文献来源:Pluye, Pierre, and Quan Nha Hong. "Combining the power of stories and the power of numbers: mixed methods research and mixed studies reviews." Annual review of public health 35 (2014): 29-45.
文献获取:链接:https://pan.baidu.com/s/1mZSDwrWDcvQAgcrEoPCTEQ
提取码:6lh7
一、为什么使用混合研究方法?
混合方法用于结合定量和定性方法的优点,并弥补它们的局限性。我们提供了混合方法的三个主要原因。首先,研究人员可能需要定性方法来解释定量结果。其次,他们可能需要定量的方法来概括定性的发现。第三,他们可能同时需要两种方法来更好地理解一种新现象(定性方法)和测量其大小、趋势、原因和影响(定量方法)。在表1中,我们列出了可能以混合方法的形式组合的常见定性和定量方法的列表。

二、定性与定量:两种相互竞争的范式
理想类型是马克斯·韦伯(1988)提出的一种分析工具,指的是“理念”的概念。理想类型是一种社会现象的典型特征的集合。主要的两种理想类型及其特征是(a)逻辑经验主义(唯物主义、现实主义和客观论证),通常与定量方法有关;(b)建构主义(唯心主义、相对主义和主观论证),通常与定性方法有关。
(一)逻辑经验主义
一方面,逻辑经验主义是指根据经验规律对现象进行研究,如流行/发病率描述性研究,或对关键因素(自变量)与结果(因变量)之间关联的可能性/显著性进行分析研究。
具体来说,因果因素-结果关系说明了这些经验法则。逻辑经验主义起源于19世纪的实证主义,并整合了20世纪的后实证主义批判。逻辑经验主义者通常(虽然不一定)提出,经验法则是由一个先于研究过程的理论(演绎或验证方法)提供的。例如,逻辑经验主义者可能假设(尽管并非总是如此),如果没有事先通过逻辑科学解释对经验领域进行规范组织,就不能建立因果关系。因此,对因果关系的研究基于使用因果关系(根据逻辑经验主义的科学语言)制定的假设。
(二)建构主义
另一方面,建构主义指的是对复杂现象的探索。通过解释过程,研究结果被语境化,这有助于研究者更好地理解这些现象。建构主义者通常(虽然不一定)在没有现有模型的情况下提出一个理论模型(归纳或探索方法)。例如,建构主义者可能会假设(虽然并不总是)在数据收集之前没有必要形成理论,因为理论将从数据中产生(有根据的理论)。建构主义源于20世纪20年代社会学先驱们发展的综合研究方法。建构主义定性研究者强调现实的社会建构本质的重要性。它们强调了研究者、被研究的现象和背景之间的亲密关系(21)。他们根据文化、经济和社会背景探索现象的历史、解释和叙事方面(1)。
定性方法也随之在几个学科中发展起来,并使用不同的解释程序(例如,人类学中的民族志和社会学中的民族方法)。这些知识对于计划、实施、评估和维持项目是有用的。具体而言,定性研究提供了实证研究结果,以解释在不同的实施环境中,项目的效果为何以及如何变化。然而,定性方法受到了批评,因为结果可能特定于特定环境(知识不能转移到另一个环境),或者可能基于无法复制或验证的隐性解释程序。
(三)总结
这两种理想类型(定量研究的逻辑经验主义和定性研究的建构主义)有助于从三个方面为混合方法研究提供概念基础。
首先,每种类型都可能与混合方法研究相关联。例如,定性发现经常被整合到检验因果关系的研究中,在那里它们被认为是产生理论或假设的科学有效论据(后实证主义)。Campbell认为,需要进行定性研究评估,为进一步的实验或准实验定量研究提出可信的竞争性假设。其次,在混合方法研究团队中工作可能需要一些方法上的开放性和对话来解决成员之间的紧张关系。在这样的团队中工作时,研究人员可能会认同不同的世界观:一些成员可能认同逻辑经验主义,而另一些成员可能认同建构主义。在研究过程的所有阶段可能都需要缓和紧张局势:制定问题/方案(规划),收集/分析数据(实施),解释/呈现结果(传播)。第三,除了这两种理想类型之外,其他认识论与混合方法研究有关,包括实用主义、建构主义、批判理论和批判现实主义。事实上,多种认识论可以与混合方法研究相关联,这表明混合方法有可能成为一种独特的方法。
三、混合方法研究
(一)混合研究方法界定
任何方法组合视为混合方法研究(MM),当它满足所有三个条件时:
(a)至少有一种定性方法(QUAL)和一种定量方法(QUAN)相结合;
(b)严格使用每种方法;
(c)整合数据收集、和/或数据分析和/或结果。
我们声称以下五种类型的方法不是MM。首先,任何收集或分析QUAL数据的QUAN方法,如果不遵循严格的QUAL方法,就不是MM。例如,使用自我管理的问卷调查,以可选的自由评论结尾,就不是MM;在这种情况下,研究人员无法解释为什么有些人会(或不)提供评论,也无法与参与者互动,通过额外的反思、观察和文件来丰富或解释评论。其次,任何收集或分析QUAN数据而没有遵循严格的QUAN设计的QUAL方法都不是MM。第三,QUAN方法的组合不是MM。第四,QUAL方法的组合也不是MM。第五,没有整合数据收集、数据分析或结果的QUAL和QUAN方法并置不是MM。
(二)混合研究设计
常见的MM分类基于三种关键类型的研究设计,每一种都反映了QUAN和QUAL方法的一种集成。
1. 顺序探索性MM设计:QUAL方法之后是QUAN方法。
在整合方面,qal的发现为全权方法提供了信息;然后,利用QUAN结果来确认和推广QUAL结果。
2. 顺序解释性MM设计:QUAN方法之后是QUAL方法。
在集成方面,QUAN的结果为QUAL方法提供信息;然后,利用质量评估结果来解释全质量评估结果。
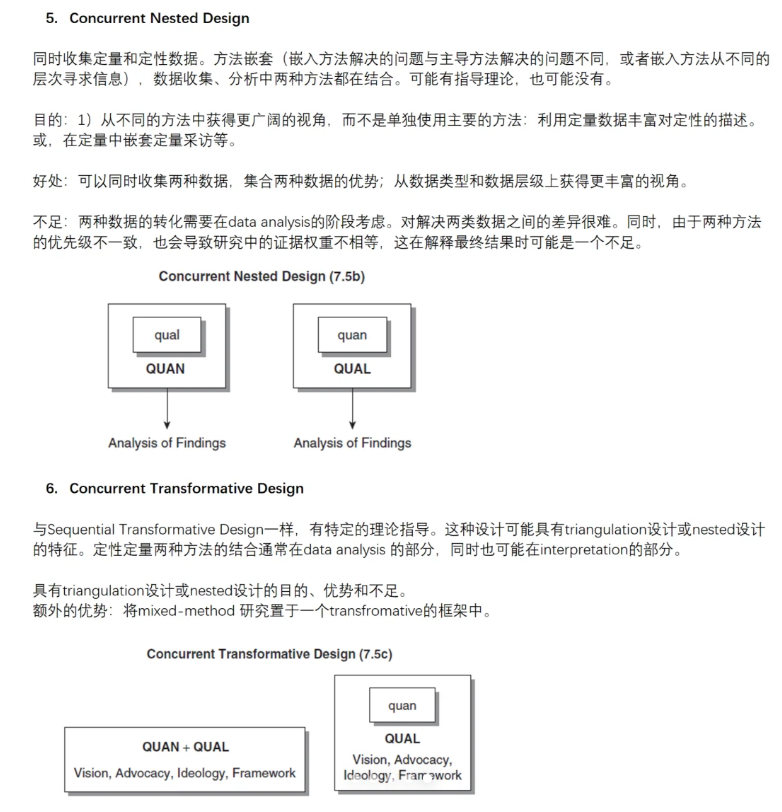
3. 趋同MM设计:QUAN和QUAL方法在数据收集或数据分析中是互补的,或两者兼而有之。整合发生在收集或分析,或收集和分析QUAN和QUAL数据期间。

(三)混合研究技术
研究人员可以在MM中任意组合使用QUAL和QUAN数据收集和分析技术。Bryman对社会科学中报道MM研究的232篇文章进行了文献综述。他总结道,MM研究中最常用的数据收集技术如下(按字母顺序排列):文献回顾、焦点小组、个人访谈、参与者观察和问卷调查。最常用的数据分析技术如下(按字母顺序排列):QUAL专题分析、QUAN内容分析和统计分析。
为了描述上述MM设计和技术在公共卫生中的应用,我们对该领域的MM研究进行了概述。我们在Medline进行了探索性搜索(直到2012年11月),使用以下搜索策略:(混合形容词方法$)。仅限于英语或法语,仅限于人类。通过搜索,我们确定了114项公共卫生领域原发性MM研究的样本(参考文献列表可根据要求提供)。我们根据MM设计的三种主要类型对这些研究进行分类。最常见的设计是收敛型(n = 63)。48项研究为序贯研究:序贯解释设计(n = 36)和序贯探索性设计(n = 12)。另外三项研究采用了多相设计。最常报道的数据收集技术是半结构化或非结构化访谈(n = 88)、焦点小组(n = 48)和调查问卷(n = 47)。在表2中,我们按设计类型列出了不同的数据收集技术。

四、混合研究综述
系统混合研究综述遵循七个标准的系统综述步骤:(a)撰写综述问题(或qualal和QUAN问题);(b)确定资格标准;(c)在多个信息源中采用广泛的搜索策略;(d)确定潜在的相关研究(两名研究人员独立筛选标题和摘要);(e)选择有关研究(以全文为基础);(f)评估纳入研究的质量(使用MMAT等工具);(g)综合纳入的研究。
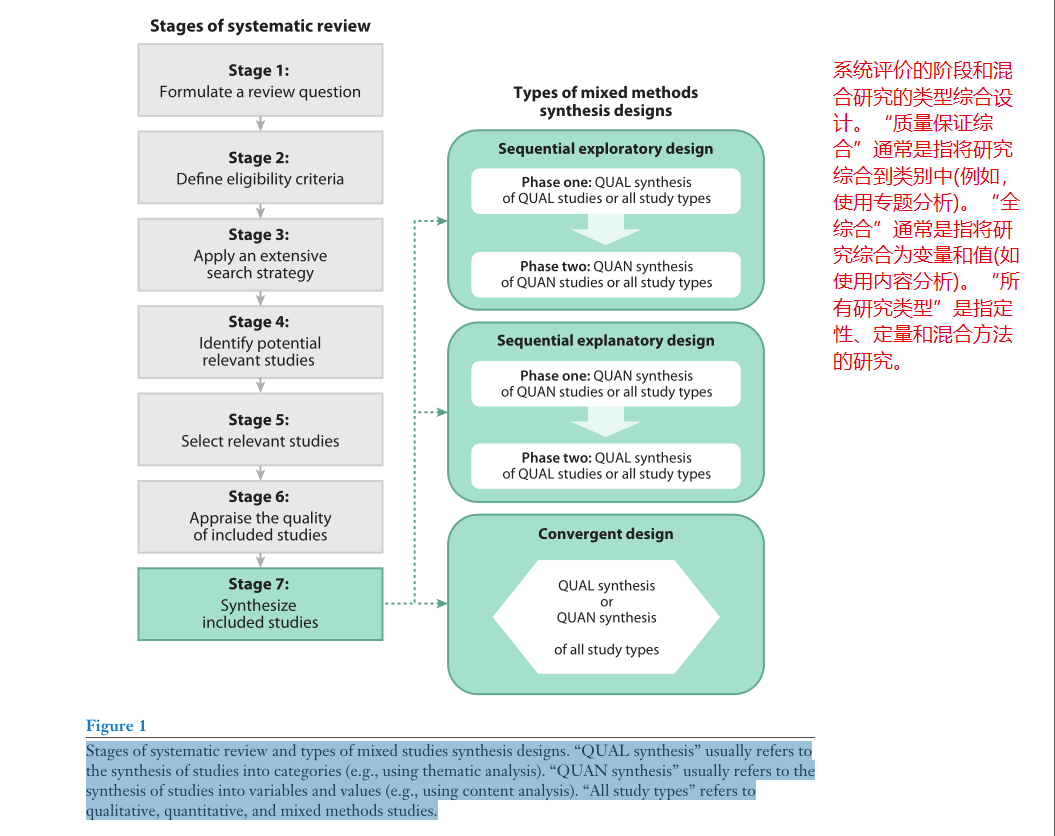
系统评审包括专业图书馆员(如步骤b-c)和至少两名独立工作的研究人员,以评估评审过程的可靠性(如步骤d-f)。按照这些步骤,我们提出了一个Wiki来帮助研究生和研究人员设计、进行和报告系统的混合研究综述(http://toolkit4mixedstudiesreviews.pbworks.com)。这个Wiki包括综述问题的例子,搜索不同设计的研究的提示,关键的评估工具,综合设计的主要类型,以及报告此类综述的建议模板(该Wiki旨在帮助培训研究人员进行混合研究综述)。进行混合研究综述的主要理由是为了更好地理解复杂的干预措施、项目和现象。一个典型的混合研究回顾问题是,“定性和定量证据告诉我们关于……的什么?”根据MM研究的定义,我们将系统混合研究综述定义为一种文献综述,在这种文献综述中,评审者团队识别、选择、评价和综合QUAL、QUAN和MM研究。在综合阶段,数据来源包括报告纳入研究的qualal结果和QUAN结果的文件。在过去十年中,已经开发了几种综合QUAN和QUAL数据源的技术,如贝叶斯综合、政策和实践信息证据(EPPI)综合、叙事综合、现实主义综合和专题分析(6,22,47,58,70,77)。Heyvaert等人(35)提出了一个对混合研究综述进行分类的框架。他们开发了一个基于三个维度的18个设计框架:强调QUAL或QUAN方法(即,平等或主导地位),集成类型(即,顺序或收敛),以及集成水平(即,部分或完全集成)。根据上述三种主要的MM研究设计类型,我们提出以下混合研究综合设计分类:顺序探索性、顺序解释性和收敛性(图1)。每种综合设计如下。
(一)顺序探索性综合
对于这种类型的合成设计,(a) QUAL合成之后是QUAN合成,并通知QUAN合成;和(b) QUAN综合总结或检验qualal综合的发现。这两个阶段是连续的:第一阶段质量评估是解释第二阶段质量评估结果的必要条件。在第一阶段的质量评估中,例如,使用质量评估专题分析,将质量评估、全权研究和MM研究的结果转化为质量评估结果(例如,研究结果的分类)。
在第二阶段QUAN中,当研究之间存在共同变量(例如,一种共同类型的研究结果)时,将QUAN研究的结果和MM研究的QUAN结果制成表格并进行比较。然后,对第一阶段和第二阶段结果的解释提出了新的假设,并揭示了知识差距。例如,顺序探索性综合的目的可以是开发一种类型(第一阶段质量评估)并测量每种类型的可用指标(第二阶段质量评估)。
Pluye等人(67)和Mills等人(49)提供了例子。例如,Mills等人提出的问题涉及癌症患者参与临床试验的障碍(第一阶段质量评估),以及这些障碍的频率(第二阶段质量评估)。并非所有已确定障碍的频率都可用,这揭示了知识差距(有待在未来研究中测量的障碍)。
(二)顺序解释性综合
对于这种类型的合成设计,(a) QUAN合成之后是QUAL合成,并通知QUAL合成;(b) qal综合有助于解释QUAN综合的一些结果。这两个阶段是连续的:第一阶段QUAN是解释第二阶段QUAL结果所必需的。例如,在第一阶段QUAN中,QUAN研究的结果和混合方法研究的QUAN结果汇集在证据表中,并且可以测量效果差异的存在和重要性(例如,在适当时使用荟萃分析技术)。例如,在第二阶段的质量评估中,使用质量评估专题分析将质量评估研究的结果和MM研究的质量评估结果结合起来。对第一阶段和第二阶段结果的解释揭示了新的解释并揭示了知识差距。例如,顺序解释性综合的目的可以是衡量公共卫生项目的效果(第一阶段全质量评价),并解释效果差异(第二阶段全质量评价)。
Harden等人(34)和Thomas等人(84)给出了这种合成设计的例子。例如,Thomas等人在混合研究综述中提出的问题是,“对于4-10岁儿童健康饮食的障碍和促进因素,我们知道什么?”(84,第1010页)。在第一阶段QUAN中,他们系统地回顾了衡量公共卫生干预措施对儿童健康饮食有效性的随机对照试验,然后进行了荟萃分析,最后得出结论:“试验中描述的干预措施能够使儿童每天的水果和蔬菜摄入量增加约半份”(84,p. 1011)。在第二阶段的质量评估中,他们综合了关于儿童对健康饮食意义感知的质量评估研究结果(使用质量评估专题数据分析),并根据儿童的观点提出了健康饮食的障碍和促进因素。随后,他们将这些障碍和促进因素与随机对照试验中评估的干预措施进行了比较,问题包括“哪些干预措施符合来自儿童观点和经验的建议?”以及“哪些建议尚未在经过合理评估的干预措施中加以尝试”?(84,第1011页)。他们得出的结论是,两种最好的干预措施每天增加的蔬菜摄入量超过了0.4份,而且只有这两种干预措施符合孩子们的观点。
(三)收敛合成法
在收敛综合设计中,纳入研究的结果使用数据转换技术进行整合:QUAL或QUAN转换。在趋同的qualal综合设计中,包括qualal、QUAN和MM的研究结果转化为qualal结果。在收敛全权综合设计中,将它们转化为变量。下面介绍了与这些合成设计相关的方法。
收敛质量综合。收敛质量综合解决研究问题,如什么,如何,为什么。为了解决这些问题,包括qualal、QUAN和MM在内的研究结果被转化为qualal的发现,如主题、配置、理论、概念和模式。最常见的数据转换技术是QUAL主题合成。更复杂的数据转换方法有现实主义综合理论驱动的公共卫生干预措施和项目评估)、批判性解释综合(构建新理论)、元叙事综合(建立概念)和多案例综合(寻找跨案例研究的模式)。这些类型的趋同qualal综合设计有助于解决特定的公共卫生审查问题。
收敛QUAN综合。收敛的QUAN合成仍然很少见。全要素综合可以解决全要素公共卫生研究的典型问题,包括问题或危险因素的发生率和/或流行程度,以及因素与结果之间关联的可能性和重要性。为了解决这些问题,我们将纳入的QUAL、QUAN和MM研究的结果转化为变量。最常见的数据转换技术是允许进一步统计分析的内容分析。其他类型的数据转换包括配置比较方法(布尔代数)和贝叶斯合成(概率)。
五、混合研究总结
为了描述混合研究综合设计的使用,我们进行了混合研究综述。我们在Scopus和Medline数据库中进行了探索性检索(截至2012年9月),使用以下搜索策略:(定量和定性)或(混合形容词方法)或(多形容词方法))。并限制审查。本研究确定了29个混合研究综述的样本,其中11个被保留,因为它们遵循了系统综述的七个阶段,并且对合成技术有清晰的描述。然后,我们根据混合研究综合设计的三种类型对系统综述进行分类。在我们的样本中发现的最常见的合成类型是收敛型(n = 8),其中7种是QUAL和1种QUAN。其他三个混合研究综述是顺序的,其中两个使用顺序探索性综合(67,76),一个使用顺序解释性综合。经常使用qualal主题综合(n = 8)。我们没有发现报告混合研究综述的建议,如系统评价,除了现实主义和元叙事qualal综合的具体初步出版标准。
六、图解
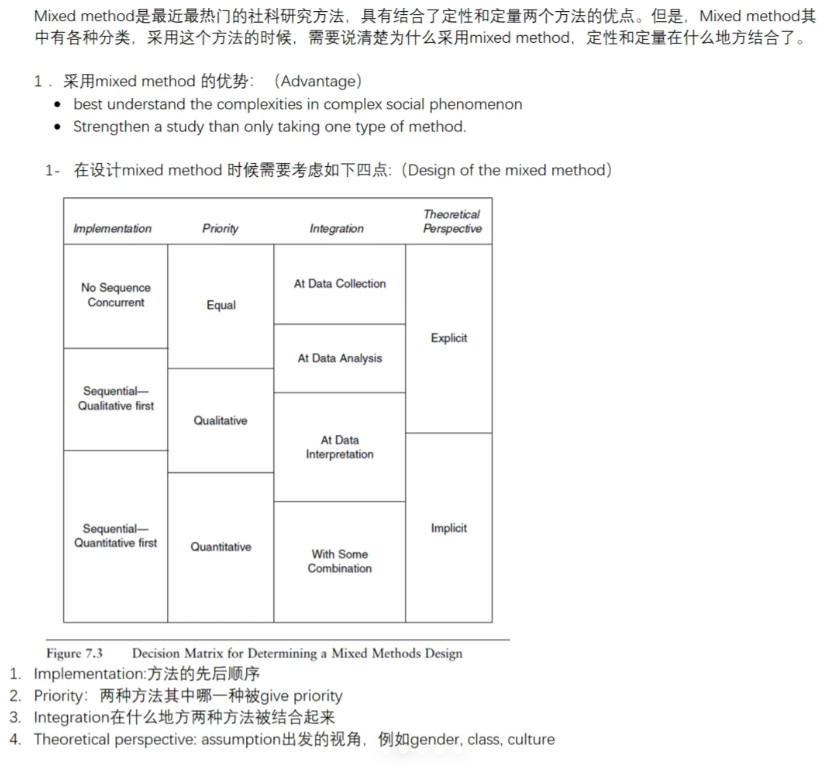
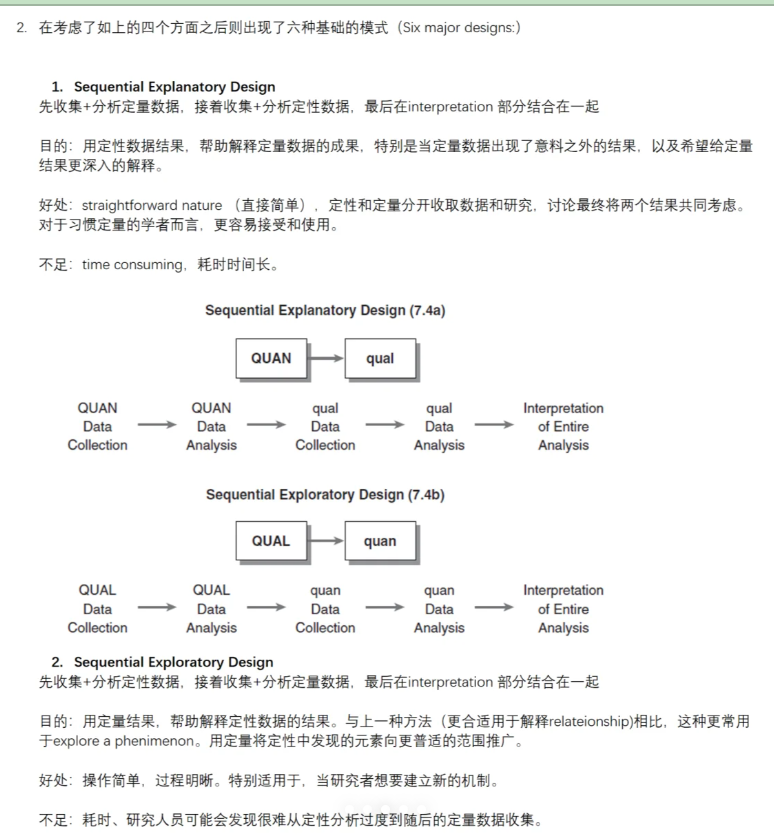
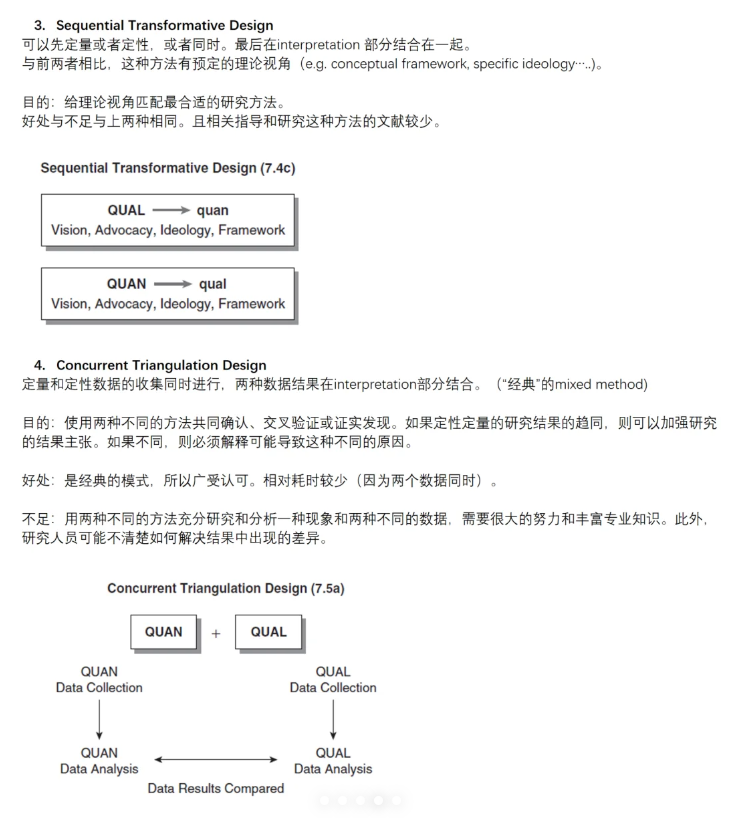






![C++静态数组和C语言静态数组的区别( array,int a[])](https://img-blog.csdnimg.cn/direct/b5081660510144898787447195b9ac79.png)


