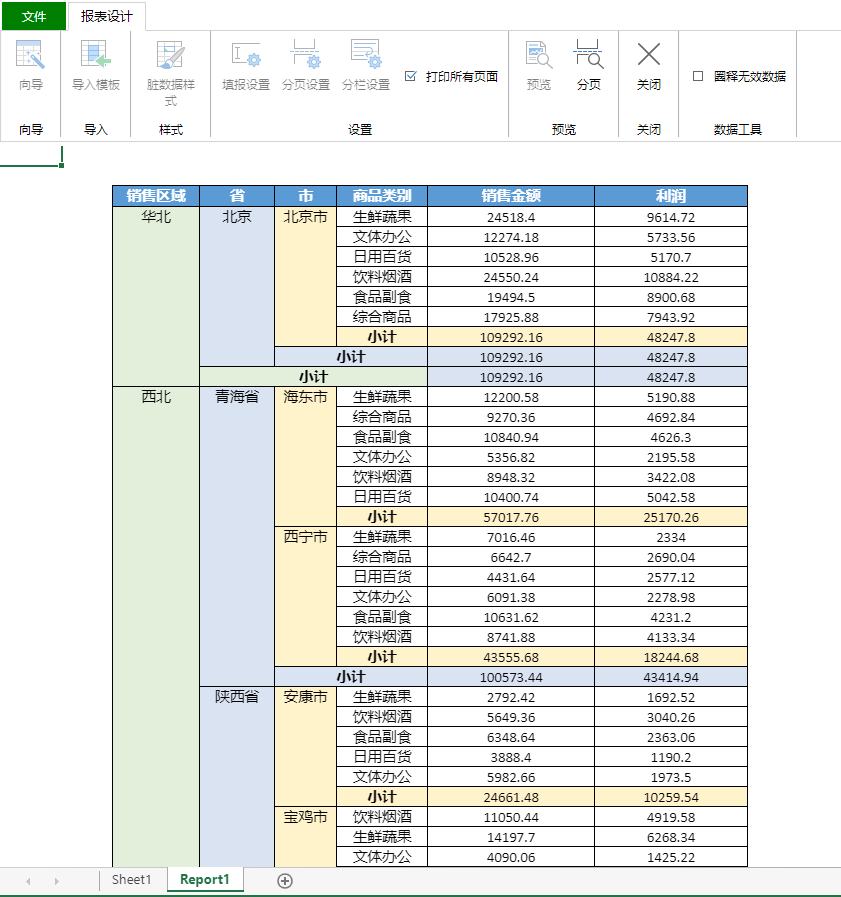
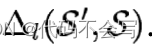符号优先级
概率公式中一共有三种符号:分号 ; 、逗号 , 、竖线 | 。
; 分号代表前后是两类东西,以概率P(x;θ)为例,分号前面是x样本,分号后边是模型参数。分号前的 表示的是这个式子用来预测分布的随机变量x,分号后的 表示所需的相关参数θ。
, 逗号代表两个事件同时发生的概率,逗号连接两个事件,有时可以省略,如联合概率P(AB),等价于P(A,B)
| 竖线代表 if,以条件概率P(A|B)为例,A,B是随机试验E的两个随机试验,P(A|B)就是如果B事件发生的条件下,发生A事件的概率,结合图进行理解:
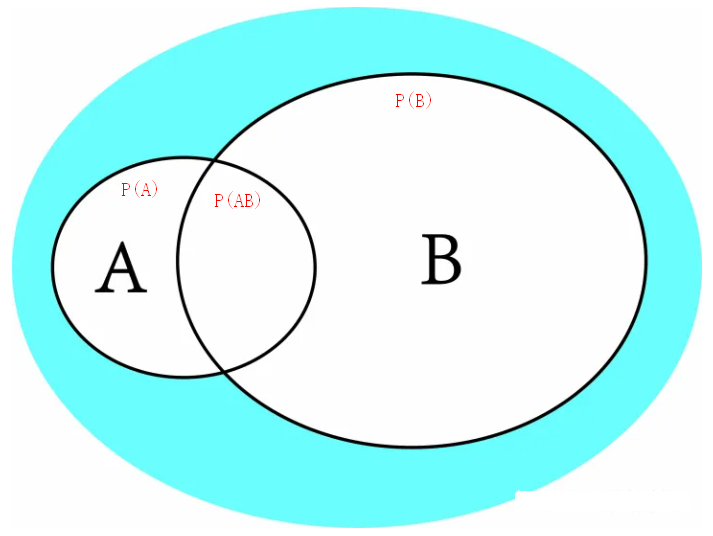
优先级: , > | > ;
例子1: P(A|B,C)表示在B,C的条件下,发生A的概率。
例子2:P(y∣x ; α,ω)表示:x发生条件下y的条件概率,该条件概率模型用参数α,ω建模(或者说用参数a,ω表示)。
注意:
p
(
x
∣
θ
)
p(x | \theta)
p(x∣θ)不总是代表条件概率,也就是说
p
(
x
∣
θ
)
p(x | \theta)
p(x∣θ) 不代表条件概率时与
p
(
x
;
θ
)
p(x ; \theta)
p(x;θ) 等价。而一般地,写竖杠表示条件概率,是随机变量。
p
(
x
;
θ
)
p(x ; \theta)
p(x;θ) 中,分号后的 表示待估参数(是固定的,只是当前未知),应该可以直接认为是
p
(
x
)
p(x)
p(x),加了,是为了强调说明这里有个
θ
\theta
θ 的参数,
p
(
x
;
θ
)
p(x ; \theta)
p(x;θ) 意思是随机变量
X
=
x
X=x
X=x 的概率。在 贝叶斯理论下又叫
X
=
x
X=x
X=x 的先验概率。
和 扩散模型推导公式的联系
根据以上讨论的这些,现在讨论一个比较复杂的情况。比如,
N
(
x
;
0
,
I
)
\mathcal{N}(x;0,I)
N(x;0,I)的意思是什么?
我们知道,
N
(
0
,
I
)
\mathcal{N}(0,I)
N(0,I)表示标准高斯分布,均值为0,方差为1,其本质上也是一个概率密度函数
f
(
x
)
=
1
σ
2
π
e
−
1
2
(
x
−
μ
σ
)
2
f(x) = \frac{1}{{\sigma \sqrt{2\pi}}} e^{ -\frac{1}{2}\left(\frac{x-\mu}{\sigma}\right)^2}
f(x)=σ2π1e−21(σx−μ)2(标准高斯分布情况下为
f
(
x
)
=
1
2
π
e
−
x
2
2
f(x) = \frac{1}{{\sqrt{2\pi}}} e^{ -\frac{x^2}{2}}
f(x)=2π1e−2x2 )。从这里可以发现,一般的函数我们都是强调自变量本身(比如
x
x
x),而在概率论里面有时候强调的是函数参数本身(比如高斯分布的均值和方差),而淡化了输入变量
x
x
x。因此
N
(
x
;
0
,
I
)
\mathcal{N}(x;0,I)
N(x;0,I)相比与
N
(
0
,
I
)
\mathcal{N}(0,I)
N(0,I)的区别就在于显式强调了函数的输入为
x
x
x。
这下,就好理解扩散模型中的噪声公式了:

那么,
q
(
x
t
∣
x
t
−
1
)
=
N
(
x
t
;
1
−
β
t
x
t
−
1
,
β
t
I
)
q(x_t | x_{t-1})=\mathcal{N}(x_t; \sqrt{1-\beta_t }x_{t-1}, \beta_t I)
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI),这个公式何意义?
这个东西分多步看。首先,函数本身是个条件概率分布,
q
(
x
t
∣
x
t
−
1
)
q(x_t | x_{t-1})
q(xt∣xt−1) 表示
x
t
−
1
x_{t-1}
xt−1 已知的情况下,
x
t
x_t
xt 的分布 (
x
t
x_t
xt取各种值的概率)。而后面的这个高斯分布则强调了其输入自变量为
x
t
x_t
xt(因为是
x
t
x_t
xt的概率密度函数,所以自变量当然是
x
t
x_t
xt),而高斯分布的均值和方差则分别为
1
−
β
t
x
t
−
1
和
β
t
I
\sqrt{1-\beta_t }x_{t-1} 和 \beta_t I
1−βtxt−1和βtI,与条件分布的条件
x
t
−
1
x_{t-1}
xt−1 有关。
全概率(概率函数连乘)

图示可表示为:
参考:
https://blog.csdn.net/shyjhyp11/article/details/133969095