Python语言进阶
重要知识点
- 生成式(推导式)的用法
prices = {
'AAPL': 191.88,
'GOOG': 1186.96,
'IBM': 149.24,
'ORCL': 48.44,
'ACN': 166.89,
'FB': 208.09,
'SYMC': 21.29
}
# 用股票价格大于100元的股票构造一个新的字典
prices2 = {key: value for key, value in prices.items() if value > 100}
print(prices2)
说明:生成式(推导式)可以用来生成列表、集合和字典。
- 嵌套的列表的坑
names = ['关羽', '张飞', '赵云', '马超', '黄忠']
courses = ['语文', '数学', '英语']
# 录入五个学生三门课程的成绩
# scores = [[None] * len(courses)] * len(names)
scores = [[None] * len(courses) for _ in range(len(names))]
for row, name in enumerate(names):
for col, course in enumerate(courses):
scores[row][col] = float(input(f'请输入{name}的{course}成绩: '))
print(scores)
heapq模块(堆排序)
"""
从列表中找出最大的或最小的N个元素
堆结构(大根堆/小根堆)
"""
import heapq
list1 = [34, 25, 12, 99, 87, 63, 58, 78, 88, 92]
list2 = [
{'name': 'IBM', 'shares': 100, 'price': 91.1},
{'name': 'AAPL', 'shares': 50, 'price': 543.22},
{'name': 'FB', 'shares': 200, 'price': 21.09},
{'name': 'HPQ', 'shares': 35, 'price': 31.75},
{'name': 'YHOO', 'shares': 45, 'price': 16.35},
{'name': 'ACME', 'shares': 75, 'price': 115.65}
]
print(heapq.nlargest(3, list1))
print(heapq.nsmallest(3, list1))
print(heapq.nlargest(2, list2, key=lambda x: x['price']))
print(heapq.nlargest(2, list2, key=lambda x: x['shares']))
itertools模块
"""
迭代工具模块
"""
import itertools
# 产生ABCD的全排列
itertools.permutations('ABCD')
# 产生ABCDE的五选三组合
itertools.combinations('ABCDE', 3)
# 产生ABCD和123的笛卡尔积
itertools.product('ABCD', '123')
# 产生ABC的无限循环序列
itertools.cycle(('A', 'B', 'C'))
-
collections模块常用的工具类:
namedtuple:命令元组,它是一个类工厂,接受类型的名称和属性列表来创建一个类。deque:双端队列,是列表的替代实现。Python中的列表底层是基于数组来实现的,而deque底层是双向链表,因此当你需要在头尾添加和删除元素时,deque会表现出更好的性能,渐近时间复杂度为 O ( 1 ) O(1) O(1)。Counter:dict的子类,键是元素,值是元素的计数,它的most_common()方法可以帮助我们获取出现频率最高的元素。Counter和dict的继承关系我认为是值得商榷的,按照CARP原则,Counter跟dict的关系应该设计为关联关系更为合理。OrderedDict:dict的子类,它记录了键值对插入的顺序,看起来既有字典的行为,也有链表的行为。defaultdict:类似于字典类型,但是可以通过默认的工厂函数来获得键对应的默认值,相比字典中的setdefault()方法,这种做法更加高效。
"""
找出序列中出现次数最多的元素
"""
from collections import Counter
words = [
'look', 'into', 'my', 'eyes', 'look', 'into', 'my', 'eyes',
'the', 'eyes', 'the', 'eyes', 'the', 'eyes', 'not', 'around',
'the', 'eyes', "don't", 'look', 'around', 'the', 'eyes',
'look', 'into', 'my', 'eyes', "you're", 'under'
]
counter = Counter(words)
print(counter.most_common(3))
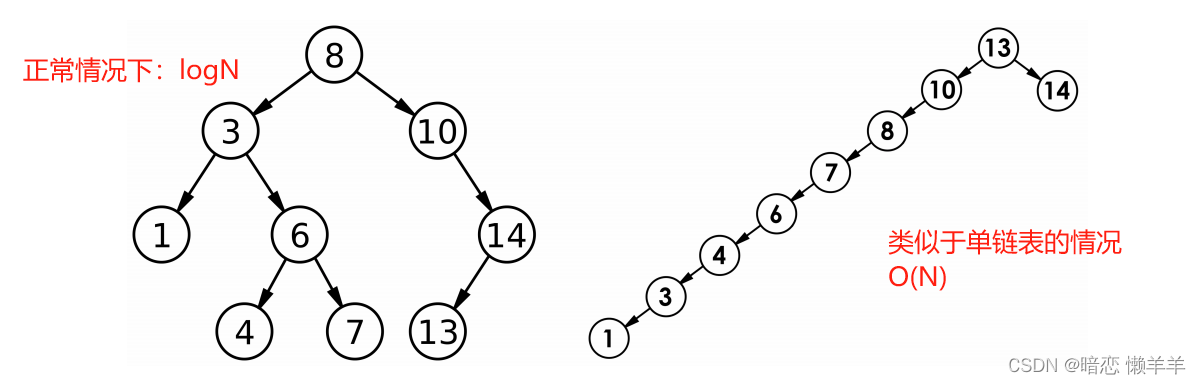
数据结构和算法
-
算法:解决问题的方法和步骤
-
评价算法的好坏:渐近时间复杂度和渐近空间复杂度。


- 排序算法(选择、冒泡和归并)和查找算法(顺序和折半)
def select_sort(items, comp=lambda x, y: x < y):
"""简单选择排序"""
items = items[:]
for i in range(len(items) - 1):
min_index = i
for j in range(i + 1, len(items)):
if comp(items[j], items[min_index]):
min_index = j
items[i], items[min_index] = items[min_index], items[i]
return items
def bubble_sort(items, comp=lambda x, y: x > y):
"""冒泡排序"""
items = items[:]
for i in range(len(items) - 1):
swapped = False
for j in range(len(items) - 1 - i):
if comp(items[j], items[j + 1]):
items[j], items[j + 1] = items[j + 1], items[j]
swapped = True
if not swapped:
break
return items
def bubble_sort(items, comp=lambda x, y: x > y):
"""搅拌排序(冒泡排序升级版)"""
items = items[:]
for i in range(len(items) - 1):
swapped = False
for j in range(len(items) - 1 - i):
if comp(items[j], items[j + 1]):
items[j], items[j + 1] = items[j + 1], items[j]
swapped = True
if swapped:
swapped = False
for j in range(len(items) - 2 - i, i, -1):
if comp(items[j - 1], items[j]):
items[j], items[j - 1] = items[j - 1], items[j]
swapped = True
if not swapped:
break
return items
def merge(items1, items2, comp=lambda x, y: x < y):
"""合并(将两个有序的列表合并成一个有序的列表)"""
items = []
index1, index2 = 0, 0
while index1 < len(items1) and index2 < len(items2):
if comp(items1[index1], items2[index2]):
items.append(items1[index1])
index1 += 1
else:
items.append(items2[index2])
index2 += 1
items += items1[index1:]
items += items2[index2:]
return items
def merge_sort(items, comp=lambda x, y: x < y):
return _merge_sort(list(items), comp)
def _merge_sort(items, comp):
"""归并排序"""
if len(items) < 2:
return items
mid = len(items) // 2
left = _merge_sort(items[:mid], comp)
right = _merge_sort(items[mid:], comp)
return merge(left, right, comp)
def seq_search(items, key):
"""顺序查找"""
for index, item in enumerate(items):
if item == key:
return index
return -1
def bin_search(items, key):
"""折半查找"""
start, end = 0, len(items) - 1
while start <= end:
mid = (start + end) // 2
if key > items[mid]:
start = mid + 1
elif key < items[mid]:
end = mid - 1
else:
return mid
return -1
-
常用算法:
- 穷举法 - 又称为暴力破解法,对所有的可能性进行验证,直到找到正确答案。
- 贪婪法 - 在对问题求解时,总是做出在当前看来
- 最好的选择,不追求最优解,快速找到满意解。
- 分治法 - 把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题,直到可以直接求解的程度,最后将子问题的解进行合并得到原问题的解。
- 回溯法 - 回溯法又称为试探法,按选优条件向前搜索,当搜索到某一步发现原先选择并不优或达不到目标时,就退回一步重新选择。
- 动态规划 - 基本思想也是将待求解问题分解成若干个子问题,先求解并保存这些子问题的解,避免产生大量的重复运算。
穷举法例子:百钱百鸡和五人分鱼。
# 公鸡5元一只 母鸡3元一只 小鸡1元三只
# 用100元买100只鸡 问公鸡/母鸡/小鸡各多少只
for x in range(20):
for y in range(33):
z = 100 - x - y
if 5 * x + 3 * y + z // 3 == 100 and z % 3 == 0:
print(x, y, z)
# A、B、C、D、E五人在某天夜里合伙捕鱼 最后疲惫不堪各自睡觉
# 第二天A第一个醒来 他将鱼分为5份 扔掉多余的1条 拿走自己的一份
# B第二个醒来 也将鱼分为5份 扔掉多余的1条 拿走自己的一份
# 然后C、D、E依次醒来也按同样的方式分鱼 问他们至少捕了多少条鱼
fish = 6
while True:
total = fish
enough = True
for _ in range(5):
if (total - 1) % 5 == 0:
total = (total - 1) // 5 * 4
else:
enough = False
break
if enough:
print(fish)
break
fish += 5
贪婪法例子:假设小偷有一个背包,最多能装20公斤赃物,他闯入一户人家,发现如下表所示的物品。很显然,他不能把所有物品都装进背包,所以必须确定拿走哪些物品,留下哪些物品。
| 名称 | 价格(美元) | 重量(kg) |
|---|---|---|
| 电脑 | 200 | 20 |
| 收音机 | 20 | 4 |
| 钟 | 175 | 10 |
| 花瓶 | 50 | 2 |
| 书 | 10 | 1 |
| 油画 | 90 | 9 |
"""
贪婪法:在对问题求解时,总是做出在当前看来是最好的选择,不追求最优解,快速找到满意解。
输入:
20 6
电脑 200 20
收音机 20 4
钟 175 10
花瓶 50 2
书 10 1
油画 90 9
"""
class Thing(object):
"""物品"""
def __init__(self, name, price, weight):
self.name = name
self.price = price
self.weight = weight
@property
def value(self):
"""价格重量比"""
return self.price / self.weight
def input_thing():
"""输入物品信息"""
name_str, price_str, weight_str = input().split()
return name_str, int(price_str), int(weight_str)
def main():
"""主函数"""
max_weight, num_of_things = map(int, input().split())
all_things = []
for _ in range(num_of_things):
all_things.append(Thing(*input_thing()))
all_things.sort(key=lambda x: x.value, reverse=True)
total_weight = 0
total_price = 0
for thing in all_things:
if total_weight + thing.weight <= max_weight:
print(f'小偷拿走了{thing.name}')
total_weight += thing.weight
total_price += thing.price
print(f'总价值: {total_price}美元')
if __name__ == '__main__':
main()
分治法例子:[快速排序]
"""
快速排序 - 选择枢轴对元素进行划分,左边都比枢轴小右边都比枢轴大
"""
def quick_sort(items, comp=lambda x, y: x <= y):
items = list(items)[:]
_quick_sort(items, 0, len(items) - 1, comp)
return items
def _quick_sort(items, start, end, comp):
if start < end:
pos = _partition(items, start, end, comp)
_quick_sort(items, start, pos - 1, comp)
_quick_sort(items, pos + 1, end, comp)
def _partition(items, start, end, comp):
pivot = items[end]
i = start - 1
for j in range(start, end):
if comp(items[j], pivot):
i += 1
items[i], items[j] = items[j], items[i]
items[i + 1], items[end] = items[end], items[i + 1]
return i + 1
回溯法例子:[骑士巡逻]
"""
递归回溯法:叫称为试探法,按选优条件向前搜索,当搜索到某一步,发现原先选择并不优或达不到目标时,就退回一步重新选择,比较经典的问题包括骑士巡逻、八皇后和迷宫寻路等。
"""
import sys
import time
SIZE = 5
total = 0
def print_board(board):
for row in board:
for col in row:
print(str(col).center(4), end='')
print()
def patrol(board, row, col, step=1):
if row >= 0 and row < SIZE and \
col >= 0 and col < SIZE and \
board[row][col] == 0:
board[row][col] = step
if step == SIZE * SIZE:
global total
total += 1
print(f'第{total}种走法: ')
print_board(board)
patrol(board, row - 2, col - 1, step + 1)
patrol(board, row - 1, col - 2, step + 1)
patrol(board, row + 1, col - 2, step + 1)
patrol(board, row + 2, col - 1, step + 1)
patrol(board, row + 2, col + 1, step + 1)
patrol(board, row + 1, col + 2, step + 1)
patrol(board, row - 1, col + 2, step + 1)
patrol(board, row - 2, col + 1, step + 1)
board[row][col] = 0
def main():
board = [[0] * SIZE for _ in range(SIZE)]
patrol(board, SIZE - 1, SIZE - 1)
if __name__ == '__main__':
main()
动态规划例子:子列表元素之和的最大值。
说明:子列表指的是列表中索引(下标)连续的元素构成的列表;列表中的元素是int类型,可能包含正整数、0、负整数;程序输入列表中的元素,输出子列表元素求和的最大值,例如:
输入:1 -2 3 5 -3 2
输出:8
输入:0 -2 3 5 -1 2
输出:9
输入:-9 -2 -3 -5 -3
输出:-2
def main():
items = list(map(int, input().split()))
overall = partial = items[0]
for i in range(1, len(items)):
partial = max(items[i], partial + items[i])
overall = max(partial, overall)
print(overall)
if __name__ == '__main__':
main()
说明:这个题目最容易想到的解法是使用二重循环,但是代码的时间性能将会变得非常的糟糕。使用动态规划的思想,仅仅是多用了两个变量,就将原来 O ( N 2 ) O(N^2) O(N2)复杂度的问题变成了 O ( N ) O(N) O(N)。
函数的使用方式
-
将函数视为“一等公民”
- 函数可以赋值给变量
- 函数可以作为函数的参数
- 函数可以作为函数的返回值
-
高阶函数的用法(
filter、map以及它们的替代品)
items1 = list(map(lambda x: x ** 2, filter(lambda x: x % 2, range(1, 10))))
items2 = [x ** 2 for x in range(1, 10) if x % 2]
-
位置参数、可变参数、关键字参数、命名关键字参数
-
参数的元信息(代码可读性问题)
-
匿名函数和内联函数的用法(
lambda函数) -
闭包和作用域问题
-
Python搜索变量的LEGB顺序(Local >>> Embedded >>> Global >>> Built-in)
-
global和nonlocal关键字的作用global:声明或定义全局变量(要么直接使用现有的全局作用域的变量,要么定义一个变量放到全局作用域)。nonlocal:声明使用嵌套作用域的变量(嵌套作用域必须存在该变量,否则报错)。
-
-
装饰器函数(使用装饰器和取消装饰器)
例子:输出函数执行时间的装饰器。
def record_time(func):
"""自定义装饰函数的装饰器"""
@wraps(func)
def wrapper(*args, **kwargs):
start = time()
result = func(*args, **kwargs)
print(f'{func.__name__}: {time() - start}秒')
return result
return wrapper
如果装饰器不希望跟print函数耦合,可以编写可以参数化的装饰器。
from functools import wraps
from time import time
def record(output):
"""可以参数化的装饰器"""
def decorate(func):
@wraps(func)
def wrapper(*args, **kwargs):
start = time()
result = func(*args, **kwargs)
output(func.__name__, time() - start)
return result
return wrapper
return decorate
from functools import wraps
from time import time
class Record():
"""通过定义类的方式定义装饰器"""
def __init__(self, output):
self.output = output
def __call__(self, func):
@wraps(func)
def wrapper(*args, **kwargs):
start = time()
result = func(*args, **kwargs)
self.output(func.__name__, time() - start)
return result
return wrapper
说明:由于对带装饰功能的函数添加了@wraps装饰器,可以通过
func.__wrapped__方式获得被装饰之前的函数或类来取消装饰器的作用。
例子:用装饰器来实现单例模式。
from functools import wraps
def singleton(cls):
"""装饰类的装饰器"""
instances = {}
@wraps(cls)
def wrapper(*args, **kwargs):
if cls not in instances:
instances[cls] = cls(*args, **kwargs)
return instances[cls]
return wrapper
@singleton
class President:
"""总统(单例类)"""
pass
提示:上面的代码中用到了闭包(closure),不知道你是否已经意识到了。还没有一个小问题就是,上面的代码并没有实现线程安全的单例,如果要实现线程安全的单例应该怎么做呢?
线程安全的单例装饰器。
from functools import wraps
from threading import RLock
def singleton(cls):
"""线程安全的单例装饰器"""
instances = {}
locker = RLock()
@wraps(cls)
def wrapper(*args, **kwargs):
if cls not in instances:
with locker:
if cls not in instances:
instances[cls] = cls(*args, **kwargs)
return instances[cls]
return wrapper
提示:上面的代码用到了
with上下文语法来进行锁操作,因为锁对象本身就是上下文管理器对象(支持__enter__和__exit__魔术方法)。在wrapper函数中,我们先做了一次不带锁的检查,然后再做带锁的检查,这样做比直接加锁检查性能要更好,如果对象已经创建就没有必须再去加锁而是直接返回该对象就可以了。
重要知识点
因为五一的原因,无奈托更了几天,还请大家谅解,从今天开始仍然会每天为大家分享Python的知识,而且从本片博客开始,也正是进入了Python第二阶段,大家一起加油吧!!!