1. Map接口
1.1 Map接口概述
Map接口是一种双列集合。Map的每个元素都包含一个键对象Key和一个值对象Value ,键对象和值对象之间存在对应关系,这种关系称为映射(Mapping)。
Map接口中的元素,可以通过 key 找到 value,因此:
- 一个键只能映射一个值,但允许多个不同的键映射到同一个值上
- 键对象Key必须是唯一的,不允许重复
- 值对象Value允许重复
如下图所示:

1.2 Map接口的实现类
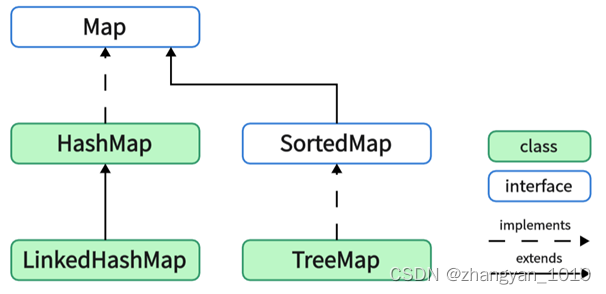
Map接口常用的实现类包括HashMap、TreeMap和LinkedHashMap:
1.3 Map接口的常用方法
Map是实现映射集合的根接口。Map接口定义了关于映射集合的相关的操作方法,常用方法如下所示:
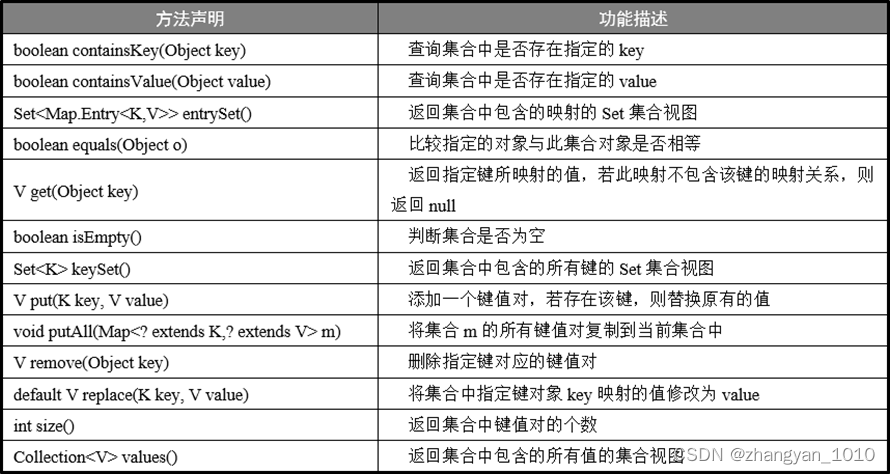
编写代码,测试Map的常用方法。代码示意如下:
import java.util.*;
public class MapDemo1 {
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<>();
// 存放元素,以键值对形式
map.put(1, "Tom");
map.put(3, "Jerry");
map.put(5, "Lucy");
// 获取元素,通过key获取value
String value = map.get(1);
System.out.println("value: " + value); // Tom
String value2 = map.get(2); // 尝试通过不存在的key获取value
System.out.println("value2: " + value2); // 返回null
// 存放已存在的key,则替换value,并返回被替换的value
String oldValue = map.put(1, "Tony");
System.out.println("oldValue: "+oldValue); // Tom
System.out.println("value: " + map.get(1)); // Tony
// 支持基于key删除键值对,返回被删除的value
map.remove(1);
System.out.println("value: " + map.get(1)); // null
// 查询map中是否包含了某个key 或 value
boolean flag1 = map.containsKey(3);
System.out.println("containsKey 3: "+flag1);
boolean flag2 = map.containsValue("Tom");
System.out.println("containsValue Tom: "+flag2);
// 返回包含了所有key的集合
Set<Integer> keys = map.keySet();
System.out.println("keys: " + keys); // [3, 5]
// 返回包含了所有value的集合
Collection<String> values = map.values();
System.out.println("values: " + values); // [Jerry, Lucy]
}
}
2. 哈希表
2.1 初识哈希表
哈希表(Hash Table),也称为散列表,是一种常见的数据结构,用于存储和检索键值对(key-value pairs)。它基于哈希函数将关键字(key)映射到数组索引(下标),以便快速访问和操作数据。
我们通过一个对比案例来介绍哈希表的作用及原理。在这个案例中,我们需要按顺序添加5个键值对,分别是(5, Lucy), (22, Tom), (131, Jerry), (666, Bob), (23, Alice)。
首先,我们来看一下不使用哈希表的情况,默认按照元素的添加顺序将键值对的键存放到数组中,如下图所示。
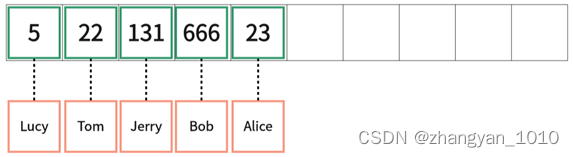
这种方式的缺点在于使用key查询数据时,最差的情况下需要遍历整个数组。
接下来,我们来看一下使用哈希表的情况。想使用哈希表,我们需要先定义一个哈希函数。简单的说,哈希函数是计算一个key对应的数组索引的函数。
在本例中,我们使用的哈希函数如下:
![]()
此时计算得到的key与数组下标的关系如下:

按照这一规则,元素在数组中的存放位置如下:
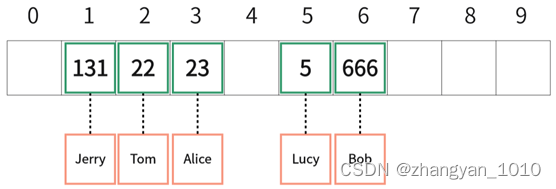
采用这样的方式,使用key查询数据时,可以使用相同的规则计算索引,直接通过计算的结果获取数组该位置元素,查询效率高。
在许多情况下,哈希表比搜索树或任何其他表查找结构平均更有效。 因此,哈希表被广泛用于多种计算机软件,特别是关联数组、数据库索引、缓存和集合。
2.2 哈希算法
哈希函数(也称Hash算法)有多种实现方法,比如“除留取余法”,以及“直接定址法”、“数字分析法”、“分段叠加法”、“平均取中法”、“伪随机数法”等。
除留取余法如下图所示:

2.3 哈希冲突
两个不同的输入值,根据同一哈希函数计算出的索引相同的现象称为哈希冲突,也称为哈希碰撞。
例如,假设数组的长度为10,使用除留取余法,元素18和元素28对应的数组索引均为8,即发生了哈希冲突。
衡量一个Hash算法的重要指标就是发生冲突的概率,以及发生冲突的解决方案。任何Hash函数基本都无法彻底避免冲突,常见的解决冲突的方法有以下几种:
1、开放地址法:一旦发生了冲突,就去寻找下一个空的哈希地址,只要哈希表足够大,总能找到空的哈希地址,并将元素存入。
2、再Hash法:当Hash地址发生冲突时使用其他函数计算另一个Hash函数地址,直到不再产生冲突为止。
3、建立公共溢出区:将Hash表分为基本表和溢出表两部分,发生冲突的元素都放入溢出表。
4、链地址法:将Hash表的每个单元作为链表的头节点,所有Hash地址为i的元素构成一个同义词链表,即发生冲突时就把该元素链接在该单元为头节点的链表的尾部。
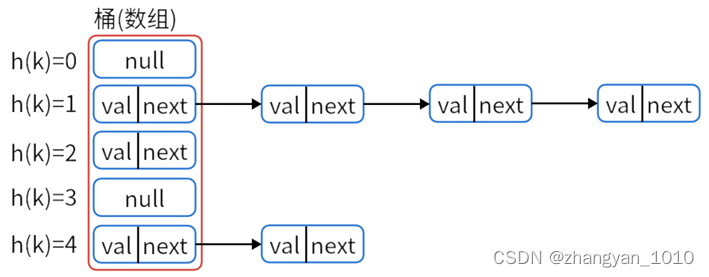
3. HashMap
3.1 HashMap概述
HashMap类是Map接口最常用的实现类之一,内部基于哈希表存储键值对数据,以提供高效的插入、删除和查找操作。HashMap在实际开发中广泛应用于缓存、索引、数据存储和快速查找等场景。
HashMap的内部使用了一个Node类来表示存储在哈希桶(数组)中的键值对。Node类是HashMap的内部私有静态类。
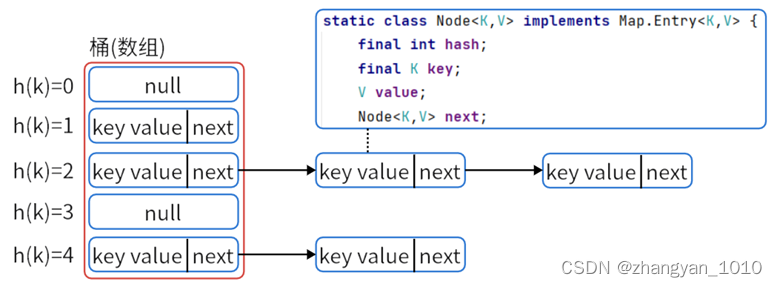
Node类包含了以下几个主要的字段:
- final int hash:存储键的哈希码,用于确定键值对在桶数组中的位置。
- final K key:存储键的值。
- V value:存储与键相关联的值。
- Node<K,V> next:用于处理哈希冲突,存储下一个Node节点的引用,形成链表或红黑树结构。
3.2 HashMap遍历示例
编写代码,测试HashMap的遍历。代码示意如下:
import java.util.*;
public class HashMapDemo1 {
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<>();
// 存放元素,以键值对形式
map.put(5, "Tom");
map.put(3, "Jerry");
map.put(9, "Lucy");
// 通过keySet()方法遍历
Set<Integer> keySet = map.keySet();
for(Integer key : keySet) {
// 基于key查询value,多了一步查询
System.out.println("key: " + key+" value: " + map.get(key));
}
// 通过entrySet方法遍历(推荐),一次查询出全部键值对
Set<Map.Entry<Integer,String >> entrySet = map.entrySet();
for(Map.Entry<Integer,String> entry:entrySet){
System.out.println("key: " + entry.getKey()+" value: " + entry.getValue());
}
}
}
3.3 hashCode方法
在前面的案例中,我们使用的key是整型,可以直接参与取余运算。如果我们想要使用字符串或者自定义类型(例如Student)作为key,是否还能使用哈希表呢?答案是肯定的。
Java在Object类中设计了hashCode方法,用于返回当前对象的哈希值。通过下面的源码可以看到,该方法返回的是一个int类型的值。

通过这样的设计,任意一个Java对象均可以作为哈希表的key。

3.4 put方法的执行流程
当使用HashMap对象的put方法存储一个键值对时,一般会经过以下几步:
1、计算Key的哈希值。
- 如果Key为null,则哈希值为0
- 如果Key不为null,调用Key的hashCode方法,计算Key的哈希值
2、如果内部数组没有被初始化,会先初始化内部数组。
3、通过Key的哈希值计算Key在桶(数组)中的位置。
4、如果桶中目标位置没有元素,则创建Node对象,存储键值对数据,并将Node对象保存到桶中目标位置。
5、如果桶中目标位置有元素(注意可能有多个),则将key与这些元素的key进行比较。
- 如果Key与某个元素的Key相等(== 或 equals),则使用新存入的Value覆盖旧的Value
- 如果Key与桶中该位置的所有元素都不相等,则创建新的Node对象,存储键值对数据,并追加到链表中
3.5 put方法示例
编写代码,测试HashMap的遍历。代码示意如下:
import java.util.HashMap;
import java.util.Map;
public class HashMapDemo2 {
public static void main(String[] args) {
// 使用包裹类作为Key
Map<Integer, String> map1 = new HashMap<>();
map1.put(1, "Tom");
map1.put(1, "Jerry");
System.out.println(map1.get(1)); // Jerry
// 使用自定义类作为Key
Map<Student, String> map2 = new HashMap<>();
Student s1 = new Student("Tom", 18);
Student s2 = new Student("Tom", 18);
map2.put(s1, "Tom");
map2.put(s2, "Jerry");
System.out.println(map2.get(s1)); // Tom
System.out.println(map2.get(s2)); // Jerry
// hashCode不同导致不会调用equals方法
System.out.println("s1.hashCode:"+s1.hashCode()); // 990368553
System.out.println("s1.hashCode:"+s2.hashCode()); // 1096979270
}
}
class Student{
String name;
Integer age;
public Student(String name, Integer age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object obj) { // 案例中的equals并没有被调用
System.out.println("equals方法被调用了:" + obj);
return super.equals(obj);
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
3.6 重写hashCode方法
结合put方法的执行流程及上面案例的执行效果我们可以发现:使用hashCode方法的默认实现逻辑,可能导致HashMap无法正确识别两个逻辑相等的Key。
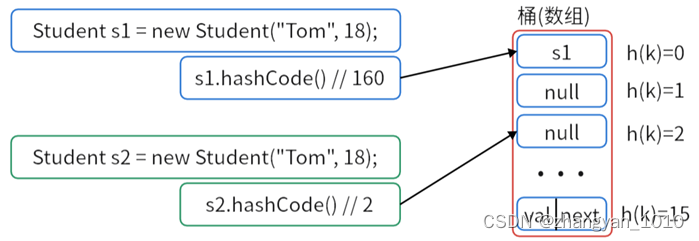
因此,在使用自定义类型作为HashMap中的Key时,需要重写该类的hashCode方法,以满足以下要求。
1、多次调用同一个对象的hashCode方法,应返回相同的哈希码。
2、如果两个对象被equals()方法判断为相等,那么它们的hashCode()方法应该返回相同的哈希码。
3、如果两个对象被equals()方法判断为不相等,不强制要求它们的hashCode()方法返回不同的哈希码,但是开发者应该了解,返回不同的哈希码有利于提高哈希表的性能。
集成式开发环境如IDEA和Eclipse均提供了重写hashCode和equals方法的支持,开发者可直接使用,提高开发效率。




![[数据结构]——非递归排序总结——笔试爱考](https://img-blog.csdnimg.cn/direct/e5b9ac54148b40d2b937918e485995ec.png)