目录
一、Scikit是什么?
二、用Scikit做一个简单房价预测例子
三、sklearn知识点
一、Scikit是什么?

Scikit就是scikit-learn,是一个免费软件机器学习库。
https://scikit-learn.org/stable/![]() https://scikit-learn.org/stable/
https://scikit-learn.org/stable/
- 用于预测数据分析的简单高效的工具
- 每个人都可以访问,并可在各种环境中重复使用
- 基于NumPy、SciPy和matplotlib构建
- 开放源代码,商业可用-BSD许可证
二、用Scikit做一个简单房价预测例子
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
import matplotlib
# 设置默认字体为中文字体,如黑体
matplotlib.rcParams['font.family'] = 'SimHei'
# 假设的数据集
data = {
'面积': [80, 100, 120, 140, 160],
'卧室数量': [2, 3, 3, 4, 4],
'楼层': [5, 10, 15, 20, 25],
'房价(万元)': [50, 60, 70, 80, 90]
}
df = pd.DataFrame(data)
# 划分数据集
X = df[['面积', '卧室数量', '楼层']]
y = df['房价(万元)']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = LinearRegression()
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
# 评估模型
mse = mean_squared_error(y_test, y_pred)
# 打印均方误差
print(f"Mean Squared Error: {mse}")
# 绘制训练数据散点图
plt.scatter(X_train['面积'], y_train, color='blue', label='Training Data')
# 绘制测试数据散点图
plt.scatter(X_test['面积'], y_test, color='red', label='Test Data')
# 绘制预测线
plt.plot(X_test['面积'], y_pred, color='green', label='Predictions', linewidth=5)
# 添加图例和标题
plt.legend()
plt.title('XX城市房价预测模型')
plt.xlabel('面积')
plt.ylabel('房价(万元)')
# 预测新数据
new_data = [[150, 4, 22]]
predicted_price = model.predict(new_data)
print(f"预测新数据(面积150平米,4个卧室,22楼)的房价: {predicted_price[0]}")
plt.scatter(new_data[0][0], predicted_price[0], color='yellow', label='预测数据')
new_data = [[120, 3, 22]]
predicted_price = model.predict(new_data)
print(f"预测新数据(面积120平米,3个卧室,22楼)的房价: {predicted_price[0]}")
plt.scatter(new_data[0][0], predicted_price[0], color='yellow', label='预测数据')
new_data = [[80, 3, 22]]
predicted_price = model.predict(new_data)
print(f"预测新数据(面积80平米,2个卧室,22楼)的房价: {predicted_price[0]}")
plt.scatter(new_data[0][0], predicted_price[0], color='yellow', label='预测数据')
# 显示图表
plt.show()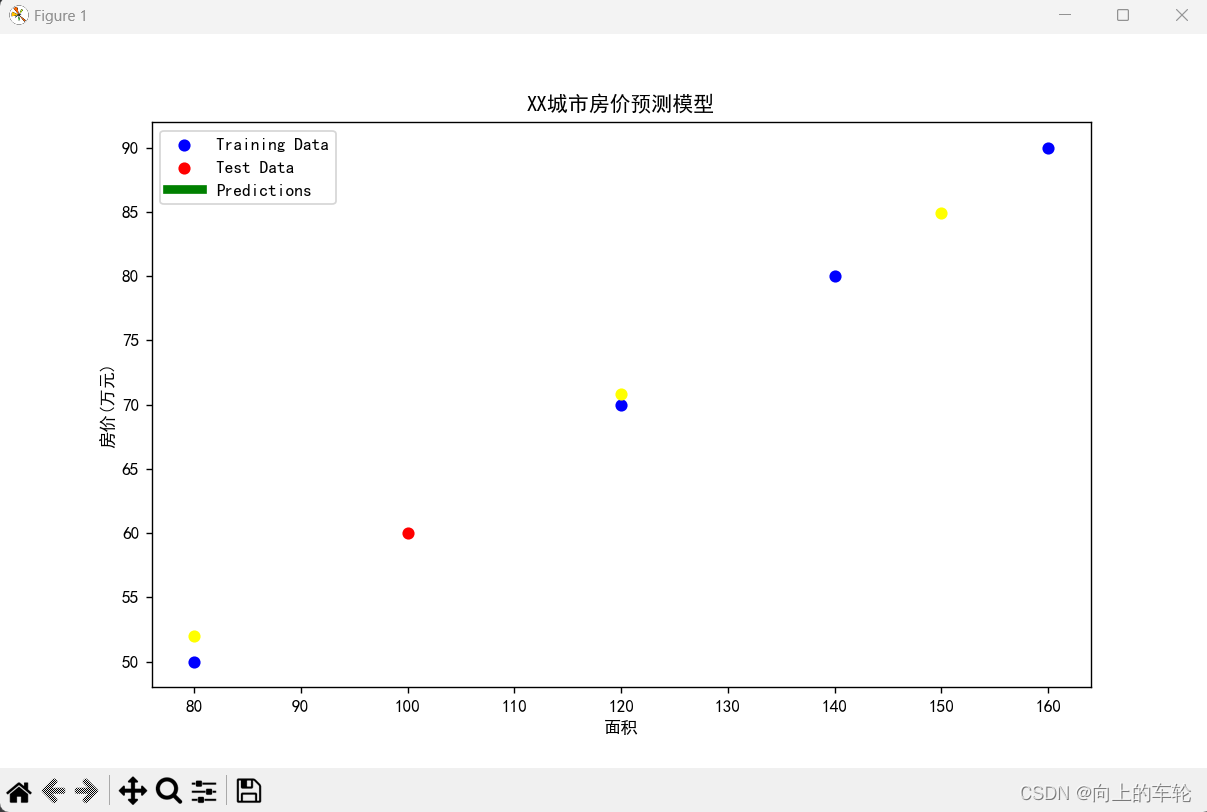
三、sklearn知识点
sklearn包含了各种分类、回归、聚类算法,并且接口统一,使用方便,是机器学习领域非常受欢迎的库之一。主要功能:
-
分类(Classification):
sklearn提供了多种分类算法,如逻辑回归(Logistic Regression)、支持向量机(Support Vector Machines, SVM)、决策树(Decision Trees)、随机森林(Random Forests)、梯度提升(Gradient Boosting)等,用于解决分类问题。 -
回归(Regression):对于预测连续值的问题,
sklearn提供了线性回归(Linear Regression)、岭回归(Ridge Regression)、套索回归(Lasso Regression)等回归算法。 -
聚类(Clustering):
sklearn包含K-均值(K-Means)、层次聚类(Hierarchical Clustering)、DBSCAN等聚类算法,用于发现数据中的结构或组。 -
降维(Dimensionality Reduction):通过主成分分析(Principal Component Analysis, PCA)、t-SNE(t-Distributed Stochastic Neighbor Embedding)等方法,
sklearn可以帮助减少数据集的维度,以便于可视化或提高算法效率。 -
模型选择和评估(Model Selection and Evaluation):
sklearn提供了交叉验证(Cross-validation)、网格搜索(Grid Search)等工具,用于评估和调整模型性能,选择最佳参数。 -
预处理(Preprocessing):包括数据标准化(Standardization)、归一化(Normalization)、编码(Encoding,如独热编码One-Hot Encoding)等,以便机器学习算法能够更有效地工作。
-
特征提取(Feature Extraction):
sklearn可以从原始数据中提取有用的特征,例如文本数据的词袋模型(Bag of Words)、TF-IDF(Term Frequency-Inverse Document Frequency)等。 -
数据可视化(Data Visualization):虽然
scikit-learn本身不是专门的数据可视化库,但它与matplotlib、seaborn等可视化库可以很好地配合,用于展示数据和模型结果。
总的来说,scikit-learn是一个非常全面且强大的机器学习库,适用于各种规模和复杂度的数据科学项目。
数据分析,智慧之源。用数据说话,让我们一起洞悉规律,发现机遇。