我们处理的变量可以分为两类,一类是连续型变量,另一类叫做分类型变量,其中对于连续型变量,如果服从正态分布就用平均值填充NA,不服从正态分布就用中位数填充NA,对于分类型变量,不管是有序的(比如一年级,二年级)还是无序的(比如男性,女性)都是用众数来填补NA。
分类型变量的描述性数据分析
对于分类型变量,我们只需要关心每一类变量有多少个以及他的众数,使用的函数为table(变量),table函数的基本语法为
table(..., useNA = "always", exclude = NULL)
- ...:一个或多个向量,表示要创建频率表的分类变量。可以是因子(factor)、逻辑(logical)或整数(integer)类型。
- useNA:指定如何处理NA值。默认always,表示总是将NA作为一个类别包括在内。如果设置为no,则不包括NA值。
- exclude:指定要排除的类别。
包含了分类变量中每种类别的名字和其对应的频数。
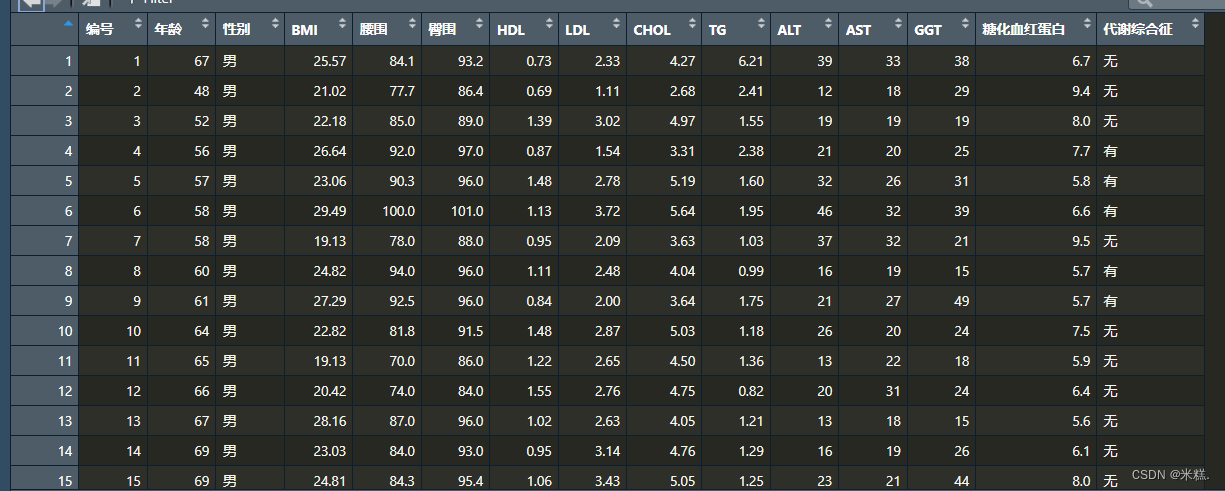
假如有一个名为mydata的数据框如图所示
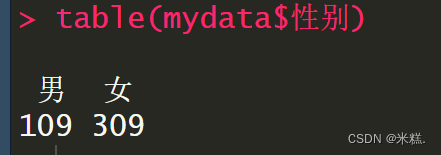
运行代码table(mydata$性别)就可以得到男女各有多少人了,table函数的返回结果为分类变量中每种类别的名字和对应的频数
要找查分类变量中的众数,可以借助which.max函数,运行代码
which.max(table(mydata$性别)),结果如图

which.max用于返回变量中最大值出现位置的下标,而max函数用于返回最大值。基本语法为which.max(..., arr.ind = FALSE, useNames = TRUE)
- ...:一个或多个数值型向量,从中找出最大值的索引。
- arr.ind:逻辑值,指定是否返回数组索引。默认为FALSE。
- useNames:逻辑值,指定是否使用变量名作为返回值的一部分。默认TRUE。可以看到上面的例子中确实返回了变量名。
连续型变量的描述性数据分析
R语言描述统计操作的函数有:summary函数,describe函数等
summary函数
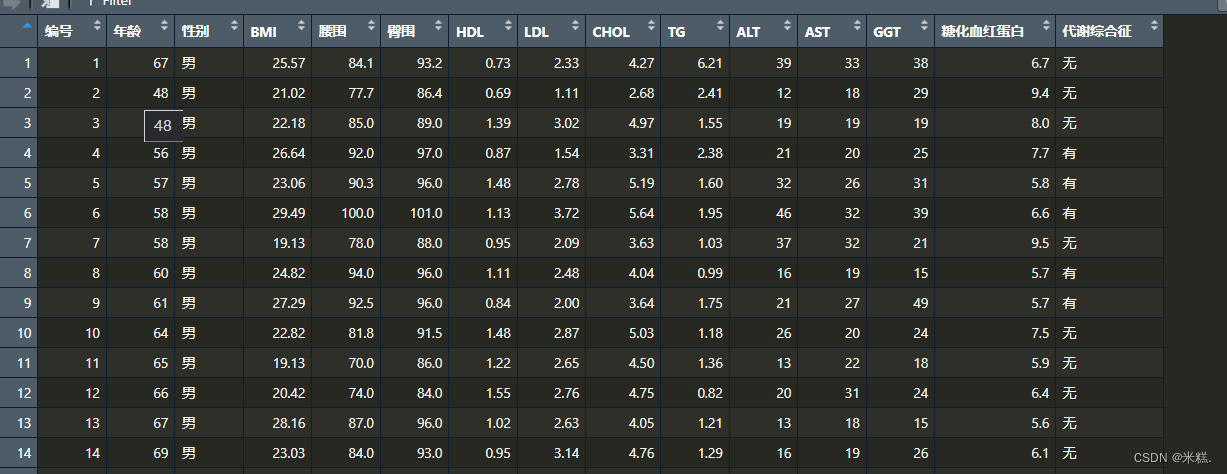
这个函数用于对连续型变量做一个整体的概述,比如数据框mydata如图所示
运行代码summary(mydata)结果如图

对于连续型变量summary给出了这个变量的最大最小值,中位数平均数等等信息,对于分类型变量则给出了各种类型有多少个。因此调用summary函数即可让我们对一组数据具有一个整体的了解。但是使用summary得到的结果很难转换成数据框或者矩阵这样的表格,因此再进行描述性统计分析的时候推荐使用describe函数。
describe函数
这个函数来自于R包: psych
describe这个函数对于分类型变量的描述可能会有一点点问题,因为我们发现直接给该函数传参为mydata结果如图

年龄居然有平均值58.21,因此这个函数并不适合用来处理分类型变量,那么我们再单独把那些连续型变量的列提取出来,运行代码
describe(mydata[,c(2,4:14)])
结果如图

使用变量ret把describe函数的运行结果存起来并且查看发现ret长这样
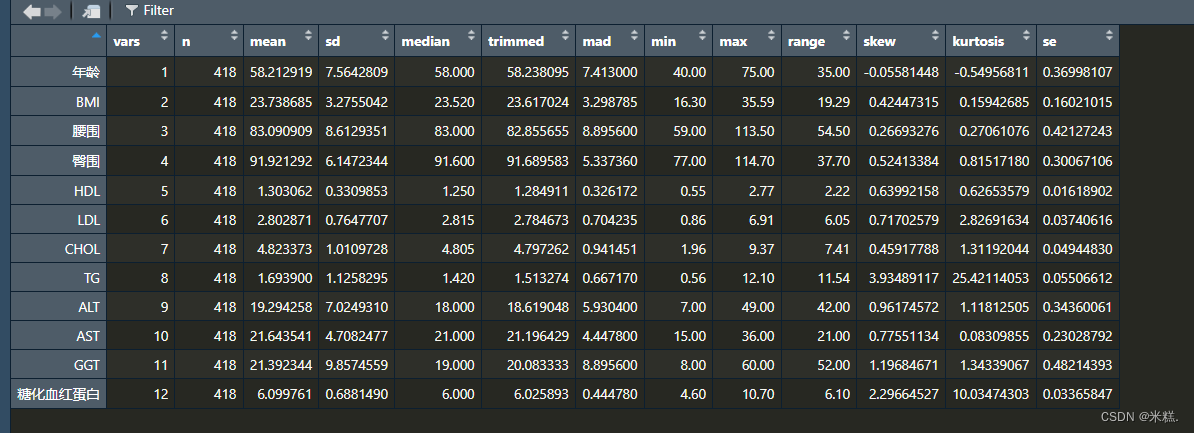
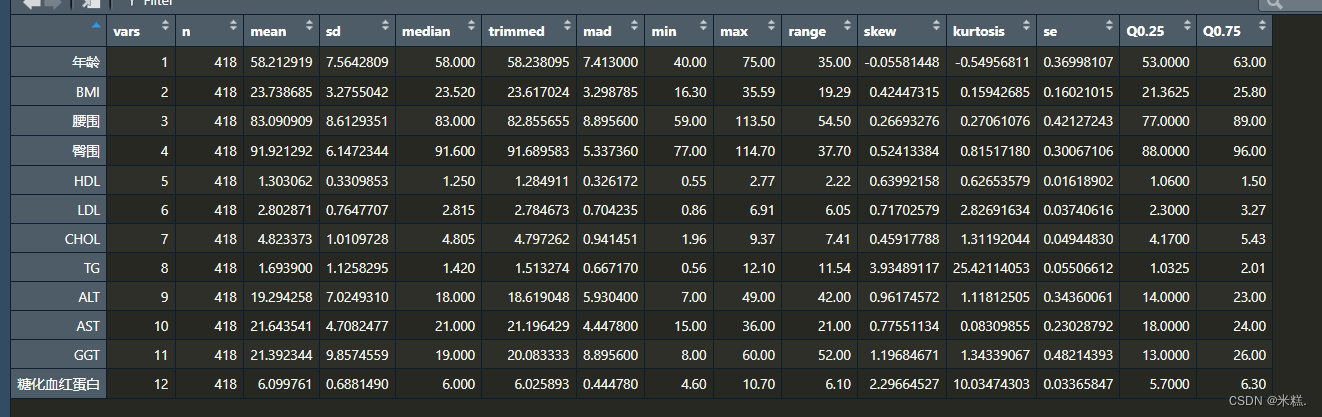
俨然是一个表格,可以方便的导出。当然我们发现describe函数默认并没有给出上下四分位点,但这并不是说该函数不能给出上下四分位点,只需要添加参数quant=c(.25,.75)即可完成任务,运行代码
ret
最终ret的结果如图
正态性检验的方法
样本量小于2000,使用函数shapiro.test(),p>0.05则服从正态分布
样本量大于2000,使用函数ks.test(x,"pnorm"),p>0.05则服从正态分布。其中第二个参数pnorm表示进行正态性检验
数据可视化
R语言中提供了丰富的绘图函数,这些函数要求的参数各不相同,但有一些通用的参数,这些参数可以控制图形的各种属性,如颜色、线条样式、字体大小等。以下是一些常用的通用图形参数:
- col:设置颜色。可以是颜色名称(如"red")、十六进制颜色代码(如"#FF0000")或RGB值。
- pch:设置点的类型。可以是数字(1-25),代表不同的点形状,或者是一个字符向量。
- lty:设置线条类型。可以是"solid"(实线)、"dashed"(虚线)、"dotted"(点线)等。
- lwd:设置线条宽度。数值越大,线条越粗。
- cex:设置字符大小扩展,影响文本、点和线条的大小。
- cex.axis:设置坐标轴标签的字符大小。
- cex.lab:设置图例标签的字符大小。
- cex.main:设置主标题的字符大小。
- font:设置字体。不同的数字代表不同的字体。
- family:设置字体族,可以是字体名称。
- bg:设置背景颜色,常用于设置点或多边形的填充色。
- xlab:设置x轴的标签。
- ylab:设置y轴的标签。
- main:设置图形的主标题。
- sub:设置图形的副标题。
- xlim:设置x轴的显示范围。
- ylim:设置y轴的显示范围。
- xaxs、yaxs:控制坐标轴的比例(如"i"表示等比例,"r"表示根据图形区域自动调整)。
- xaxt、yaxt:控制坐标轴的显示(如"n"表示不显示坐标轴)。
- log:对x或y轴进行对数变换。
- asp:设置y轴与x轴的比率。
- bty:设置图形边界框的类型。
- fg:设置前景色,常用于设置边框颜色。
- tck:设置坐标轴刻度的长度。
- tcl:设置坐标轴刻度标签的距离。
直方图
绘制直方图使用的函数是hist
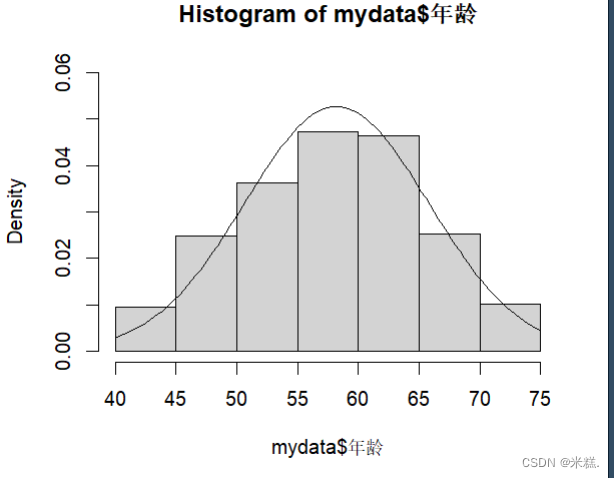
运行代码hist(mydata$年龄)即可得到这样一幅图
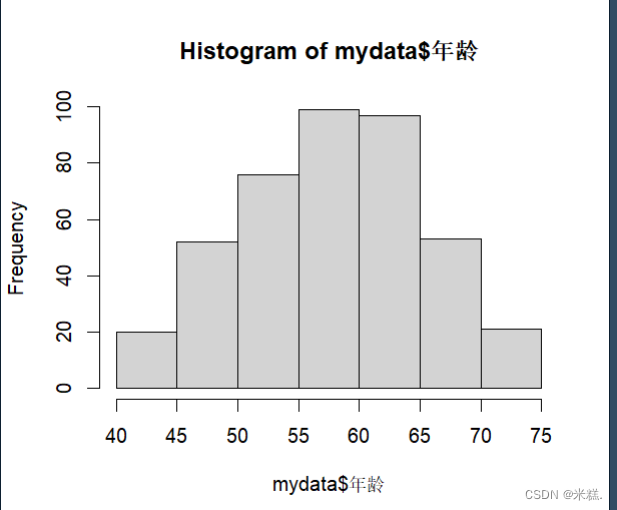
这个直方图的横坐标代表着一个个区间,纵坐标代表频数,比如40到45这个区间内又20个样本,45到50这个区间内又大约50个样本。显然这是一个频数直方图。而众所周知我们想要添加概率密度曲线只能添加在频率直方图中,实际上hist函数也可以用来绘制频率直方图,只需要在刚才代码中添加一个参数freq=FALSE即可。
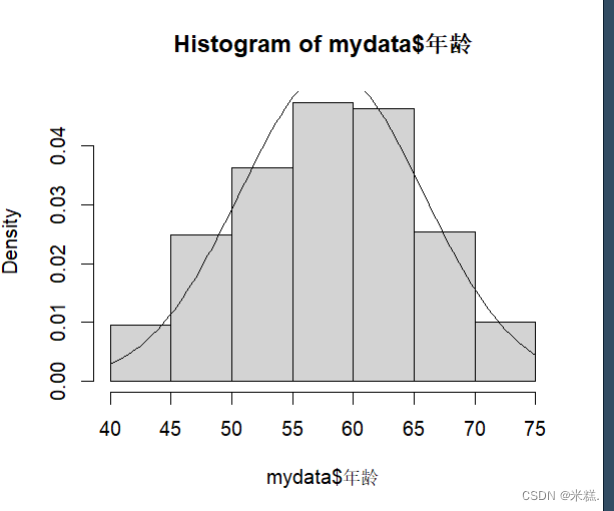
运行代码hist(mydata$年龄,freq = FALSE),结果如图

添加概率密度曲线使用的函数是curve,运行代码
curve(dnorm(x,mean=mean(mydata$年龄),sd=sd(mydata$年龄)),add = T)
其中在curve内部调用了dnorm函数,这个函数用于计算正态分布的概率密度函数,其内部的参数x表示正态分布的取值点,这个参数是固定的,就是用x表示,然后mean和sd指定了该分布的均值和方差,因此dnorm函数的调用结果是一个表达式,细说就是均值为mean(mydata$年龄),方差为sd(mydata$年龄)的概率密度函数表达式,curve函数需要的参数就是这样的一个表达式,他会根据这个表达式来绘制这个表达式的图像,参数add=T表示绘制的图形将会添加在当前画板中,而不是另外开一块画板。
结果如图
我们还发现了一个问题就是,这个纵坐标好像有点不够用,画的图都已经超出去了,这个问题可以通过hist函数中的参数ylim来控制。比如运行代码
hist(mydata$年龄,freq = FALSE,ylim=c(0,0.06)),此时的图像就变成了这样

再运行代码
curve(dnorm(x,mean=mean(mydata$年龄),sd=sd(mydata$年龄)),add = T)把概率密度曲线添加进去