细粒度图像分类论文研读
- 摘要
- Abstract
- 1. 基于细粒度图像分类的视觉语义嵌入模型
- 1.1 文献摘要
- 1.2 创新点
- 1.3 模型网络结构和方法
- 1.3.1 问题陈述
- 1.3.2 两级卷积神经网络
- 1.3.3 局部化 CNN
- 1.3.4 回归排序网络
- 1.3.5 参数学习
- 1.4 实验
- 1.4.1 数据集
- 1.4.2 实验设置
- 1.4.3 分类结果对比
- 1.4.4 模型分析
- 1.5 结论
- 1.6 思考
- 总结
摘要
基于细粒度图像分类的视觉语义嵌入模型是一种深度学习架构,旨在将图像的视觉内容映射到一个高维的语义空间中,其中图像的语义特征被编码为向量表示。这种模型特别适用于细粒度图像分类任务,如不同品种的鸟类或花卉识别,它通过学习图像中的细节特征和全局上下文信息,能够捕捉到图像中微小但具有区分性的视觉差异。这些嵌入向量不仅能够反映图像的视觉属性,还能够表达图像的语义信息,从而使得模型在面对类别间相似性高的挑战时,仍能实现高精度的分类效果。本文将详细介绍基于细粒度图像分类的视觉语义嵌入模型
Abstract
A visual semantic embedding model based on fine-grained image classification is a deep learning architecture designed to map the visual content of an image into a high-dimensional semantic space, where the semantic features of the image are encoded as vector representations. This model is particularly suitable for fine-grained image classification tasks, such as bird or flower recognition of different species, where it is able to capture small but distinguishing visual differences in an image by learning detailed features and global contextual information in the image. These embedding vectors not only reflect the visual attributes of the image, but also express the semantic information of the image, thus enabling the model to achieve high accuracy in classification even when facing the challenge of high similarity between categories. In this paper, we will introduce the visual semantic embedding model based on fine-grained image classification in detail
文章出处:Fine-grained Image Classification by Visual-Semantic Embedding
1. 基于细粒度图像分类的视觉语义嵌入模型
1.1 文献摘要
细粒度图像分类(fine-grained image classification, FGIC),难点在于很大的类内多样性与微妙的类间不同点。现有的方法限制在利用图像中的视觉信息嵌入,本文使用了一些先验知识,来自于结构化知识基础或者非结构化的文本信息,来简化FGIC问题。建立了一个视觉语义嵌入模型来从知识基础和文本中探索语义嵌入,然后训练一个CNN线性的将图像特征映射到语义嵌入空间当中。
1.2 创新点
细粒度图像分离目标是子基础的类别中识别物体的子类别(例如辨识鸟的物种)。难点在于不同的类别之间相似度极高,而且同一类别的物体也会因为不同的动作、尺度等造成极高的不相似性。
此前的工作
- 学习可区分的视觉表示
- 尝试将物体的不同部分局部化
人类识别图像中的物体时,不仅仅关注视觉信息,而且会考虑通过经验或者物体的文字描述获取的先验信息,这样的外部先验信息有两种:
- 文本信息:文字上下文中图片的类别标签经常有严格定义的内部结构,标签经常和相关的信息一同出现
- 知识库信息:标签经常包含多种类型和特点,类之间的联系描述了它们之间的关系
此前的方法(将类别标签作为one-hot向量去评估)通常 假设类之间在统计学上是相互独立的,这就忽视了他们之间语义上的关联性。本文首先使用劳务一个视觉-语义嵌入框架来学习类别和图像之间的关系,即将图像特征空间投射到一个多类别的富语义嵌入空间,后者中外部先验知识被编码为类的嵌入向量。
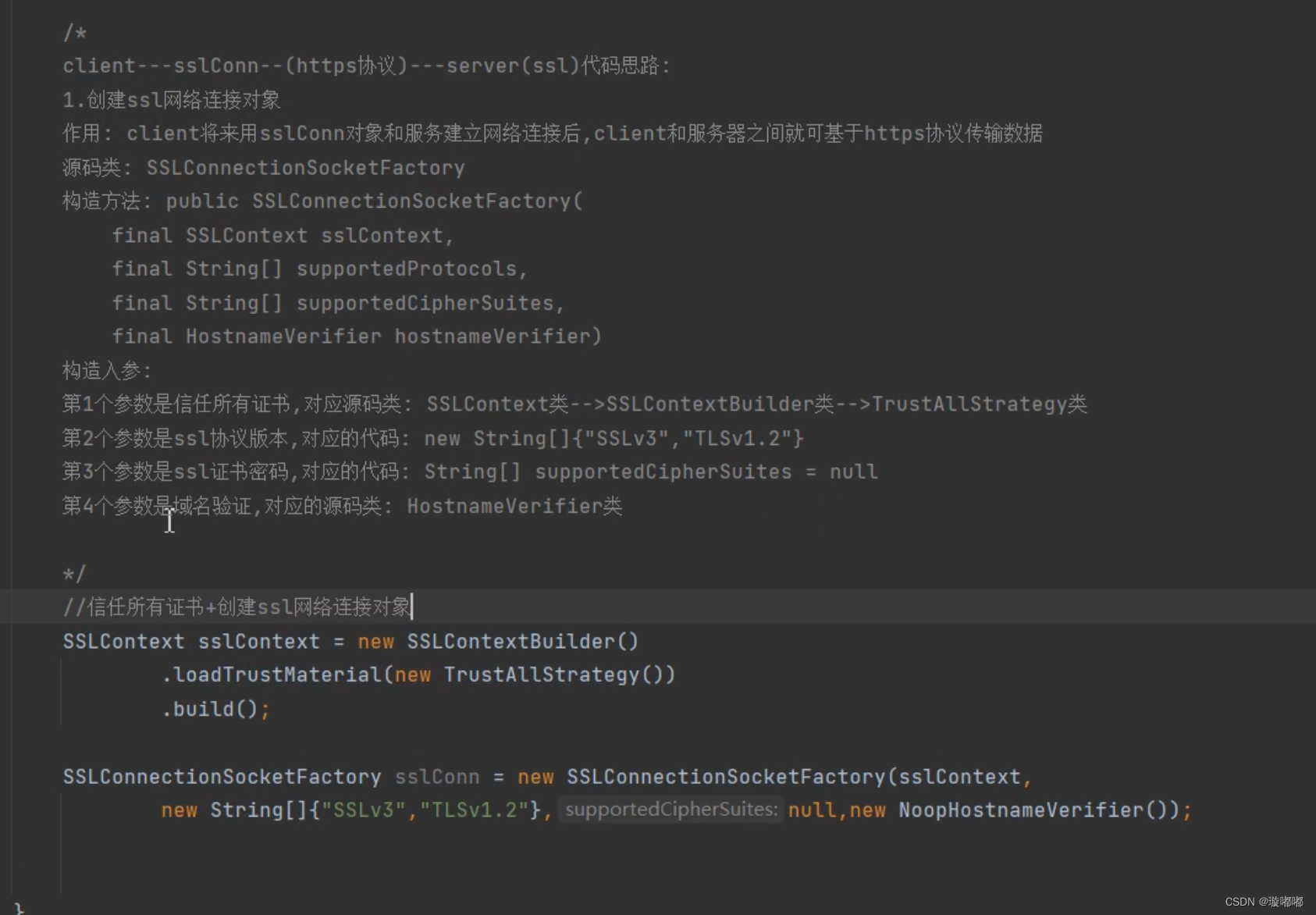
1.3 模型网络结构和方法
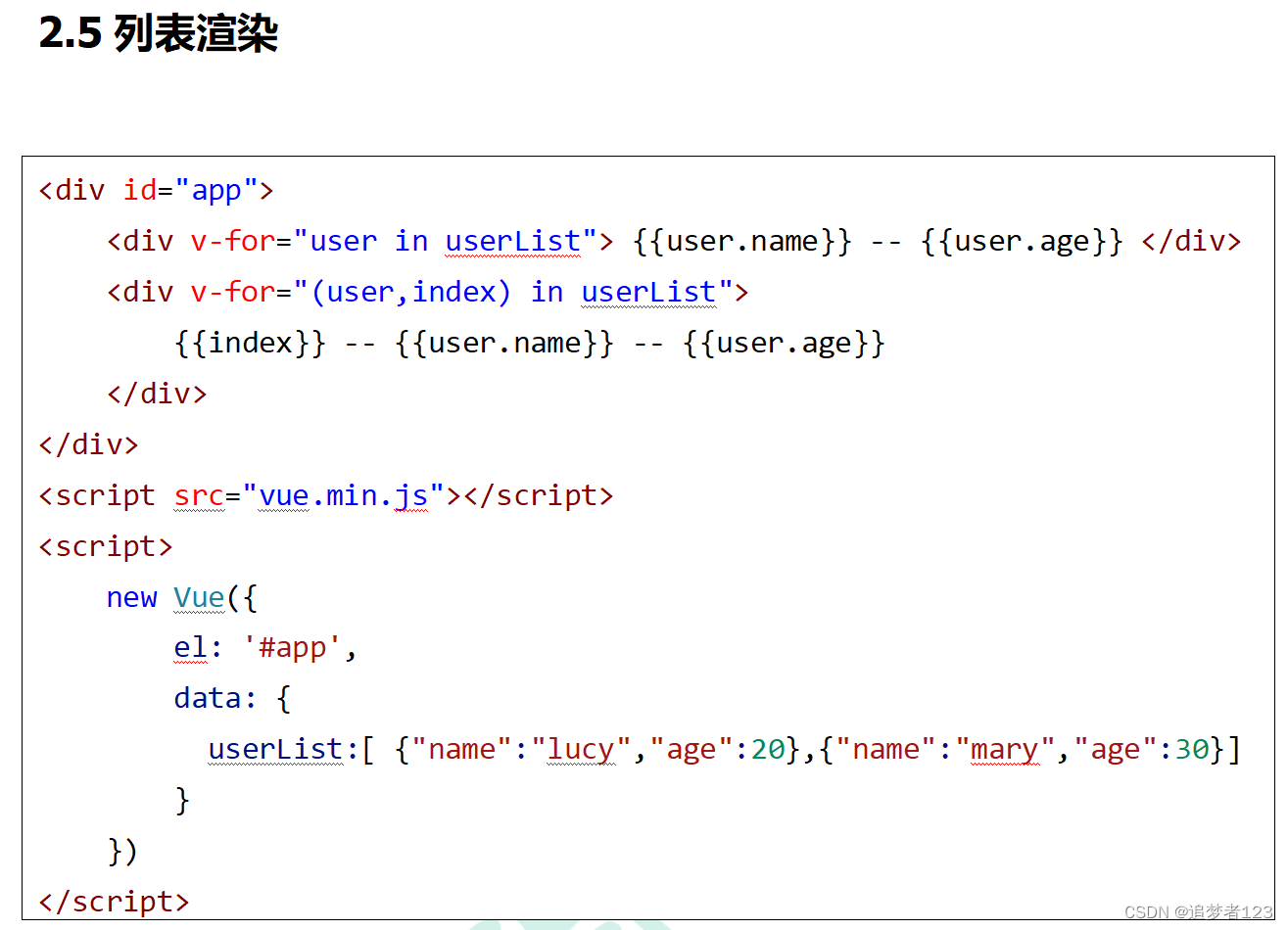
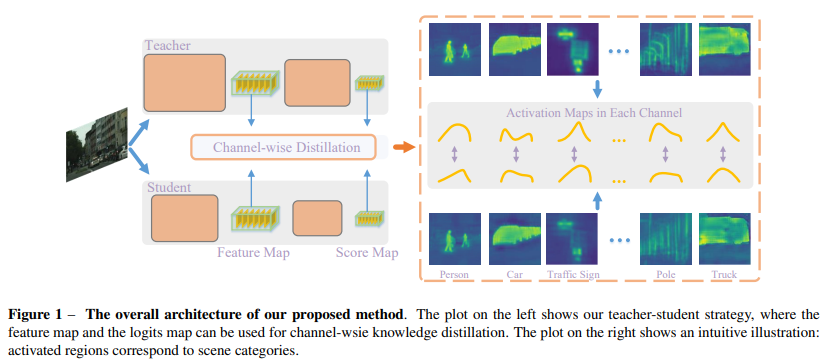
下图为作者提出的 FGIC 两级卷积神经网络。
F
A
F_A
FA旨在基于检测机制获取对象的局部特征,而
F
B
F_B
FB则将图像的视觉特征线性映射到语义嵌入空间(
F
B
F_B
FB将每个图像嵌入到知识库嵌入空间中其对应标签的附近位置,并且文本嵌入空间)。

1.3.1 问题陈述
训练数据集
X
=
{
(
x
i
,
y
i
)
}
(
i
=
1
,
2
,
.
.
.
,
m
)
X=\left \{ (x_i,y_i) \right \}(i=1,2,...,m)
X={(xi,yi)}(i=1,2,...,m),相应的细粒度标签集合
y
=
{
y
1
,
y
2
,
y
3
,
.
.
.
,
y
c
}
y=\left \{ y_1,y_2,y_3,...,y_c \right \}
y={y1,y2,y3,...,yc},需要学习一个函数映射
f
:
X
⟶
y
f:X\longrightarrow y
f:X⟶y,最小化实验损失(计算视觉输出以及真实class之间的差距)。给定一个输入图片
x
x
x,知识库嵌入
δ
1
(
y
)
∈
R
k
\delta_1(y)\in R^k
δ1(y)∈Rk以及文本嵌入
δ
2
(
y
)
∈
R
k
\delta_2(y)\in R^k
δ2(y)∈Rk,都是针对给定的真实class y yy 而言的。这样的模型目标最是最大化后验概率:
![]()
其中
θ
\theta
θ 就是学习参数。
针对
δ
1
(
y
)
\delta_1(y)
δ1(y)和
δ
2
(
y
)
\delta_2(y)
δ2(y),作者分别使用了 TransR 和 Word2Vec 模型。因此,
δ
1
(
y
)
\delta_1(y)
δ1(y)和
δ
2
(
y
)
\delta_2(y)
δ2(y)是条件独立的,上式可以化简为:

考虑到视觉-语义嵌入框架,DeViSE 使用了成对的排序目标函数来直接的将图片映射到富语义嵌入空间中。SJE 使用兼容函数将图像的视觉嵌入和文本嵌入实现相互映射,训练了一个 two-step 模型。作者的不同之处在于:整合了多个领域的信息,并且训练了一个端到端的模型。
1.3.2 两级卷积神经网络
微妙、局部化的不同在区分子类别中是十分重要,这些不同经常出现在物体的不同部分和区域。 因此此前的一些工作使用了两阶段的框架:
- 借助于R-CNN框架,局部化物体或者其中的可区分性 parts
- 从划分的 parts 或者整个物体中抽取视觉特征
这里作者提到了 Bilinear CNN,它使用了两个基于CNN的特征提取模型,第一个强调物体的识别,第二个关注在空间位置,两个CNN提取器以平移不变的方式考虑成对相互作用,这特别适用于细粒度分类任务。
1.3.3 局部化 CNN
模型的第一层是训练一个局部化网络
(
F
A
)
(F_A)
(FA),希望能够检测出物体的边界框。如果proposal是positive的,那么proposal区域的特征对物体的parts或者边界是敏感的。对于细粒度图像分割,一张图像中只有一个被认为是正样本的物体。因此,本文中使用原始图像作为正样本区域,输出就类似于RCNN。这样,
F
A
F_A
FA的目标就是:

其中边界框使用
(
x
,
y
,
h
,
w
)
(x,y,h,w)
(x,y,h,w) 表示。
1.3.4 回归排序网络
模型的第二层是一个回归排序网络
(
F
B
)
(F_B)
(FB),希望能够得到图片物体的全局视觉特征,为了整合语义嵌入,
F
A
F_A
FA同时训练了两个平行的加入softmax的全连接层。全连接层将图像的视觉嵌入(deep CNN学到的)映射到类别的语义嵌入(TransR 或者 Word2Vec 学到的)当中。两个全连接层被称作 projection layer。使用
M
1
∈
R
d
×
k
M_1\in R^{d\times k}
M1∈Rd×k 和
M
2
∈
R
d
×
k
M_2\in R^{d\times k}
M2∈Rd×k表示投影层的参数,
v
∈
R
d
v\in R^{d}
v∈Rd是视觉嵌入,其中 d 是视觉嵌入的维度,k 是图片类别的嵌入向量的维度。训练是这个网络同时使用了余弦相似度和欧氏距离来衡量差异:

所以这里同时使用两种距离的原因是什么?作者好像也没有解释,倒是花了不小的篇幅解释距离的定义与计算。从含义来看欧氏距离要求是更加严格的,只有两个向量重合结果才是0,而余弦距离只关注到向量的夹角。在这里首先应该是要求两个向量完全重合的,然后通过余弦距离放大了夹角部分的效果,maybe。那么问题就在于:这样的映射空间中,嵌入向量的夹角究竟代表着什么
利用这个距离得到损失函数:

其中,
y
−
y^-
y− 通过排序公式挑选出来:

作者所这样能够对小化positive class的距离同时最大化negative class的距离。
无论如何,作者这样的操作更加直接的将语义信息和图像的视觉信息取得了关联,而不是像前人做的——需要标注进行关联。从某种程度来讲这种脱离标注的建模方式不仅有利于挖掘信息,而且一旦设置一个好的评价方式,能够得到的有价值的参考是会大于标注得来的。但不得不提到的是,这样的网络应该是比较难以训练出理想效果的(因为从数据集到网络设置都要很小心地选择才行)
1.3.5 参数学习
将局部化网络的特征和回归排序网络的特征相乘(element-wise),最终的loss函数为:

两个网络最终的乘积看作是一种attention的操作,相当于使用对于 F A F_{A} FA中的特征根据 F B F_B FB中的结果进行加权。可以分类模型考虑边界框真的不会增大学习难度吗?可能是因为细粒度更需要聚焦网络关注点?
1.4 实验
1.4.1 数据集
本实验作者采用的数据集有:
- 鸟类数据集:Caltech-UCSD Bird-200-2011
- TransR训练集:DBpedia [Lehmann et al., 2015] (KB)
- Word2Vec训练集:English-language Wikipedia (text) from 06.01.2016
1.4.2 实验设置
- 回归排序网络:AlexNet、GoogleNet、VGG
- 图片尺寸:224*224
- 局部化网络:AlexNet,边界框回归
- mini-batch:40,lr=0.0015, α = 0.85 \alpha=0.85 α=0.85,每层卷积加BN,全连接层加dropout
- F B F_B FB中的所有参数都是在ImageNet中训练然后在鸟类数据集上fine-tune的
- 语义数据集中抽取出和鸟类数据集属性相关的部分进行fine-tune
1.4.3 分类结果对比

对比来看,前人考虑到边界框时似乎是考虑直接使用边界框,而作者使用的模型采用自己生成的边界框。our T-CNN中作者修改了
F
A
F_A
FA,这里
F
A
F_A
FA 只用来抽取特征。Ensemble T-CNN中作者使用了不同的基于CNN的结构。
起码可以证明这种视觉-语义特征时间的直接映射是有效的。我感觉只要保证映射的正确性,那么分类的准确性上升是可以保证的,但这种直接映射的方式是最佳选择吗?
1.4.4 模型分析

我们通过比较模型的不同变体来进行详细分析:(1)仅回归排名网络作为具有语义嵌入的FB; (2) 不使用边界框的两级CNN模型; (3) 我们在训练阶段带有边界框的完整两级 CNN 模型。 结果如表 2 所示。通过利用外部知识的语义嵌入,当使用最强大的特征提取器(AlexNet+ResNet)时,我们获得了最高结果 87.0%。 通过比较(1)和(2)的设置,我们证明了定位网络的有效性。 特别是,定位网络学习的特征是对我们的回归排名网络的关注信息。
1.5 结论
- 文章有效地利用了语义信息来简化FGIC问题
- 将结构化的KB信息与非结构化的文本信息统一处理,使得他们都能对提高分类准确性产生积极影响
- 作者认为由于梯度传递带来的attention作用是有效的
1.6 思考
- 作者这里使用的语义信息嵌入直接套用了前人的工作,从思路上来讲确实很有新意,但方法上来看基本没有什么改动——可以认为是拓展了原有模型的应用领域
- 分析来看loss的传播应该是对 F A F_A FA有attention作用的,但缺乏验证
- 作者其实也没有强调 直接映射 本身的作用,但似乎作者所最突出的处理方式就是“特征直接映射+边界框损失”,能不能有更好的方式实现特征之间的映射从而更有效地利用语义信息呢?
- 值得关注的是人类识别机制分析。人类在识别一个物体时,缺失能有更多的有效信息供参考,这些知识来自于经验或者非视觉形式的信息,这也是当前视觉神经网络没能运用到的一个层面
总结
本周学习了基于细粒度图像分类的视觉语义嵌入模型,这种模型特别适用于细粒度图像分类任务,如不同品种的鸟类或花卉识别,它通过学习图像中的细节特征和全局上下文信息,能够捕捉到图像中微小但具有区分性的视觉差异。这些嵌入向量不仅能够反映图像的视觉属性,还能够表达图像的语义信息,从而使得模型在面对类别间相似性高的挑战时,仍能实现高精度的分类效果。下周我将继续阅读细粒度图像分类相关的文献,加油加油~