文章目录
- Python中对象数据持久化操作模块学习笔记
- marshal模块
- 优点
- 缺点
- 使用示例
- 保存数据到文件
- 从文件读取数据
- shelve模块
- 优点
- 缺点
- 使用示例
- 保存数据到文件
- 从文件读取数据
- 总结
Python中对象数据持久化操作模块学习笔记
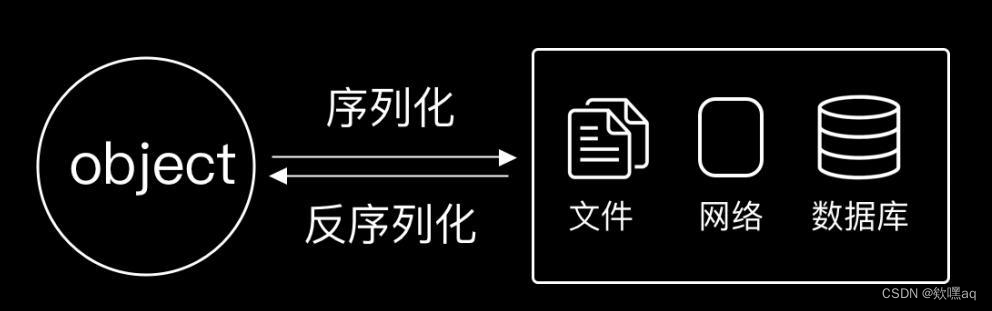
在Python中,数据持久化指的是将程序中的数据结构转换为可以存储的形式,并在需要的时候重新加载到程序中。以下是两个常用于数据持久化的模块:marshal 和 shelve。
marshal模块
marshal模块是Python的一个内置模块,它可以用来将Python对象序列化为字节流,以及将这些字节流反序列化回Python对象。这个模块主要用于Python对象的序列化,它支持大多数Python数据类型。
优点
- 速度快,因为
marshal模块是C语言编写的,所以序列化和反序列化的速度非常快。 - 兼容性好,可以序列化几乎所有Python标准数据类型。
缺点
- 安全性低,因为
marshal模块不进行任何数据的安全性检查,所以它可能会执行任意代码。 - 不支持自定义对象。
使用示例
保存数据到文件
import marshal
# 字典数据
data = {'key1': 'value1', 'key2': 'value2'}
# 将数据序列化并保存到文件
with open('data.marshal', 'wb') as f:
marshal.dump(data, f)
从文件读取数据
import marshal
# 从文件反序列化数据
with open('data.marshal', 'rb') as f:
data = marshal.load(f)
print(data)
shelve模块
shelve模块提供了一个简单的接口来保存和读取Python对象。它使用一个字典类型的对象作为界面,所有字典中的操作都会被保存到磁盘上。
优点
- 易于使用,它提供了一个非常直观的字典接口。
- 支持自定义对象。
缺点
- 速度慢,相比
marshal,shelve的速度较慢。 - 兼容性一般,它依赖于
dbm模块,不同的dbm实现可能会影响数据的兼容性。
使用示例
保存数据到文件
import shelve
# 创建一个shelve对象,指定数据库名称
with shelve.open('data.db') as db:
db['key1'] = 'value1'
db['key2'] = 'value2'
从文件读取数据
import shelve
# 打开shelve对象并读取数据
with shelve.open('data.db') as db:
print(db['key1'])
print(db['key2'])
总结
marshal模块适合于快速序列化和反序列化Python内置数据类型,但安全性较低,不支持自定义对象。shelve模块提供了一个简单易用的字典接口,支持自定义对象,但速度较慢,且依赖于dbm模块。
在实际应用中,选择哪个模块取决于具体的需求和场景。如果数据安全性和自定义对象支持是关键因素,shelve可能是更好的选择。如果速度和性能是主要考虑,marshal可能更适合。不过,对于更复杂的数据持久化需求,可能需要考虑其他更专业的数据库解决方案。