深度强化学习(Deep Reinforcement Learning,DRL)可以用于解决优化问题,尤其是具有复杂、高维度的状态空间和动作空间的问题。它结合了深度学习的强大表示能力和强化学习的学习框架,深度神经网络可以学习复杂的特征和模式,而强化学习可以在与环境的交互中进行学习和优化,因此能够有效地解决复杂的优化问题。其基本思路是将优化问题建模为强化学习问题,然后利用深度神经网络来学习策略或值函数,以最大化累积奖励或最小化成本函数。通过与环境的交互,智能体学习如何在不同状态下采取行动以达到最优解。在这个过程中,深度神经网络可以作为函数近似器来表示策略函数或值函数,帮助智能体学习复杂的优化策略。智能体通过与环境的交互来不断地更新网络参数,以逐步提高策略的性能,并最终找到最优解或近似最优解。
在传统的TSP(Traveling Salesman Problem)中,问题的结构通常是保持不变的,即客户的位置和客户之间的旅行时间是固定的。但在现实应用中,客户的订单状况和道路交通情况是在不断变化的:客户可能会添加或取消订单;交通情况的变化会影响路线的预期总时间,有时还会因被迫绕行而影响距离。由此我们引出DTSP,即在这种动态环境中调整路线计划,使得总行驶路径长度最短。
本文将具体介绍深度强化学习求解动态旅行商问题(Dynamic Traveling Salesman Problems,DTSP)的方法,即重点介绍深度强化学习解决单目标优化问题的研究。
1.问题描述
本文考虑DTSP的序贯决策问题(a sequential decision-making problem of DTSP),其中销售员可以在当前顾客访问完成后决定下一个顾客的访问。同时考虑了客户和流量的变化,具体体现在边权和节点的变化:
-
边权的变化:两个点之间所需要的通行时间受到当前的交通状况的影响,并随着时间的变化而变化。在本文中,假设任意两个点
在时刻
实际所需的通行时间为
。由于各种原因(如交通事故等),我们不能提前准确预测时间,所以假设
。其中
为事先预测的通行时间,而
是一个随机变量,表示突发情况延迟的时间。
-
节点的变化:顾客的需求是动态变化的。在旅行商的行程中,会收到新顾客的需求,旧的顾客也有可能会取消订单。在本文中,我们假设顾客所有潜在出现的位置集合为 V ,当前所有顾客所在位置集合为 C 。在旅行商服务完一名顾客后,有一定概率从集合 V \ C 中取一个新的点加入 C,也有一定概率删除一位从 C 中选出的未服务的顾客。我们引入随机操作
,表示旅行商在完成第k个顾客的订单后,随机选取insert,delete和do nothing三种操作来表示顾客需求的动态变化。
DTSP是在线优化问题(online optimization problem),是时间依赖的旅行商问题(time-dependent traveling salesman problem,TDTSP)的在线优化版本。而TDTSP是一个单阶段决策问题,考虑由于受交通事故、天气变化、上下班高峰期的影响而使得任意两节点间的旅行时间依赖于一天中所处的具体时段或依赖于该节点在哈密顿圈中所处的具体位置(顺序),我们用函数 来表示旅行时间,其值受抵达节点
的时间
影响。
以下为TDTSP问题的模型。
其中 为二元决策变量,若销售员从节点
到节点
,则
等于1,否则为0。为销售员访问节点
的时间。C为待访问客户池,0为仓库的编号。
此外还研究了DTSP的一个变体——动态取送货问题(Dynamic Pickup and Delivery Problem,DPDP),在此问题中,一个订单包括两位顾客,送货顾客与取货顾客,而每个订单的数量 不一定相同,旅行商同时最多携带不超过数量为Q的货物。该问题的其余设置与旅行商问题相同,具体细节在此不再赘述。
2.算法流程
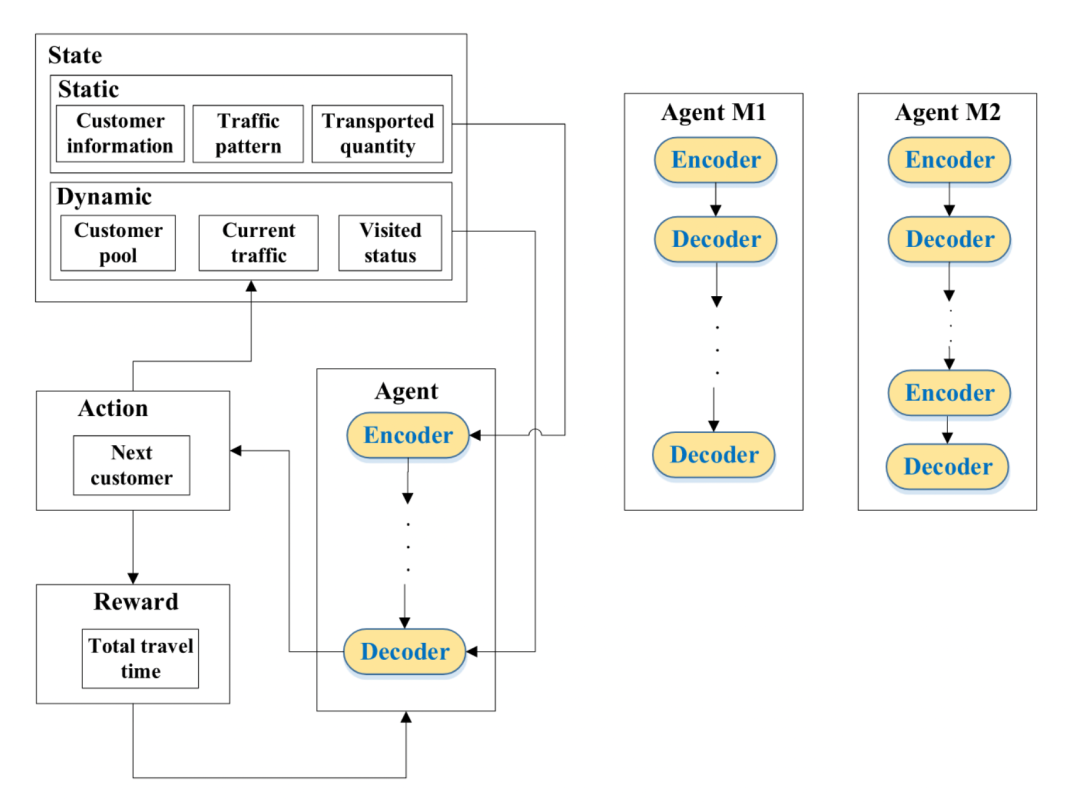
为了实时求解DTSP,提出了一种基于注意力模型的DRL方法。该方法将DTSPs视为一个马尔科夫决策过程,由状态(state),行动(action),奖励(reward),智能体(agent)四个部分组成:
-
状态分为静态信息和动态信息。静态信息包括所有顾客信息,交通状况模式,订单运输量;动态信息包括当前的所有顾客,当前的交通以及顾客的访问状态。
-
行动定义为下一个访问的顾客。
-
奖励设置为总旅行时间的相反数。
-
设计了两个基于深度神经网络模型的智能体:Model 1(M1)和Model 2(M2)。两者都由编码器和解码器组成。其中M1包含1次编码过程和多次解码过程,较适合处理仅边权(交通情况)变化情况,而M2包含多次编码与解码过程,更适合处理节点(顾客)变化情况。
DRL框架
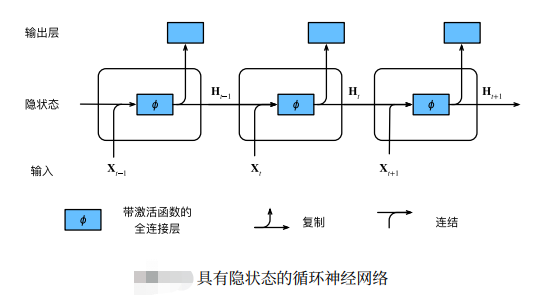
在深度强化学习中,智能体的编码器和解码器通常与序列数据处理相关。以下是它们的含义及作用:
1.编码器(Encoder):
含义:编码器是将输入序列转换为隐藏表示的组件。它接收来自环境的输入数据(如状态或观察)并将其转换为一个固定维度的向量,其中包含了输入序列的信息。
作用:编码器的主要作用是捕获输入序列中的特征和模式,并将其编码成一个表示,以便后续的处理和学习。它通常使用神经网络(如循环神经网络或卷积神经网络)来实现。
2.解码器(Decoder):
含义:解码器是将隐藏表示转换回原始数据形式的组件。它接收编码器生成的隐藏表示,并将其解码成与任务相关的输出。
作用:解码器的作用是将隐藏的表示转换成对智能体有意义的输出,例如选择动作。其设计取决于具体的任务和应用场景。
下面将对M1和M2进行介绍。
2.1 Model 1
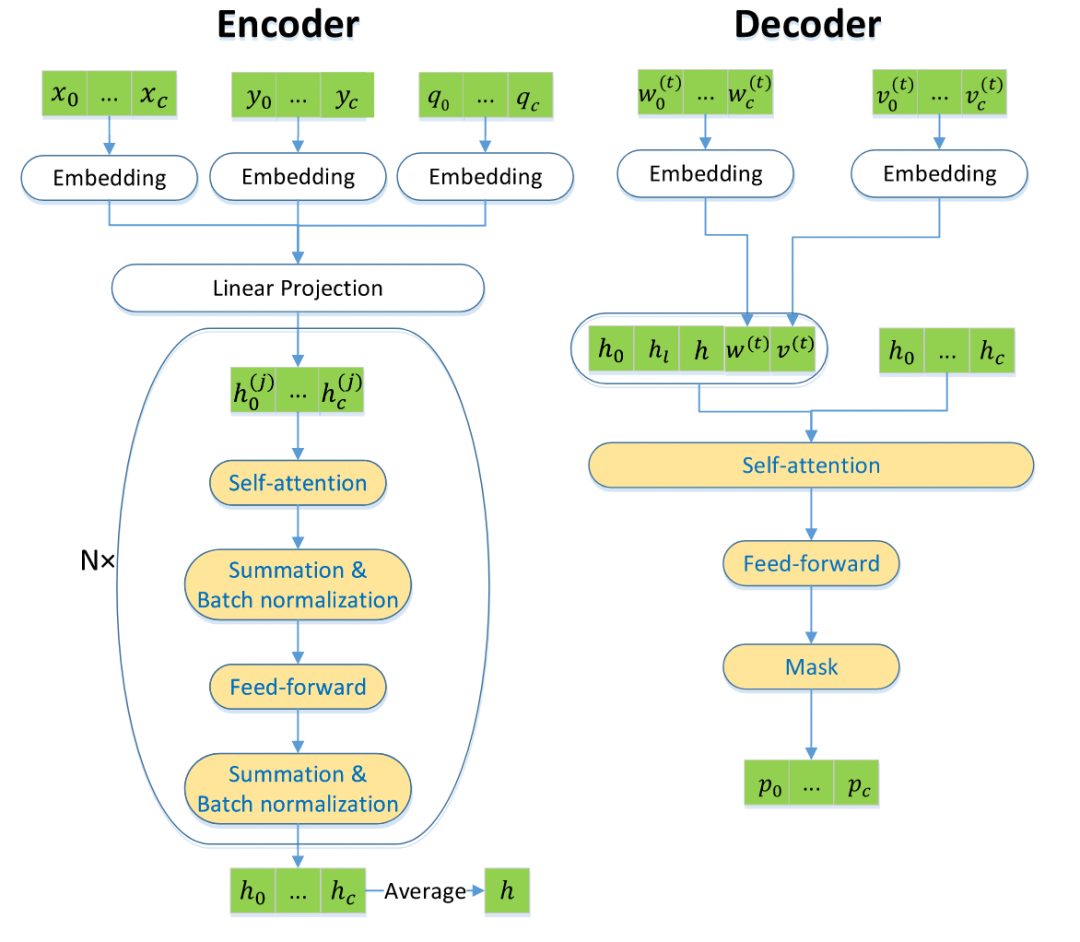
M1主要对动态交通流量进行感知,具有一个编码器和c个解码器。
M1流程图
编码器
编码器以初始c个客户的静态信息为输入,然后生成一个表示图上下文的嵌入(context embedding),即将静态信息通过线性模型以及多头自注意力模型进行编码,该编码在整个求解过程中只进行一次。具体步骤为 :
-
首先通过全连接NN将每个客户节点i的身份转换为ID嵌入
,并将估计的交通状态转换为交通嵌入
。对于DPDP而言,运输量qi也会被嵌入。
-
之后,结合
,
,
。
-
最后,编码器通过N个注意力层计算聚合嵌入hi,每个注意力层包含一个多头注意力( MHA )子层和一个带有一个隐藏层和ReLu激活的节点级全连接前馈子层(a node-wise fully connected feed-forward sublayer)。
解码器
解码器将当前的交通状况、客户的访问状态等动态信息和编码器计算的嵌入作为输入,并输出所有客户被选为下一个访问客户的概率。具体内容见流程图。
2.2 Model 2
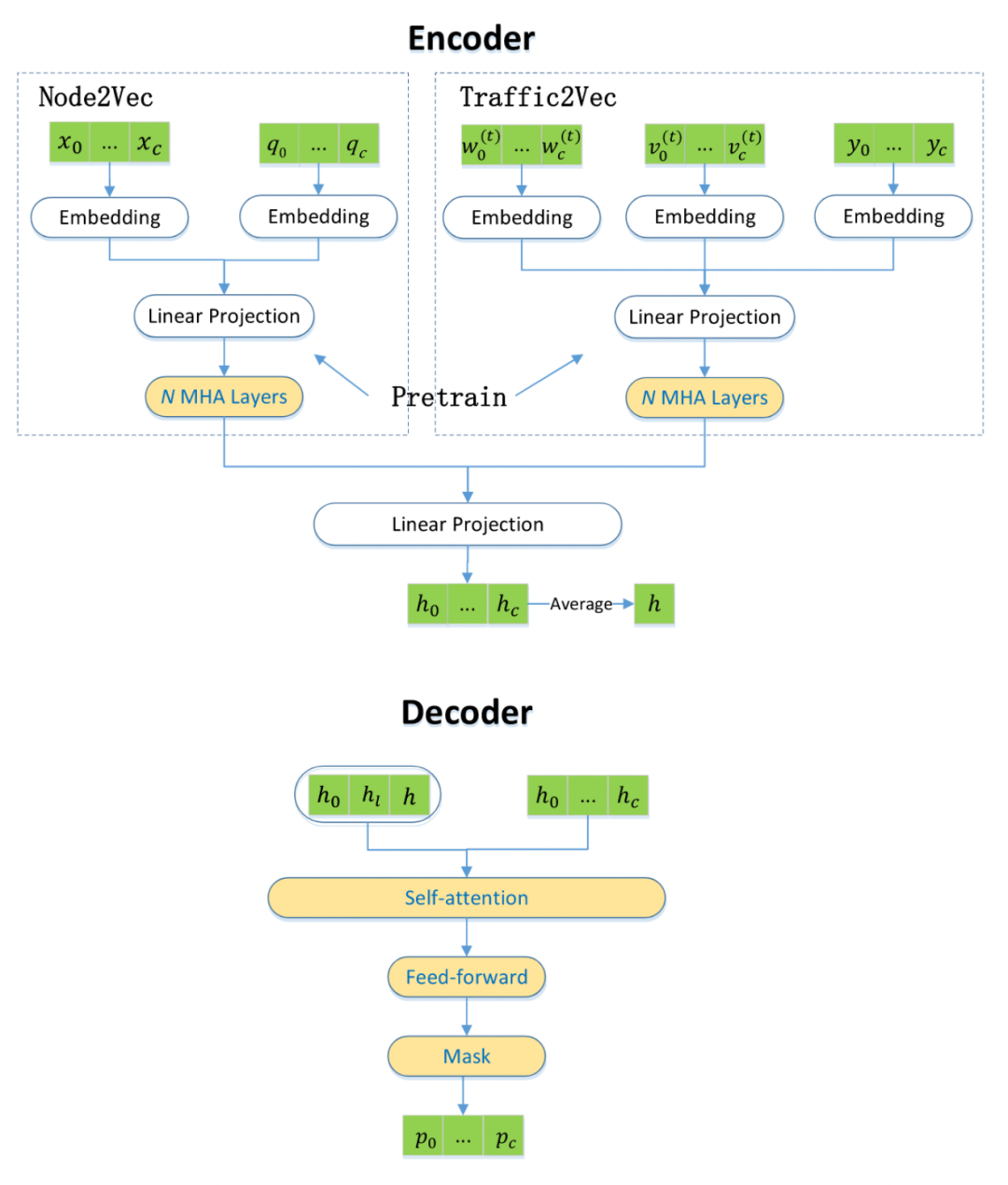
M1的缺点在于其解码器中使用的上下文嵌入h。由于h是从它的编码器中获得的,所以它无法预见解码器部分的动态请求处理。因此提出M2,对每次访问后的状态进行重新编码,以捕捉客户请求的变化。
M2流程图
M2具有个编码器和
个解码器,其中
是动态客户池中的最大客户数量。模型中编码器包含了两个预训练的模型Node2Vec和Traffic2Vec。Node2Vec用于编码顾客信息,以及订单需求量信息。Traffic2Vec用于编码当前交通信息以及顾客访问状况。编码器用这两个编码对线性模型进一步编码得到h,而解码器根据此编码解码用自注意力机制解码到每位顾客作为下一位访问顾客的概率。在访问下一位顾客并更新动态环境后,进行下一轮的编码和解码。
2.3 模型训练
本文采用带基线的策略梯度算法(Proposed Policy Gradient With Rollout Baseline Algorithm)训练模型。此算法迭代地优化模型参数。在每一轮的训练中,利用之前得到的最优模型作为基线,采用Adam优化器优化模型的参数。之后对比当前模型及最优模型
。若
显著优于
,则更新
。否则,若在一定轮次内未更新
,则将
设置为
。

伪代码
3.实验结果
采用由京东物流提供的数据集来进行检验,随机选取99位顾客以及一个仓库来组成点集 V 。而顾客集合 C 初始在 V 中随机选择。共设计六种对比算法:
-
离线模拟退火算法 (Offline simulated annealing,SA):迭代地采用五种常见算子(2-opt, 3-opt, or-opt,交换,重分配)进行优化。
-
贪心算法 (Greedy,GR):每次选取离上一位顾客最近的点进行访问。
-
在线TSP求解器 (Online TSP Solver,Solver):每次选取的点为当前剩余点在当前时刻下组成的静态旅行商问题最优解中的下一个点,然后采用TSP求解器解决该静态问题。
-
在线动态规划法(Online Dynamic Programming,DP):利用预计通行时间图片作为通行时间,采用类似于Held-Karp算法的动态规划方法求解最优解。选择最优解中的下一个点。
-
M1-FF:将模型M1中的自注意力层替换成全连接层。
-
M2-NP:整体训练整个模型M2,而不对两个子模型预训练。
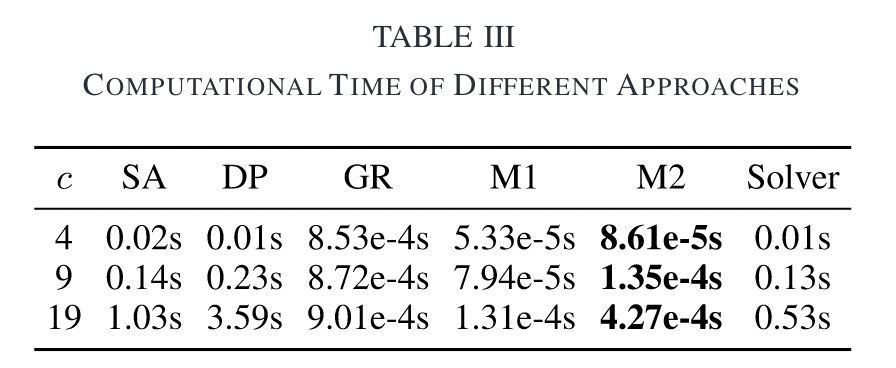
首先测试各算法的运行时间,模型M1与M2的运行时间是毫秒级的,比其它的对比算法运行时间都快。
之后,测试了只有边权变化的算例下各算法的表现,结果表明模型M1在大部分算例下都显著优于其它算法(平均比Solver,DP,SA提升5%),而模型M2稍差于M1(1%)但比其它对比算法优秀。接下来,我们测试了既有边权变化,又有节点变化的算例。结果表明模型M2在大部分算例下优于其它算法(比Solver及DP提升约1%),而M1的表现不如M2,Solver和DP,而优于GR, M1-FF和M2-NP。最后,我们测试了动态取货送货问题的算例。在此数据集下,模型M2的表现依然优于其它算法(比DP提升约1%)。而模型M1差于M2与DP,而优于GR。
可以看出,研究方法可以在极短的时间内为动态旅行商问题提供一个高质量的解。
4.代码分享
代码篇幅较长,下面将以Model 1为例进行代码讲解。
baselines.py
这段代码主要定义了几个基线类,用于对模型的评估。下面对部分代码进行介绍
# 随机生成城市坐标数据以模拟TSP问题
class TSPDataset(Dataset):
# 以贪心的方式解码TSP实例并计算预测旅行路径的成本,从而评估模型。
def rollout(mat, model, dataset, opts):
# Put in greedy evaluation mode!
set_decode_type(model, "greedy")
model.eval()
def eval_model_bat(bat):
with torch.no_grad():
cost, _, _ = model(mat, move_to(bat, opts.device))
return cost.data.cpu()
return torch.cat([
eval_model_bat(bat)
for bat in DataLoader(dataset, batch_size=opts.eval_batch_size)
], 0)
...
其中,基线类分为:
-
Baseline:基线的抽象基类。 -
WarmupBaseline:一个基线,从指数移动平均开始,并在热身期后过渡到另一个基线。 -
NoBaseline:始终返回零的基线,表示没有基线。 -
ExponentialBaseline:使用成本的指数移动平均的基线。 -
CriticBaseline:使用critic网络来估计路径成本的基线。 -
RolloutBaseline:利用现有的模型在验证集上进行rollout以估计当前策略的好坏,并且当候选模型性能优于现有基线时,会更新基线模型。
基线类方法的作用为:
-
wrap_dataset: 对数据集应用特定的基线处理逻辑。 -
unwrap_batch: 将批次数据还原为其原始形式及对应的基线值。 -
eval: 计算给定状态下的价值评估和损失。 -
epoch_callback: 每个训练周期结束时调用的方法,用于更新基线、检查模型性能等操作。 -
state_dict和load_state_dict: 实现模型状态的序列化和加载,以便于模型保存与恢复。
options.py
这段代码使用argparse库解析命令行参数,用于配置和运行注意力模型,并返回一个包含所有选项的对象 opts。下面对部分代码进行介绍:
import os
import time
import argparse
import torch
def get_options(args=None):
parser = argparse.ArgumentParser(
description="Attention based model for solving the Travelling Salesman Problem with Reinforcement Learning")
# Data
#add_argument读入命令行参数
parser.add_argument('--problem', default='tsp', help="The problem to solve, default 'tsp'")
parser.add_argument('--graph_size', type=int, default=19, help="The size of the problem graph")
parser.add_argument('--batch_size', type=int, default=512, help='Number of instances per batch during training')
...
#解析命令行参数,将add_argument获取的信息存储
opts = parser.parse_args(args)
opts.use_cuda = torch.cuda.is_available() and not opts.no_cuda #检查CUDA支持
opts.run_name = "{}_{}".format(opts.run_name, time.strftime("%Y%m%dT%H%M%S"))
opts.save_dir = os.path.join(#保存目录设置
opts.output_dir,
"{}_{}".format(opts.problem, opts.graph_size),
opts.run_name
)
if opts.bl_warmup_epochs is None:#动态设置基线预热周期
opts.bl_warmup_epochs = 1 if opts.baseline == 'rollout' else 0
#检查参数的合理性
assert (opts.bl_warmup_epochs == 0) or (opts.baseline == 'rollout')
assert opts.epoch_size % opts.batch_size == 0, "Epoch size must be integer multiple of batch size!"
return opts
transformer.py
这部分代码主要实现了注意力模型,包含向前传播,注意力机制,参数更新,掩码转换和Skip Connection等操作。
train.py
这段代码用于训练强化学习模型,其中:
-
DistanceMatrix类用于模拟城市间距离,并实现基于时间变化的距离矩阵。定义了两个方法getd 和 getddd,它们都用于获取在某一特定时间 t 下,由状态向量 st 中指定的城市 a 和 b 之间的距离估计。getd 方法针对单个时间点和一对城市计算距离;getddd 方法处理批量计算,接受多个时间和多对城市作为输入,返回距离矩阵。
class DistanceMatrix:
def __init__(self, ci, max_time_step = 100, load_dir = None):
self.n_c = ci.n_cities
self.max_time_step = max_time_step
with torch.no_grad():
self.mat = torch.zeros(self.n_c * self.n_c * max_time_step, device=device)
self.m2 = torch.zeros(self.n_c * self.n_c * max_time_step, device=device)
self.m3 = torch.zeros(self.n_c * self.n_c * max_time_step, device=device)
self.m4 = torch.zeros(self.n_c * self.n_c * max_time_step, device=device)
self.var = torch.full((ci.n_cities * ci.n_cities, 1), 0.03, device = device).view(-1)
#self.var = torch.rand(ci.n_cities * ci.n_cities, device = device) * 0.06
#self.var = torch.randn(ci.n_cities * ci.n_cities, device = device) * 0.05 + 0.03
if (load_dir is not None):
temp = np.loadtxt(load_dir, delimiter=',', skiprows=0)
x = np.arange(max_time_step + 1)
for k in range(self.n_c):
self.var[k*self.n_c+k] = 0
for j in range(self.n_c):
i = k * self.n_c + j
cs = CubicSpline(x, np.concatenate((temp[i], [temp[i,0]]), axis=0), bc_type='periodic')
self.m4[i * max_time_step : i * max_time_step + 12] = torch.tensor(cs.c[0], device=device)
self.m3[i * max_time_step : i * max_time_step + 12] = torch.tensor(cs.c[1], device=device)
self.m2[i * max_time_step : i * max_time_step + 12] = torch.tensor(cs.c[2], device=device)
self.mat[i * max_time_step : i * max_time_step + 12] = torch.tensor(cs.c[3], device=device)
def __getd__(self, st, a, b, t):
a = torch.gather(st, 1, a)
b = torch.gather(st, 1, b)
tt = torch.floor(t * self.max_time_step) % self.max_time_step
zz = (torch.floor(t * self.max_time_step) + 1) % self.max_time_step
c = a.squeeze() * self.n_c * self.max_time_step + b.squeeze() * self.max_time_step + tt.squeeze().long()
d = a.squeeze() * self.n_c * self.max_time_step + b.squeeze() * self.max_time_step + zz.squeeze().long()
a0 = torch.gather(self.mat, 0, c)
a1 = torch.gather(self.m2, 0, c)
a2 = torch.gather(self.m3, 0, c)
a3 = torch.gather(self.m4, 0, c)
b0 = torch.gather(self.mat, 0, d)
z = (t.squeeze() * self.max_time_step - torch.floor(t.squeeze() * self.max_time_step)) / self.max_time_step
z2 = z * z
z3 = z2 * z
res = a0 + a1 * z + a2 * z2 + a3 * z3
minres = (a0 + b0) * 0.05
maxres = (a0 + b0) * 5
res,_ = torch.max(torch.cat((res.unsqueeze(-1), minres.unsqueeze(-1)), dim = -1), dim = -1)
res,_ = torch.min(torch.cat((res.unsqueeze(-1), maxres.unsqueeze(-1)), dim = -1), dim = -1)
return res
def __getddd__(self, st, a, b, t):
s0, s1 = a.size(0), a.size(1)
a = torch.gather(st, 1, a)
b = torch.gather(st, 1, b)
tt = torch.round(t * self.max_time_step) % self.max_time_step
zz = (torch.round(t * self.max_time_step) + 1) % self.max_time_step
c = a * self.n_c * self.max_time_step + b * self.max_time_step + tt.long()
c = c.view(-1)
d = a * self.n_c * self.max_time_step + b * self.max_time_step + zz.long()
d = d.view(-1)
a0 = torch.gather(self.mat, 0, c)
a1 = torch.gather(self.m2, 0, c)
a2 = torch.gather(self.m3, 0, c)
a3 = torch.gather(self.m4, 0, c)
b0 = torch.gather(self.mat, 0, d)
tt = tt.view(-1)
ttt = t.expand(s0, s1).contiguous().view(-1)
z = (ttt * self.max_time_step - torch.floor(ttt * self.max_time_step)) / self.max_time_step
z2 = z * z
z3 = z2 * z
res = a0 + a1 * z + a2 * z2 + a3 * z3
minres = (a0 + b0) * 0.05
maxres = (a0 + b0) * 5
res,_ = torch.max(torch.cat((res.unsqueeze(-1), minres.unsqueeze(-1)), dim = -1), dim = -1)
res,_ = torch.min(torch.cat((res.unsqueeze(-1), maxres.unsqueeze(-1)), dim = -1), dim = -1)
return res.view(s0, s1)
-
rollout 和 roll 函数分别用于执行模型的评估过程,遍历数据集并在贪心解码模式下计算每批数据的成本(cost)。
def rollout(mat, model, dataset, opts):
# Put in greedy evaluation mode!
set_decode_type(model, "greedy")
model.eval()
def eval_model_bat(bat):
with torch.no_grad():
cost, _, _ = model(mat, move_to(bat, opts.device))
return cost.data.cpu()
return torch.cat([
eval_model_bat(bat)
for bat in DataLoader(dataset, batch_size=opts.eval_batch_size)
], 0)
def roll(mat, model, dataset, opts):
# Put in greedy evaluation mode!
set_decode_type(model, "greedy")
model.eval()
c = []
p = []
def eval_model_bat(bat):
with torch.no_grad():
cost, _, pi = model(mat, move_to(bat, opts.device))
return cost.data.cpu(), pi.data.cpu()
for bat in DataLoader(dataset, batch_size=opts.eval_batch_size):
cost, pi = eval_model_bat(bat)
for z in range(cost.size(0)):
c.append(cost[z])
p.append(pi[z])
return torch.stack(p), torch.stack(c)
-
validate 函数用于验证,计算模型在验证集上的平均成本(avg_cost)。
def validate(mat, model, dataset, opts):
# Validate
print('Validating...')
cost = rollout(mat, model, dataset, opts)
avg_cost = cost.mean()
print('Validation overall avg_cost: {} +- {}'.format(
avg_cost, torch.std(cost) / math.sqrt(len(cost))))
return avg_cost
-
train_batch 函数定义了单个训练批次的过程,包括前向传播、计算损失、反向传播更新模型参数,并记录训练指标。
def train_batch(mat,model,optimizer,baseline,epoch,batch_id,step,batch,tb_logger,opts):
x, bl_val = baseline.unwrap_batch(batch)
x = move_to(x, opts.device)
bl_val = move_to(bl_val, opts.device) if bl_val is not None else None
# print(x.size())
# Evaluate model, get costs and log probabilities
cost, log_likelihood,_ = model(mat, x)
# Evaluate baseline, get baseline loss if any (only for critic)
bl_val, bl_loss = baseline.eval(x, cost) if bl_val is None else (bl_val, 0)
# Calculate loss
reinforce_loss = ((cost - bl_val) * log_likelihood).mean()
loss = reinforce_loss + bl_loss
# Perform backward pass and optimization step
optimizer.zero_grad()
loss.backward()
# Clip gradient norms and get (clipped) gradient norms for logging
grad_norms = clip_grad_norms(optimizer.param_groups, opts.max_grad_norm)
optimizer.step()
# Logging
if step % int(opts.log_step) == 0:
log_values(cost, grad_norms, epoch, batch_id, step,
log_likelihood, reinforce_loss, bl_loss, tb_logger, opts)
-
train_epoch 函数负责一个完整训练周期的执行,其中包括生成新的训练数据、进行多个训练批次的迭代,以及在每个epoch结束时进行模型验证和保存模型状态。
def train_epoch(mat, ci, model, optimizer, baseline, lr_scheduler, epoch, val_dataset, tb_logger, opts):
print("Start train epoch {}, lr={} for run {}".format(epoch, optimizer.param_groups[0]['lr'], opts.run_name))
step = epoch * (opts.epoch_size // opts.batch_size)
start_time = time.time()
lr_scheduler.step(epoch)
if not opts.no_tensorboard:
tb_logger.log_value('learnrate_pg0', optimizer.param_groups[0]['lr'], step)
# Generate new training data for each epoch
training_dataset = baseline.wrap_dataset(TSPDataset(ci, size=opts.graph_size, num_samples=opts.epoch_size))
training_dataloader = DataLoader(training_dataset, batch_size=opts.batch_size)
# Put model in train mode!
model.train()
set_decode_type(model, "sampling")
for batch_id, batch in enumerate(training_dataloader):
train_batch(mat,model,optimizer,baseline,epoch,batch_id,step,batch,tb_logger,opts)
step += 1
epoch_duration = time.time() - start_time
print("Finished epoch {}, took {} s".format(epoch, time.strftime('%H:%M:%S', time.gmtime(epoch_duration))))
if (opts.checkpoint_epochs != 0 and epoch % opts.checkpoint_epochs == 0) or epoch == opts.n_epochs - 1:
print('Saving model and state...')
torch.save(
{
'model': get_inner_model(model).state_dict(),
'optimizer': optimizer.state_dict(),
'rng_state': torch.get_rng_state(),
'cuda_rng_state': torch.cuda.get_rng_state_all(),
'baseline': baseline.state_dict()
},
os.path.join(opts.save_dir, 'epoch-{}.pt'.format(epoch))
)
avg_reward = validate(mat, model, val_dataset, opts)
if not opts.no_tensorboard:
tb_logger.log_value('val_avg_reward', avg_reward, step)
baseline.epoch_callback(model, epoch)
-
run函数实现了从加载数据到模型初始化、训练恢复及初步验证等多个步骤,展示的模型训练流程。