文章目录
- 公开可用的模型检查点或 API
- LLaMA 变体系列
- 大语言模型的公共 API
公开可用的模型检查点或 API
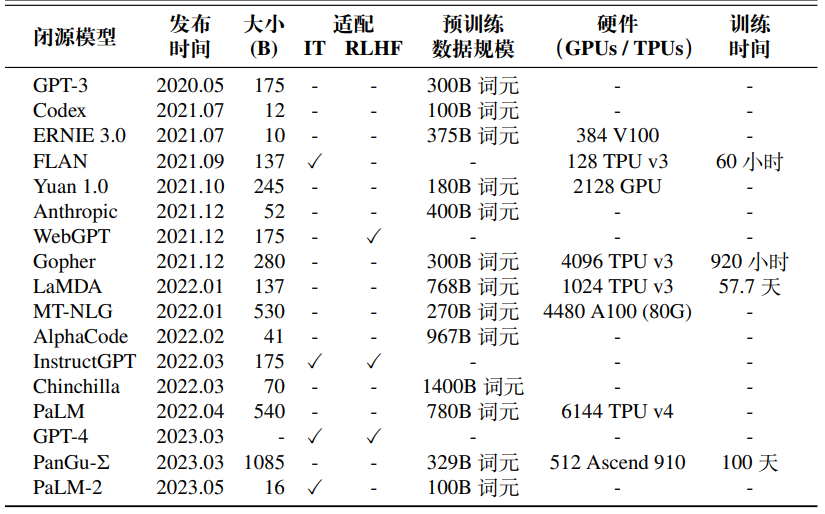
众所周知,大模型预训练是一项对计算资源要求极高的任务。因此,经过预训练的公开模型检查点(Model Checkpoint)对于推动大语言模型技术的渐进式发展起到了至关重要的作用。得益于学术界和工业界的共同努力,目前开源社区已经积累了大量的模型检查点资源,用户可以根据自身研究或开发需求,灵活选择并下载使用这些检查点。此外,对于那些仅需利用模型进行解码生成的用户而言,商业公司提供的闭源模型的 API 接口也是一种便捷的选择。这些接口为用户提供了与模型进行交互的渠道,而无需关心模型内部的复杂结构和训练过程,即可快速获得生成结果,从而满足各种真实场景的应用需求。
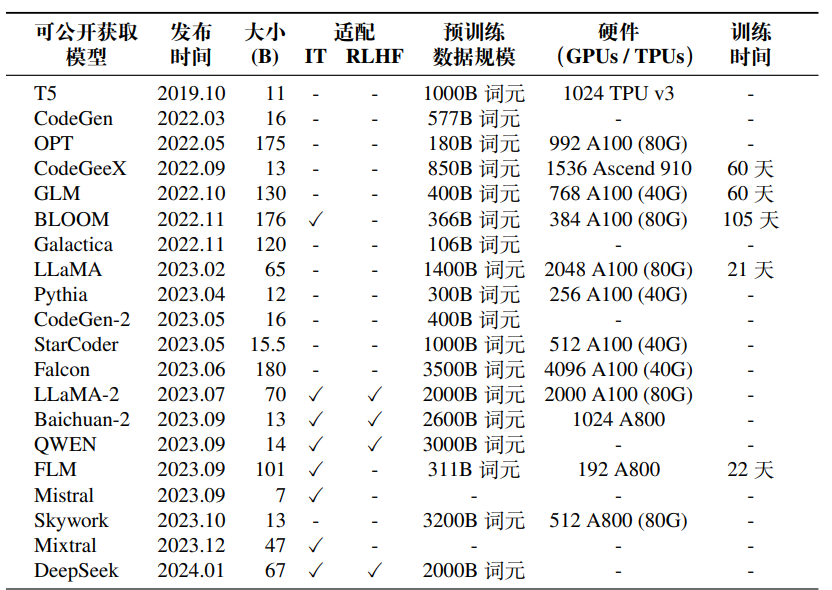
LLaMA 和 LLaMA-2,LLaMA是 Meta AI 在 2023 年 2 月发布的一系列大语言模型,有 7B、13B、30B 和 65B 四种参数规模版本,是当时性能非常优异的开源模型之一,直到目前也仍然被广泛使用与对比。其中,13B 参数的版本在部分自然语言处理基准测试中超越了具有 175B 参数的 GPT-3 模型。LLaMA 各个参数量版本都在超过 1T 词元的预训练语料上进行了训练,其中 65B 参数的模型版本在 2,048 张 80G 显存的 A100 GPU 上训练了近 21 天。由于对公众开放了模型权重且性能优秀,LLaMA 已经成为了最受欢迎的开源大语言模型之一,许多研究工作都是以其为基座模型进行微调或继续预训练,衍生出了众多变体模型,极大地推动了大语言模型领域的研究进展。2023 年 7 月,Meta AI 公开发布了 LLaMA-2,对第一代模型进行了综合升级。LLaMA-2 有 7B、13B、34B(未开源)和 70B 四种参数规模版本,并且可用于商用。相比于第一版 LLaMA,LLaMA-2 扩充了预训练的词元量(达到了 2T),同时将模型的上下文长度翻了一倍(达到 4,096 个词元),并引入了分组查询注意力机制等技术来提升模型性能。此外,Meta AI 使用 LLaMA-2 作为基座模型,通过进一步的有监督微调、基于人类反馈的强化学习等技术对模型进行迭代优化,完整经历了“预训练-有监督微调-基于人类反馈的强化学习”这一训练流程,并发布了面向对话应用的微调系列模型 LLaMA-2 Chat(同样具有四种参数规模的版本)。LLaMA-2 Chat不仅在许多任务上具有更好的模型性能(例如代码生成、世界知识、阅读理解和数学推理),同时在应用中也更加安全。
ChatGLM,ChatGLM是智谱 AI 和清华大学联合开发的中英双语对话式模型,最早发布于 2023 年 5 月,并一直进行迭代优化,目前已经更新到了ChatGLM-3。ChatGLM 系列模型参数量都是 6B,具备流畅对话的能力且部署门槛低,在语义、数学、推理、代码、知识等不同角度的评测中都取得了优异表现。除此之外,该系列还开源了基础模型 ChatGLM3-6B-Base 、长文本对话式模型 ChatGLM3-6B-32K 和进一步强化了对于长文本理解能力的 ChatGLM3-6B-128K。除了 ChatGLM 系列,智谱 AI 还致力于开发更强更大规模的 GLM
Falcon,Falcon是阿布扎比的技术创新研究院(TII)发布的一系列语言 模型,包括 7B、40B 和 180B 三个参数版本,两个较小的版本发布于 2023 年 5 月,180B 参数的版本发布于 2023 年 9 月。其中,180B 参数的版本是当时参数量最大的开源预训练语言模型。Falcon 的训练数据 80% 以上来自 RefinedWeb 数据集,该数据集是一个基于 Common Crawl 的经过严格清洗的网页数据集。根据 Falcon 的技术报告,其 7B 版本的模型在 384 张 A100 上使用了 1.5T 词元进行训练,40B 版本的模型在 384 张 A100 上使用了 1T 词元进行训练,而 180B 版本的模型在 4,096张 A100 上使用了 3.5T 词元进行训练。同样地,TII 也开放了经过指令微调的模型Falcon Instruct 供用户使用。
Baichuan 和 Baichuan-2,Baichuan是百川智能公司于 2023 年 6 月发布的开源可商用大语言模型,参数规模为 7B,支持中英双语,预训练数据规模达到了1.2T 词元。当时在其比较的中文和英文的多个基准测试中都取得了同尺寸模型较优效果。2023 年 9 月,百川智能发布了新一代开源多语言模型 Baichuan-2,目前有 7B 和 13B 两种参数规模,预训练数据规模达到了 2.6T 词元。除了基座模型,百川智能也提供了经过有监督微调和人类偏好对齐的对话式模型。根据 Baichuan2 的技术报告,Baichuan-2 性能进一步提升,在其评估基准测试上的表现全面超过Baichuan。此外,Baichuan-2 还具备优秀的多语言能力和垂域应用潜力(如法律、医疗等领域)。
InternLM 和 InternLM-2,InternLM是上海人工智能实验室开发的多语言开源大模型,于 2023 年 7 月公开发布,目前已开源 7B 和 20B 两种参数规模。据InternLM 的技术报告,20B 参数的 InternLM 在其评估的基准测试上达到了第一代LLaMA (70B) 的水平,并且支持数十类插件,有较强的工具调用能力。除了开源模型本体外,InternLM 还提供了配套的开源工具体系,包括预训练框架 InternLMTrain、低成本微调框架 XTuner、部署推理框架 LMDeploy、评测框架OpenCompass以及面向场景应用的智能体框架 Lagent,为用户使用提供了完备的使用链。2024年 1 月,InternLM-2正式发布,相比于 InternLM,各个方面的能力都有了提升,包括推理、代码、数学、对话、指令遵循等众多能力。InternLM-2 目前提供了1.8B、7B 和 20B 三种参数规模的版本可供使用。此外,InternLM 系列也发布了多模态模型 InternLM-XComposer 和数学模型 InternLM-Math。
Qwen,Qwen 是阿里巴巴公司开源的多语大模型系列,首次公开发布于 2023 年 8 月,且仍在继续更新。现有从 0.5B 到 72B 的不同参数规模版本,其中,14B 的 Qwen 的预训练数据规模达到了 3T 词元。根据 Qwen 的技术报告,2024年 2 月最新发布的 Qwen-1.5 (72B) 在其评估的测试基准上优于 LLaMA-2 (70B) 的表现,在语言理解、推理、数学等方面均展现出了优秀的模型能力。除此之外,Qwen 系列专门为代码、数学和多模态设计了专业化模型 Code-Qwen、Math-Qwen和 Qwen-VL,以及对应的对话式模型,可以供用户进行选择使用。
Mistral,Mistral 是 Mistral AI 在 2023 年 9 月公开发布的具有 7B 参数的 大语言模型,受到了广泛关注。根据 Mistral 博客提供的结果,Mistral (7B) 在其评估的基准测试中都优于 LLaMA-2 (13B) 和 LLaMA (34B),并且在代码生成方面的表现接近于专门为代码任务微调的Code LLaMA (7B)。在解码效率上,Mistral 采用了分组查询注意力技术;在上下文长度上,Mistral 采用了滑动窗口注意力技术,增强了对于长文本的处理能力。通过引入分组查询注意力和滑动窗口注意力技术,Mistral 在 16K 序列长度和 4K 注意力窗口大小下速度提升了 2 倍。除此之外,Mistral AI 还发布了 Mistral 的有监督微调版本——Mistral Instruct,在 MT-bench(评估大语言模型在多轮对话和指令遵循能力的基准测试)上优于很多 7B 参数的对话模型。
DeepSeek LLM,DeepSeek LLM 是幻方公司于 2023 年 11 月公开发布的大语言模型,主要支持中英双语,目前有 7B 和 67B 两种参数规模,预训练阶段使用的数据量都达到了 2T 规模的词元。根据 DeepSeek LLM 的技术报告,67B 参数量的 DeepSeek LLM 在多个评估的基准测试中超过了 LLaMA-2 (70B) 模型,特别是在代码、数学和推理任务上。DeepSeek LLM 同时提供 7B 和 67B 两种参数规模的对话模型,并针对人类价值观进行了对齐。除了通用基座模型,DeepSeek 系列也发布了相应的数学模型 DeepSeek-Math、代码模型 DeepSeek-Coder 和多模态模型 DeepSeek-VL。
Mixtral,Mixtral 全称为 Mixtral 8×7B,是 Mistral AI 在 2023 年 12 月公开发布的稀疏混合专家模型架构的大语言模型,这也是较早对外公开的 MoE 架构的语言模型。在结构上,Mixtral 包含 8 组不同的“专家”参数,对于每个词元,Mixtral 的每一层都会通过路由网络选择两组“专家”来对其进行处理,并将它们的输出相加结合起来。虽然 Mixtral 一共有 46.7B 参数,但是每个词元在处理过程中只会用到 12.9B 参数,因此其处理速度和资源消耗与 12.9B 参数的模型相当。在性能上,Mistral AI 博客提供的结果显示,Mixtral 在多个基准测试中都超过了LLaMA-2 (70B) 和 GPT-3.5,并且解码速度比 LLaMA-2 (70B) 快了 6 倍,能够支持32K 长度的上下文。此外,Mixtral 还支持多种语言,包括英语、法语、意大利语、德语和西班牙语等。Mistral AI 同样也发布了 Mixtral 8×7B 有监督微调版本——Mixtral 8×7B Instruct,在 MT-bench上取得了与 GPT-3.5 相当的性能表现。
Gemma,Gemma是谷歌于 2024 年 2 月发布的轻量级开源大模型,有 2B和 7B 两种参数规模。Gemma 的技术路线与谷歌另一款闭源多模态模型 Gemini 类似,但 Gemma 为纯语言模型,且专注于英语任务。Gemma (2B) 预训练数据规模达到了 2T 词元,而 Gemma (7B) 的预训练数据规模达到了 6T 词元,两者的预训练语料都主要是英语数据。根据 Gemma 的技术报告显示,Gemma 在其评估的多个自然语言基准测试中都取得了较好水平。同样地,Gemma 也提供了有监督微调版本 Gemma IT,并与人类偏好进行了对齐。
MiniCPM,MiniCPM 是面壁智能与清华大学共同研发的开源语言模型,仅有 2B 的参数规模,于 2024 年 2 月发布。MiniCPM 在训练前进行了模型沙盒实验,通过预先使用小模型广泛实验寻找更优的训练设置,并最终迁移至大模型上。在训练方法上,MiniCPM 首先采用了稳定训练与退火的两阶段学习方法,然后进行了有监督微调和人类偏好对齐。根据 MiniCPM 的技术报告,在其评测的多个领域基准测试中取得了非常优异的效果。同系列模型还包括 MiniCPM-2B-SFT(指令微调版本)、MiniCPM-2B-DPO(DPO 对齐版本)、MiniCPM-V(多模态模型)等。
YuLan-Chat,YuLan-Chat是中国人民大学研发的中英双语系列对话模型,最早发布于 2023 年 6 月,目前已经更迭至最新版本 YuLan-Chat-3。其中,YuLanChat-1 在LLaMA 的基础上进行微调,使用了精心优化的高质量中英文混合指令,发布了 13B 和 65B 两个参数规模版本。YuLan-Chat-2 在 LLaMA-2 的基础上使用中英双语进行继续预训练,同样具有 13B 和 65B 两个参数版本,目前可支持 8K的上下文长度。YuLan-Chat-3 从头开始进行了完整的预训练,其参数规模为 12B,预训练词元数达到 1.68 T。YuLan-Chat-3 采用了两阶段的课程学习指令微调方法,并且进行了人类对齐。
LLaMA 变体系列
自 2023 年 2 月发布以来,LLaMA 系列模型在学术界和工业界引起了广泛的关注,对于推动大语言模型技术的开源发展做出了重要贡献。LLaMA 拥有较优的模型性能,并方便用户公开获取,因此一经推出就迅速成为了最受欢迎的开放性语言模型之一。众多研究人员纷纷通过指令微调或继续预训练等方法来进一步扩展 LLaMA 模型的功能和应用范围。其中,指令微调由于相对较低的计算成本,已成为开发定制化或专业化模型的首选方法,也因此出现了庞大的 LLaMA 家族。
基础指令,在 LLaMA 的扩展模型中,Stanford Alpaca是第一个基于 LLaMA (7B) 进行微调的开放式指令遵循模型。通过使用 Self-Instruct 方法借助大语言模型进行自动化的指令生成,Stanford Alpaca 生成了 52K 条指令遵循样例数据(Alpaca-52K)用于训练,其指令数据和训练代码在随后的工作中被广泛采用。Vicuna 作为另一个流行的 LLaMA 变种,也受到了广泛关注。它并没有使用合成指令数据,主要是使用 ShareGPT 收集的用户日常对话数据进行训练,展现了基于 LLaMA 的语言模型在对话生成任务中的优秀实力。
中文指令,原始的 LLaMA 模型的训练语料主要以英语为主,在中文任务上的表现比较一般。为了使 LLaMA 模型能够有效地支持中文,研究人员通常会选择扩展原始词汇表,在中文数据上进行继续预训练,并用中文指令数据对其进行微调。经过中文数据的训练,这些扩展模型不仅能更好地处理中文任务,在跨语言处理任务中也展现出了强大的潜力。目前常见的中文大语言模型有 Chinese LLaMA、Panda、Open-Chinese-LLaMA、Chinese Alpaca、YuLan-Chat 等。
垂域指令,LLaMA 虽然展现出了强大的通用基座模型能力,但是在特定的垂直领域(例如医学、教育、法律、数学等)的表现仍然较为局限。为了增强 LLaMA模型的垂域能力,很多工作基于搜集到的垂域相关的指令数据,或者采用垂域知识库以及相关专业文献等借助强大的闭源模型 API(例如 GPT-3.5、GPT-4 等)构建多轮对话数据,并使用这些指令数据对 LLaMA 进行指令微调。常见的垂域 LLaMA模型有 BenTsao(医学)、LAWGPT(法律)、TaoLi(教育)、Goat(数学)、Comucopia(金融)等。
多模态指令,由于 LLaMA 模型作为纯语言模型的强大能力,许多的多模态模型都将其(或将其衍生模型)作为基础语言模型,搭配视觉模态的编码器,使用多模态指令对齐视觉表征与文本。与其他语言模型相比,Vicuna 在多模态语言模型中受到了更多的关注,由此形成了一系列基于 Vicuna 的多模态模型,包括LLaVA 、MiniGPT4 、InstructBLIP 和 PandaGPT 。
除了使用不同种类的指令数据进行全参数微调外,研发人员还经常使用轻量化微调的技术训练 LLaMA 模型变体,以降低训练成本,方便用户部署。例如,AlpacaLoRA 使用 LoRA 复现了 Stanford Alpaca。LLaMA 模型系列的发布有力地推动了大语言模型技术的发展。为了更直观地展示 LLaMA 系列模型的研究进展以及衍生模型之间的关系,下图展示了一个 LLaMA 系列模型的简要演化图,呈现了 LLaMA 模型系列从发布到快速发展以及在各个领域中的广泛应用。

大语言模型的公共 API
语言模型 API,目前最常用的 GPT 系列模型 API 包括 GPT-3.5 Turbo、GPT-4和 GPT-4 Turbo。其中,GPT-3.5 Turbo 对应的 API 接口为 gpt-3.5-turbo,支持16K 词元的上下文长度。目前,开发者可以使用自己的数据来微调 GPT-3.5 Turbo,以便更好地适用于个性化的应用场景,例如提高模型的指令遵循能力、定制化输出格式以及定制化语气等;GPT-4 是一个多模态模型,也是目前 GPT 系列效果最好的模型,其对应的 API 接口有 gpt-4(基础版本,没有视觉功能)、gpt-4-32k(将上下文长度扩展到 32K)、gpt-4-vision-preview(带有视觉功能的 GPT-4 多模态版本)。相较于 GPT-4,GPT-4 Turbo 有更快的生成速度、更长的上下文窗口(最多 128K)以及更低的价格,其最新对应的 API 为 gpt-4-turbo-preview。对于许多基本任务来说,GPT-4 和 GPT-3.5 模型之间的差异并不显著。然而,在较为复杂的推理任务中,GPT-4 能够展现出更为强大的模型能力。值得注意的是,OpenAI一直在维护和升级这些模型接口,因此 API 名称实际上将指向最新版本。
文本表征 API. 除了语言模型 API 外,OpenAI 还提供用于文本表征的 API,可用于聚类、稠密信息检索等多种下游任务,可以为知识检索以及检索增强生成提供支持。目前 OpenAI 主要提供三种文本表征的 API 接口,包括 text-embedding-ada-002、text-embedding-3-small 以及 text-embedding-3-large。其中,text-embedding-ada-002 发布于 2022 年,至今模型并未更新,可以提供1,536 维的向量表征,在英文文本表征基准测试 MTEB 获得了 61% 的平均得分;text-embedding-3-small 是一个更高效的文本表征模型,同样提供 1,536 维的向量表征。相对于 text-embedding-ada-002,text-embedding-3-small 有较大的性能提升,在 MTEB 的平均得分达到62.3%;而 text-embedding-3-large 能够支持高达 3,072 维的向量表征,是三者中目前性能最好的模型,在 MTEB 的平均得分达到了 64.6%。这三个 API 支持的输入长度都是 8,191 个词元,开发者可根据自身需求选择合适的 API。