Transformer 用于学习句子中的长距离依赖关系,同时执行序列到序列的建模。
它通过解决可变长度输入、并行化、梯度消失或爆炸、数据规模巨大等问题,比其他模型表现更好。使用的注意力机制是神经架构的一部分,使其能够动态突出显示输入数据的相关特征,仅关注必要的特征/单词。让我们看一个例子:
“I poured water from the bottle into the cup until it was full.”
这里的“it”指的是杯子
“I poured water from the bottle into the cup until it was empty.”
这里的“it”指的是瓶子
句子中的单一替换改变了对象“it”的引用。对于我或你来说,识别“it”所指的主体/对象是很容易的,但最终的任务是让机器学会这一点。
因此,如果我们翻译这样一个句子或尝试生成文本,机器必须知道单词“it”的指代对象。这可以通过深度学习机制“注意力”来实现。
注意力机制的使用赋予了 Transformer 很高的潜力。Transformer 的一个应用就是 BERT。
BERT 架构概述
BERT 代表双向编码器表示来自Transformer(BERT),用于高效地将高度非结构化的文本数据表示为向量。BERT是一个经过训练的 Transformer 编码器堆栈。
论文:https://arxiv.org/abs/1810.04805
主要有两种模型大小:BERT BASE和BERT LARGE。
BERT BASE和BERT LARGE之间的区别,即编码器的总数量。
“BERTBASE (L=12, H=768, A=12, Total Parameters=110M)
BERTLARGE (L=24, H=1024, A=16, Total Parameters=340M)
Where L = Number of layers (i.e; the total number of encoders)
H = Hidden size
A = Number of self-attention heads
”
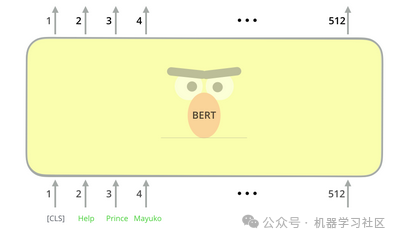
输入表示可以是单个句子或一对句子。在将输入传递到BERT之前,需要嵌入一些特殊的标记。
[CLS] - 每个序列的第一个标记(指的是传递给BERT的输入标记序列)始终是一个特殊的分类标记。
[SEP] - 句子对被打包成一个序列。我们可以通过这个特殊的标记区分句子。(另一种区分的方法是通过给每个标记添加一个学习嵌入,指示它是否属于句子A或句子B)
给定标记(单词)的输入表示是通过对应的标记、段和位置嵌入求和来构造的。
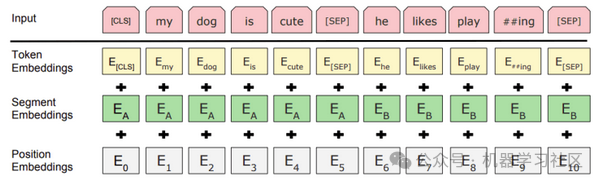
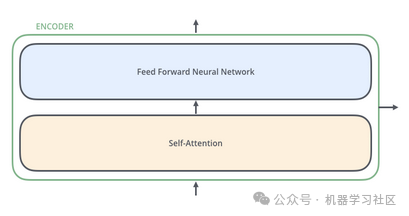
一旦输入标记准备好,它们就会在层叠中流动。每一层都应用自注意力,将其结果通过前馈网络传递,并将其交给下一个编码器。
在架构方面,它与 Transformer 保持相同。
我们为什么需要 BERT?
当我们已经有词嵌入时,为什么我们还需要 BERT?
一个词在不同的上下文中可能有不同的含义。例如,I encountered a bat when I went to buy a cricket bat.(我去买板球拍时遇到了一只蝙蝠),这里,第一次出现的bat“蝙蝠”,指的是一种哺乳动物,第二次出现的指的是一只球拍。
在这种情况下,bat“蝙蝠”这个词的第一次和第二次出现需要以不同的方式表示,因为它们的含义不同,但是词嵌入将它视为相同的词。
因此,将生成单个词bat“蝙蝠”的表示。这将导致错误的预测。BERT 嵌入将能够通过为同一个词bat“蝙蝠”生成两个不同的向量来区分和捕捉两个不同的语义含义。
使用 BERT 和 Hugging Face 进行情感分析
问题陈述:
分析2016年首次共和党总统辩论的推文情感。
- 安装 Hugging Face 的 Transformers 库
Hugging Face 是最受欢迎的自然语言处理社区之一,为深度学习研究人员、实践者和教育工作者提供支持。Transformers 库(以前称为 PyTorch-transformers)为自然语言理解(NLU)和自然语言生成(NLG)提供了广泛的通用架构(BERT、GPT-2、RoBERTa、XLM、DistilBert 等),拥有多种预训练模型。
!pip install transformers
-
加载和理解 BERT
2.1 下载预训练的 BERT 模型
我们将使用 BERT 基本模型的小写版本。它是在小写的英文文本上训练的。
from transformers import BertModel
bert = BertModel.from_pretrained('bert-base-uncased')
2.2 分词和输入格式化
下载 BERT 分词器
from transformers import BertTokenizerFast
tokenizer = BertTokenizerFast.from_pretrained('bert-base-uncased', do_lower_case=True)
输入格式化的步骤
- 分词
- 特殊标记
- 在序列开头添加 [CLS] 标记。
- 在序列末尾添加 [SEP] 标记。
- 填充序列
- 将标记转换为整数
- 创建注意力掩码以避免填充标记
# 输入文本
text = "Jim Henson was a puppeteer"
sent_id = tokenizer.encode(text,
# 添加 [CLS] 和 [SEP] 标记
add_special_tokens=True,
# 指定序列的最大长度
max_length = 10,
truncation = True,
# 在序列的右侧添加填充标记
pad_to_max_length='right')
# 打印整数序列
print("整数序列: {}".format(sent_id))
# 将整数转换回文本
print("标记化文本:",tokenizer.convert_ids_to_tokens(sent_id))
输出
整数序列: [101, 3958, 27227, 2001, 1037, 13997, 11510, 102, 0, 0]
标记化文本: ['[CLS]', 'jim', 'henson', 'was', 'a', 'puppet', '##eer', '[SEP]', '[PAD]', '[PAD]']
解码标记化文本
decoded = tokenizer.decode(sent_id)
print("解码字符串: {}".format(decoded))
输出
解码字符串: [CLS] jim henson was a puppeteer [SEP] [PAD] [PAD]
避免对填充标记索引执行注意力的掩码。 掩码值:未屏蔽的标记为 1,屏蔽的标记为 0。
att_mask = [int(tok > 0) for tok in sent_id]
print("注意力掩码:",att_mask)
注意力掩码: [1, 1, 1, 1, 1, 1, 1, 1, 0, 0]
2.3 理解输入和输出
# 将列表转换为张量
sent_id = torch.tensor(sent_id)
att_mask = torch.tensor(att_mask)
# 将张量调整为(批量大小,文本长度)的形式
sent_id = sent_id.unsqueeze(0)
att_mask = att_mask.unsqueeze(0)
print(sent_id)
输出
tensor([[ 101, 3958, 27227, 2001, 1037, 13997, 11510, 102, 0, 0]])
# 将整数序列传递给 BERT 模型
outputs = bert(sent_id, attention_mask=att_mask)
# 解包 BERT 模型的输出
# 每个时间步的隐藏状态
all_hidden_states = outputs[0]
# 第一个时间步的隐藏状态([CLS] 标记)
cls_hidden_state = outputs[1]
print("最后一个隐藏状态的形状:",all_hidden_states.shape)
print("CLS 隐藏状态的形状:",cls_hidden_state.shape)
输出
最后一个隐藏状态的形状: torch.Size([1, 10, 768])
CLS 隐藏状态的形状: torch.Size([1, 768])
-
准备数据
3.1 加载和读取 Twitter 航空公司数据
import pandas as pd
df = pd.read_csv('/content/drive/MyDrive/Sentiment.csv')
print(df.shape)
输出
(13871, 21)
df['text'].sample(5)
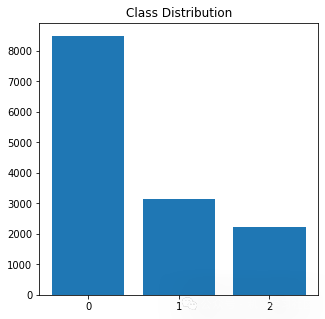
# class distribution
print(df['sentiment'].value_counts(normalize = True))
# saving the value counts to a list
class_counts = df['sentiment'].value_counts().tolist(
Output
Negative 0.612285
Neutral 0.226516
Positive 0.161200
Name: sentiment, dtype: float64
3.2 文本清洗
定义文本清洗函数
# 导入用于模式匹配的库
import re
def preprocessor(text):
# 将文本转换为小写
text = text.lower()
# 移除用户提及
text = re.sub(r'@[A-Za-z0-9]+','',text)
# 移除主题标签
# text = re.sub(r'#[A-Za-z0-9]+','',text)
# 移除链接
text = re.sub(r'http\S+', '', text)
# 分割单词以去除额外空格
tokens = text.split()
# 以空格连接单词
return " ".join(tokens)
# 执行文本清洗
df['clean_text'] = df['text'].apply(preprocessor)
# 将清理后的文本和标签保存到变量中
text = df['clean_text'].values
labels = df['sentiment'].values
print(text[50:55])
3.3 准备输入和输出数据 准备输出数据
# 导入标签编码器
from sklearn.preprocessing import LabelEncoder
# 定义标签编码器
le = LabelEncoder()
# 将目标字符串进行拟合和转换为数字
labels = le.fit_transform(labels)
print(le.classes_)
print(labels)
输出
array(['negative', 'neutral', 'positive'], dtype=object) array([1, 2, 1, ..., 1, 0, 1])
准备输入数据
import matplotlib.pyplot as plt
# compute no. of words in each tweet
num = [len(i.split()) for i in text]
plt.hist(num, bins = 30)
plt.title("Histogram: Length of sentences")
# 导入进度条库
from tqdm import notebook
# 创建一个空列表来保存整数序列
sent_id = []
# 遍历每个推文
for i in notebook.tqdm(range(len(text))):
encoded_sent = tokenizer.encode(text[i],
add_special_tokens=True,
max_length=25,
truncation=True,
pad_to_max_length='right')
# 将整数序列保存到列表中
sent_id.append(encoded_sent)
创建注意力掩码
attention_masks = []
for sent in sent_id:
att_mask = [int(token_id > 0) for token_id in sent]
attention_masks.append(att_mask)
# 使用 train_test_split 将数据划分为训练集和验证集
from sklearn.model_selection import train_test_split
# 使用 90% 的数据作为训练集,10% 作为验证集
train_inputs, validation_inputs, train_labels, validation_labels = train_test_split(sent_id, labels, random_state=2018, test_size=0.1, stratify=labels)
# 同样处理注意力掩码
train_masks, validation_masks, _, _ = train_test_split(attention_masks, labels, random_state=2018, test_size=0.1, stratify=labels)
from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler
# 对于在特定任务上微调 BERT,作者建议使用批量大小为 16 或 32。
# 定义批量大小
batch_size = 32
# 创建训练集的 DataLoader。
# 将张量封装成数据集
train_data = TensorDataset(train_inputs, train_masks, train_labels)
# 定义用于对数据进行采样的采样器
# 随机采样器从数据集中随机采样
# 顺序采样器按顺序采样,总是以相同的顺序
train_sampler = RandomSampler(train_data)
# 创建训练集的迭代器
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=batch_size)
# 创建验证集的 DataLoader。
# 将张量封装成数据集
validation_data = TensorDataset(validation_inputs, validation_masks, validation_labels)
# 定义顺序采样器
# 这个采样器按顺序采样数据
validation_sampler = SequentialSampler(validation_data)
# 创建验证集的迭代器
validation_dataloader = DataLoader(validation_data, sampler=validation_sampler, batch_size=batch_size)
# 创建一个迭代器对象
iterator = iter(train_dataloader)
# 加载批量数据
sent_id, mask, target = iterator.next()
print(sent_id.shape)
输出:
torch.Size([32, 25])
# 将输入传递给模型
outputs = bert(sent_id, attention_mask=mask, return_dict=False)
hidden_states = outputs[0]
CLS_hidden_state = outputs[1]
print("Shape of Hidden States:", hidden_states.shape)
print("Shape of CLS Hidden State:", CLS_hidden_state.shape)
输出:
Shape of Hidden States: torch.Size([32, 25, 768])
Shape of CLS Hidden State: torch.Size([32, 768])
- 模型微调
4.1 关闭所有参数的梯度
for param in bert.parameters():
param.requires_grad = False
4.2 定义模型架构
import torch.nn as nn
class Classifier(nn.Module):
def __init__(self, bert):
super(Classifier, self).__init__()
self.bert = bert
self.fc1 = nn.Linear(768, 512)
self.fc2 = nn.Linear(512, 3)
self.dropout = nn.Dropout(0.1)
self.relu = nn.ReLU()
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, sent_id, mask):
all_hidden_states, cls_hidden_state = self.bert(sent_id, attention_mask=mask, return_dict=False)
x = self.fc1(cls_hidden_state)
x = self.relu(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.softmax(x)
return x
# 创建模型
model = Classifier(bert)
# 如果可用,将模型推送到 GPU
model = model.to(device)
# 将张量推送到 GPU
sent_id = sent_id.to(device)
mask = mask.to(device)
target = target.to(device)
# 将输入传递给模型
outputs = model(sent_id, mask)
print(outputs)
输出:
tensor([[-1.1375, -0.9447, -1.2359],
[-0.9407, -1.0664, -1.3266],
...
[-0.9815, -1.0167, -1.3339]], device='cuda:0', grad_fn=<LogSoftmaxBackward>)
4.3 定义优化器和损失函数
# Adam 优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
import numpy as np
from sklearn.utils.class_weight import compute_class_weight
# 计算类别权重
class_weights = compute_class_weight(class_weight="balanced", classes=np.unique(labels), y=labels)
print("Class Weights:", class_weights)
输出:
Class Weights: [0.54440912 1.471568 2.06782946]
# 将类别权重列表转换为张量
weights = torch.tensor(class_weights, dtype=torch.float)
# 将权重传输到 GPU
weights = weights.to(device)
# 定义损失函数
cross_entropy = nn.NLLLoss(weight=weights)
# 计算损失
loss = cross_entropy(outputs, target)
print("Loss:", loss)
4.4. 模型训练与评估
训练:Epoch -> Batch -> 前向传播 -> 计算损失 -> 反向传播损失 -> 更新权重
因此,对于每个 epoch,我们有训练和验证阶段。在每个 batch 后,我们需要:
训练阶段
将数据加载到 GPU 上以加速 解包数据输入和标签 清除上一次传递中计算的梯度。 前向传播(将输入数据通过网络) 反向传播(反向传播) 使用 optimizer.step() 更新参数 跟踪变量以监视进度
# 为训练模型定义一个函数
def train():
print("\n训练中.....")
# 将模型设置为训练模式 - Dropout 层被激活
model.train()
# 记录当前时间
t0 = time.time()
# 将损失和准确率初始化为 0
total_loss, total_accuracy = 0, 0
# 创建一个空列表以保存模型的预测结果
total_preds = []
# 对于每个 batch
for step, batch in enumerate(train_dataloader):
# 每经过 40 个 batch 后更新进度
if step % 40 == 0 and not step == 0:
# 计算经过的时间(以分钟为单位)
elapsed = format_time(time.time() - t0)
# 报告进度
print(' Batch {:>5,} of {:>5,}. Elapsed: {:}.'.format(step, len(train_dataloader), elapsed))
# 将 batch 推送到 GPU 上
batch = tuple(t.to(device) for t in batch)
# 解包 batch 为单独的变量
# `batch` 包含三个 PyTorch 张量:
# [0]: 输入 id
# [1]: 注意力掩码
# [2]: 标签
sent_id, mask, labels = batch
# 在执行反向传播之前,始终清除之前计算的梯度。
# PyTorch 不会自动执行此操作。
model.zero_grad()
# 执行前向传播。这将返回模型的预测结果
preds = model(sent_id, mask)
# 计算实际值和预测值之间的损失
loss = cross_entropy(preds, labels)
# 累积所有 batch 的训练损失,以便在结束时计算平均损失。
# `loss` 是一个包含单个值的张量;`.item()` 函数只返回张量中的 Python 值。
total_loss = total_loss + loss.item()
# 执行反向传播以计算梯度。
loss.backward()
# 使用计算出的梯度更新参数。
# 优化器决定了“更新规则”——参数如何根据梯度、学习率等进行修改。
optimizer.step()
# 模型的预测结果存储在 GPU 上。因此,将其推送到 CPU 上
preds = preds.detach().cpu().numpy()
# 累积每个 batch 的模型预测结果
total_preds.append(preds)
# 计算一个 epoch 的训练损失
avg_loss = total_loss / len(train_dataloader)
# 预测结果的形式为 (batch 数量, batch 大小, 类别数量)。
# 因此,将预测结果重新整形为 (样本数量, 类别数量)
total_preds = np.concatenate(total_preds, axis=0)
# 返回损失和预测结果
return avg_loss, total_preds
评估:Epoch -> Batch -> 前向传播 -> 计算损失
评估阶段
- 将数据加载到 GPU 上以加速
- 解包数据输入和标签
- 前向传播(将输入数据通过网络)
- 计算验证数据上的损失
- 跟踪变量以监视进度
# 为评估模型定义一个函数
def evaluate():
print("\n评估中.....")
# 将模型设置为训练模式 - Dropout 层被停用
model.eval()
# 记录当前时间
t0 = time.time()
# 将损失和准确率初始化为 0
total_loss, total_accuracy = 0, 0
# 创建一个空列表以保存模型的预测结果
total_preds = []
# 对于每个 batch
for step, batch in enumerate(validation_dataloader):
# 每经过 40 个 batch 后更新进度
if step % 40 == 0 and not step == 0:
# 计算经过的时间(以分钟为单位)
elapsed = format_time(time.time() - t0)
# 报告进度
print(' Batch {:>5,} of {:>5,}. Elapsed: {:}.'.format(step, len(validation_dataloader), elapsed))
# 将 batch 推送到 GPU 上
batch = tuple(t.to(device) for t in batch)
# 解包 batch 为单独的变量
# `batch` 包含三个 PyTorch 张量:
# [0]: 输入 id
# [1]: 注意力掩码
# [2]: 标签
sent_id, mask, labels = batch
# 在执行前向传播时,停用自动求导
with torch.no_grad():
# 执行前向传播。这将返回模型的预测结果
preds = model(sent_id, mask)
# 计算实际值和预测值之间的验证损失
loss = cross_entropy(preds, labels)
# 累积所有 batch 的验证损失,以便在结束时计算平均损失。
# `loss` 是一个包含单个值的张量;`.item()` 函数只返回张量中的 Python 值
total_loss = total_loss + loss.item()
# 将模型的预测结果从 GPU 推送到 CPU
preds = preds.detach().cpu().numpy()
# 累积每个 batch 的模型预测结果
total_preds.append(preds)
# 计算一个 epoch 的验证损失
avg_loss = total_loss / len(validation_dataloader)
# 预测结果的形式为 (batch 数量, batch 大小, 类别数量)。
# 因此,将预测结果重新整形为 (样本数量, 类别数量)
total_preds = np.concatenate(total_preds, axis=0)
return avg_loss, total_preds
4.5 训练模型
# 将初始损失设为无穷大
best_valid_loss = float('inf')
# 创建一个空列表来存储每个 epoch 的训练和验证损失
train_losses = []
valid_losses = []
epochs = 5
# 对于每个 epoch
for epoch in range(epochs):
print('\n....... 第 {:} / {:} 个周期 .......'.format(epoch + 1, epochs))
# 训练模型
train_loss, _ = train()
# 评估模型
valid_loss, _ = evaluate()
# 保存最佳模型
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'saved_weights.pt')
# 累积训练和验证损失
train_losses.append(train_loss)
valid_losses.append(valid_loss)
print(f'\n训练损失: {train_loss:.3f}')
print(f'验证损失: {valid_loss:.3f}')
print("")
print("训练完成!")
# 输出
# ...... 第 1 / 5 个周期 .......
# 训练.....
# 第 40 批 共 391 批. 耗时: 0:00:02.
# 第 80 批 共 391 批. 耗时: 0:00:05.
# 第 120 批 共 391 批. 耗时: 0:00:07.
# 第 160 批 共 391 批. 耗时: 0:00:09.
# 第 200 批 共 391 批. 耗时: 0:00:12.
# 第 240 批 共 391 批. 耗时: 0:00:14.
# 第 280 批 共 391 批. 耗时: 0:00:17.
# 第 320 批 共 391 批. 耗时: 0:00:19.
# 第 360 批 共 391 批. 耗时: 0:00:21.
#
# 评估.....
# 第 40 批 共 44 批. 耗时: 0:00:02.
#
# 训练损失: 1.098
# 验证损失: 1.088
#
# ...... 第 2 / 5 个周期 .......
# 训练.....
# 第 40 批 共 391 批. 耗时: 0:00:02.
# 第 80 批 共 391 批. 耗时: 0:00:04.
# 第 120 批 共 391 批. 耗时: 0:00:07.
# 第 160 批 共 391 批. 耗时: 0:00:09.
# 第 200 批 共 391 批. 耗时: 0:00:11.
# 第 240 批 共 391 批. 耗时: 0:00:13.
# 第 280 批 共 391 批. 耗时: 0:00:16.
# 第 320 批 共 391 批. 耗时: 0:00:18.
# 第 360 批 共 391 批. 耗时: 0:00:20.
#
# 评估.....
# 第 40 批 共 44 批. 耗时: 0:00:02.
#
# 训练损失: 1.074
# 验证损失: 1.040
4.6 模型评估
# 加载最佳模型的权重
路径='saved_weights.pt'
model.load_state_dict(torch.load(路径))
# 在验证数据上获取模型预测
# 返回2个元素-验证损失和预测
验证损失, 预测结果 = evaluate()
print(验证损失)
# 输出
评估.....
第 40 批 共 44 批. 耗时: 0:00:02.
1.0100846696983685
# 导入分类报告函数
from sklearn.metrics import classification_report
# 将对数概率转换为类别
# 选择最大值的索引作为类别
预测类别 = np.argmax(预测结果, axis=1)
# 实际标签
实际类别 = validation_labels
print(classification_report(实际类别, 预测类别))
结论
BERT在自然语言处理(NLP)领域是一个重要的里程碑,特别是随着谷歌AI语言的出现。它的影响横跨了各种应用,从训练语言模型到命名实体识别。利用transformer中的编码器表示,BERT改变了预训练模型,提高了它们在理解和处理文本数据方面的能力。
机器学习技术,特别是涉及自然语言推理的技术,在BERT和类似模型的整合下取得了显着进步。这些预训练的BERT模型已经成为处理大量训练数据的重要工具,推动了NLP领域所能实现的极限。语言推理方面的最新技术现在严重依赖于编码器机制,这是BERT的核心组成部分。