目录
1.创建对象
1.一维对象
1.字典创建法
2.数组创建法
2.二维对象
1.字典创建法
2.数组创建法
2.对象的索引
1.一维对象的索引
1.查询
2.切片
2.二维对象的索引
1.访问
2.修改
3.对象的变形
1.对象的转置
2.上下翻转和左右翻转
3.对象的重塑
4.一维对象的合并
5.一维对象和二维对象的合并
6.二维对象的合并
4.对象的计算
1.带有系数的计算
2.对象之间的运算
5.针对NaN的处理
1.发现缺失值
2.去除缺失值
3.填补缺失值
6.读取excel表(CSV格式)
pandas标签库是用来给numpy数组加上行列标签,类似于字典一样。
1.创建对象
1.一维对象
1.字典创建法
通过Series函数将py里的字典转化为Pandas对象。
import pandas as pd
dict_v={'a':111,'b':222,'c':333}
sr=pd.Series(dict_v)
sr结果为

同时也返回值的数据类型为整型
2.数组创建法
也是用series函数,但是需要先定义键与值。其中第一个参数为值,第二个参数为键,也可以指明index和data。其中data可以是列表、数组、字典或标量值。
k=['a','b','c']
v=[111,222,333]
sr=pd.Series(data=v,index=k)
sr结果为

与sr=pd.Series(v,k)等效。
且可以查出values属性,只需要sr.values即可。
![]()
是一个数组。
2.二维对象
二维对象不仅有行索引还有列索引。
1.字典创建法
将每一列的数据作为一个Series对象,然后将这些Series对象合并成一个DataFrame。列索引在DataFrame函数中标明,用法是({x:sr1,y:sr2……}),x,y就是列索引。
k1=['1号','2号','3号']
v1=[100,80,90]
sr1=pd.Series(v1,k1)
k2=['1号','2号','3号']
v2=['男','女','男']
sr2=pd.Series(v2,k2)
k3=['1号','2号','3号']
v3=['N','Y','N']
sr3=pd.Series(v3,k3)
df=pd.DataFrame({'分数':sr1,'性别':sr2,'是否是班干':sr3})
df结果为
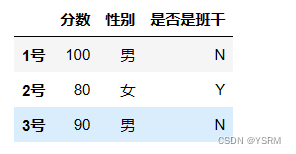
其中号码为行索引,分数、性别以及班干是列索引。
但是要确保这些series对象键相同,否则会造成拼接自动补空。
k1=['1号','2号','3号','4号']#缺五号和六号
v1=[100,80,90,98]
sr1=pd.Series(v1,k1)
k2=['1号','2号','3号','5号']#缺四号和六号
v2=['男','女','男','女']
sr2=pd.Series(v2,k2)
k3=['1号','2号','3号','6号']#缺四号和五号
v3=['N','Y','N','Y']
sr3=pd.Series(v3,k3)
df=pd.DataFrame({'分数':sr1,'性别':sr2,'是否是班干':sr3})
df结果为
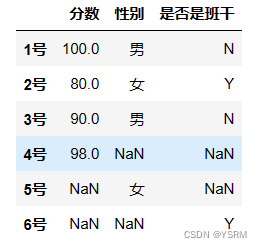
其中NaN就是空值。
2.数组创建法
这种方法不需要使用series对象,直接使用DataFrame函数。
data:可以是列表、数组、字典、DataFrame或其他可转换为二维结构的数据。如果是字典,则字典的键将作为列名,字典的值将作为对应列的数据。columns:指定列名,可以是列表或索引对象。如果未指定列名,将使用默认的整数索引。index:指定行索引,可以是列表、数组或索引对象。如果未指定行索引,将使用默认的整数索引。
data1=np.array([[100,'男'],[80,'女'],[90,'男']])
column=['分数','性别']
index1=['1号','2号','3号']
df=pd.DataFrame(data=data1,columns=column,index=index)
df结果为
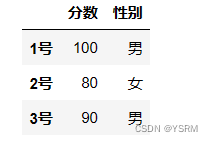
2.对象的索引
在 pandas 中,有两种类型的索引:显示索引(explicit index)和隐式索引(implicit index)。
loc属性是显示索引,iloc属性是隐式索引。
显示索引(Explicit Index):
- 显示索引是用户定义的,可以是任何唯一标识符,如字符串、数字、日期等。
- 对于 DataFrame,显示索引通常用于标识行。
- 对于 Series,显示索引用于标识每个数据点。
隐式索引(Implicit Index):
- 隐式索引是由 pandas 自动创建的整数序列,从 0 开始。
- 隐式索引用于标识 DataFrame 或 Series 中的行或列,特别是在未指定显示索引时。
- 隐式索引可以通过
.index和.columns属性访问。
1.一维对象的索引
1.查询
以下表为例

用显示索引操作
sr1.loc['1号']结果为
![]()
sr1.loc['1号']=90
sr1结果为

再用隐式索引进行操作
sr1.iloc[1]结果为
![]()
因为索引号是从0开始的
如果不加loc和iloc则默认是显示索引,隐式索引也可以使用,但是在未来的版本中,整数键将始终被视为标签,与 DataFrame 的行为保持一致。因此,为了避免这个警告,建议使用 iloc 方法来访问 Series 中的数据,以确保按照位置访问而不是标签访问。
sr1['1号']结果为
![]()
2.切片
切片是视图,会改变原对象的值,赋值绑定也会改变原对象的值。
还是以这个为例
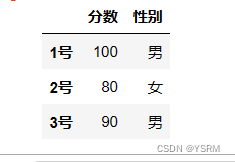
cut1=sr1['1号':'3号']#显示索引
cut1['1号']=666
sr1结果为

将1号原来的100改变为666了。
2.二维对象的索引
1.访问
访问时必须带上loc或者iloc,否则会报错。且由于是二维对象,访问时要注意行标签和列标签。
以下表为例
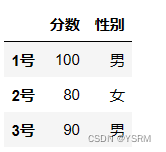
如果不加loc或者iloc,就会报错
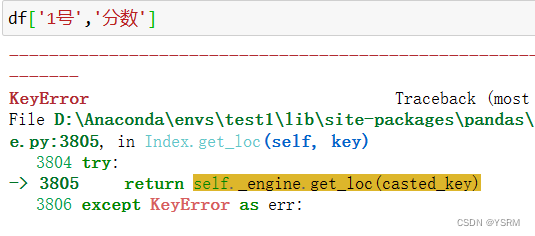
所以我们访问二维对象时必须加上loc或者iloc
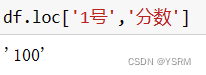
此外使用loc属性时还可以使用花式索引

输出1号和3号对应的性别属性,这也是一个二维对象,与numpy要区分开,numpy返回的时向量。
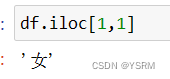
这是通过隐式索引来访问2号元素的性别,切记索引从0开始。
2.修改
修改二维对象时也必须加上loc或者iloc,否则会出现下图中的错误。
还是以上面的二维对象为例。

本意是改变2号分数,却弄巧成拙,新增了一列,所以要改变二维对象的值要加索引器。
正确的方式应该是这样的
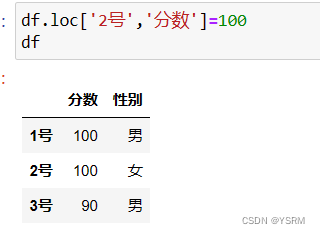
对于切片,和一维对象原理一样。
3.对象的变形
1.对象的转置
用T即可,下表为例
v=[[53,64,72,42],['女','女','女','男']]
i=['年龄','性别']
c=['1号','2号','3号','4号']
df=pd.DataFrame(v,index=i,columns=c)
df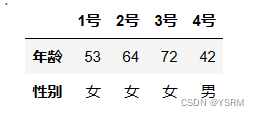
然后用T进行转置,就会得到一个使用起来正常的二维对象(行为号,列为属性)。

2.上下翻转和左右翻转
利用-1为间隔,就可以逆着来,达到上下翻转和左右翻转的效果。
还是以上表为例
上下倒置

左右倒置

3.对象的重塑
即二维对象分出一维对象,一维对象合成二维对象。
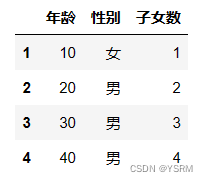
用下列三个一维对象合成二维对象
i=['1','2','3','4']
v1=[10,20,30,40]
v2=['女','男','男','男']
v3=[1,2,3,4]
sr1=pd.Series(v1,index=i)
sr2=pd.Series(v2,index=i)
sr3=pd.Series(v3,index=i)
sr1,sr2,sr3结果为

可以用字典法创建或者本节介绍的直接并的方法,相信大家看到这里以及可以掌握了字典法创建,所以我直接并了。但是要并的话,要首先有一个二维对象,所以我们先定义一个二维对象。
cf=pd.DataFrame()
cf['年龄']=sr1
cf['性别']=sr2
cf['子女数']=sr3
cf结果为
我们也可以分出一列,即分出一个一维对象。

如是,分出了一个性别对象。
4.一维对象的合并
用concat函数
原本是两个一维对象
v1=[10,20,30,40]
v2=[11,21,31]
k1=['1号','2号','3号','4号']
k2=['5号','6号','7号']
sr1=pd.Series(v1,index=k1)
sr2=pd.Series(v2,index=k2)
sr1,sr2
经过合并后,成为了具有7个对象的一维对象。

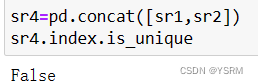
如果两个一维对象中有重复的地方怎么办???
不会像数组一样舍去重复的部分,证实如下

此外可以查其index属性是否重复,需要用到is_unique属性,如果重复,返回false,如果不重复返回true
5.一维对象和二维对象的合并
可以理解为在二维对象上加一列或一行
以此表为基础
i=['1','2','3','4']
v1=[10,20,30,40]
v2=['女','男','男','男']
v3=[1,2,3,4]
sr1=pd.Series(v1,index=i)
sr2=pd.Series(v2,index=i)
sr3=pd.Series(v3,index=i)
cf=pd.DataFrame()
cf['年龄']=sr1
cf['性别']=sr2
cf此时此表为

加上一列

加上一行(涉及二维对象的修改)
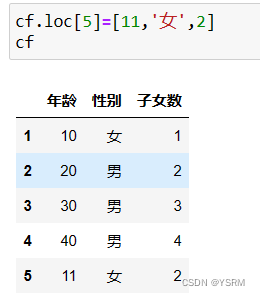
6.二维对象的合并
也涉及到concat函数,但是需要注意axis参数,axis为1代表列合并,axis=0代表行合并,默认为0
下面以三个二维对象为例子
v1=[[10,'女'],[20,'男'],[30,'男'],[40,'女']]
v2=[[1,'是'],[2,'是'],[3,'是'],[4,'否']]
v3=[[50,'男',5,'是'],[60,'女',6,'是']]
i1=['1','2','3','4']
i2=['1','2','3','4']
i3=['5','6']
c1=['年龄','性别']
c2=['孩子数','smoke']
c3=['年龄','性别','孩子数','smoke']
df1=pd.DataFrame(v1,index=i1,columns=c1)
df2=pd.DataFrame(v2,index=i2,columns=c2)
df3=pd.DataFrame(v3,index=i3,columns=c3)
df1,df2,df3
接下来会将这三个二维对象开始拼凑
将df1,df2进行列合并

将df再与df3进行行合并

4.对象的计算
遵循运算法则,是对内部元素的修改。
1.带有系数的计算
以此一维对象为例
v1=[11,21,31]
i1=['1','2','3']
sr=pd.Series(v1,i1)
sr
分别对其依次进行加减乘除

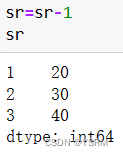
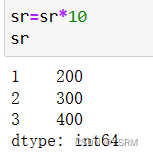
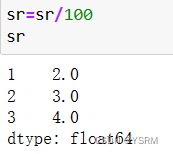
如果是二维对象,同理,但是要挑出你需要改变的该列(int或者float型)
2.对象之间的运算
对象之间维度可以不同,且只能数字部分进行运算
以下面两个一维对象为例
v1=[11,21,31]
v2=[10,20,30,40]
i1=['1','2','3']
i2=['1','2','3','4']
sr1=pd.Series(v1,i1)
sr2=pd.Series(v2,i2)
sr1,sr2
可以发现他们的维度不同
对其进行加法运算
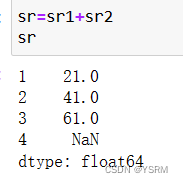
由于缺少一个加数,则为NaN
对于二维对象的相加,就要挑出可以运算的列
以下面两个二维对象为例
v1=[[10,'女'],[20,'男'],[30,'男'],[40,'女']]
v3=[[50,'男',5,'是'],[60,'女',6,'是']]
i1=['1','2','3','4']
i3=['5','6']
c1=['年龄','性别']
c3=['年龄','性别','孩子数','smoke']
df1=pd.DataFrame(v1,index=i1,columns=c1)
df3=pd.DataFrame(v3,index=i3,columns=c3)
df1,df3
将其中的年龄数进行相加

全是NaN,因为df3无1,2,3,4号
此外,bool型运算也适用于pandas对象,具体可看我上一篇文章
5.针对NaN的处理
1.发现缺失值
其中针对NaN的函数为isnull,检测某元素是否为空,若空返回True,非空返回False
notnull函数与其功能相反

2.去除缺失值
使用dropna函数,一维函数只会去除行,对于二维数组较难处理,因为可能去除含有缺失值的行,也有可能去除含有缺失值的列。axis=columns或者1去除列,axis=index或者0去除行。默认去除index。参数how='all'表示只有该行全是NaN,才去除该个特征。
在定义时是None而不是NaN
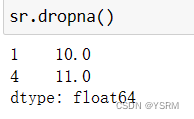
以下面的一维对象为例
v=[10,None,None,11]
i=['1','2','3','4']
sr=pd.Series(v,index=i)
sr
去除其中的NaN,将其中的2与3行去除
以下面的二维对象为例
v=[[10,20],[None,4],[6,6],[1,11]]
i=['1','2','3','4']
c=['年纪','分数']
df=pd.DataFrame(v,index=i,columns=c)
df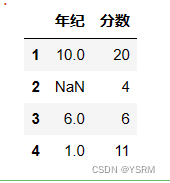
依次对行和列处理

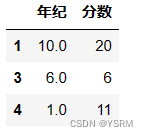
以下面的二维对象为例检测how参数的作用。
v=[[None,None],[None,4],[6,6],[1,11]]
i=['1','2','3','4']
c=['年纪','分数']
df=pd.DataFrame(v,index=i,columns=c)
df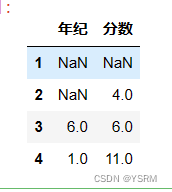
结果为
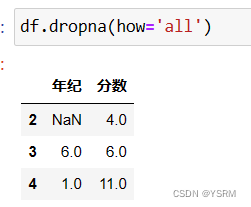
其中all也可以改成数字,表示超过这个数字,该行才该被删除。
3.填补缺失值
需要用到fillna函数,参数为你需要填充的数,将所有缺失值填满,method=ffill,表示用前一个的数进行填充,bfill表示用后面的参数填充,但目前版本已经过时了,可以直接用ffill函数和bfill函数。
以下面这个二维对象为例
v=[[None,None],[None,4],[6,6],[1,11]]
i=['1','2','3','4']
c=['年纪','分数']
df=pd.DataFrame(v,index=i,columns=c)
df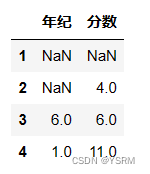
用0填充
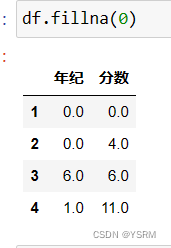
用后者数填充

用前者数填充

没想到吧,NaN也可以填充其他数。
6.读取excel表(CSV格式)
利用read_csv函数,excel表是可以生成csv形式的
以下表为例,一般都存在jupyter的dataset文件夹中
设置index_col=0参数是为了确保csv文件第一行是columns
此外,可以借助上一篇所学的方法对数据进行分析,修改等操作,最后
下面是一些常用的跟在read_csv.xxxx使用
head():
- 作用:返回 DataFrame 的前 N 行,主要用于快速查看数据的前几行。
- 参数:
n,整数,表示要显示的行数,默认为 5。- 用法示例:
df.head()或df.head(10)。tail():
- 作用:返回 DataFrame 的最后 N 行,与
head()相对应,用于查看数据的末尾。- 参数:
n,整数,表示要显示的行数,默认为 5。- 用法示例:
df.tail()或df.tail(10)。info():
- 作用:打印 DataFrame 的简要摘要,包括索引的类型和列、非空值的数量和每列的数据类型。
- 参数:无主要参数。
- 用法示例:
df.info()。describe():
- 作用:对于数值类型的列,返回描述性统计(如均值、标准差、最小值、最大值等)。对于对象和分类(categorical)类型的数据,返回计数、唯一值数量、众数等。
- 参数:
include和exclude,用于控制哪些数据类型应该被包含或排除在统计结果之外。- 用法示例:
df.describe()或df.describe(include=['O'])。sample():
- 作用:随机抽样 DataFrame 中的行。
- 参数:
n表示抽取的行数,frac表示抽取的比例。- 用法示例:
df.sample(n=10)或df.sample(frac=0.1)。dtypes:
- 作用:返回 DataFrame 每一列的数据类型。
- 用法示例:
df.dtypes。shape:
- 作用:返回 DataFrame 的维度,形式为 (行数, 列数)。
- 用法示例:
df.shape。columns:
- 作用:获取或设置 DataFrame 的列名。
- 用法示例:
df.columns或df.columns = ['new', 'column', 'names']。
原教学视频链接在这Python深度学习:Pandas标签库_哔哩哔哩_bilibili