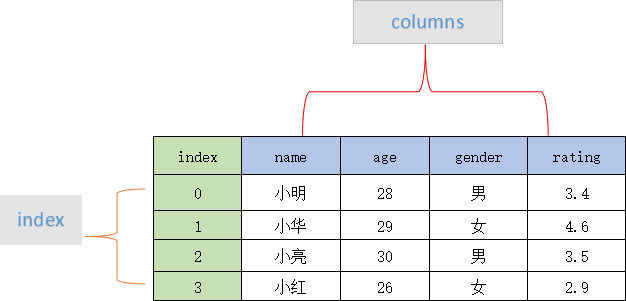
下面首先是参考的一些博客 https://blog.csdn.net/qq_44681809/article/details/137081515
qustion

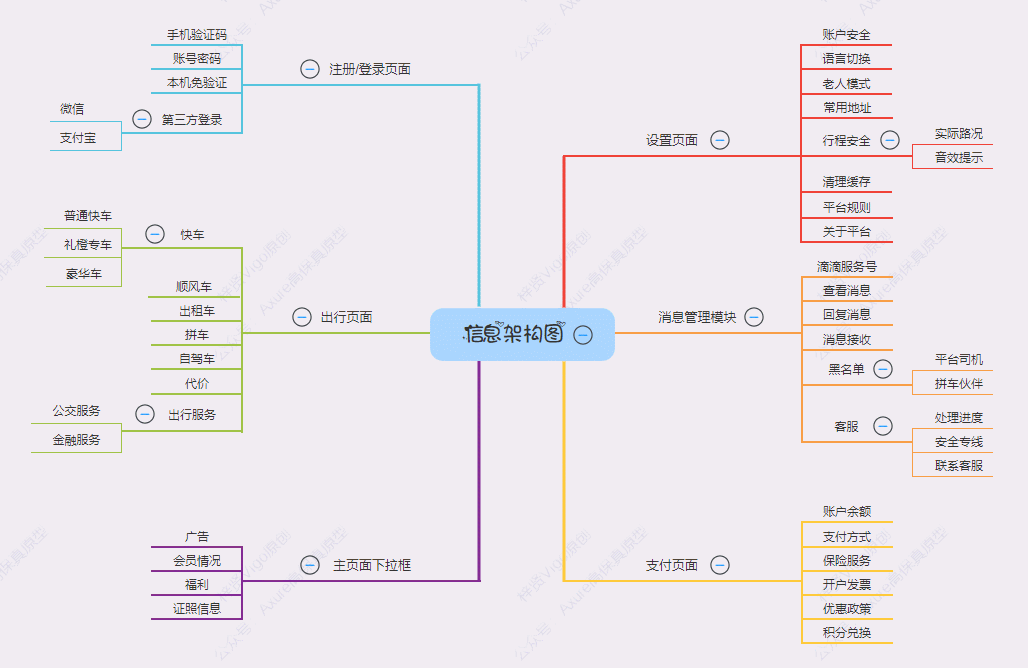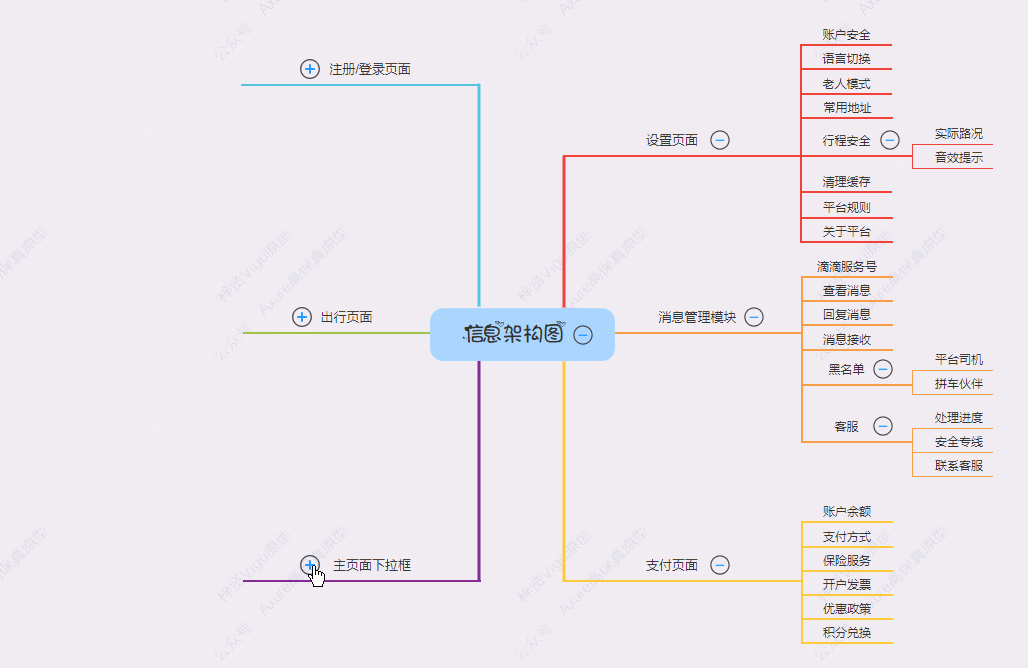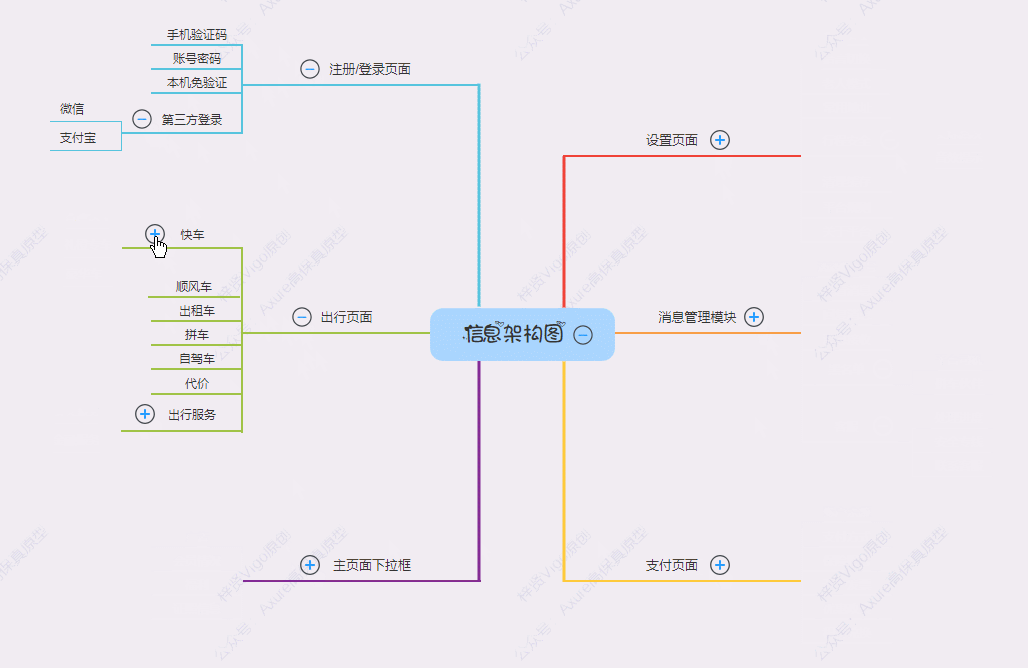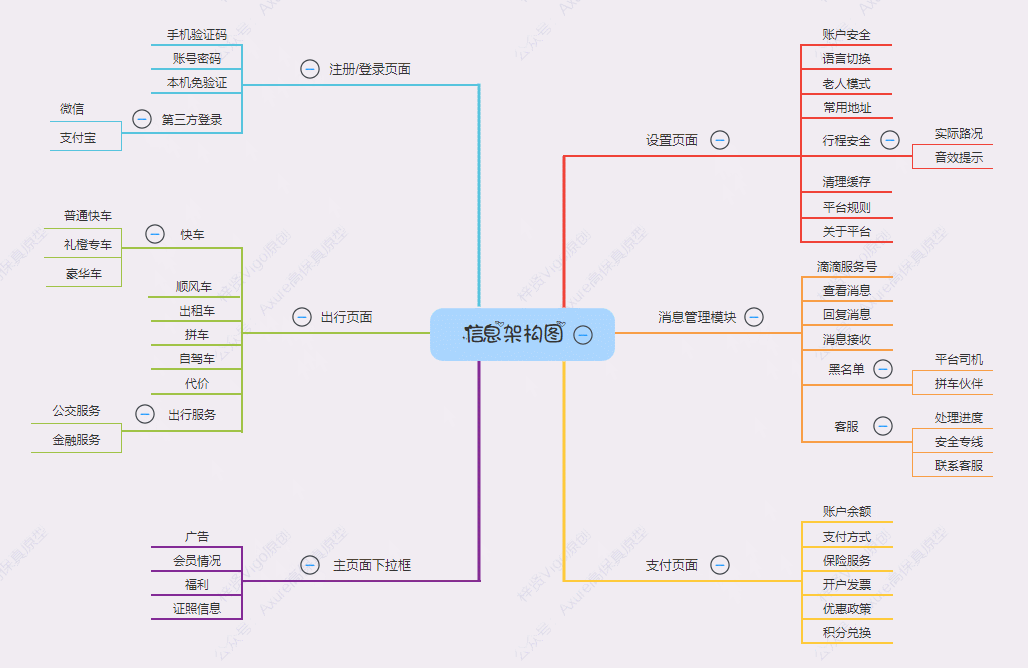
- SDEdit:就是给图片加一点噪声然后再用模型去噪,来获得一个更好的帧,比如去掉伪影和污点

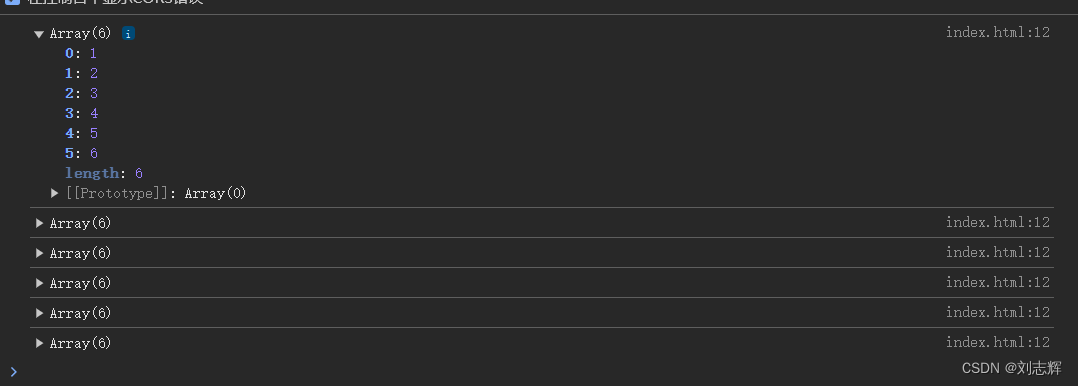
- 这里的分割为m个24帧的块,块与块之间已经有8帧重叠了吗?,就是在分割的时候按重叠分d perservation的吗?


- 由代码可以看出,它是按照每24帧中间重叠8帧的方式,做好分配规划后,提前取原视频的前trim_length帧,然后再喂给模型去做生成

- 按照这里的采样的新噪声是采了F-O个帧的来看,是在切分为24帧块的时候就已经把重叠做好了,,,,,不一定,噪声是共享的,但不能说明在切分为24帧块的时候是怎么切的,前好的前一块和后一块公共部分一模一样?还是独立的?还是?
- 猜测从低分辨率视频的切分应该是前一个块和后一个块不关联的切分,没有太大关系,由于生成也是一块一块生的(生成的时候是每次生成都一样的帧数吗?是24吗?),所以在块和块之间会不一致,所以要解决这个问题
- 所以这做到了共享噪声

- 这是什么意思

- 这里的更新整个长视频的重叠帧是什么意思,是从前一个块的重叠区域取一些帧,从后一个块的重叠区域取一些帧,然后凑成8帧,然后用这个新8帧再替换掉前一个块和后一个块的重叠的8帧是吗?还是把两块儿连在一起,只用一个,相当于去掉8帧?如果是前面一种情况,那初始分块的时候是怎么分的呢,按照这个取的规则,如果刚开始随机一个F_thr为1或者8,那就相当于用一个块的部分替换另一个一个块的部分了,所以初始分块的时候是完全切割分的吗,当然这和生成是怎么生成有关
- 在每一个t的去噪过程中,同一个块内还要做时间时间层面的注意力什么的,这种应该也会让重叠帧和块内其它帧做内容上的对齐
https://blog.csdn.net/v_JULY_v/article/details/136845242
https://blog.csdn.net/qq_29788741/article/details/137077902
- 这段长达 1200 帧的 2 分钟视频来自一个文生视频(text-to-video)模型,尽管 AI 生成的痕迹依然浓重,但我们必须承认,其中的人物和场景具有相当不错的一致性。这是如何办到的呢?要知道,虽然近些年文生视频技术的生成质量和文本对齐质量都已经相当出色,但大多数现有方法都聚焦于生成短视频(通常是 16 或 24 帧长度)。然而,适用于短视频的现有方法通常无法用于长视频(≥ 64 帧)。即使是生成短序列,通常也需要成本高昂的训练,比如训练步数超过 260K,批大小超过 4500。如果不在更长的视频上进行训练,通过短视频生成器来制作长视频,得到的长视频通常质量不佳。而现有的自回归方法(通过使用短视频后几帧生成新的短视频,进而合成长视频)也存在场景切换不一致等一些问题。
为了克服现有方法的缺点和局限,Picsart AI Resarch 等多个机构联合提出了一种新的文生视频方法:StreamingT2V。这也是一种自回归方法,并配备了长短期记忆模块,进而可以生成具有时间一致性的长视频。
summary
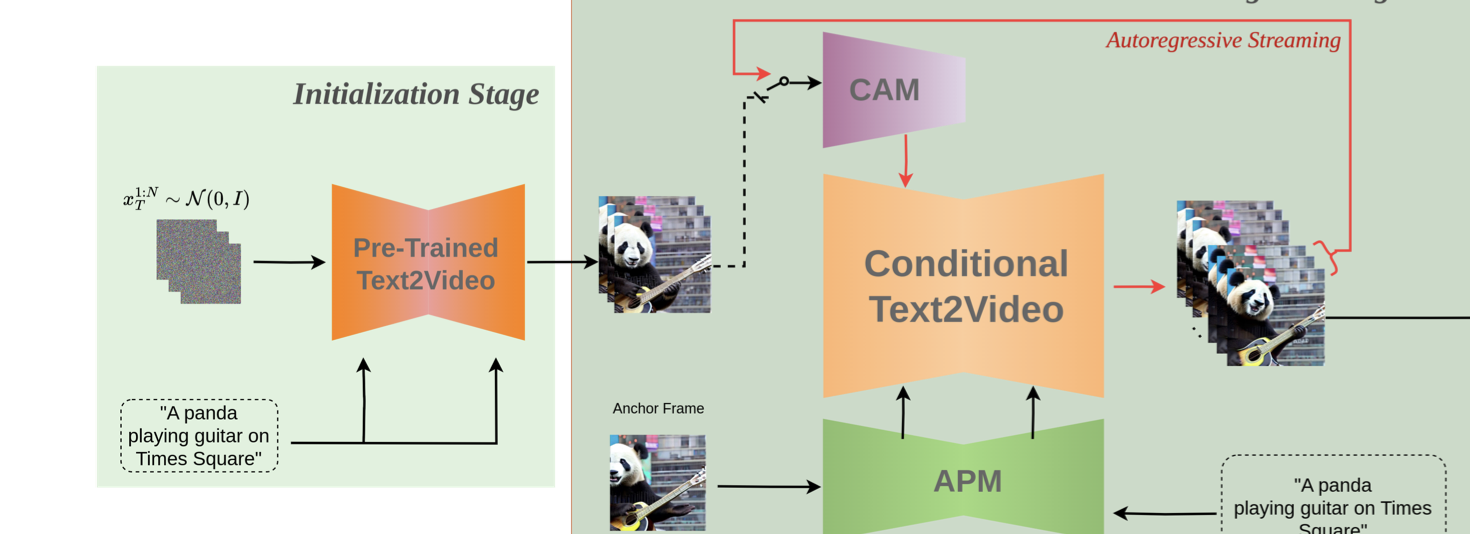
- 该团队提出了条件注意力模块(CAM)。得益于其注意力性质,它可以有效地借用之前帧的内容信息来生成新的帧,同时还不会让之前帧的结构 / 形状限制新帧中的运动情况。
- 而为了解决生成的视频中人与物外观变化的问题,该团队又提出了外观保留模块(APM):其可从一张初始图像(锚帧)提取对象或全局场景的外观信息,并使用该信息调节所有视频块的视频生成过程。
- 为了进一步提升长视频生成的质量和分辨率,该团队针对自回归生成任务对一个视频增强模型进行了改进。为此,该团队选择了一个高分辨率文生视频模型并使用了 SDEdit 方法来提升连续 24 帧(其中有 8 帧重叠帧)视频块的质量。
- 为了使视频块增强过渡变得平滑,他们还设计了一种随机混合方法,能以无缝方式混合重叠的增强过的视频块
- 这两个T2V是同一个模型吗?
- 根据代码中来看是的

- 上面的是初始阶段

- 上面是自回归阶段
- 根据代码中来看是的
StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text
摘要
-
现有方法大多集中在生成高质量的短视频(通常为 16 或 24 帧),当简单地扩展到长视频合成时,会出现硬切换(hardcuts)
-
StreamingT2V,是一种用于生成 80、240、600、1200 帧或更多帧具有平滑过渡的长视频的自回归方法
-
关键组件包括:
- 一种短期记忆块,称为条件注意力模块(conditional attention module,CAM),它通过注意机制将当前生成与从先前块(chunk)提取的特征相关联,从而实现一致的块过渡
- 一种长期记忆块,称为外观保持模块(Appearance Preservation Module,APM),它从第一个视频块中提取高级场景和对象特征,以防止模型忘记初始场景
- 一种随机混合(randomized blending)方法,使得将视频增强器自回归地应用于无限长视频时,不会出现块之间的不一致性
-
StreamingT2V,这是一种高质量的无缝文本到长视频生成器,其在一致性和运动方面优于竞争对手
-
问题:如果将长期记忆模块的锚帧换为自己的图片,不知道能不能做T+I to V的生成?或者将T2V换的模型换位I2V的模型,不知道能不变成T to V的生成?
相关工作
- 以前的长视频生成工作

- DynamiCrafter-XL [43],在每个文本交叉注意力中增加一个图像交叉注意力,这导致更好的质量,但仍然导致块之间频繁的不一致性
Preliminary
- StreamingT2V,是一个在VQ-GAN自动编码器D(E(·))的潜在空间上操作的扩散模型,其中E和D分别是对应的编码器和解码器
- 给定一个视频V ∈ R_F×H×W×3,它的潜在代码x0 ∈ R_F×h×w×c是通过逐帧应用编码器获得的
方法
-
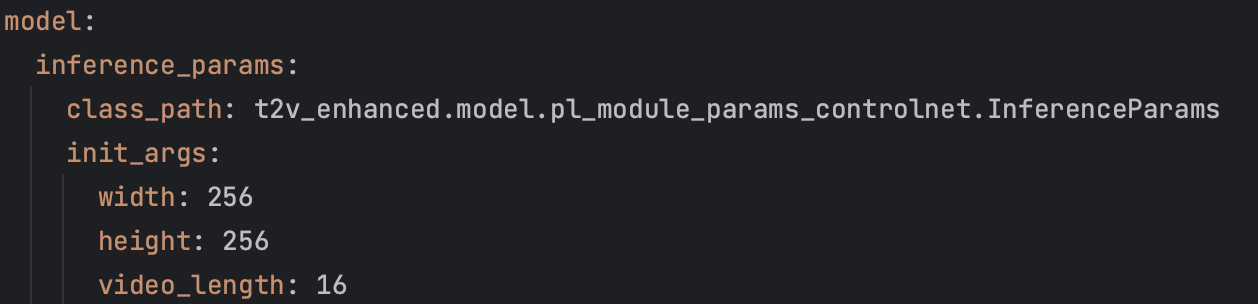
我们首先生成了 256 × 256 分辨率的长视频,时长为 5 秒(16fps),然后将它们提升到更高分辨率(720 × 720),整个流程的概述如下图所示

-
长视频生成部分包括:
- (初始化阶段)通过预先训练的文本到视频模型(例如可以使用 Modelscope [39])合成第一个 16 帧块(chunk),
- 以及(Streaming T2V 阶段)通过自回归方式为后续帧生成新内容。对于自回归(见图 3),我们提出了条件注意力模块(CAM),利用前一块的最后 F_cond = 8 帧的短期信息,实现块之间的无缝过渡。此外,我们利用外观保持模块(APM),从一个固定的锚定帧中提取长期信息,使自回归过程在生成过程中能够稳健地保留对象外观或场景细节
- 在生成了长视频(80、240、600、1200 帧或更多)之后,我们应用流式细化阶段(Streaming Refinement Stage),通过自回归方式应用高分辨率文本到短视频模型(例如可以使用 MS-Vid2Vid-XL [48]),并配备我们的随机混合方法进行无缝的块处理。后一步骤无需额外训练,因此使我们的方法在较低的计算成本下实现。
-
问题:先生成80帧,然后进行第三阶段,然后再生成剩下的帧?
-
每次生成16帧,以及输入生成多少次,自回归完后,再去第三阶段

-
上面是附录里给的详细参数
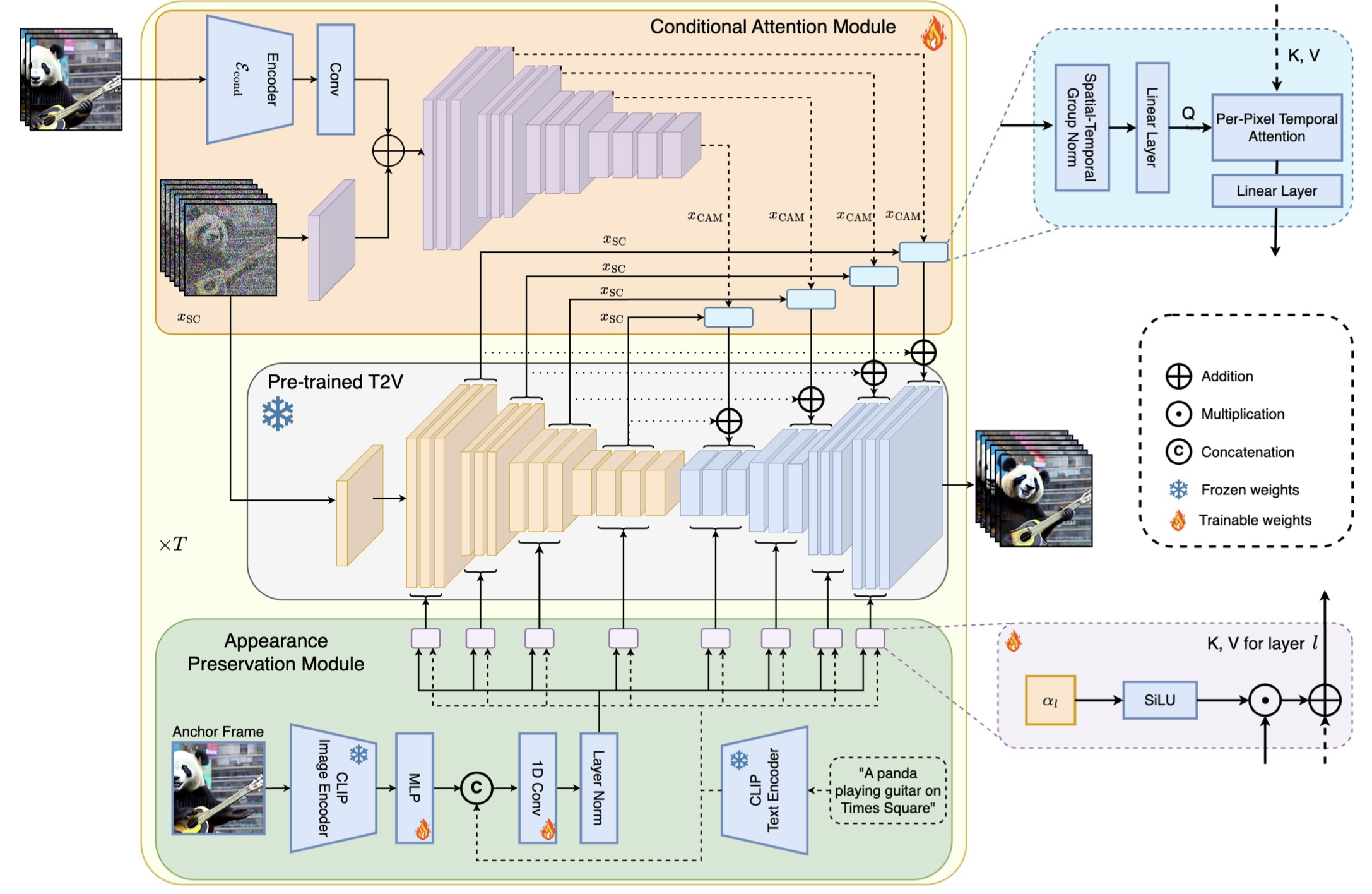
条件注意力模块
-
我们利用了文本到视频模型的预训练能力(例如 Modelscope [39]),作为长视频生成的先验,以自回归的方式进行,在接下来的写作中,我们将这个预训练的文本到(短)视频模型称为 Video-LDM。
-
为了通过前一块的一些短期信息(见图 2,中)自回归地调节 Video-LDM,受 ControlNet [46] 的启发,我们提出了条件注意力模块(CAM),它由特征提取器和一个注入到 Video-LDM UNet 中的特征注入器组成。
- 特征提取器利用逐帧图像编码器 E_cond,这个用的VQ-GAN的编码器
- 后跟与 Video-LDM UNet 到其中间层相同编码器层(并使用 UNet 的权重进行初始化),这里CAM的特征注入器应该是直接把Video-LDM的前一半拿过来,然后再可训练
-
对于特征注入,我们让 UNet 中的每个长距离跳连接通过交叉注意力来关注由 CAM 生成的相应特征。
-
令 x 表示在零卷积后的 E_cond 的输出
- 为什么要有零卷积
-
我们使用加法,将 x 与 CAM 的第一个时间 transformer 块的输出融合
- 为什么要有个这部分?
- 时间特征的捕捉:时间变换器模块(temporal transformer block)设计用来处理时间序列数据,它可以捕捉视频帧序列之间的时间动态和关联性
- 噪声的作用:向数据添加噪声并通过模型去除这些噪声的过程能够帮助模型学习如何在帧之间填充正确的时间动态
- 数据增强:通过噪声添加和去除的过程也可以被看作是一种数据增强技术,它可以帮助模型变得更加鲁棒,能够处理更多的不确定性
- 这里的直接相交操作是通道数变多了,还是逐元素值相加
- 为什么要有个这部分?
-
对于将 CAM 的特征注入到 Video-LDM Unet 中,我们考虑 UNet 的跳跃连接特征x_SC ∈ R^(b×F×h×w×c)。
- 我们对 x_SC 应用时空分组归一化(spatio-temporal group norm),并在 x_SC 上应用线性投影 P_in
- 空间-时间组归一化会考虑一个视频块(或帧序列)的所有帧,并在整个块中同时对空间和时间维度进行归一化。这有助于网络捕捉到视频中的运动模式和其他时间动态,同时减少内部协变量偏移(internal covariate shift)
- 在神经网络中使用的空间-时间组归一化(spatio-temporal group norm)通常指的是对数据进行规范化处理,以使得数据的分布具有固定的均值和标准差(例如均值为0,标准差为1),这样的处理有利于模型的训练和泛化
- 线性投影通常是一个全连接层或者线性层,没有激活函数,作用是将输入数据(这里是归一化后的特征)映射到另一个空间,作用可能是特征转换、降维/升维、数据预处理
- 让 x′_SC ∈ R^((b·w·h)×F×c) 表示重塑后的张量,我们通过时间多头注意力(T-MHA),即对每个空间位置(和 batch)独立地
- 对每个batch下的像素都做
- 令 x′_SC 以相应的 CAM 特征 x_CAM ∈ R^((b·w·h)×F_cond×c) 为条件,其中 F_cond 是条件帧的数量,对于查询、键和值,使用可学习的线性映射 P_Q、P_K、P_V,我们应用 TMHA,其中键和值来自 x_CAM,而查询来自 x′_SC,即

- 最后,我们使用线性投影 P_out。通过使用适当的重塑操作 R,将 CAM 的输出添加到跳跃连接中(与 ControlNet [46] 中的方式相同)

- 我们对 x_SC 应用时空分组归一化(spatio-temporal group norm),并在 x_SC 上应用线性投影 P_in
-
因此,x′′′ 在 UNet 的解码器层中使用。投影 P_out 是零初始化的,因此在训练开始时,CAM 不会影响基础模型的输出,这有助于提高训练的收敛性。
外观保持模块
- 自回归视频生成器通常会忘记初始对象和场景特征,导致外观变化严重
- 为了解决这个问题,我们利用提出的外观保持模块(APM)来结合长期记忆,利用第一个块的固定锚定帧中包含的信息
- 我们将锚定帧的 CLIP [25] 图像 token 与文本指令中的 CLIP 文本 token 混合,通过使用线性层将 clip 图像 token 扩展为 k = 8 个 token,并在 token 维度上连接文本和图像编码,然后使用投影块,得到 x_mixed ∈ R^(b×77×1024)
- 对于每个交叉注意力层 l,我们引入一个权重 α_l ∈ R(初始化为 0),通过对 x_mixed 和文本指令的常规 CLIP 文本编码的加权和来执行交叉注意力
- 第 5.3 节的实验表明,轻量级的 APM 模块有助于在自回归过程中保持场景和身份特征(见图 6)
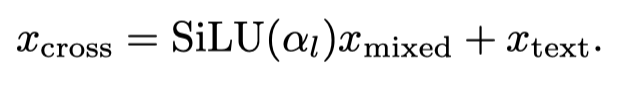
- 1D卷积可以沿着时间轴扫描并提取特征,识别序列中的局部模式,例如视频帧之间的运动变化或连续性
自回归视频增强
-
为了进一步提高我们文本到视频结果的质量和分辨率,我们利用一个高分辨率(1280x720)的文本到(短)视频模型(Refiner Video-LDM,见图 3),自回归地增强生成视频的 24 帧块
-
使用文本到视频模型作为 24 帧块的精化器/增强器是通过将大量噪声添加到输入视频块中,并使用文本到视频扩散模型(SDEdit [22] 方法)进行去噪来实现的
- SDEdit:就是给图片加一点噪声然后再用模型去噪,来获得一个更好的帧,比如去掉伪影和污点
-
更具体地说,
- 我们采用高分辨率文本到视频模型(例如 MS-Vid2Vid-XL [40, 48]),
- MS-Vid2Vid-XL是什么分辨率的
- 以及首先通过双线性上采样 [2] 将 24 帧的低分辨率视频块上采样到目标高分辨率,
- 然后我们使用图像编码器 E 对帧进行编码,以获得潜在代码 x0
- 然后,我们应用 T′ < T 个前向扩散步骤,以便 x_T′ 仍包含信号信息(主要是关于视频结构)
- 并使用高分辨率视频扩散模型进行去噪。
- 我们采用高分辨率文本到视频模型(例如 MS-Vid2Vid-XL [40, 48]),
-
然而,独立增强每个块的简单方法会导致不一致的过渡(见图 4 (a))
-
我们通过在连续块之间使用共享噪声并利用我们的随机混合方法来解决这个问题
-
给定我们的低分辨率长视频,我们将其分割成 m 个长度为 F = 24 帧的块 V1,…,Vm,以便每两个连续的块具有 O = 8 帧的重叠
- 切分的时候就让它重叠8帧切的吗?
- 是的,上面有代码
- 切分的时候就让它重叠8帧切的吗?
-
从 T′ 开始,我们必须采样噪声来执行一个去噪步骤,我们从第一个块 V1 开始,并采样噪声 ϵ_1 ∼ N(0, I),其中 ϵ_1 ∈ R^(F×h×w×c)。对于每个后续块 V_i,i > 1,我们采样噪声 ˆϵi ∼ N(0, I),其中 ˆϵi ∈ R^((F−O)×h×w×c),并沿帧维度将其与前一个块的 O 个重叠帧的噪声链接
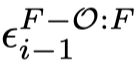
-
即

-
如果直接用 ϵ \epsilon ϵi进行Vi块的加噪去噪,得到X_t-1(i) ,这种方法并不足以消除过渡不一致(见图 4 (b))。
-
为了显著提高一致性,我们提出了随机混合方法。考虑到连续两个块 V_(i−1)、Vi 在去噪步骤 t−1 时的潜在编码
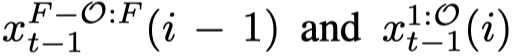
-
块 V_(i−1) 的潜在编码 x_(t−1) (i−1) 在其前几帧到重叠帧之间具有平滑过渡,而块 Vi 的潜在编码 x_(t−1) (i) 在重叠帧到其后续帧之间具有平滑过渡。因此,我们通过串联两个潜在编码来组合它们:随机从 {0, . . . ,O} 中采样一个帧索引 f_thr,然后从
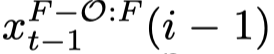 中取前 f_thr 帧的潜在编码,从
中取前 f_thr 帧的潜在编码,从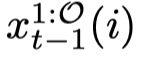 中取从 fthr + 1 开始的帧的潜在编码
中取从 fthr + 1 开始的帧的潜在编码 -
然后,我们更新整个长视频的潜在编码 x_(t−1) 上的重叠帧,并执行下一个去噪步骤
-
通过在重叠区域中使用潜在编码的概率混合,我们成功地减少了块之间的不一致性(见图 4©)。
-
问题:这里的更新重叠帧是指怎么更新?
- 整个视频序列是连着的,然后把重叠部分替换掉
-
MS-Vid2Vid由达摩院研发和训练,主要用于提升文生视频、图生视频的分辨率和时空连续性,其训练数据包含了精选的海量的高清视频、图像数据(最短边>720),可以将低分辨率的(16:9)的视频提升到更高分辨率(1280 * 720),可以用于任意低分辨率的的超分
-
最终生成的视频大小是多少?
-
unet的网络最后一维是512,但为什么初始生成的视频是256?
-可能在unet后面又做了其它处理,这得仔细看代码