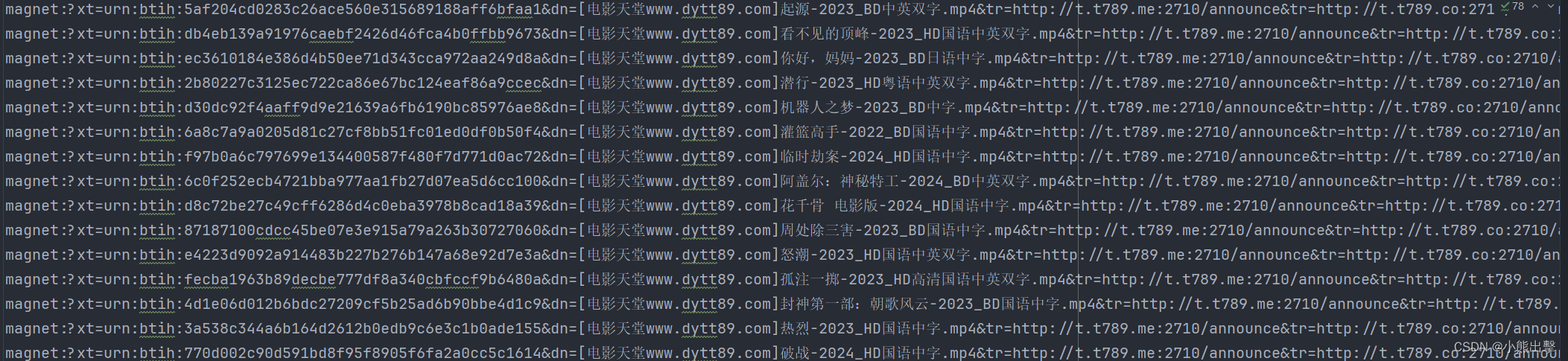
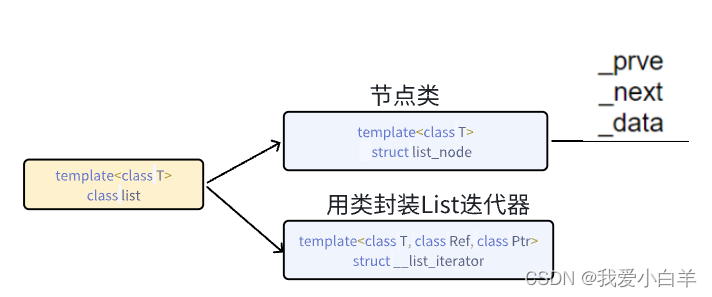
进入电影天堂首页,提取到主页面中的每一个电影的背后的那个urL地址 访问子页面,提取到电影的名称以及下载地址 from tqdm import tqdm
import requests
import re
from selenium import webdriver
from selenium. webdriver. edge. options import Options
class MovieScraper :
"""
MovieScraper类用于从网站抓取电影信息。
属性
----------
edge_options : Options
用于配置webdriver的selenium Options对象
web_driver : webdriver
用于与网站交互的selenium webdriver
request_headers : dict
包含请求头的字典
方法
-------
get_response(url)
向指定的URL发送GET请求并返回响应。
get_movie_list_html(response)
从响应中提取电影列表的HTML。
get_sub_url_list(movie_list_html)
从电影列表HTML中提取子URL。
get_movie_info(child_response)
从子URL的响应中提取电影信息。
scrape(target_url)
从指定的URL抓取电影信息并写入文件。
"""
def __init__ ( self) :
"""初始化MovieScraper,配置webdriver和请求头。"""
self. edge_options = Options( )
self. edge_options. add_argument( "headless" )
self. web_driver = webdriver. Edge( options= self. edge_options)
self. request_headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
}
def get_response ( self, url) :
"""
向指定的URL发送GET请求并返回响应。
参数
----------
url : str
要发送请求的URL。
返回
-------
response : Response
GET请求的响应。
"""
response = requests. get( url, headers= self. request_headers)
response. encoding = "gbk"
return response
def get_movie_list_html ( self, response) :
"""
从响应中提取电影列表的HTML。
参数
----------
response : Response
要提取HTML的响应。
返回
-------
movie_list_html : str
电影列表的HTML。
"""
movie_list_pattern = re. compile ( r'2024必看热片.*?<ul>(?P<html>.*?)</ul>' , re. S)
movie_list_result = movie_list_pattern. search( response. text)
return movie_list_result. group( "html" )
def get_sub_url_list ( self, movie_list_html) :
"""
从电影列表HTML中提取子URL。
参数
----------
movie_list_html : str
电影列表的HTML。
返回
-------
sub_url_list : iterator
子URL的迭代器。
"""
sub_url_pattern = re. compile ( r"<li><a href='(?P<sub_url>.*?)'" , re. S)
return sub_url_pattern. finditer( movie_list_html)
def get_movie_info ( self, child_response) :
"""
从子URL的响应中提取电影信息。
参数
----------
child_response : Response
要提取电影信息的响应。
返回
-------
movie_info_result : Match
包含电影信息的匹配对象。
"""
movie_info_pattern = re. compile ( r'◎片 名 (?P<movie>.*?)<br.*?<td style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<download>.*?)"' , re. S)
return movie_info_pattern. search( child_response. text)
def scrape ( self, target_url) :
"""
从指定的URL抓取电影信息并写入文件。
参数
----------
target_url : str
要抓取电影信息的URL。
"""
self. web_driver. get( target_url)
response = self. get_response( target_url)
movie_list_html = self. get_movie_list_html( response)
sub_url_list = self. get_sub_url_list( movie_list_html)
with open ( "电影天堂.txt" , "w" , encoding= "utf-8" ) as file :
for sub_url in tqdm( sub_url_list, desc= "处理URL中" , unit= "URL" ) :
child_url = target_url + sub_url. group( "sub_url" )
child_response = self. get_response( child_url)
movie_info_result = self. get_movie_info( child_response)
download_link = movie_info_result. group( "download" )
file . write( download_link + "\n" )
self. web_driver. quit( )
print ( "爬取完毕" )
if __name__ == "__main__" :
scraper = MovieScraper( )
scraper. scrape( "https://www.dy2018.com/" )