【22-处理不平衡数据集:Scikit-learn中的技术和策略】
news2026/2/13 15:51:07

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1641383.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

WebDriver使用带用户名密码验证的IP代理解决方案
背景,使用python3 selenium
先定义一个方法,这里主要用到了chrome插件的功能,利用这个插件来放进代理内容。
def create_proxy_auth_extension(proxy_host, proxy_port,proxy_username, proxy_password, schemehttp):manifest_json "…
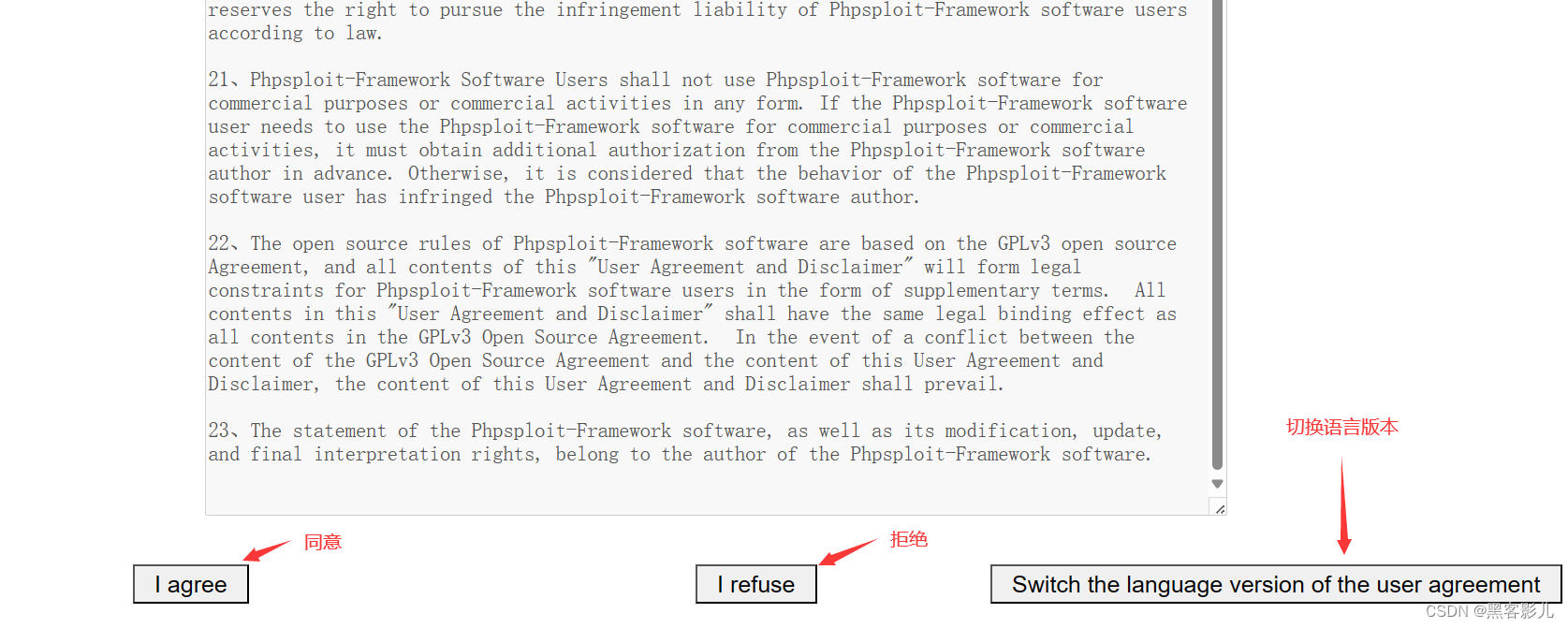
专业渗透测试 Phpsploit-Framework(PSF)框架软件小白入门教程(一)
本系列课程,将重点讲解Phpsploit-Framework框架软件的基础使用!
本文章仅提供学习,切勿将其用于不法手段!
Phpsploit-Framework(简称 PSF)框架软件,是一款什么样的软件呢?
Phpspl…

开源的贴吧数据查询工具
贴吧数据查询工具
这是一个贴吧数据查询工具,目前仍处于开发阶段。
本地运行
要本地部署这个项目,请
克隆这个仓库并前往项目目录
git clone https://github.com/Dilettante258/tieba-tools.git
cd tieba-tools安装依赖
pnpm install运行项目
np…
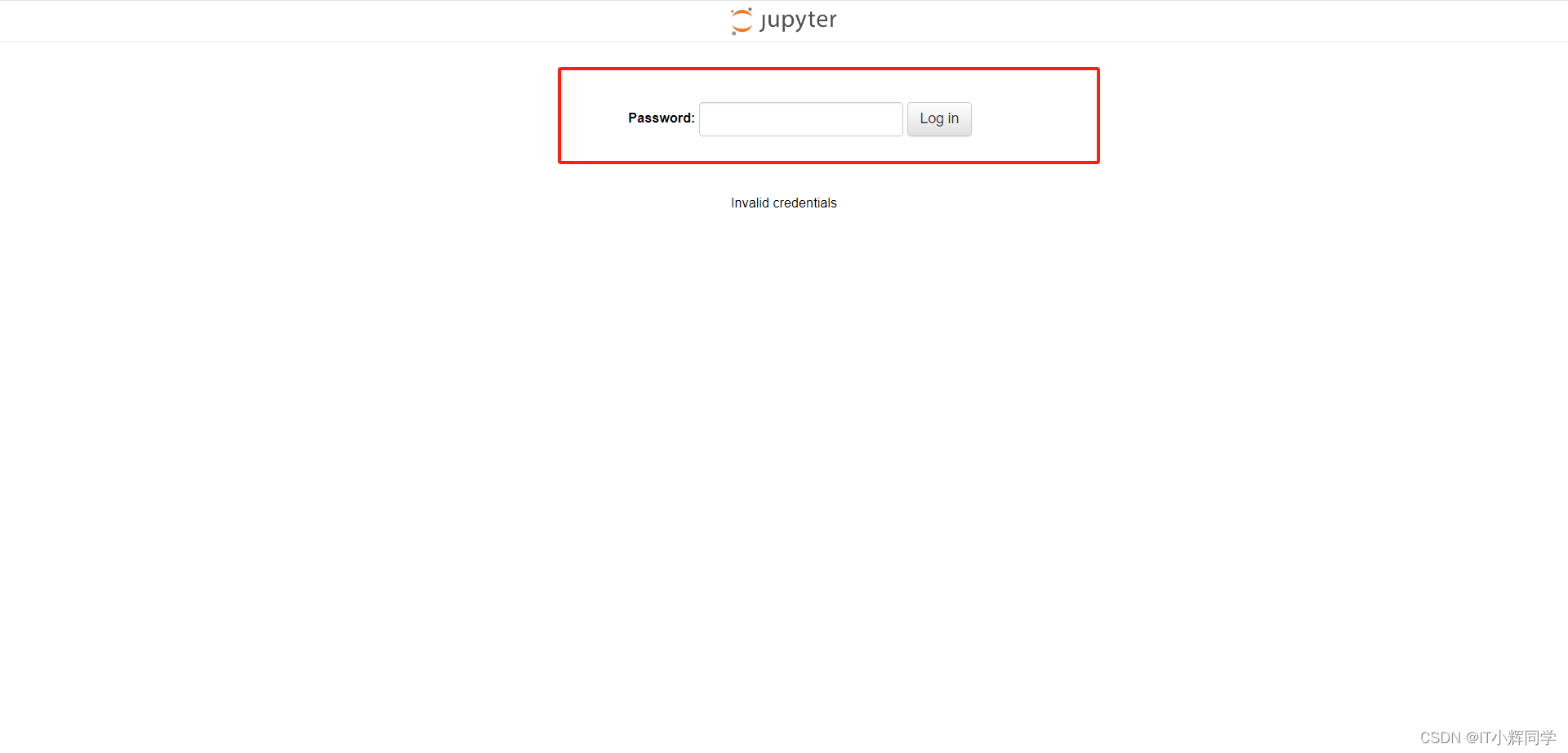
如何配置Jupyter Lab以允许远程访问和设置密码保护
如何配置Jupyter Lab以允许远程访问和设置密码保护 当陪你的人要下车时,即使不舍,也该心存感激,然后挥手道别。——宫崎骏《千与千寻》 在数据科学和机器学习工作流中,Jupyter Lab是一个不可或缺的工具,但是默认情况下…
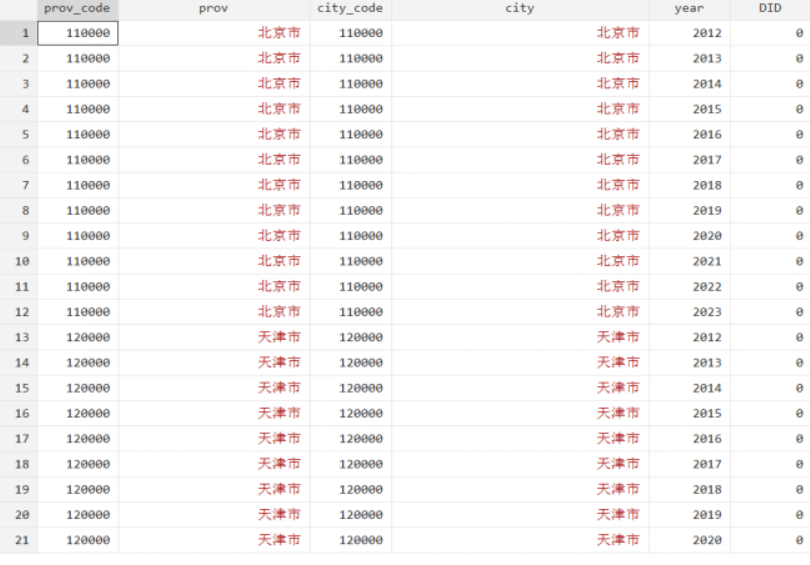
《金融研究》:普惠金融改革试验区DID工具变量数据(2012-2023年)
数据简介:本数据集包括普惠金融改革试验区和普惠金融服务乡村振兴改革试验区两类。
其中,河南兰考、浙江宁波、福建龙岩和宁德、江西赣州和吉安、陕西铜川五省七地为普惠金融改革试验区。山东临沂、浙江丽水、四川成都三地设立的是普惠金融服务乡村振兴…
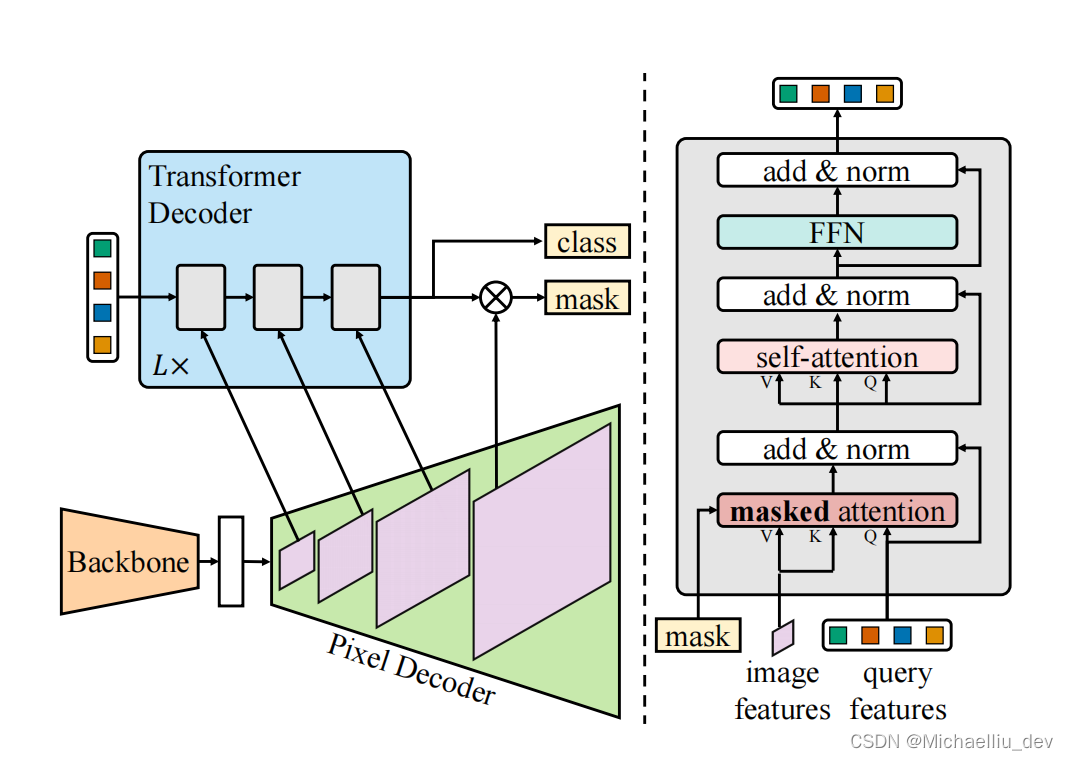
《Mask2Former》算法详解
文章地址:《Masked-attention Mask Transformer for Universal Image Segmentation》 代码地址:https://github.com/facebookresearch/Mask2Former
文章为发表在CVPR2022的一篇文章。从名字可以看出文章像提出一个可以统一处理各种分割任务(…

C++学习第二十二课:STL映射类的深入解析
C学习第二十二课:STL映射类的深入解析
在C标准模板库(STL)中,映射类(std::map和std::multimap)是用来存储关联数据的容器。与集合类不同,映射类中的每个元素都是一个键值对(key-val…
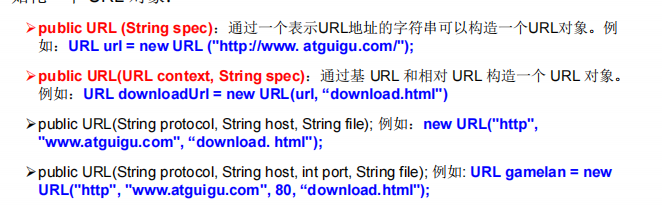
17 内核开发-内核内部内联汇编学习
17 内核开发-内核内部内联汇编学习
课程简介: Linux内核开发入门是一门旨在帮助学习者从最基本的知识开始学习Linux内核开发的入门课程。该课程旨在为对Linux内核开发感兴趣的初学者提供一个扎实的基础,让他们能够理解和参与到Linux内核的开发过程中…
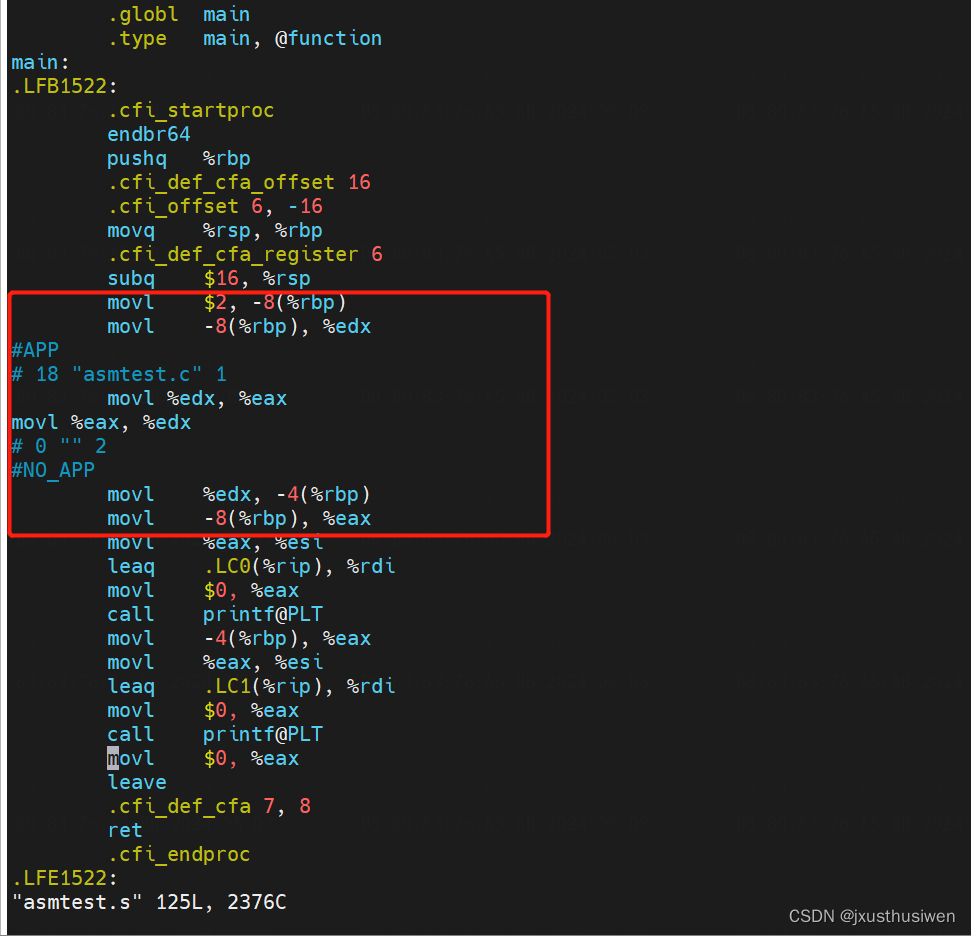
【 书生·浦语大模型实战营】学习笔记(六):Lagent AgentLego 智能体应用搭建
🎉AI学习星球推荐: GoAI的学习社区 知识星球是一个致力于提供《机器学习 | 深度学习 | CV | NLP | 大模型 | 多模态 | AIGC 》各个最新AI方向综述、论文等成体系的学习资料,配有全面而有深度的专栏内容,包括不限于 前沿论文解读、…
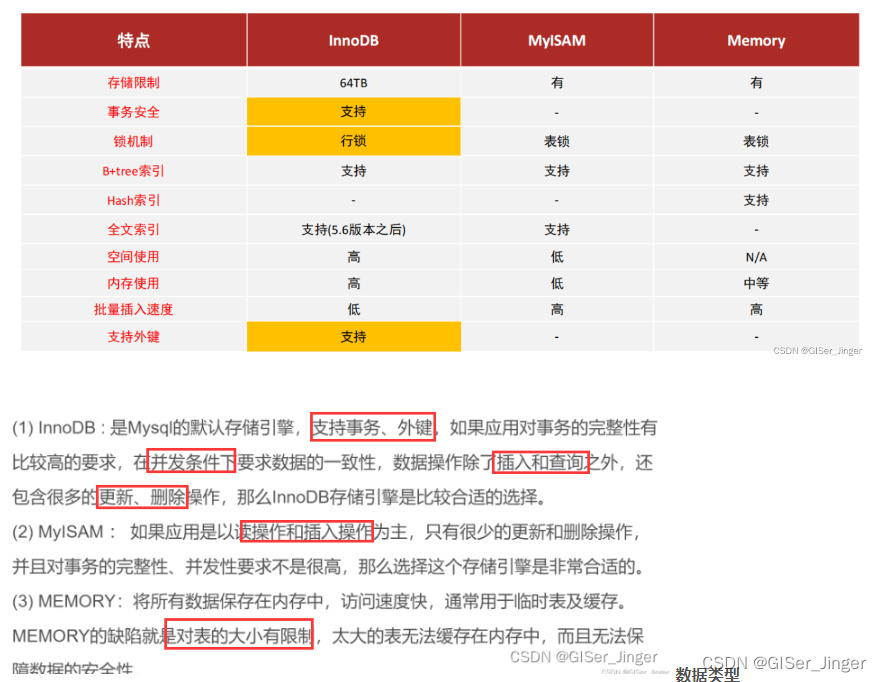
MySQL技能树学习——数据库组成
数据库组成: 数据库是一个组织和存储数据的系统,它由多个组件组成,这些组件共同工作以确保数据的安全、可靠和高效的存储和访问。数据库的主要组成部分包括: 数据库管理系统(DBMS): 数据库管理系…
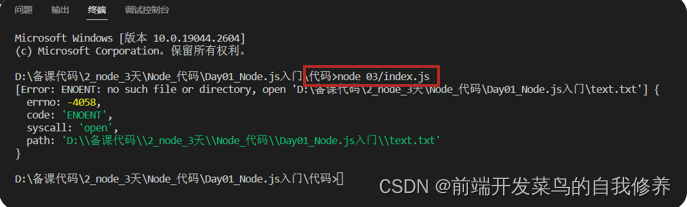
node.js中path模块-路径处理,语法讲解
node中的path 模块是node.js的基础语法,实际开发中,我们通过使用 path 模块来得到绝对路径,避免因为相对路径带来的找不到资源的问题。
具体来说:Node.js 执行 JS 代码时,代码中的路径都是以终端所在文件夹出发查找相…

服务器被攻击,为什么后台任务管理器无法打开?
在服务器遭受DDoS攻击后,当后台任务管理器由于系统资源耗尽无法打开时,管理员需要依赖间接手段来进行攻击类型的判断和解决措施的实施。由于涉及真实代码可能涉及到敏感操作,这里将以概念性伪代码和示例指令的方式来说明。
判断攻击类型
步…
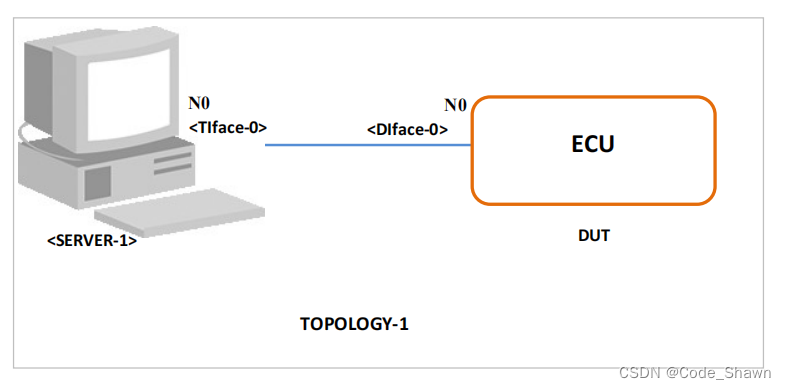
DHCPv4_CLIENT_ALLOCATING_04: 发送DHCPREQUEST - 头部值‘secs‘字段
测试目的:
验证客户端发送的DHCPREQUEST消息是否使用了与原始DHCPDISCOVER消息相同的’secs’字段值。
描述:
本测试用例旨在确保DHCP客户端在发送DHCPREQUEST消息时,使用了与它之前发送的DHCPDISCOVER消息相同的’secs’字段值。这是DHCP…

国产数据库的发展势不可挡
前言
新的一天又开始了,光头强强总不紧不慢地来到办公室,准备为今天一天的工作,做一个初上安排。突然,熊二直接进入办公室,说:“强总老大,昨天有一个数据库群炸了锅了,有一位姓虎的…
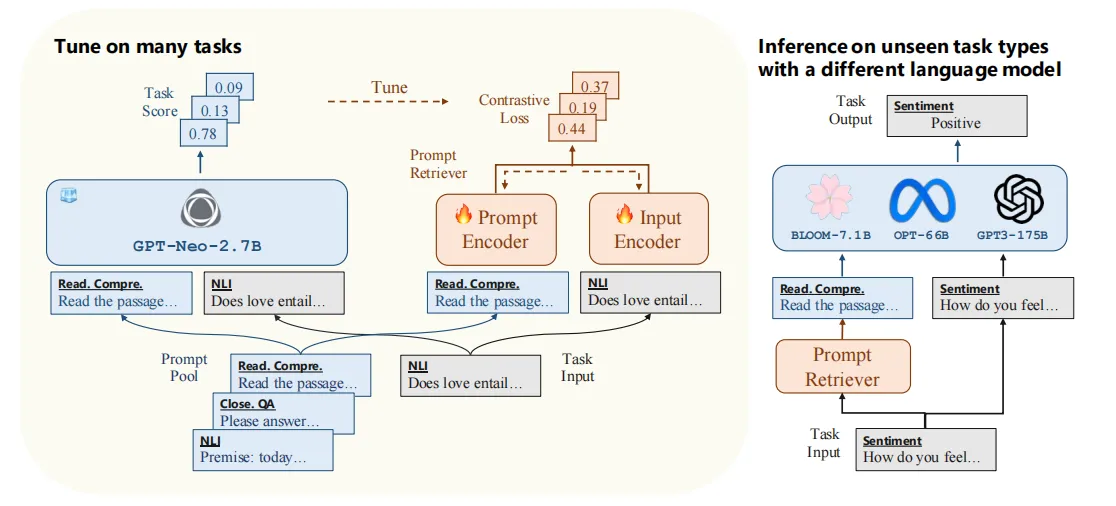
【LLM 论文】UPRISE:使用 prompt retriever 检索 prompt 来让 LLM 实现 zero-shot 解决 task
论文:UPRISE: Universal Prompt Retrieval for Improving Zero-Shot Evaluation ⭐⭐⭐⭐ EMNLP 2023, Microsoft Code:https://github.com/microsoft/LMOps 一、论文速读
这篇论文提出了 UPRISE,其思路是:训练一个 prompt retri…
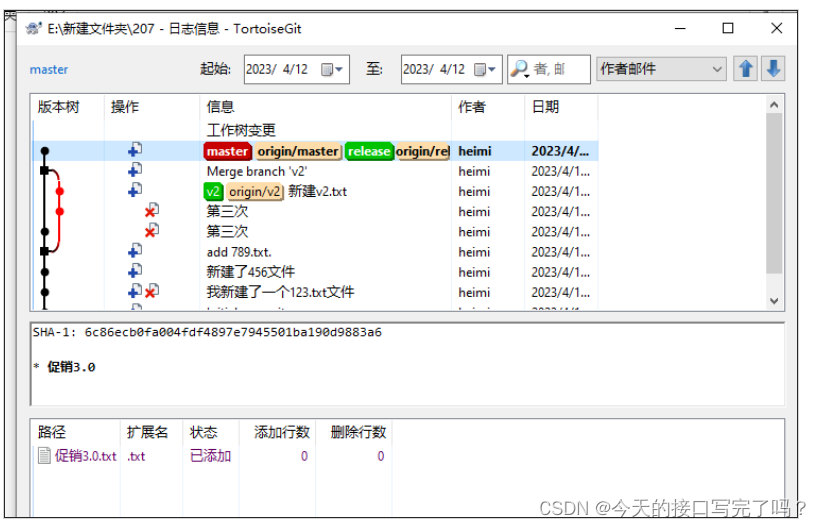
Git可视化工具tortoisegit 的下载与使用
一、tortoisegit 介绍
TortoiseGit 是一个非常实用的版本控制工具,主要用于与 Git 版本控制系统配合使用。
它的主要特点包括:
图形化界面:提供了直观、方便的操作界面,让用户更易于理解和管理版本控制。与 Windows 资源管理器…
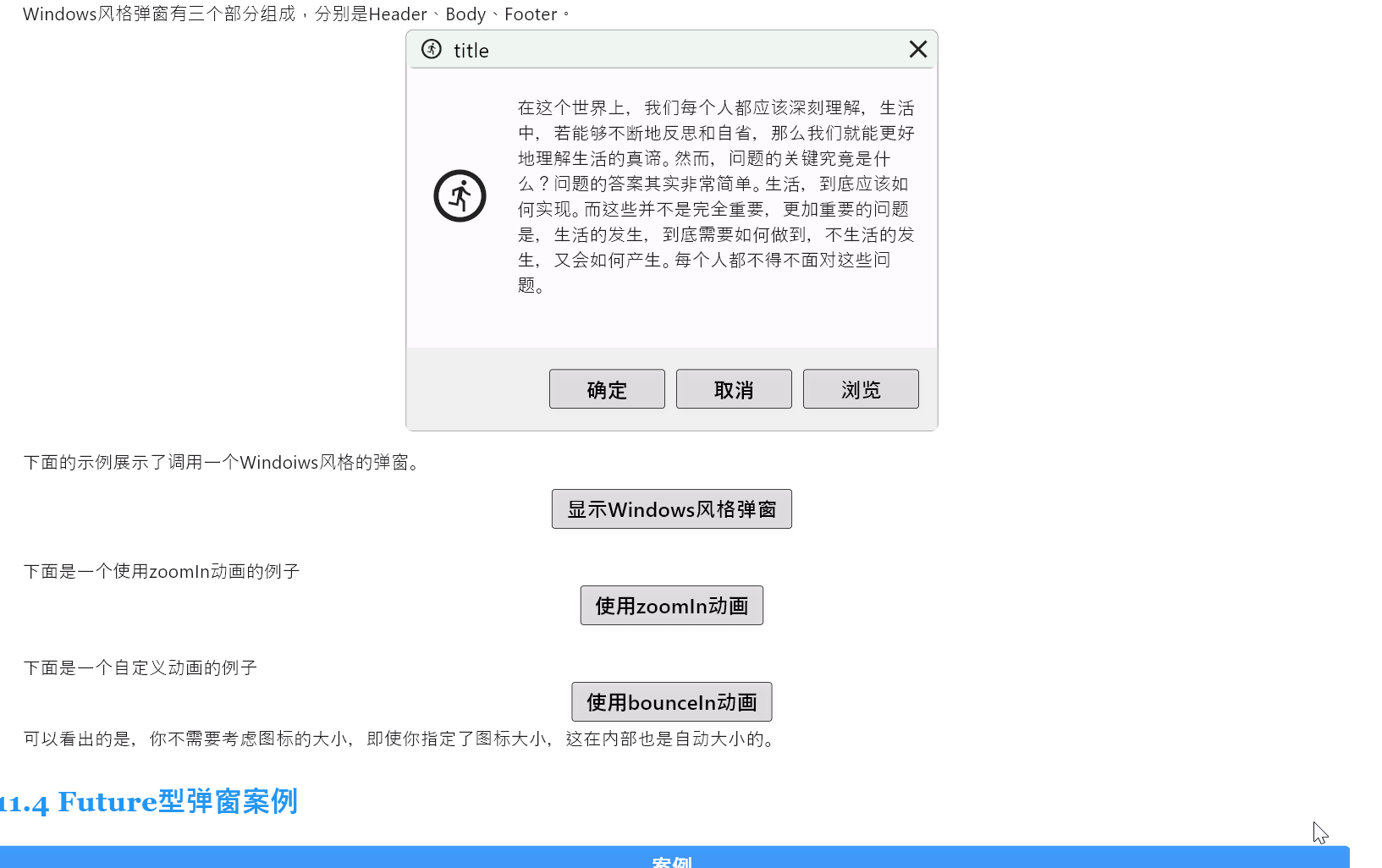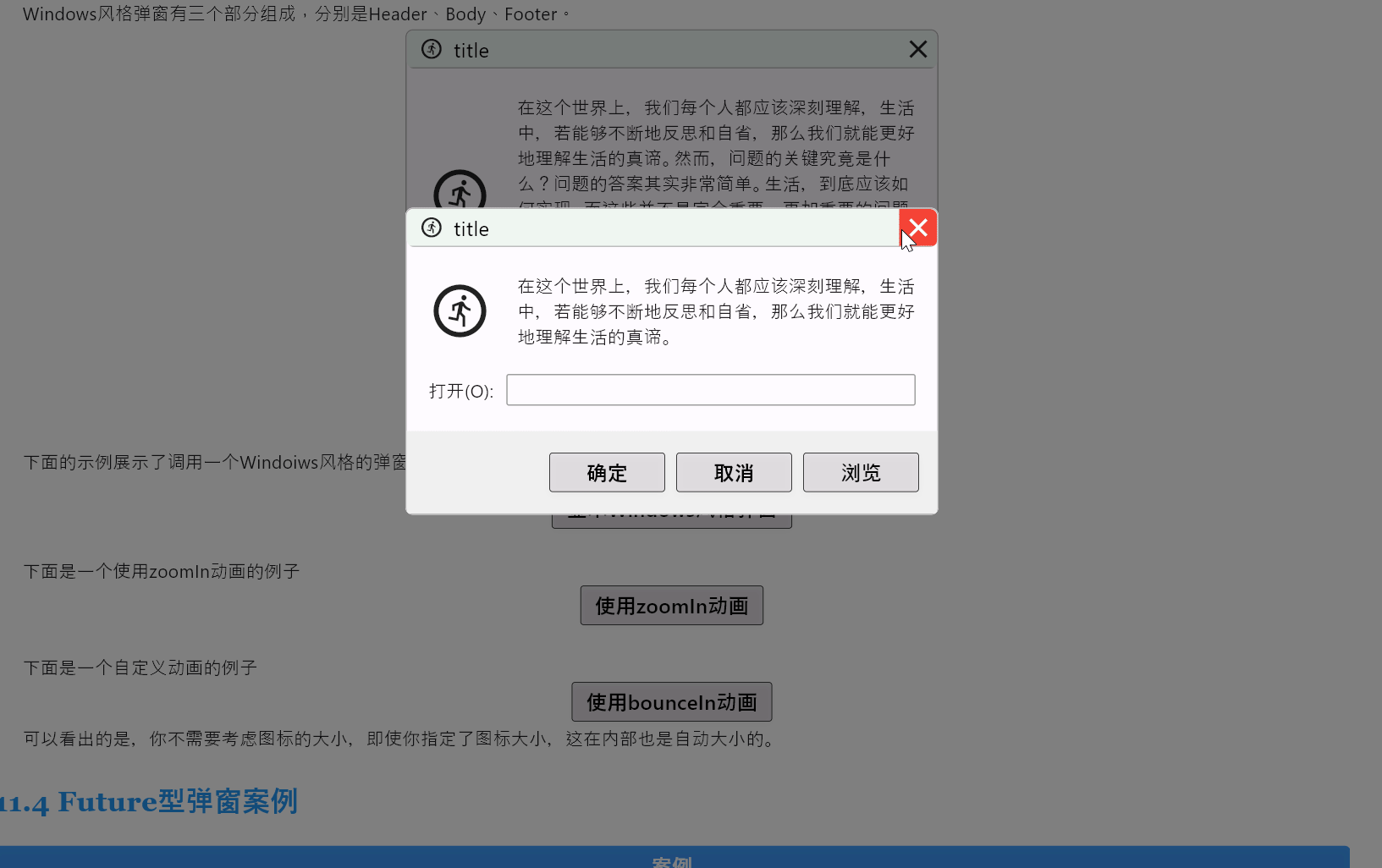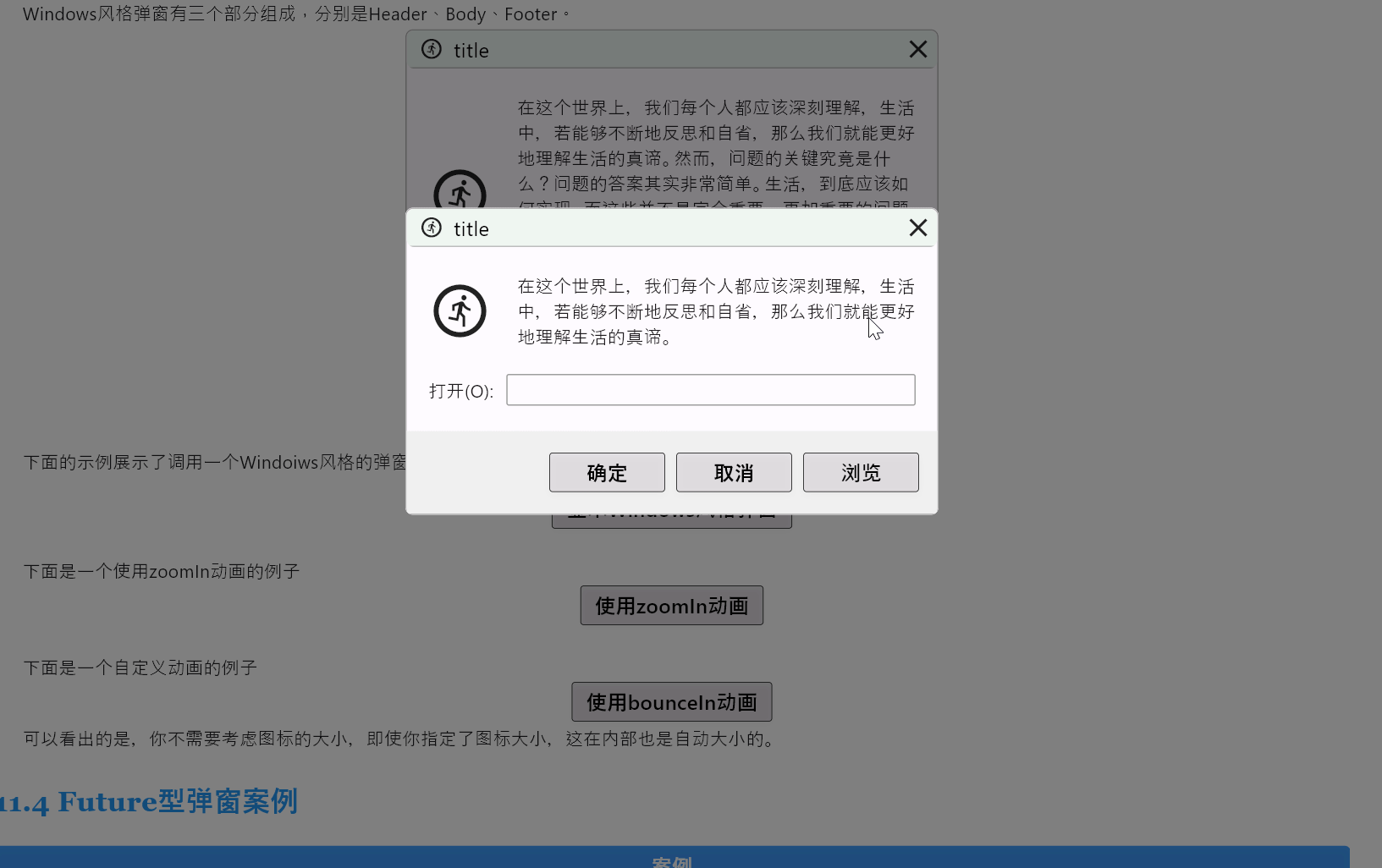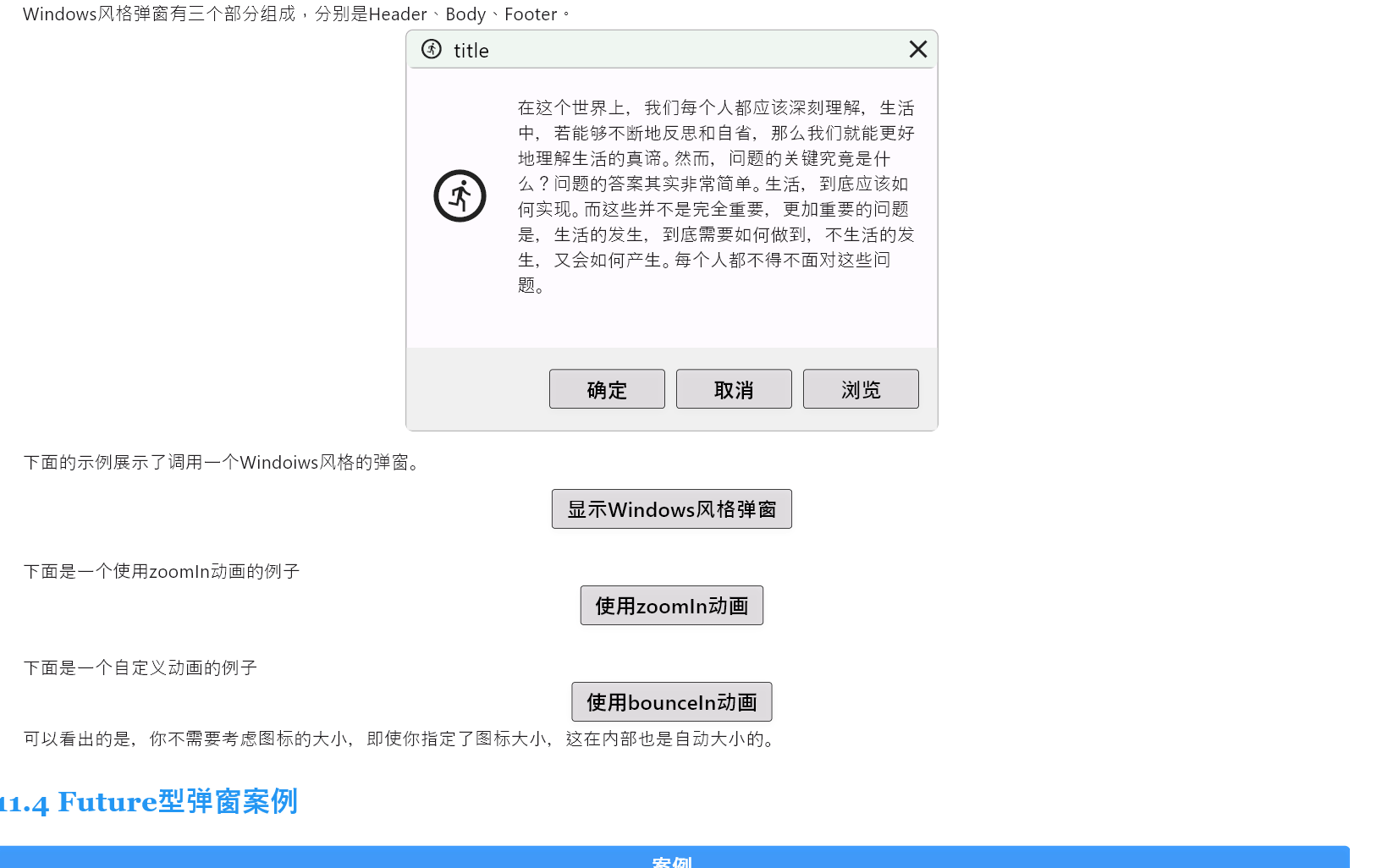
Flutter笔记:Widgets Easier组件库(9)使用弹窗
Flutter笔记 Widgets Easier组件库(9):使用弹窗 -
文章信息 -
Author: 李俊才 (jcLee95) Visit me at CSDN: https://jclee95.blog.csdn.netMy WebSite:http://thispage.tech/Email: 291148484163.com. Shenzhen ChinaAddress o…

美国站群服务器的定义、功能以及在网站运营中的应用
美国站群服务器的定义、功能以及在网站运营中的应用
在当今互联网的蓬勃发展中,站群服务器已成为网站运营和SEO优化中不可或缺的重要工具之一。尤其是美国站群服务器,在全球范围内备受关注。本文将深入探讨美国站群服务器的定义、功能以及在网站运营中的…
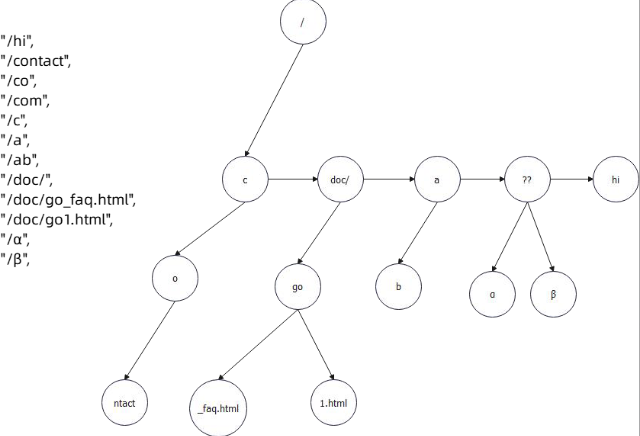
Go实战训练之Web Server 与路由树
Server & 路由树
Server
Web 核心
对于一个 Web 框架,至少要提供三个抽象:
Server:代表服务器的抽象Context:表示上下文的抽象路由树
Server
从特性上来说,至少要提供三部分功能:
生命周期控制&…