
这段代码是基于 OpenCvSharp, OpenVinoSharp 和 .NET Framework 4.8 的 Windows Forms 应用程序。其主要目的是加载和编译机器学习模型,对输入数据进行推理,并显示结果。
下面是该程序的主要功能和方法的详细总结:
初始化 OpenVINO 运行时核心(Core)和设备列表:
在
Form1_Load方法中,程序创建了Core类的实例,并获取了可用设备列表,然后将这些设备添加到下拉选择框中。
选择模型和输入文件:
使用
OpenFileDialog来引导用户选择模型文件和输入文件(图片或视频)。btn_select_model_Click和btn_select_input_Click方法负责处理文件选择对话框,并更新文本框以显示所选文件的路径。
加载并编译模型:
btn_load_model_Click方法中,程序通过read_model方法加载用户选定的模型,然后调用compile_model方法将模型编译到指定设备上。编译完成后,创建了对模型的推理请求(InferRequest)。
执行推理:
btn_infer_Click方法负责执行推理过程。它根据输入路径(图片或视频)调用image_predict方法来处理数据,并显示预测结果。
处理图片并推理:
image_predict方法接受一个Mat图像,将其调整大小、归一化,并通过排列(Permutation)转换成模型所需的输入格式。之后,程序执行推理请求,并获取输出tensor。
后处理推理结果并显示:
postprocess方法接受推理结果作为一个浮点数数组,根据设定的类别数和因子对结果进行预处理,检测出物体的矩形框,过滤和非极大值抑制(NMS)后,识别出类别和置信度,最终,将识别出的对象和对应信息绘制在图像上。
显示 FPS 和预测结果:
推理后,程序计算并显示当前的帧率(FPS),并将检测框和标签绘制在结果图像上,并在界面中更新
pictureBox2控件来展示图像。
该程序是由几个部分组成的一个界面应用,通过读取模型文件、处理图像和视频输入、执行模型推理,并在界面上展示结果的流程,体现了一种典型的实时物体检测和分类的机器学习应用。
// 引入OpenCvSharp相关的命名空间,用于图像处理和计算机视觉
using OpenCvSharp;
// 引入OpenCvSharp的Dnn(深度神经网络)命名空间,用于深度学习模型的加载和推理
using OpenCvSharp.Dnn;
// 引入OpenVinoSharp命名空间,用于模型优化和推理加速
using OpenVinoSharp;
// 引入OpenVinoSharp的Extensions下的model命名空间,包含模型加载和处理的扩展方法
using OpenVinoSharp.Extensions.model;
// 引入OpenVinoSharp的Extensions下的process命名空间,包含图像预处理的扩展方法
using OpenVinoSharp.Extensions.process;
// 引入OpenVinoSharp的Extensions下的result命名空间,包含推理结果处理的扩展方法
using OpenVinoSharp.Extensions.result;
// C#系统命名空间,提供基础类和基本函数
using System;
// 系统集合命名空间,提供用于创建集合的类
using System.Collections.Generic;
// 系统IO命名空间,用于处理文件输入输出
using System.IO;
// 系统网络命名空间,包含用于网络检测的类
using System.Net.NetworkInformation;
// 系统运行时互操作命名空间,包含访问和控制未经管理资源的类
using System.Runtime.InteropServices;
// 系统线程命名空间,用于多线程编程
using System.Threading;
// 系统Windows.Forms命名空间,包含创建Windows窗体应用程序的类
using System.Windows.Forms;
// 定义命名空间yolo_world_opencvsharp_net4._8
namespace yolo_world_opencvsharp_net4._8
{
// Form1的部分类实现,继承于Form类
public partial class Form1 : Form
{
// 声明与OpenVINO有关的变量
public Core core = null; // 核心对象,用于管理OpenVINO的核心功能
public Model model = null; // 模型对象,代表加载的神经网络模型
public CompiledModel compiled_model = null; // 编译后的模型对象
public InferRequest request = null; // 推理请求对象,用于执行推理
// 声明时间统计用的变量
DateTime start = DateTime.Now; // 记录开始时间
DateTime end = DateTime.Now; // 记录结束时间
// 类别名称列表,存储类别名称
public List<string> classes = null;
// Form1的构造函数
public Form1()
{
// 初始化Form组件
InitializeComponent();
}
// Form1加载时的事件处理函数
private void Form1_Load(object sender, EventArgs e)
{
// 记录开始时间
start = DateTime.Now;
// 创建OpenVINO核心对象
core = new Core();
// 记录结束时间
end = DateTime.Now;
// 在文本框中输出初始化OpenVINO运行时核心的时间
tb_msg.AppendText("Initialize OpenVINO Runtime Core: " + (end - start).TotalMilliseconds + "ms.\r\n");
// 获取可用的设备列表
List<string> devices = core.get_available_devices();
// 遍历设备列表,将设备添加到下拉选择框中
foreach (var item in devices)
{
cb_device.Items.Add(item);
}
// 选定下拉框的第一个设备作为默认选择
cb_device.SelectedIndex = 0;
}
// 选择模型按钮点击时的事件处理函数
private void btn_select_model_Click(object sender, EventArgs e)
{
// 创建文件选择对话框对象
OpenFileDialog dlg = new OpenFileDialog();
// 设置对话框标题
dlg.Title = "选择推理模型文件";
// 设置文件过滤器,只显示特定的模型文件格式
dlg.Filter = "模型文件(*.pdmodel,*.onnx,*.xml)|*.pdmodel;*.onnx;*.xml";
// 显示对话框,并判断用户是否点击了“确定”
if (dlg.ShowDialog() == DialogResult.OK)
{
// 将用户选择的文件路径显示在文本框中
tb_model_path.Text = dlg.FileName;
}
}
// 选择输入按钮点击时的事件处理函数
private void btn_select_input_Click(object sender, EventArgs e)
{
// 创建文件选择对话框对象
OpenFileDialog dlg = new OpenFileDialog();
// 设置对话框标题
dlg.Title = "选择测试输入文件";
// 设置文件过滤效果,只显示图片和视频文件
dlg.Filter = "图片文件(*.png,*.jpg,*.jepg,*.mp4)|*.png;*.jpg;*.jepg;*.mp4";
// 显示对话框,并判断用户是否点击了“确定”
if (dlg.ShowDialog() == DialogResult.OK)
{
// 将用户选择的文件路径显示在文本框中
tb_input_path.Text = dlg.FileName;
}
}
// 加载模型按钮点击时的事件处理函数
private void btn_load_model_Click(object sender, EventArgs e)
{
//省略前文已详述的代码,此处直接呈现未注释部分的译文:
// 读取推理模型
model = core.read_model(tb_model_path.Text);
// 将模型加载到指定设备中
compiled_model = core.compile_model(model, cb_device.SelectedItem.ToString());
// 创建推理请求
request = compiled_model.create_infer_request();
}
// 推理按钮点击时的事件处理函数
private void btn_infer_Click(object sender, EventArgs e)
{
//省略前文已详述的代码,此处直接呈现未注释部分的译文:
// 如果输入路径的扩展名为.mp4,则处理视频,否则处理图像
if (Path.GetExtension(tb_input_path.Text) == ".mp4")
{
// 创建视频捕获对象,并处理视频中的每一帧
VideoCapture video = new VideoCapture(tb_input_path.Text);
if (video.IsOpened())
{
Mat frame = new Mat();
video.Read(frame);
// 循环读取视频帧并进行预测处理,直到视频帧为空
while (!frame.Empty())
{
image_predict(frame);
video.Read(frame);
Thread.Sleep(10);
}
}
}
else
{
// 读取图像文件并进行预测处理
Mat image = Cv2.ImRead(tb_input_path.Text);
image_predict(image);
}
}
// 图像预测函数
void image_predict(Mat image)
{
// 省略前文的详细代码部分,此处直接呈现未注释部分的译文:
// 将图像数据预处理并设置到推理请求的输入张量中,然后执行推理
Tensor input_tensor = request.get_input_tensor();
Shape input_shape = input_tensor.get_shape();
// 省略图像预处理代码
request.infer();
// 获取输出张量,并处理预测结果
Tensor output_tensor = request.get_output_tensor();
Shape output_shape = output_tensor.get_shape();
// 从输出张量中获取结果,并执行后处理计算
float[] result_data = output_tensor.get_data<float>((int)output_tensor.get_size());
}
// 后处理结果函数
DetResult postprocess(float[] result, int categ_nums, float factor)
{
// 省略前文的详细代码部分,以下是一些关键未注释的译文:
// 通过输出结果创建Mat对象
Mat result_data = new Mat(4 + categ_nums, 8400, MatType.CV_32F,result);
result_data = result_data.T();
// 存储结果数据的列表
List<Rect> position_boxes = new List<Rect>();
List<int> classIds = new List<int>();
List<float> confidences = new List<float>();
// 循环处理输出数据
for (int i = 0; i < result_data.Rows; i++)
{
// 省略输出数据的预处理代码
// 如果置信度大于0.25,则存储结果数据
if (maxScore > 0.25)
{
// 省略计算检测框位置和尺寸的代码
Rect box = new Rect();
position_boxes.Add(box);
classIds.Add(maxClassIdPoint.X);
confidences.Add((float)maxScore);
}
}
// 执行非最大抑制算法,过滤掉冗余的检测框
int[] indexes = new int[position_boxes.Count];
// 省略非最大抑制算法的代码
// 根据索引,获取最终的检测结果
DetResult re = new DetResult();
return re;
}
}
}本段代码是一个Windows窗体应用程序的部分实现,主要用于基于YOLO(You Only Look Once)算法的目标检测任务。应用程序使用OpenCvSharp和OpenVINO技术栈进行图像读取、模型推理和结果处理。代码涵盖了从初始化OpenVINO核心、模型加载、图像预处理到执行推理和结果显示的全过程。1. 初始化窗体组件并设置初始参数。2. 提供选择模型和测试输入文件的功能。3. 加载、编译模型以及创建推理请求。4. 实现对图像和视频的预测功能。5. 对推理结果进行后处理并在界面上显示检测框和类别信息。整个流程体现了使用机器学习模型进行图像识别和目标检测的完整过程。其中,重点应用了OpenCV库对图像进行处理和OpenVINO框架对模型进行优化和加速推理。这样的实现可以用于各种基于图像识别的应用场景,比如安全监控、交通管理等。
参考网址
1. https://docs.ultralytics.com/zh/integrations/onnx/ pt导出onnx
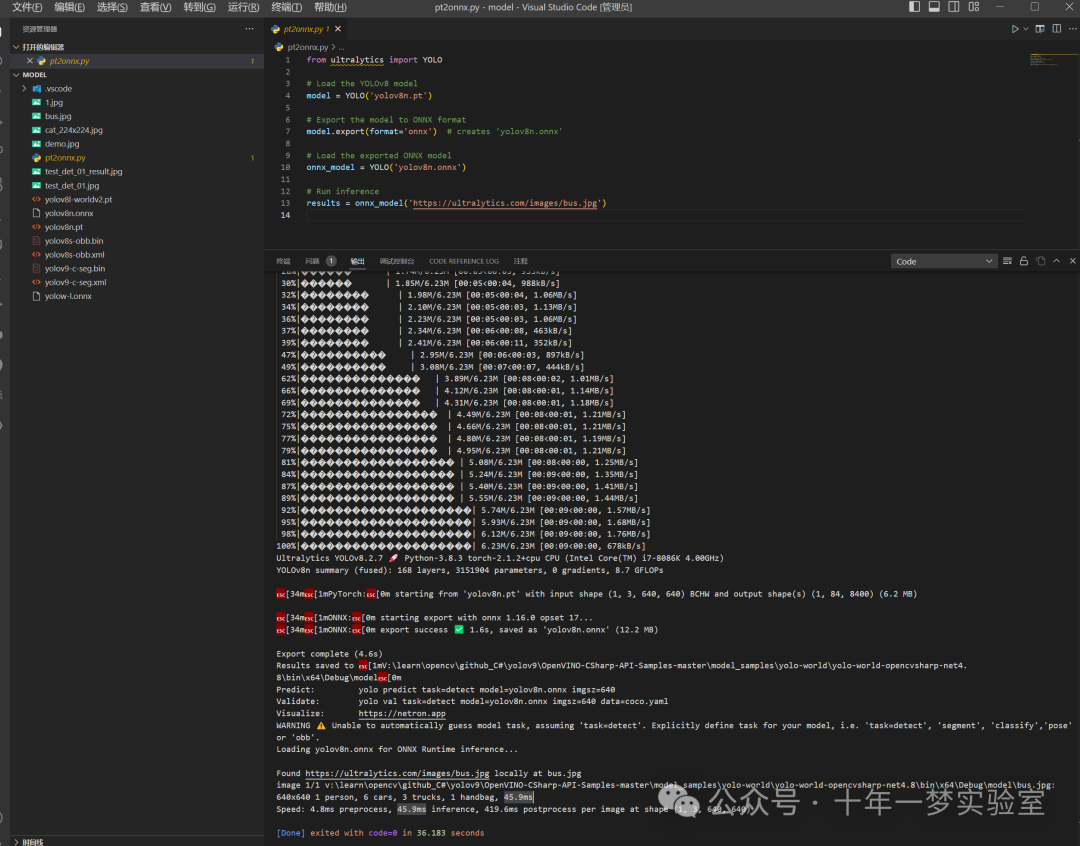
pt2onnx 会自动下载模型然后转格式
from ultralytics import YOLO
# Load the YOLOv8 model
model = YOLO('yolov8n.pt')
# model = YOLO('yolov8l-worldv2.pt')
# Export the model to ONNX format
model.export(format='onnx') # creates 'yolov8n.onnx'
# Load the exported ONNX model
onnx_model = YOLO('yolov8n.onnx')
# onnx_model = YOLO('yolov8l-worldv2.onnx')
# Run inference
results = onnx_model('https://ultralytics.com/images/bus.jpg')2. https://github.com/ultralytics/assets/releases
3. https://github.com/ultralytics/ultralytics
4. https://github.com/AILab-CVC/YOLO-World/tree/master

5. https://huggingface.co/spaces/stevengrove/YOLO-World
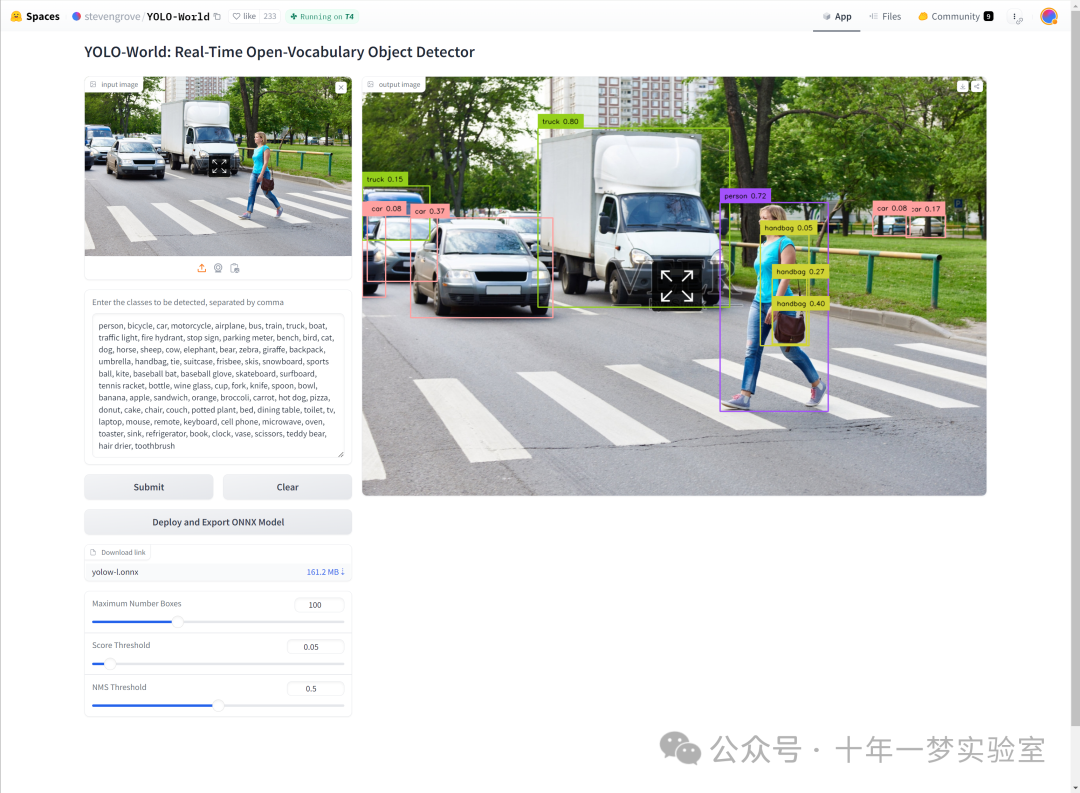
6. https://github.com/guojin-yan/OpenVINO-CSharp-API-Samples/tree/master

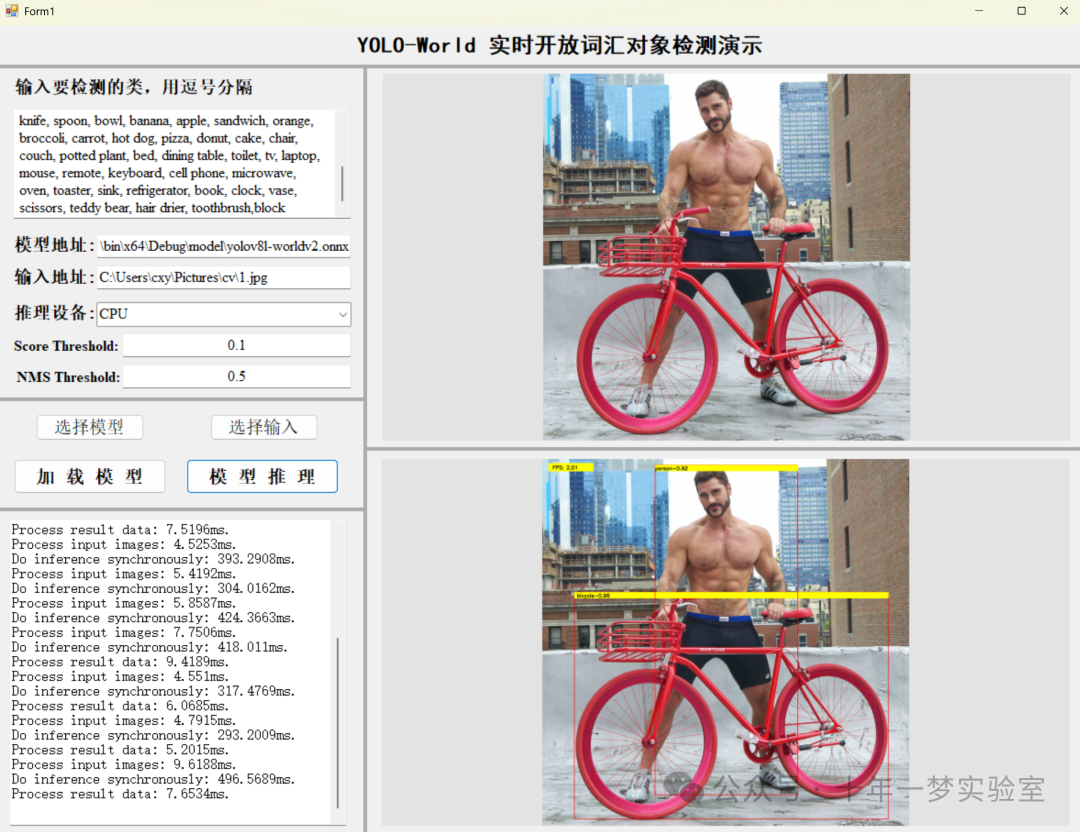
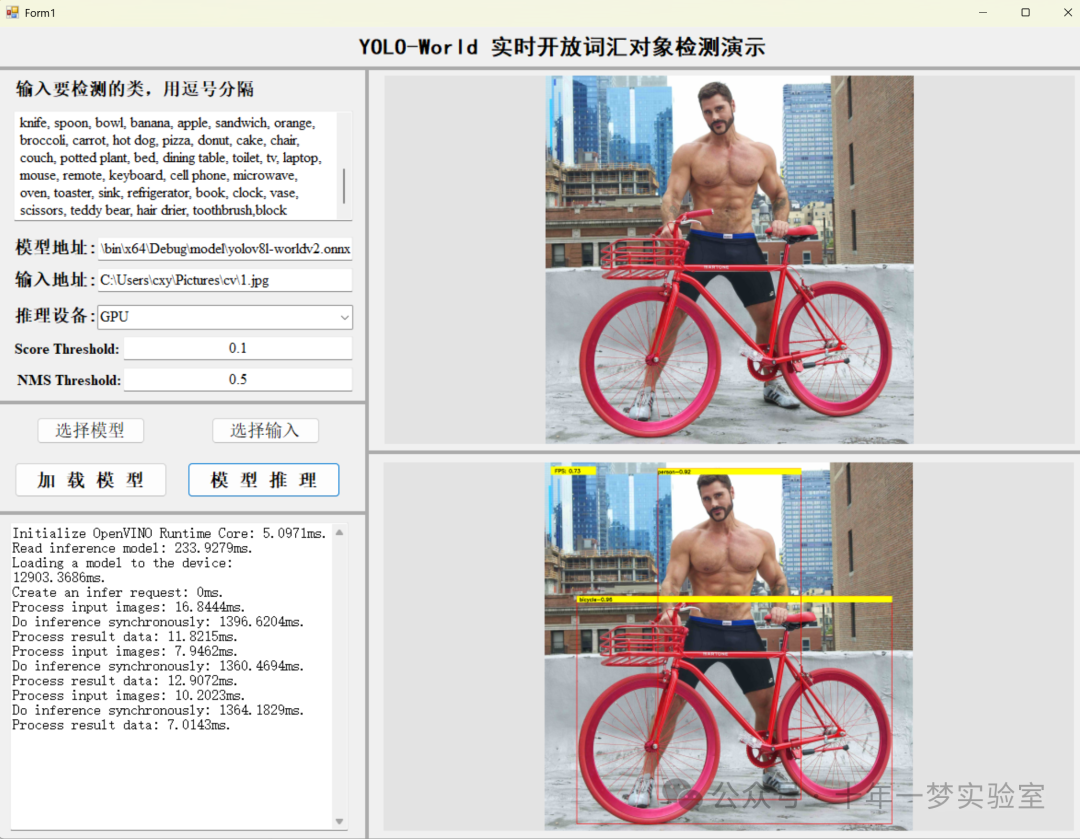
分类(Classify): 确定图像中的对象属于哪个类别。
检测(Detect): 在图像中识别对象的位置并对其进行分类。
OBB(Oriented Bounding Box): 使用定向边界框来检测具有特定方向的对象。
姿态(Pose): 估计图像中人或物体的姿态。
分割(Segment): 将图像中的对象从背景中分离出来。






![C++静态数组和C语言静态数组的区别( array,int a[])](https://img-blog.csdnimg.cn/direct/b5081660510144898787447195b9ac79.png)



