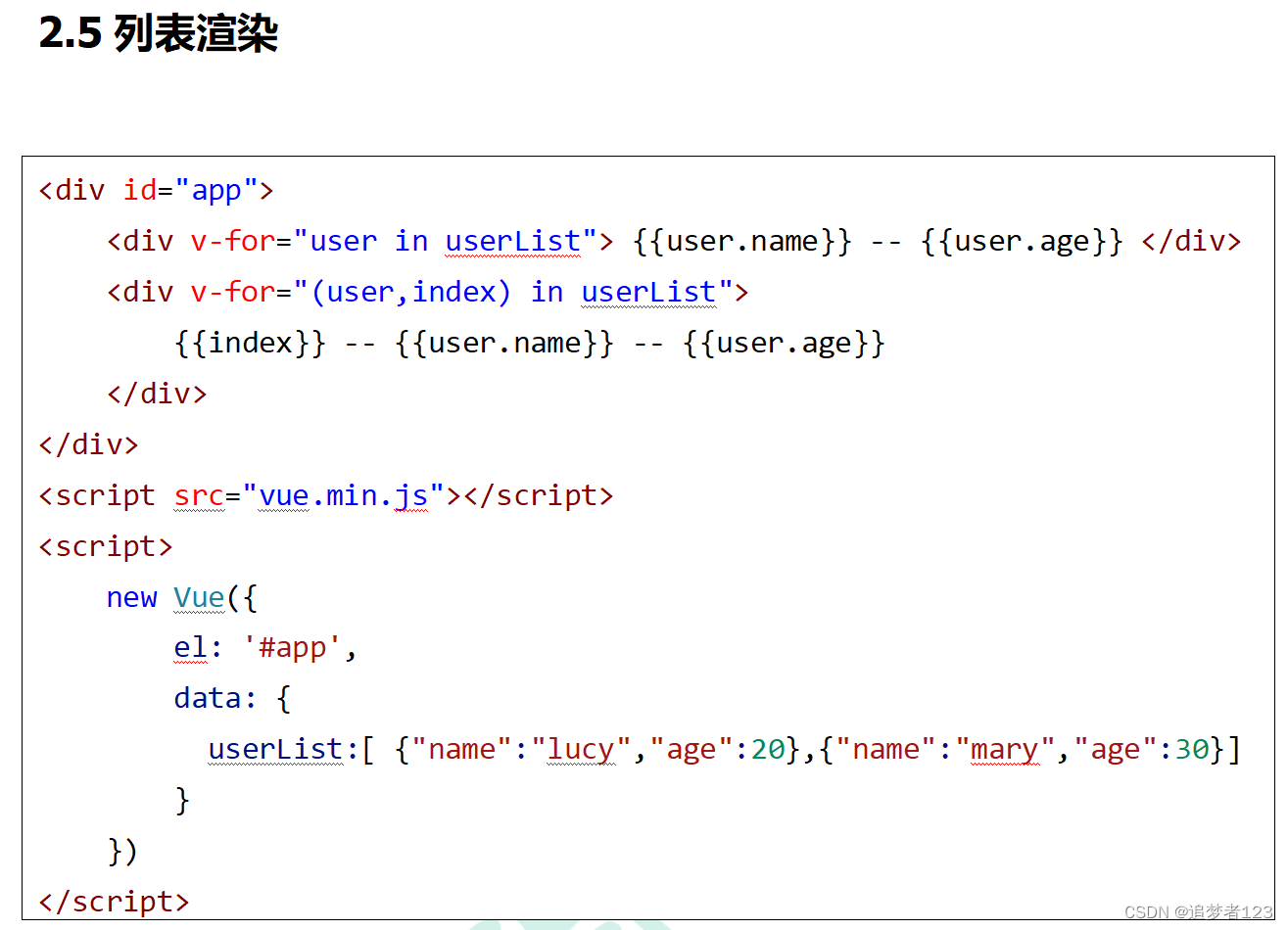
文章目录
- 时间急的可以看速成,虚拟机和配置方法已给出,提供下载的为一台主节点一台分结点的虚拟机下载,只需进行ip地址更换即可 [现成Hadoop配置,图文手把手交你](https://blog.csdn.net/weixin_52521533/article/details/132862703?spm=1001.2014.3001.5501)
- 视频版
- 1.事前准备
- 2.主机互联(namenode和datanode都做)
- 2.1 创建虚拟机
- 2.2 配置网络
- 2.2.1寻找空闲IP地址
- 2.2.2配置ifcfg-eno16777736
- 如果桥接模式下我们ping不通,我们也可以选择NAT模式来尝试一下
- 2.2.3 pc端ssh登录linux(xshell也可以)
- 2.3 实现相互免密登录(namenode和datanode都做)
- 2.3.1修改主机名及主机配置文件
- 2.3.1生成公钥实现免密登录
- 3.配置java jdk(namenode和datanode都做)
- 3.1winSCP上传java
- 3.2 配置全局变量
- 4.配置Hadoop(datanode和namenode分开)
- 4.1主节点配置 (namenode做)
- 4.1.1winSCP上传到software目录
- 4.1.2 修改Hadoop配置文件
- 4.1.2.1 core-site.xml
- 4.1.2.2 hadoop-env.sh
- 4.1.2.3 hdfs-site.xml
- 4.1.2.4 mapred-site.xml
- 4.1.2.5 slaves
- 4.1.2.6yarn-site.xml
- 4.1.3 上传至Linux
- 4.1.3 打包Hadoop分发至datanode
- 4.2 分节点配置 (datanode做)
- 4.3 启动集群(namenode做)
- 5.如何检查错误
- 5.1jdk是否安装及是否为全局变量
- 5.2是否互联互通
- 5.3检查免密登录
- 5.4hadoop的配置文件
- 6.常见问题和解决方案
- 6.1 ifcfg-eno16777736 ping不通外网,外面ping不通虚拟机
- 6.2 hdfs namenode -format失败
- 6.3 hdfs dfsadmin -report全为0
- 用户名不对
时间急的可以看速成,虚拟机和配置方法已给出,提供下载的为一台主节点一台分结点的虚拟机下载,只需进行ip地址更换即可 现成Hadoop配置,图文手把手交你
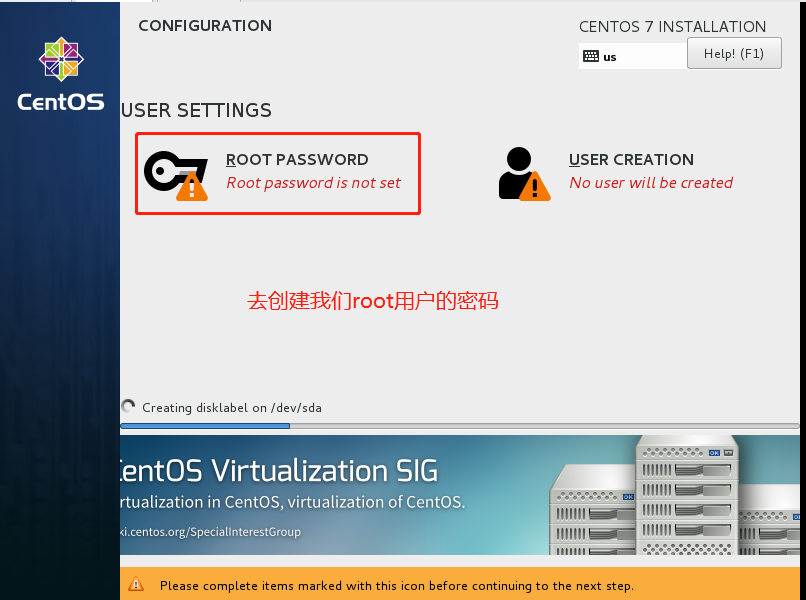
既然你选择自己配置了,那么我想想和你聊一聊,相信我这对你整体配置Hadoop流程会有一个跟全面的了解,我们抛开繁杂的学术名词,其实就是要实现我一个任务可以在多个电脑上跑的过程(分散算力),那交给我们应该如果来搞?我们是不是要对我们的虚拟机先分配地址(对应ip地址分配),分配完地址,是不是又需要我的机器可以相互连接(对应免密登录),可以相互登录之后,我就要开始安装我们的软件了,java、Hadoop,告诉他我可以免密的主机、我结点的个数、我启动的端口号。
我们做的每一步都是为了达成我们的某个目的,有的地方你可能配置了几个星期,很崩溃,还有的甚至你才刚刚接触Linux,就要进行如此复杂的操作,但请你相信自己,我一次配也花了几个星期,但在那之后是我对于Linux的进一步掌握,以及那全班第一个配出来时候的骄傲!希望本篇文章可以给予你一些帮助,下面正式开始
视频版
hadoop配置视频,带教程,资源手把手教你
点下面链接吧,这个是真的糊
B站的画质好很多,点击去B站
1.事前准备
Hadoop,说白了就是让我们计算机的算力可以进行分散,小唐这个月的搭建是真的,啊啊啊啊啊,为了让后人避免踩坑,以及后续自己也可以回来看看,就简单的说一下自己的搭建流程。
咱们首先准备好这些软件
1. VMware
2. CentOS-7-x86_64
3. hadoop-2.7.3.tar(Hadoop的安装文件)
4. jdk-8u65-linux-x64.t.gz(hadoop是基于java的,所以要有java的jdk)
5. SSH(远程连接工具)
6. winSCP(远程传输工具)
当然,小唐也帮大家全都整理出来了,大家可以直接通过网盘自行下载
链接:https://pan.baidu.com/s/1-bvzJBpRVCsgslOkYP26zA?pwd=yu9a
提取码:yu9a
--来自百度网盘超级会员V4的分享
说明,因为这里涉及到多台计算机的共同操作,对于主节点namenode 整篇文章照做,对于datanode节点,除了Hadoop的配置,其他照做,如果配置主机数为多太,只需在后更改hadoop配置文件即可
2.主机互联(namenode和datanode都做)
2.1 创建虚拟机
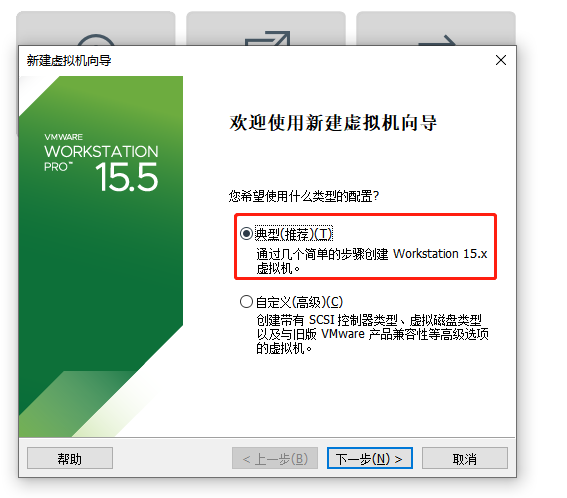
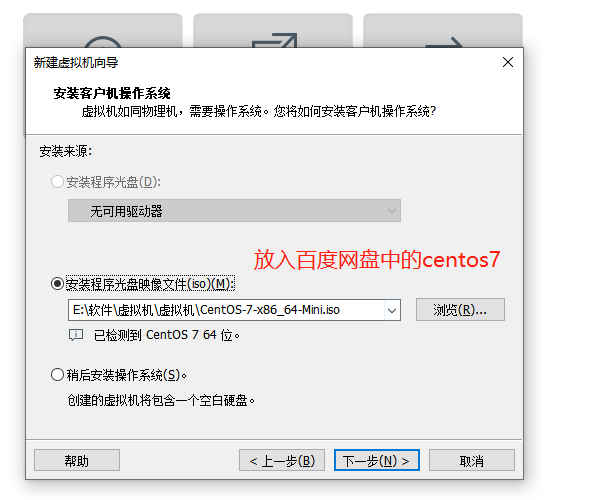
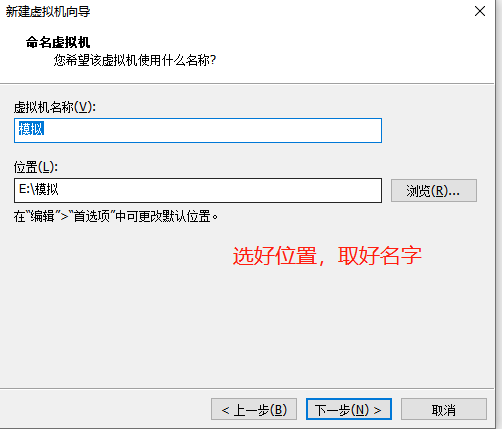
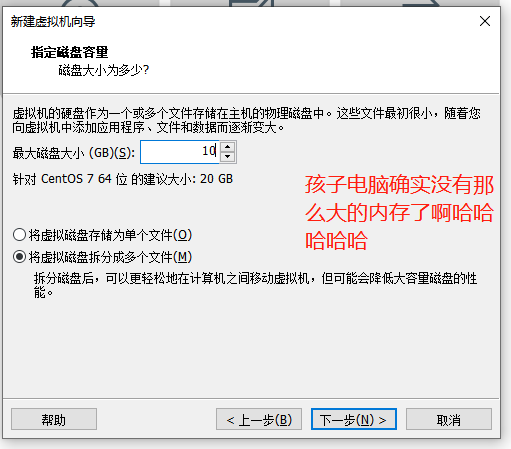
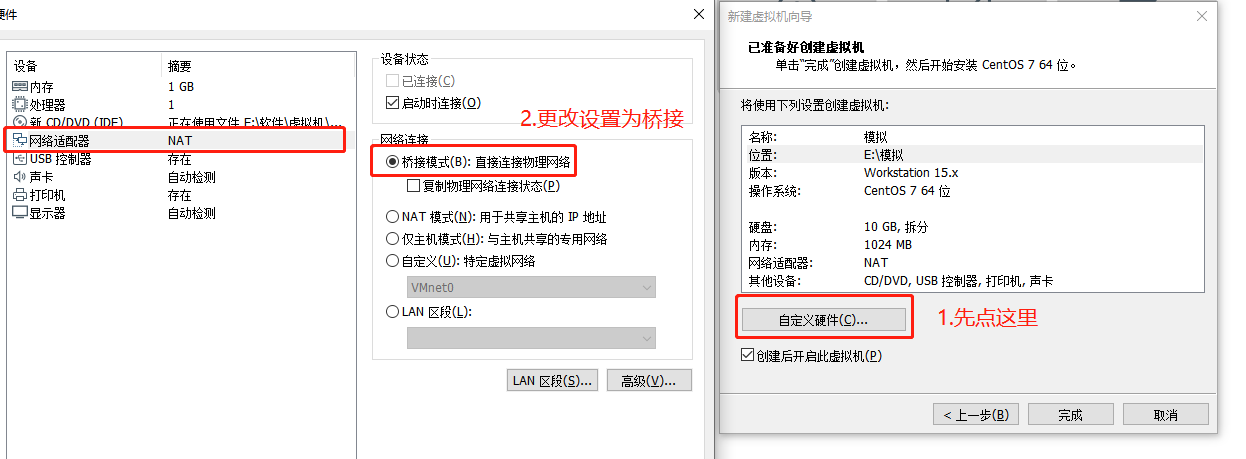

我们稍等一会,然后就可以看到我们的系统了!
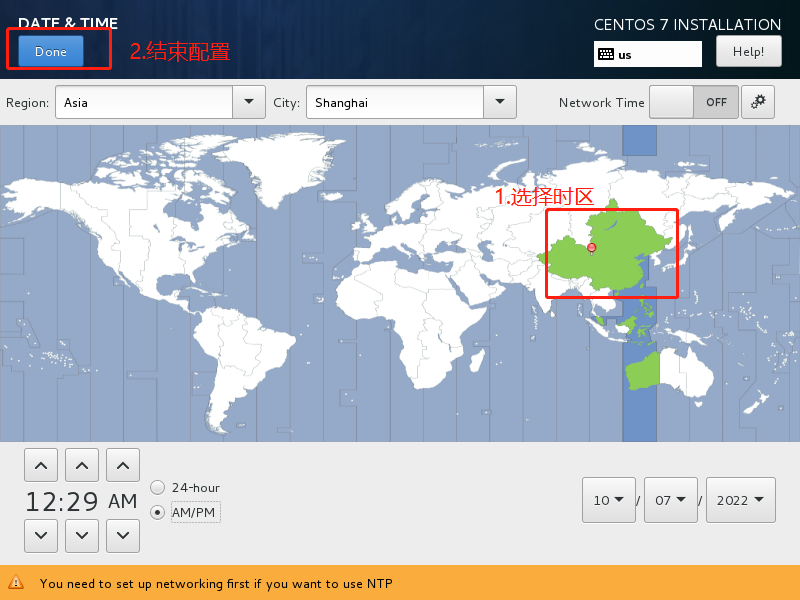
2.2 配置网络
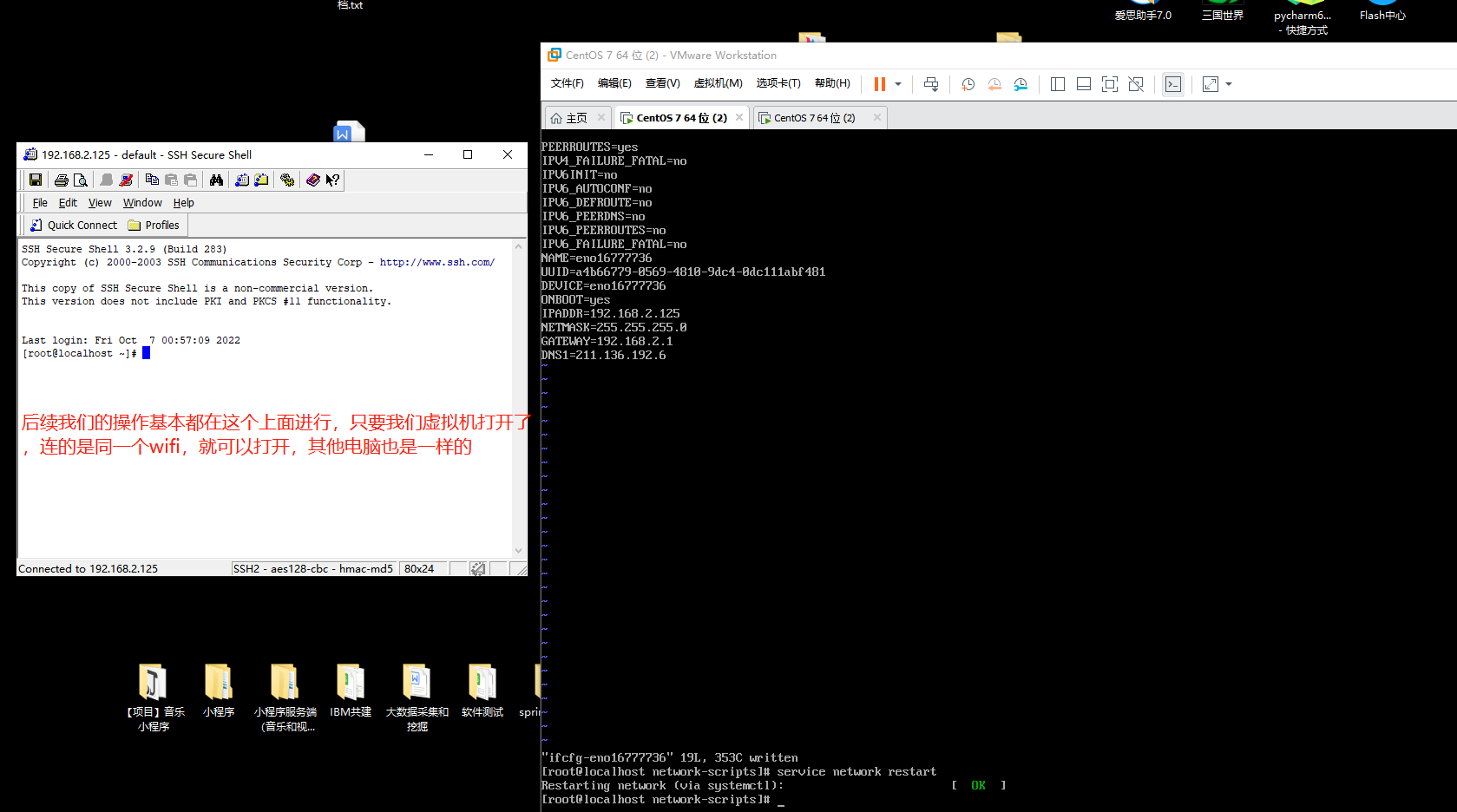
在这里说一下原理,原理就是让我们的主机和所有部署的虚拟机处于同一个网段下,然后我们的主机可以去连我们的虚拟机,我们虚拟机可以去连我们的主机,我们虚拟机之间也可以相互连接。实现了这一步,我们就可以在主机通过我们的ssh软件来对虚拟机进行访问了(只要虚拟机开着,都是这一个wifi,所有电脑都可以连你的虚拟机)
2.2.1寻找空闲IP地址
在windows里面,我们连上自己的wifi,win+r然后打开咱们的cmd窗口
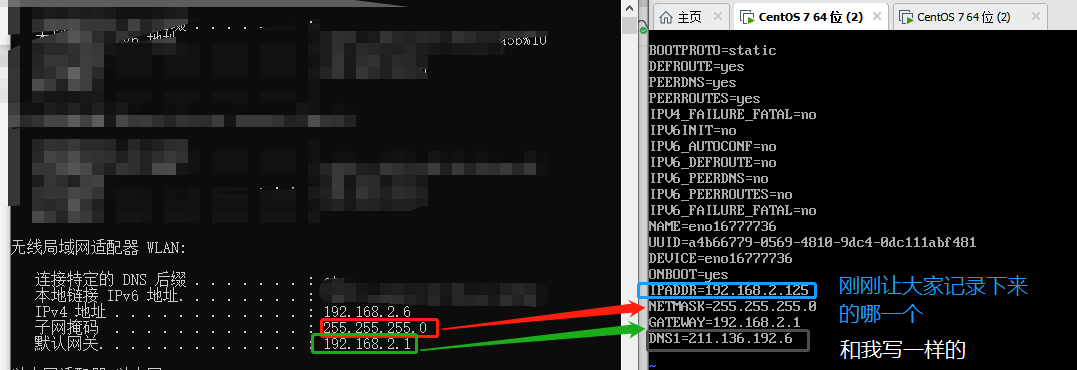
输入ipconfig在这里可以看到自己所有的网段配置信息
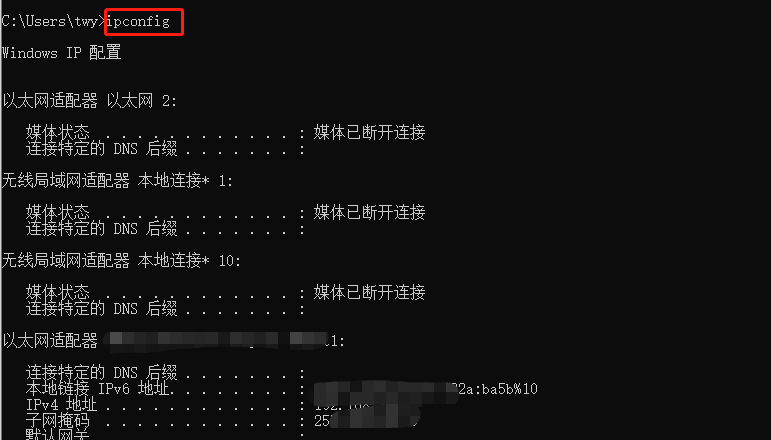
咱们去找到无线局域网适配器 WLAN
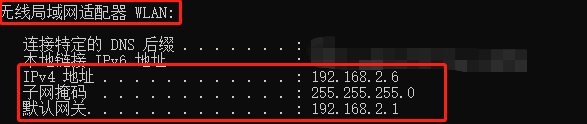
这个就是我们等会要用到的信息了,我们可以我现在是处于
192.168.2.6
这一个网段下,也就是我自己的电脑的IP地址(IP地址不可以重复,重复会引起冲突)
然后我们ping 一下

很明显,因为我现在的这台电脑在使用192.168.2.6这个ip所有他是会有回应的,但是为了让IP地址不重复,我们就要在这个网段下找没有人使用的
我的IP是192.168.2.6,那么我就找192.168.2.***(随便一个不超过255的数)
如果你的IP是172.20.43.5,那么你就找172.20.43.***(随便一个不超过255的数)

如果出现无法访问目标主机,那么恭喜你找到了,这个位置就是没有人使用的,也就是我们说的空闲ip,小唐选取了这两个来作为自己虚拟机分配的IP,这个ip我们先记住 (如果换了WiFi那么我们的ip也是会发生改变的)
192.168.2.125
192.168.2.126(这个是另外一台电脑的为了后面演示,我配置了两台虚拟机,每一个虚拟机都要分配一个IP地址)
2.2.2配置ifcfg-eno16777736
我们首先先进入这个文件夹
cd /etc/sysconfig/network-scripts
然后输入ls

就可以看到我们的这个文件了,使用vi对他进行编辑
vi ifcfg-eno16777736
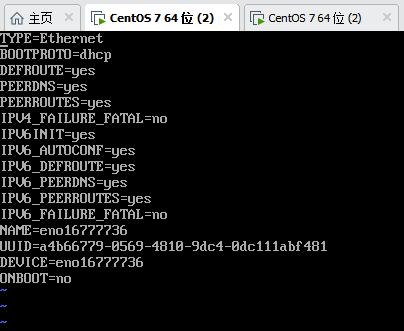
注意:先按一下字母i(就是键盘上面的)进入编辑模式
上面的配置和俺一样,后面的依据每一个的IP地址不同,是要发生改变的
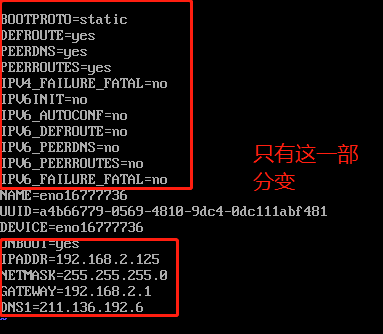
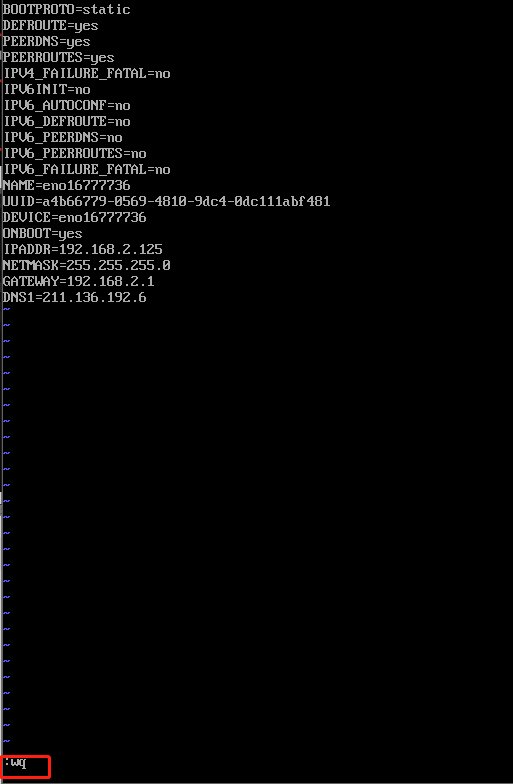
按键盘ESC(一般来说都在左上角)退出编译模式,然后输入
:wq
回车退出后重启,输入
service network restart

出现了,这个我们就基本配置好了,如果报错,请检查,你写得有没有和小唐一样,字母呀啥的
然后我们返回我们主机,再去ping一下我们现在配置好的192.168.2.125
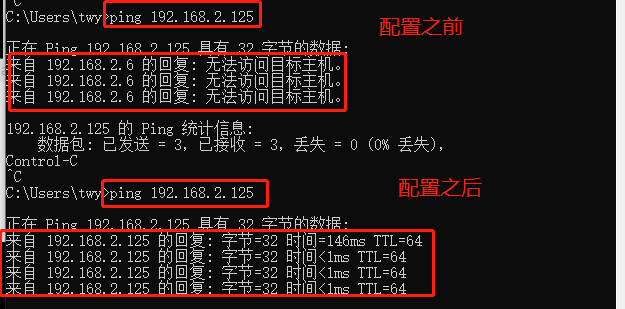
我们的主机就可以访问到我们的虚拟机啦,然后我们也可以用我们的远程软件ssh直接去访问虚拟机,如果还是没有成功,请我们去检查一下有没有开网络防火墙,我们配置文件有没有写对,还有就是我们的网络形式是不是桥接
如果桥接模式下我们ping不通,我们也可以选择NAT模式来尝试一下
桥接换NAT
、
为了不影响阅读体验,文章末尾给出了检查方法
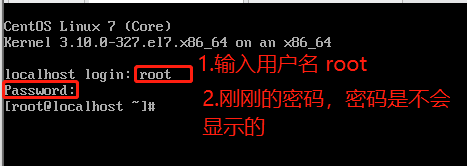
2.2.3 pc端ssh登录linux(xshell也可以)
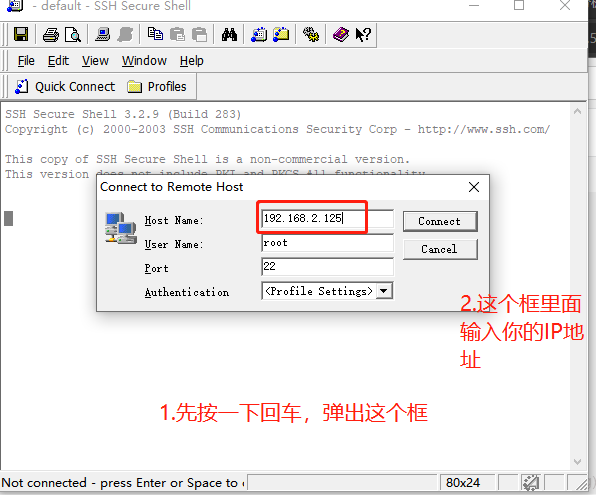
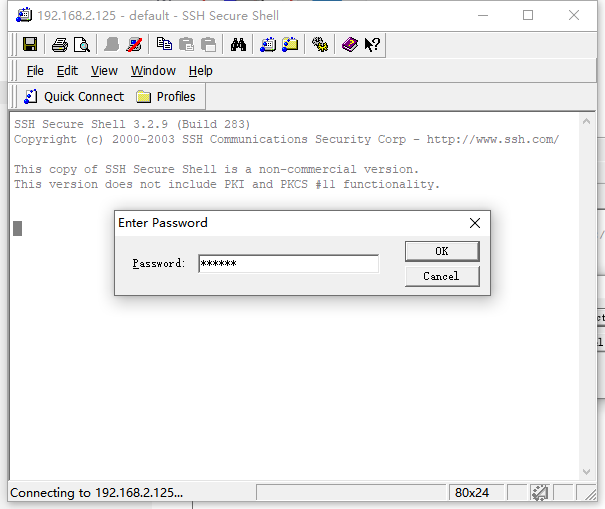
输入我们用户的密码
2.3 实现相互免密登录(namenode和datanode都做)
这一部分是为我们后续hadoop的实现打好基础,配置尤其重要,在这里要注意hostname和hosts里面的名字相同(小唐之前应为这个搞了好久)
2.3.1修改主机名及主机配置文件
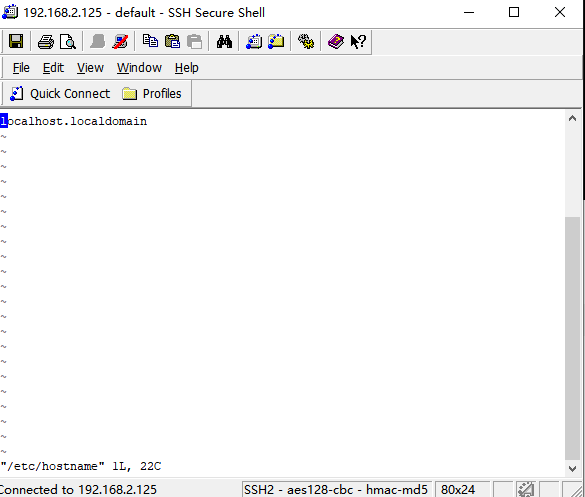
修改咱们的主机名(修改完之后,不会马上显示)
vi /etc/hostname
还是一样的,先输入字母i进入编辑模式,然后改名,在输入Esc退出编辑模式,输入:wq保存
一般如果是主节点都叫做namenode,分结点就叫做datanode1,datanode2,datanode3,然后我们再将我们的ip地址和修改后的主机名写入hosts
vi /etc/hosts
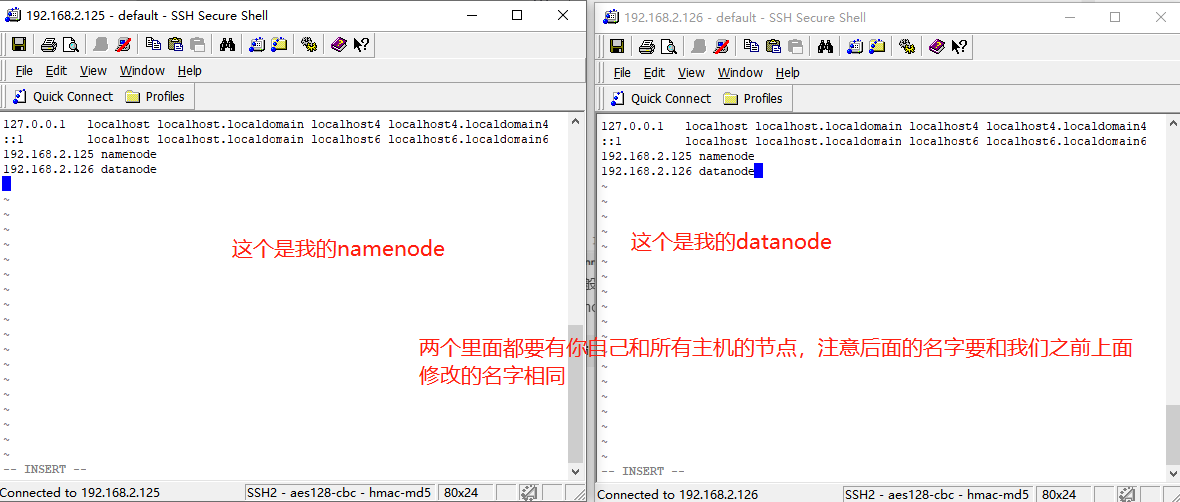
这样之后,我们ping的时候,就可以直接使用对方的主机名啦!!!
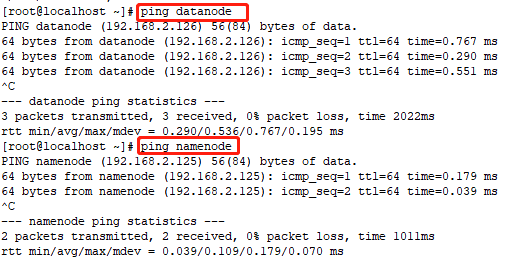
2.3.1生成公钥实现免密登录
关闭我们的防火墙
systemctl stop firewalld.service
先回到最开始的目录
cd /
执行
ssh-keygen -t rsa
然后一直按回车
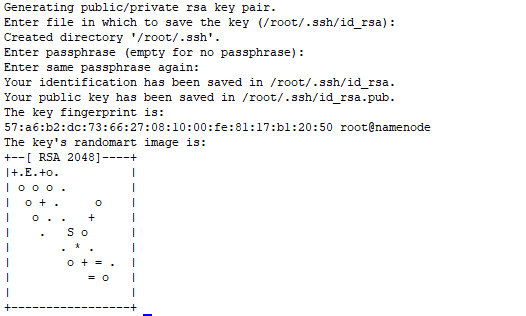
就可以看到我们现在生成的公钥和私钥了,然后我们将我们的公钥传到对方的主机上面
这里注意,我们的公钥和私钥只生产一次!!!
这里注意,我们的公钥和私钥只生产一次!!!
这里注意,我们的公钥和私钥只生产一次!!!
如果生成多次请删除所有文件,重新生成
ssh-copy-id root@datanode
ssh-copy-id root@你另外一台电脑的主机名(hosts里面的)
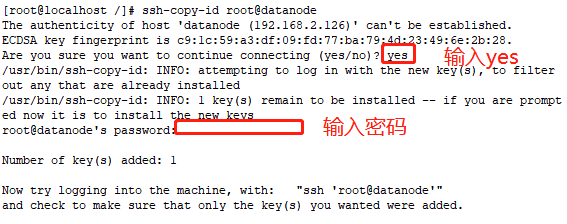
hosts里面我们写了几个,我们就重复操作几次操作,将主节点的生产的密钥传到我们的分结点
这里注意,如果你是namenode节点,那么你还需要自己可以免密登录你自己
ssh datanode
ssh XXX(你要登录的主机名)

如上图所示,我们就可以免密登录到我们的datanode节点了
如果需要退出,使用exit直接退出
exit
3.配置java jdk(namenode和datanode都做)
3.1winSCP上传java
我们输入我们ip地址和账号密码
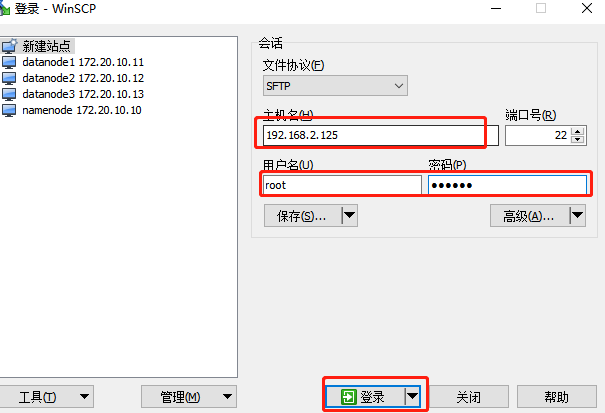
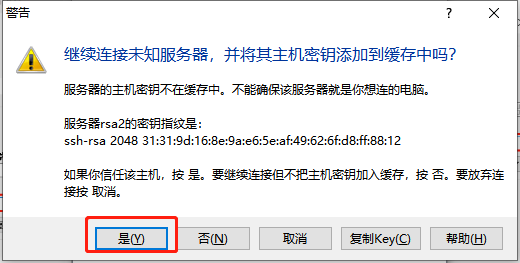
创建software文件夹
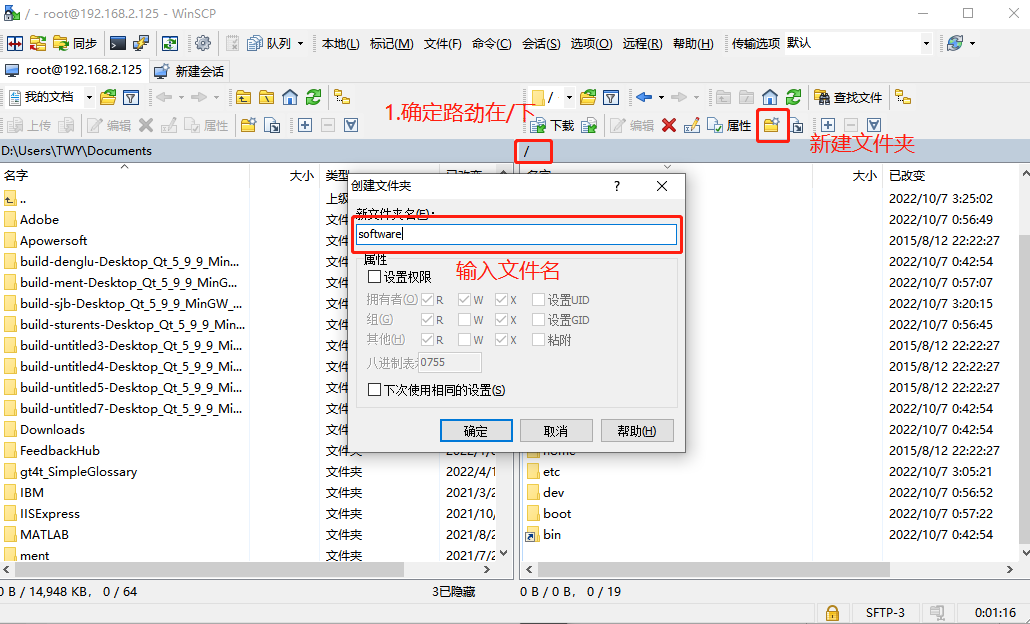
将我们java的jdk拖入software文件里面
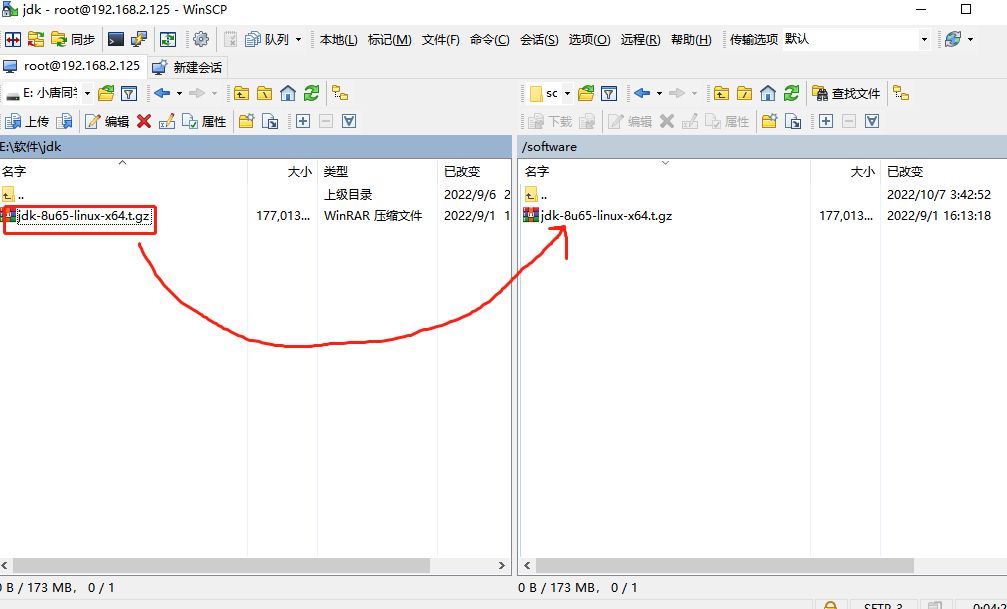
我们拖入后,使用
cd /software
ls
再用ls去看我们的目录下有了java的解压包
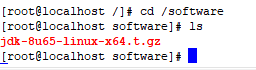
解压文件
tar -xzvf jdk-8u65-linux-x64.t.gz
修改文件夹名字
mv jdk1.8.0_65 jdk

3.2 配置全局变量
进入配置文件
vi /etc/profile
添加配置文件(为了避免hadoop配置,我们在这里就把Hadoop的配置好)
export JAVA_HOME=/software/jdk/
export PATH=.:$PATH:$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/software/hadoop
export PATH=.:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
直接把他们加在最后面
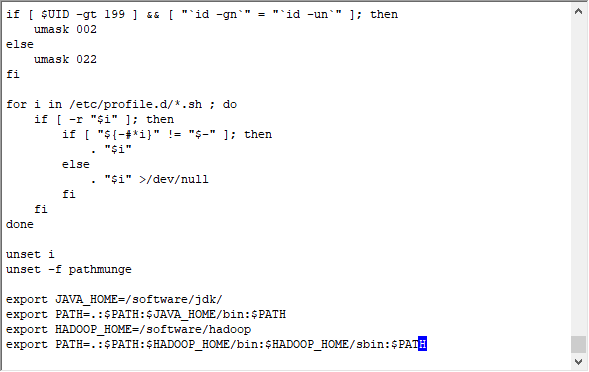
让配置文件生效
source /etc/profile
检查是否位置完成
java -version

像这样无论在哪里都可以看到我们java的版本就欧克啦!
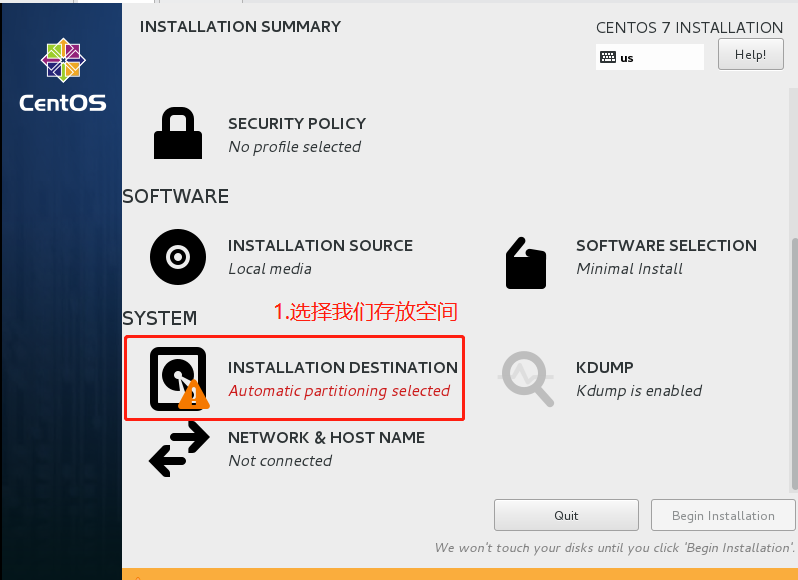
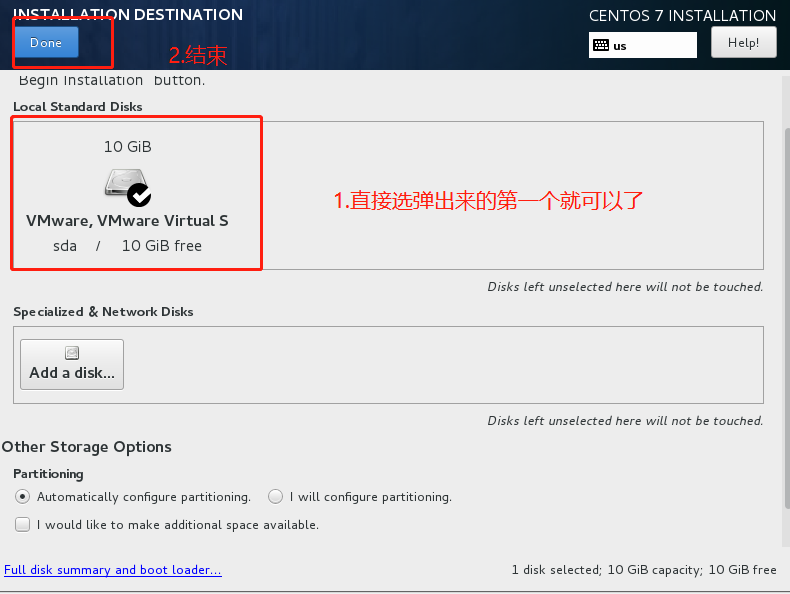
4.配置Hadoop(datanode和namenode分开)
4.1主节点配置 (namenode做)
4.1.1winSCP上传到software目录
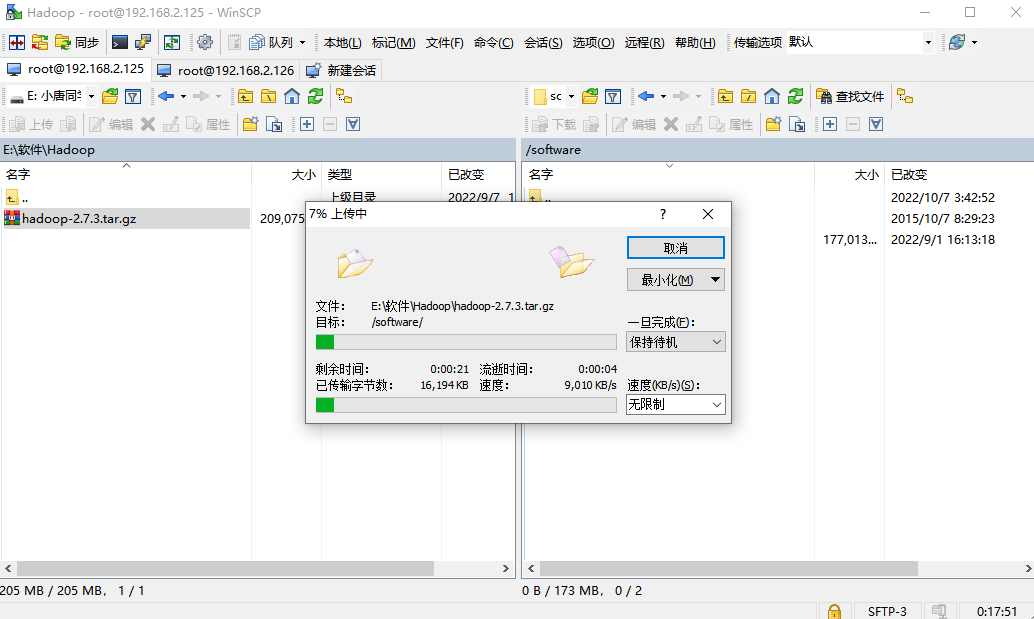
进入到我们software的文件夹,然后查看,再去解压
cd /software
ls
tar -xzvf hadoop-2.7.3.tar.gz
修改下名字
mv hadoop-2.7.3 hadoop
4.1.2 修改Hadoop配置文件
在小唐的配置文件里面,有一个Hadoop配置用例,作为参考,我们也在这个基础上面进行修改,在window上面修改,然后再通过winspc上传到Linux
4.1.2.1 core-site.xml

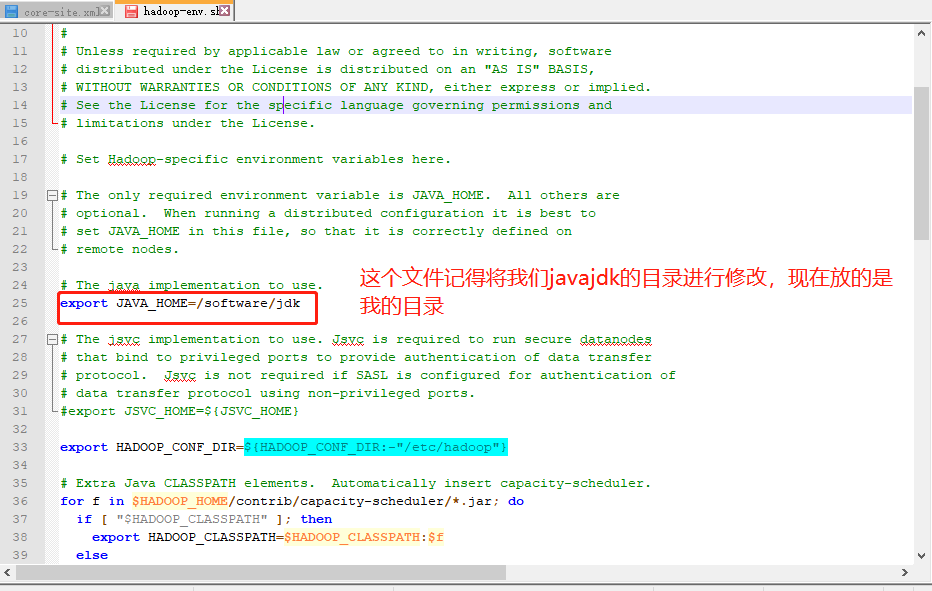
4.1.2.2 hadoop-env.sh
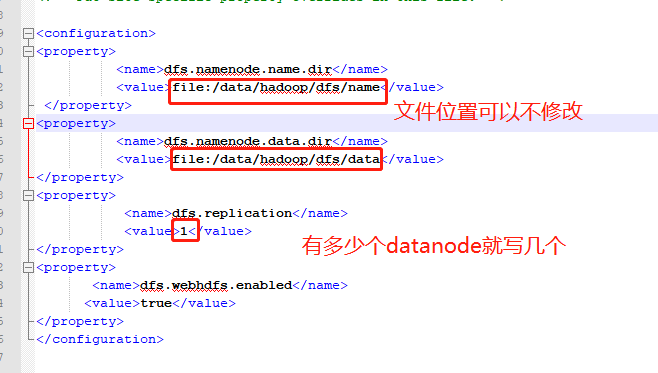
4.1.2.3 hdfs-site.xml
4.1.2.4 mapred-site.xml

4.1.2.5 slaves
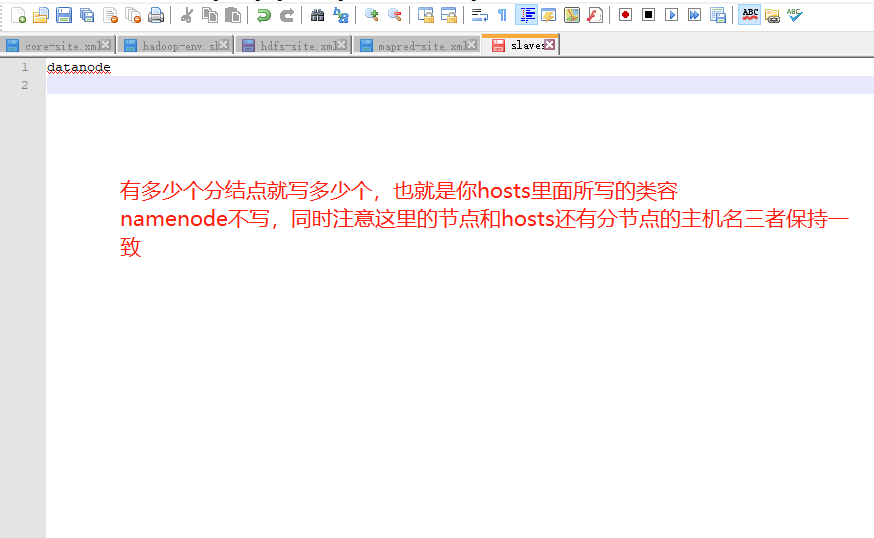
4.1.2.6yarn-site.xml

4.1.3 上传至Linux
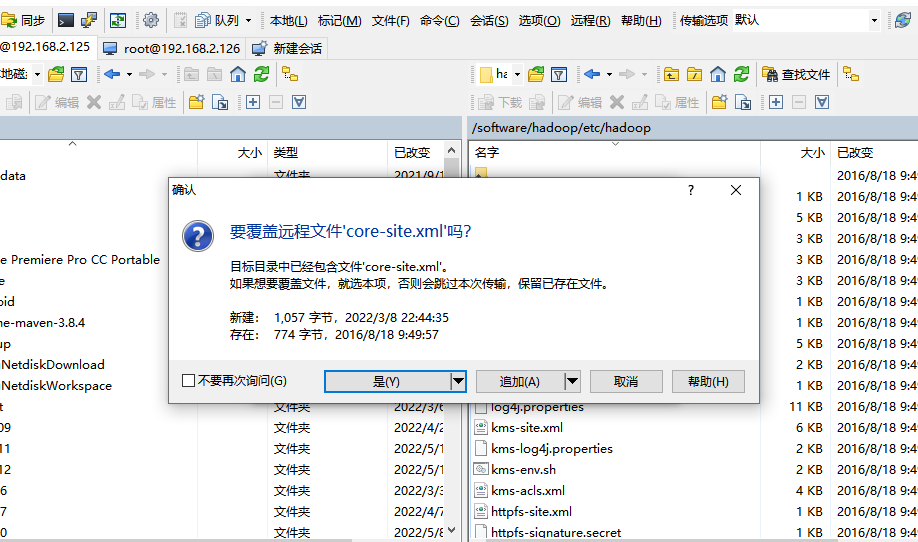
将我们刚刚修改过的所有文件上传至这个目录
/software/hadoop/etc/hadoop
全都选择进行覆盖
4.1.3 打包Hadoop分发至datanode
进入到software目录后,对hadoop进行打包
cd /software
tar -czvf hadoop.tar.gz hadoop

将其进行分发
scp hadoop.tar.gz datanode:/software
scp hadoop.tar.gz (文件名) datanode(hosts里面的节点):/software(分发位置)

4.2 分节点配置 (datanode做)
经过namenode分发之后,我们可以在各自的datanode里面看到

我们再对其进行解压
cd /software
tar -zxvf hadoop.tar.gz hadoop
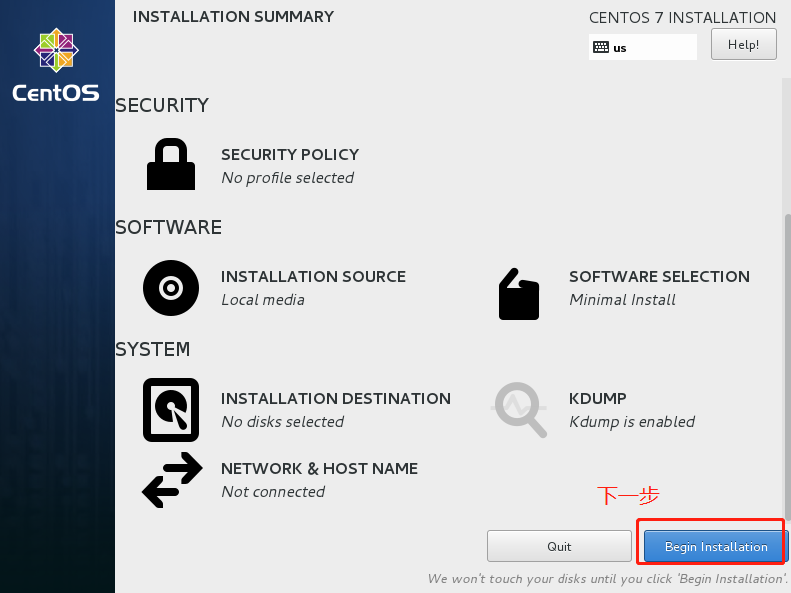
4.3 启动集群(namenode做)
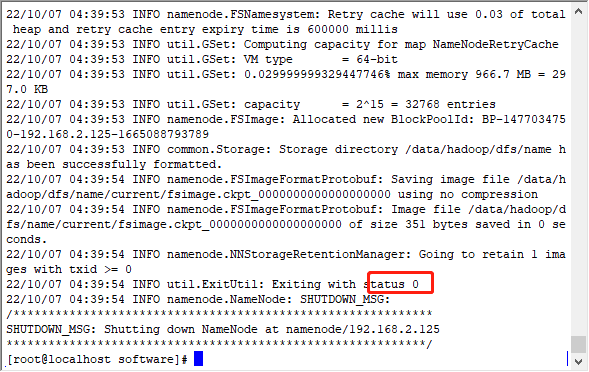
格式化集群
hdfs namenode -format
启动集群
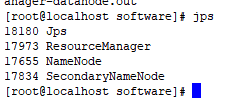
start-all.sh

jps查看状态
jps
查看集群报告
hdfs dfsadmin -report
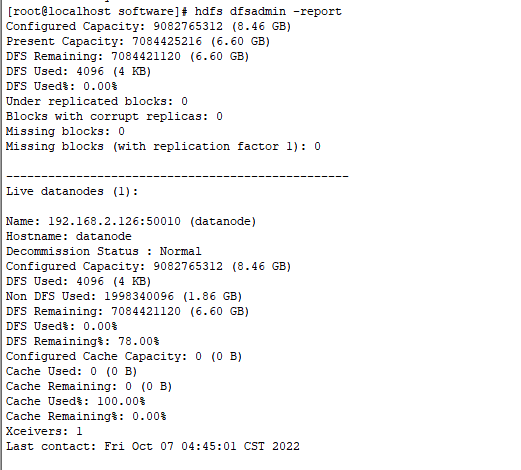
停止集群报告
stop-all.sh
5.如何检查错误
5.1jdk是否安装及是否为全局变量
java -version
查看是否可以现实java的信息,如果虚拟机java没有报错,但是我们在执行Hadoop时候java报错了,别忘记了在我们**hadoop-env.sh(详见4.1.2.2)**文件处,也有个java需要配置。
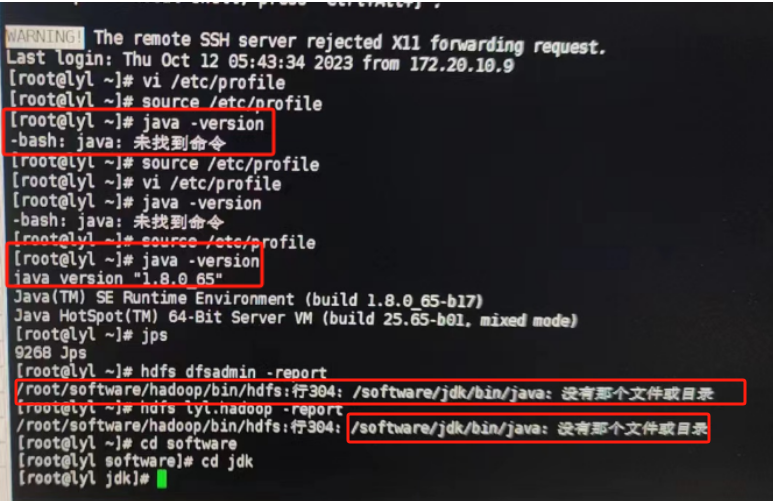
/software/jdk/bin/java:没有那个文件或目录
5.2是否互联互通
需要我每一台主机可以ping通我们hosts里面的主机名
Namendoe
Datanodea
Datanodeb
Datanodec
5.3检查免密登录
特别是namenode节点到namenode节点
还有namenode节点到其他的datanode节点
ssh xxx(主机名)
5.4hadoop的配置文件
我们主机名 hosts 还有slaves名字是否一致(主要对于datanode来说),我们主节点的名字有没有修改
6.常见问题和解决方案
6.1 ifcfg-eno16777736 ping不通外网,外面ping不通虚拟机
1.在虚拟机内ping 外网
ping wwww.baidu.com
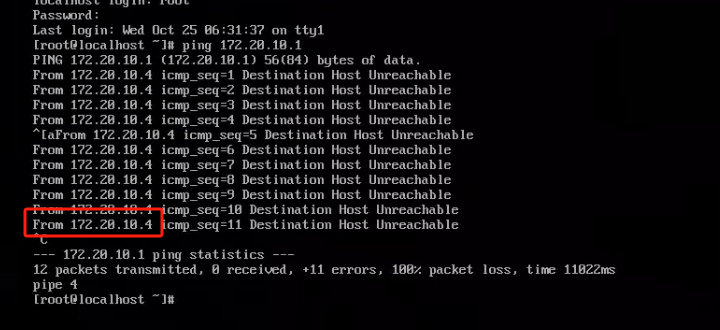
前面IP请检查是否为你修改的IP,如果没有就是你没有ifcfg-eno16777736没有配置好
2.点击你的虚拟机设置,检查网络是否为桥接(详见 2.1 创建虚拟机)
3.检查在物理机(windows上),是否存在VM网络配置问题,一般vm没删干净和配置出错会有这个问题
在桌面空白处右击,点击个性化,进入设置,搜索控制面板
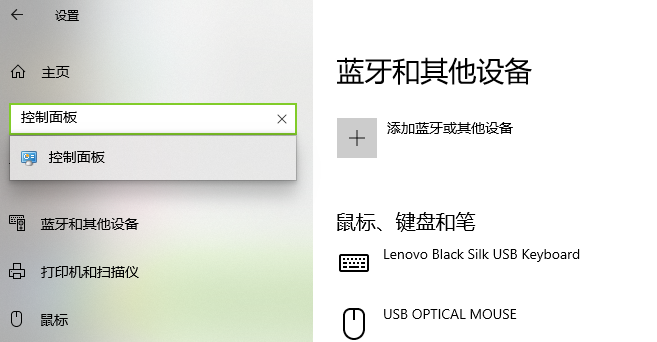
点击查询网络状态和任务

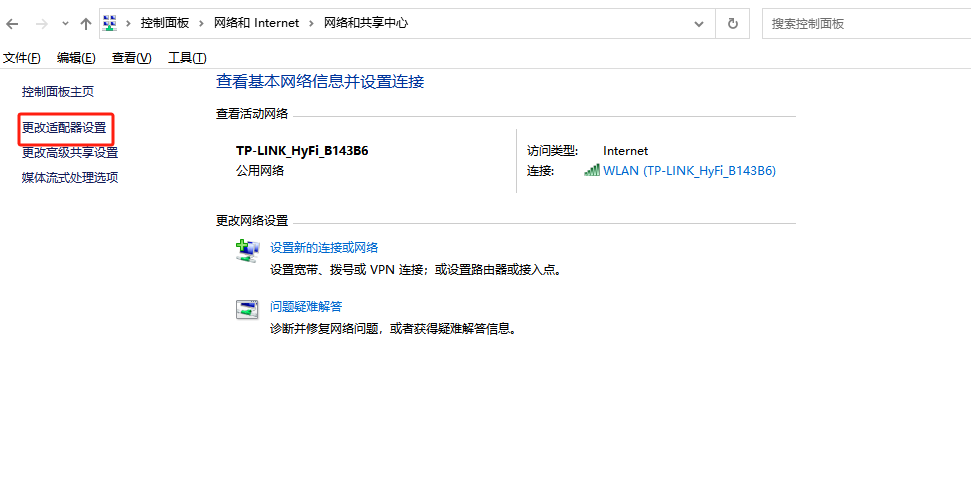
检查是否为感叹号
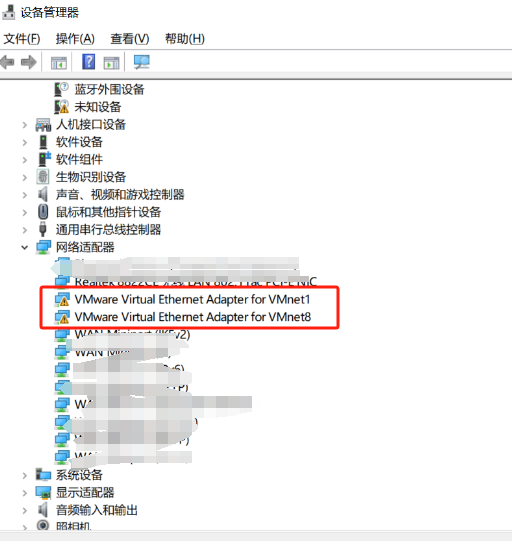
如果有请找到,VM的安装包,在管理员模式下运行,尝试修复,修复后再次检查,如果还不行,直接删除再重新安装也是可以的(记住你装虚拟机的位置,你的虚拟机不会被删除)
6.2 hdfs namenode -format失败
那是我们格式化多次,我们需要对我们每一个节点生成的格式化文件进行删除
详见4.1.2.1 core-site.xml需对里面那个路劲全删掉
(如果里面没有重要数据,直接全都删除,重新初始化即可,如果有需要打开内置文件对版本号进行手动修改)
结点信息存储在core-site.xml文件中
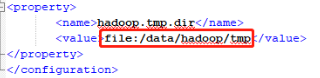
1.删除两台主机“/data/hadoop”里面的内容
rm -rf /data/hadoop
2.重新格式化
hadoop namenode -format
4.启动hadoop
start-all.sh
6.3 hdfs dfsadmin -report全为0
用户名不对
这个的原因是因为我们hostname和我们datanode主机名不一致导致的,比如我现在有三台
IP 主机名
172.2.111.10 namendoe
172.2.111.11 datandoe1
172.2.111.12 datandoe2
172.2.111.13 datandoe3
然后我为了省事在hosts这样写
172.2.111.10 namendoe
172.2.111.11 dn1
172.2.111.12 dn2
172.2.111.13 dn3
然后在slaves这样写
dn1
dn2
dn3
就会出现这个错误,我们直接修改我们的主机名就可以了,全改成一样的