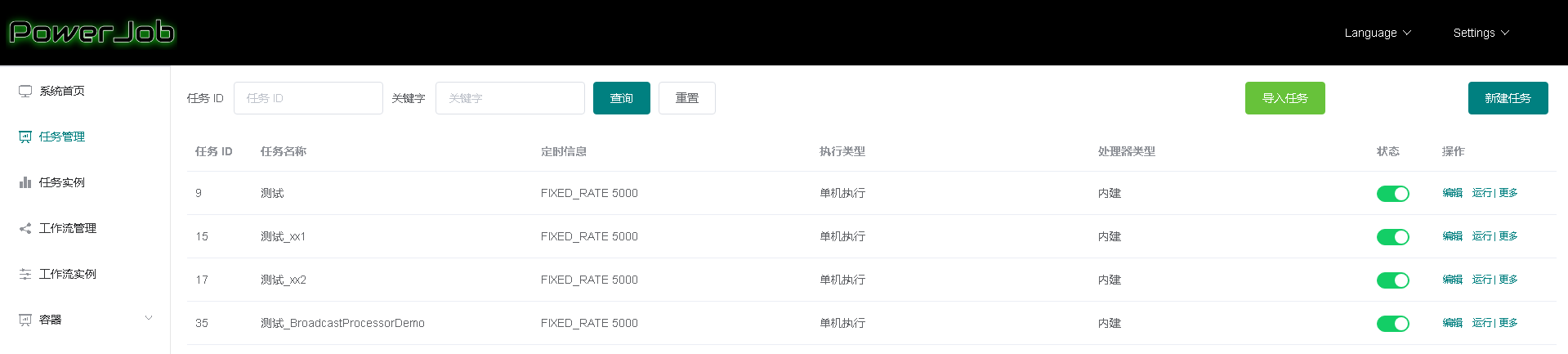
重建表
alter table t engine = InnoDB(也就是recreate),而optimize table t 等于recreate+analyze,让表大小变小
重建表的执行流程
- 建立一个临时文件,扫描表 t 主键的所有数据页;
- 用数据页中表 t 的记录生成 B+ 树,存储到临时文件中;
- 生成临时文件的过程中,将所有对 t 的操作记录在一个日志文件(row log)中;
- 临时文件生成后,将日志文件中的操作应用到临时文件,得到一个逻辑数据上与表 t相同的数据文件;
- 用临时文件替换表 t 的数据文件。
注意:在重建表的时候, InnoDB不会把整张表占满, 每个页留了1/16给后续的更新用。 也就是说, 其实重建表之后不是“最”紧凑的。
Online DDL
ALTER TABLE tbl_name ADD COLUMN col_name col_type, ALGORITHM=INPLACE, LOCK=NONE;
LOCK选项
- SHARE:共享锁,执行DDL的表可以读,但是不可以写。
- NONE:没有任何限制,执行DDL的表可读可写。
- EXCLUSIVE:排它锁,执行DDL的表不可以读,也不可以写。
- DEFAULT:默认值,也就是在DDL语句中不指定LOCK子句的时候使用的默认值。如果指定LOCK的值为DEFAULT,那就是交给MySQL子句去觉得锁还是不锁表。不建议使用,如果你确定你的DDL语句不会锁表,你可以不指定lock或者指定它的值为default,否则建议指定它的锁类型。
准备:
1、对表加元数据共享升级锁,并升级为排他锁;(此时DML不能并行)
2、判断使用inplace算法
3、判断语句是“rebuild table” 还是 “no-rebuild”,rebuild 在原表所在的路径下创建.frm和.ibd临时中转文件;
【在引擎层克隆,而不是像copy那样,在server层创建(create like)】
注意:加列的操作是需要rebuild table的
【rebuild table】---生成中转文件表
++++
no-rebuild的情况:
除创建二级索引外只创建.frm文件,其中添加二级索引操作最为特殊,该操作属于no-rebuild不会生成.ibd,
但实际上对.ibd文件却做了修改,该操作会在参数tmpdir指定路径下生成临时文件,用于存储索引排序结果,然后再合并到.ibd文件中
++++
4、申请row log空间,用于存放DDL执行阶段产生的DML操作。(no-rebuild不需要)【在innodb_sort_buffer块中】
执行:(online)
1、释放排他锁,保留元数据共享升级锁;(此时DML可以并行)
2、扫描原表主键以及二级索引的所有数据页,生成 B+ 树,存储到临时文件中;【在引擎层扫描,最耗时】
3、将所有对原表的DML操作记录在日志文件row log中,并回放部分row_log。
提交阶段:
1、升级元数据共享升级锁,产生排他锁锁表;(此时DML不能并行了)
2、重做row log中的内容;(no-rebuild不需要)
3、重命名原表文件,将临时文件改名为原表文件名,删除原表文件;
4、提交事务,变更完成。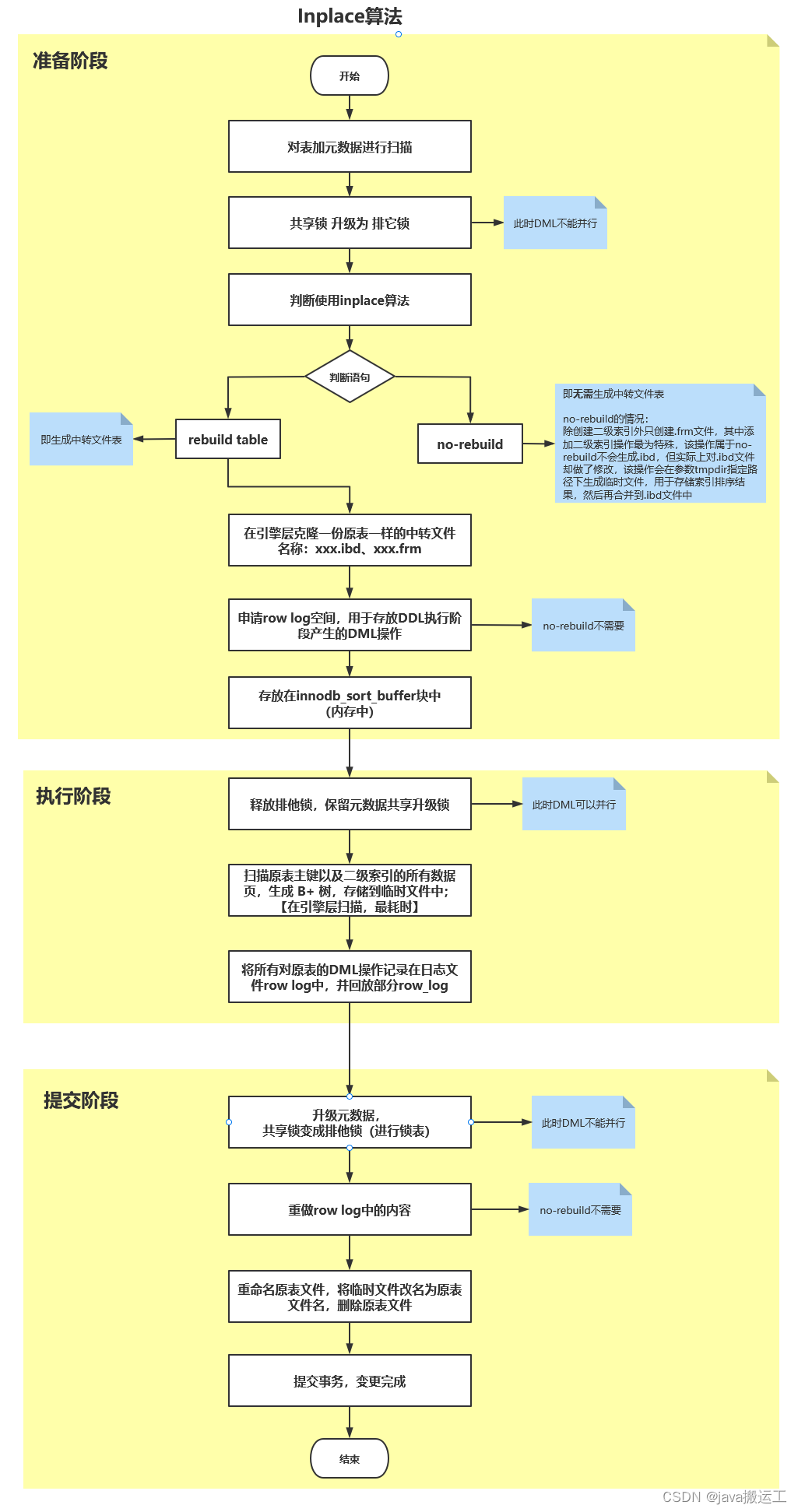
在 InnoDB 引擎中 count(*)、count(1)、count(主键)、count(字段) 哪个性能最高?
count(字段)<count(主键 id)<count(1)≈count(*) 题目解析:
- 对于 count(主键 id) 来说,InnoDB 引擎会遍历整张表,把每一行的 id 值都取出来,返回给 server 层。server 层拿到 id 后,判断是不可能为空的,就按行累加。
- 对于 count(1) 来说,InnoDB 引擎遍历整张表,但不取值。server 层对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加。
- 对于 count(字段) 来说,如果这个“字段”是定义为 not null 的话,一行行地从记录里面读出这个字段,判断不能为 null,按行累加;如果这个“字段”定义允许为 null,那么执行的时候,判断到有可能是 null,还要把值取出来再判断一下,不是 null 才累加。
- 对于 count(*) 来说,并不会把全部字段取出来,而是专门做了优化,不取值,直接按行累加。
所以最后得出的结果是:count(字段)<count(主键 id)<count(1)≈count(*)。
–single-transaction逻辑备份
当mysqldump使用参数–single-transaction的时候, 导数据之前就会启动一个事务, 来确保拿到一致性视图。
single-transaction方法只适用于所有的表使用事务引擎的库。 如果有的表使用了不支持事务的引擎, 那么备份就只能通过FTWRL(全局锁)方法。
这往往是DBA要求业务开发人员使用InnoDB替代MyISAM的原因之一。
当备库用–single-transaction做逻辑备份的时候, 如果从主库的binlog传来一个DDL语句会怎么样?
Q1:SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
Q2:START TRANSACTION WITH CONSISTENT SNAPSHOT;
/* other tables */
Q3:SAVEPOINT sp;
/* 时刻 1 */
Q4:show create table `t1`;
/* 时刻 2 */
Q5:SELECT * FROM `t1`;
/* 时刻 3 */
Q6:ROLLBACK TO SAVEPOINT sp;
/* 时刻 4 */
/* other tables */1. 如果在Q4语句执行之前到达, 现象: 没有影响, 备份拿到的是DDL后的表结构。
2. 如果在“时刻 2”到达, 则表结构被改过, Q5执行的时候, 报 Table definition has changed,please retrytransaction, 现象: mysqldump终止;
3. 如果在“时刻2”和“时刻3”之间到达, mysqldump占着t1的MDL读锁, binlog被阻塞, 现象:主从延迟, 直到Q6执行完成。
4. 从“时刻4”开始, mysqldump释放了MDL读锁, 现象: 没有影响, 备份拿到的是DDL前的表结构。
删除一个表里面的前10000行数据
要删除一个表里面的前10000行数据, 有以下三种方法可以做到:
第一种, 直接执行delete from Tlimit 10000;
第二种, 在一个连接中循环执行20次 delete from Tlimit 500;
第三种, 在20个连接中同时执行delete from Tlimit 500。
分析:
第一种方式(即: 直接执行delete from Tlimit 10000) 里面, 单个语句占用时间长, 锁的时间也比较长; 而且大事务还会导致主从延迟。
第二种方式是相对较好的。
第三种方式(即: 在20个连接中同时执行delete from Tlimit 500) , 会人为造成锁冲突。
change buffer
当需要更新一个数据页时, 如果数据页在内存中就直接更新, 而如果这个数据页还没有在内存中的话, 在不影响数据一致性的前提下, InooDB会将这些更新操作缓存在change buffer中, 这样就不需要从磁盘中读入这个数据页了。 在下次查询需要访问这个数据页的时候, 将数据页读入内存, 然后执行change buffer中与这个页有关的操作。 通过这种方式就能保证这个数据逻辑的正确性。将change buffer中的操作应用到原数据页, 得到最新结果的过程称为merge。 除了访问这个数据页会触发merge外, 系统有后台线程会定期merge。 在数据库正常关闭(shutdown) 的过程中,也会执行merge操作。对于唯一索引来说, 所有的更新操作都要先判断这个操作是否违反唯一性约束。 比如, 要插入(4,400)这个记录, 就要先判断现在表中是否已经存在k=4的记录, 而这必须要将数据页读入内存才能判断。 如果都已经读入到内存了, 那直接更新内存会更快, 就没必要使用change buffer了。
因此, 唯一索引的更新就不能使用change buffer, 实际上也只有普通索引可以使用。change buffer用的是buffer pool里的内存, 因此不能无限增大。 change buffer的大小, 可以通
过参数innodb_change_buffer_max_size来动态设置。 这个参数设置为50的时候, 表示changebuffer的大小最多只能占用buffer pool的50%。将数据从磁盘读入内存涉及随机IO的访问, 是数据库里面成本最高的操作之一。 change buffer因为减少了随机磁盘访问, 所以对更新性能的提升是会很明显的。
merge的执行流程是这样的:
1. 从磁盘读入数据页到内存(老版本的数据页) ;
2. 从change buffer里找出这个数据页的change buffer 记录(可能有多个) , 依次应用, 得到新版数据页;
3. 写redo log。 这个redo log包含了数据的变更和change buffer的变更。
redo log 主要节省的是随机写磁盘的IO消耗( 转成顺序写) , 而change buffer主要节省的则是随机读磁盘的IO消耗。
字符集不同连表查询用不上索引
performance_schema库优化
MySQL 5.6版本以后提供的performance_schema库, 就在file_summary_by_event_name
表里统计了每次IO请求的时间

Buffer Pool
Buffer Pool对查询的加速效果, 依赖于一个重要的指标, 即: 内存命中率。
你可以在show engine innodb status结果中, 查看一个系统当前的BP命中率。 一般情况下, 一个稳定服务的线上系统, 要保证响应时间符合要求的话, 内存命中率要在99%以上。
执行show engine innodb status , 可以看到“Buffer pool hit rate”字样, 显示的就是当前的命中率。
InnoDB Buffer Pool的大小是由参数 innodb_buffer_pool_size确定的, 一般建议设置成可用物理内存的60%~80%。
所以, innodb_buffer_pool_size小于磁盘的数据量是很常见的。 如果一个 Buffer Pool满了, 而又要从磁盘读入一个数据页, 那肯定是要淘汰一个旧数据页的。
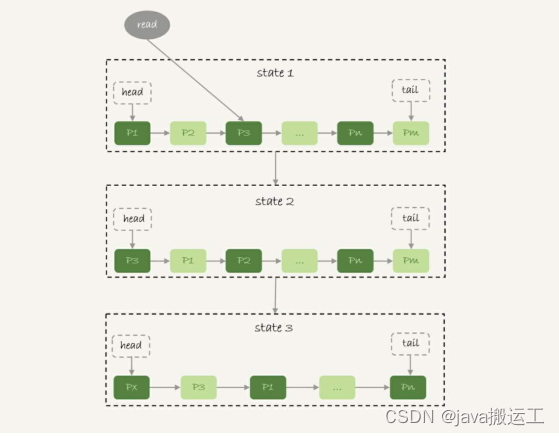
InnoDB管理Buffer Pool的LRU算法, 是用链表来实现的。
1. 在图的状态1里, 链表头部是P1, 表示P1是最近刚刚被访问过的数据页; 假设内存里只能放下这么多数据页;
2. 这时候有一个读请求访问P3, 因此变成状态2, P3被移到最前面;
3. 状态3表示, 这次访问的数据页是不存在于链表中的, 所以需要在Buffer Pool中新申请一个
数据页Px, 加到链表头部。 但是由于内存已经满了, 不能申请新的内存。 于是, 会清空链表
末尾Pm这个数据页的内存, 存入Px的内容, 然后放到链表头部。
4. 从效果上看, 就是最久没有被访问的数据页Pm, 被淘汰了。
实际上, InnoDB对LRU算法做了改进
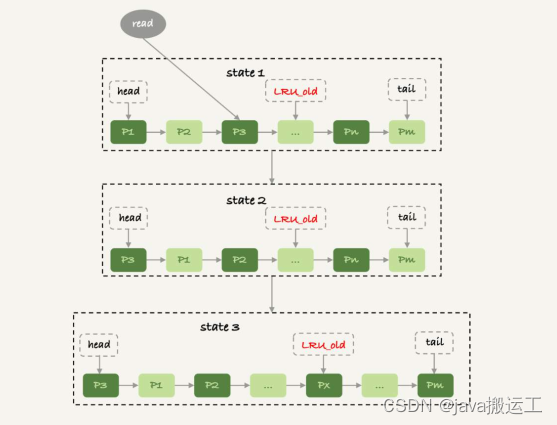
在InnoDB实现上, 按照5:3的比例把整个LRU链表分成了young区域和old区域。 图中LRU_old指向的就是old区域的第一个位置, 是整个链表的5/8处。 也就是说, 靠近链表头部的5/8是young区域, 靠近链表尾部的3/8是old区域。改进后的LRU算法执行流程变成了下面这样。
1. 图7中状态1, 要访问数据页P3, 由于P3在young区域, 因此和优化前的LRU算法一样, 将其移到链表头部, 变成状态2。
2. 之后要访问一个新的不存在于当前链表的数据页, 这时候依然是淘汰掉数据页Pm, 但是新插入的数据页Px, 是放在LRU_old处。
3. 处于old区域的数据页, 每次被访问的时候都要做下面这个判断:
若这个数据页在LRU链表中存在的时间超过了1秒, 就把它移动到链表头部;
如果这个数据页在LRU链表中存在的时间短于1秒, 位置保持不变。 1秒这个时间, 是由参数innodb_old_blocks_time控制的。 其默认值是1000, 单位毫秒。
MySQL采用的是边算边发的逻辑, 因此对于数据量很大的查询结果来说, 不会在server端保存完整的结果集。 所以, 如果客户端读结果不及时, 会堵住MySQL的查询过程, 但是不会把内
存打爆。而对于InnoDB引擎内部, 由于有淘汰策略, 大查询也不会导致内存暴涨。 并且, 由于InnoDB对LRU算法做了改进, 冷数据的全表扫描, 对Buffer Pool的影响也能做到可控。
InnoDB对Bufffer Pool的LRU算法做了优化,
即: 第一次从磁盘读入内存的数据页, 会先放在old区域。 如果1秒之后这个数据页不再被访问了, 就不会被移动到LRU链表头部, 这样对Buffer Pool的命中率影响就不大。
但是, 如果一个使用BNL算法的join语句(无索引join,参考https://www.cnblogs.com/booksea/p/17380941.html), 多次扫描一个冷表, 而且这个语句执行时间超过1秒,就会在再次扫描冷表的时候, 把冷表的数据页移到LRU链表头部。
这种情况对应的, 是冷表的数据量小于整个Buffer Pool的3/8, 能够完全放入old区域的情况。如果这个冷表很大, 就会出现另外一种情况: 业务正常访问的数据页, 没有机会进入young区
域。由于优化机制的存在, 一个正常访问的数据页, 要进入young区域, 需要隔1秒后再次被访问到。 但是, 由于我们的join语句在循环读磁盘和淘汰内存页, 进入old区域的数据页, 很可能在1秒之内就被淘汰了。 这样, 就会导致这个MySQL实例的Buffer Pool在这段时间内, young区域的数据页没有被合理地淘汰。也就是说, 这两种情况都会影响Buffer Pool的正常运作。
大表join操作虽然对IO有影响, 但是在语句执行结束后, 对IO的影响也就结束了。 但是,对Buffer Pool的影响就是持续性的, 需要依靠后续的查询请求慢慢恢复内存命中率。
判断要不要使用join语句时, 就是看explain结果里面, Extra字段里面有没有出现“BlockNested Loop”字样。




![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-11.1,11.2-BSP文件目录组织](https://img-blog.csdnimg.cn/direct/de75adfcdefa4a27b376d185622712ff.png)