目标
使用COIG-CQIA数据集和通用sft数据集对qwen1.5-7b-chat进行sft微调,使用公开dpo数据集进行dpo对齐。学习千问的长度外推方法。
一、训练配置
使用Lora方式, 将lora改为full即可使用全量微调。
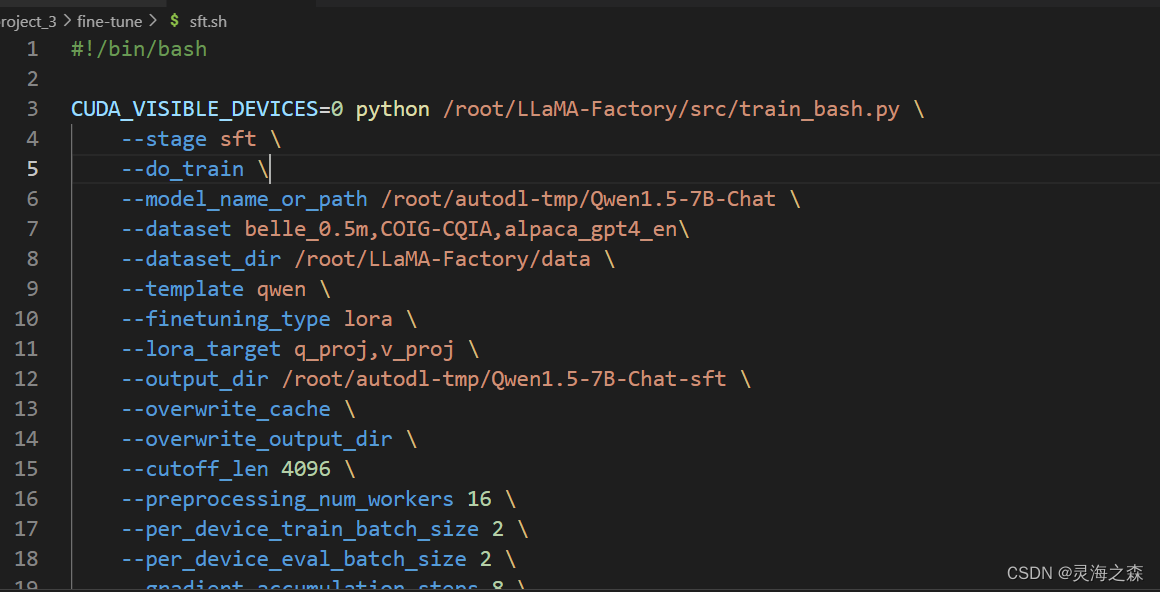 具体的参数在
具体的参数在
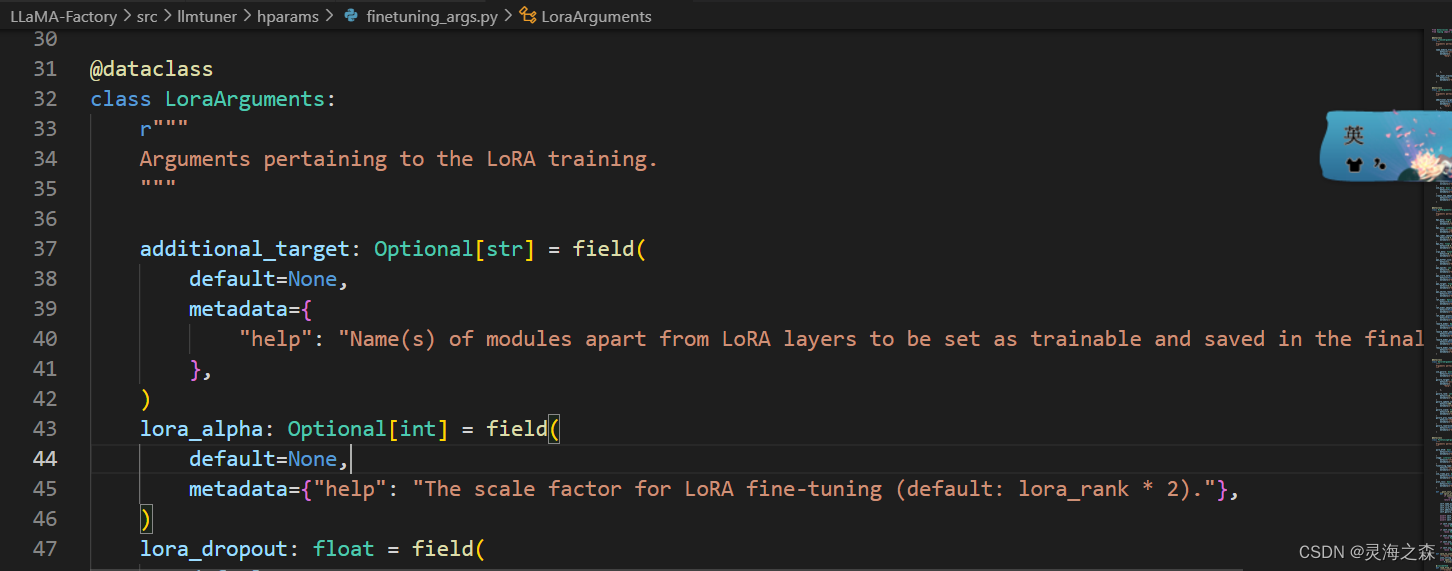
该框架将各个参数、训练配置都封装好了,直接使用脚本,将数据按格式传入即可。
自定义数据集格式:https://github.com/hiyouga/LLaMA-Factory/blob/main/data/README_zh.md
二、sft微调
 文本截断设置为2048,批次大小设置为1,梯度累积设为2,报OOM。
文本截断设置为2048,批次大小设置为1,梯度累积设为2,报OOM。
设置为1024,还是oom.
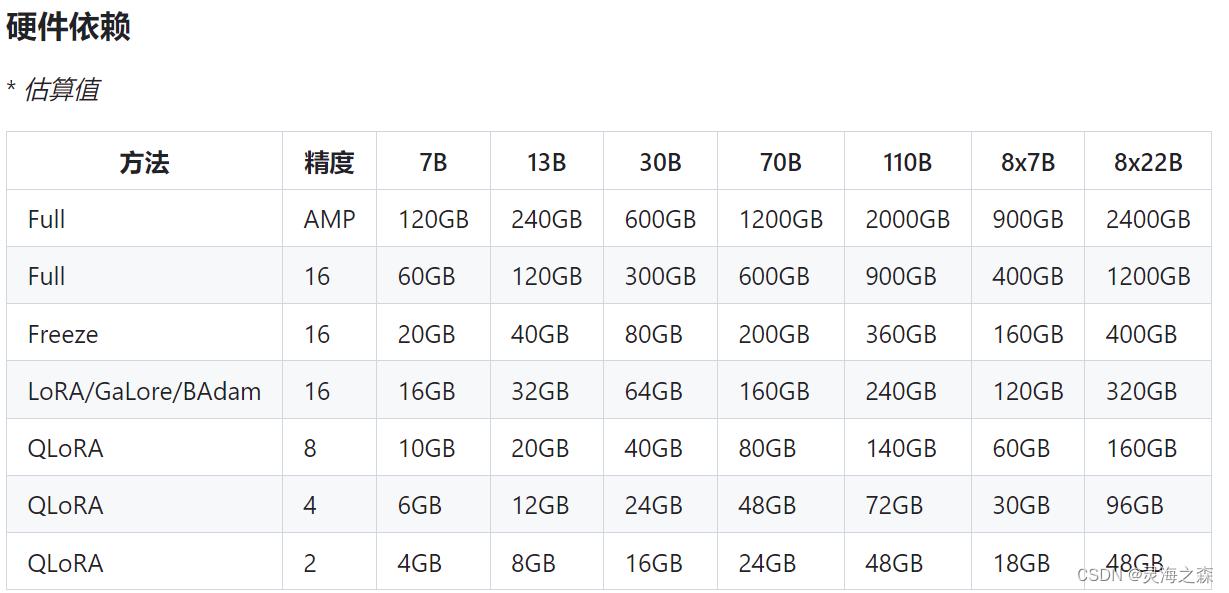
查阅发现7b的全量微调需要60G显存,因此采用lora方式重新微调。
运行截图
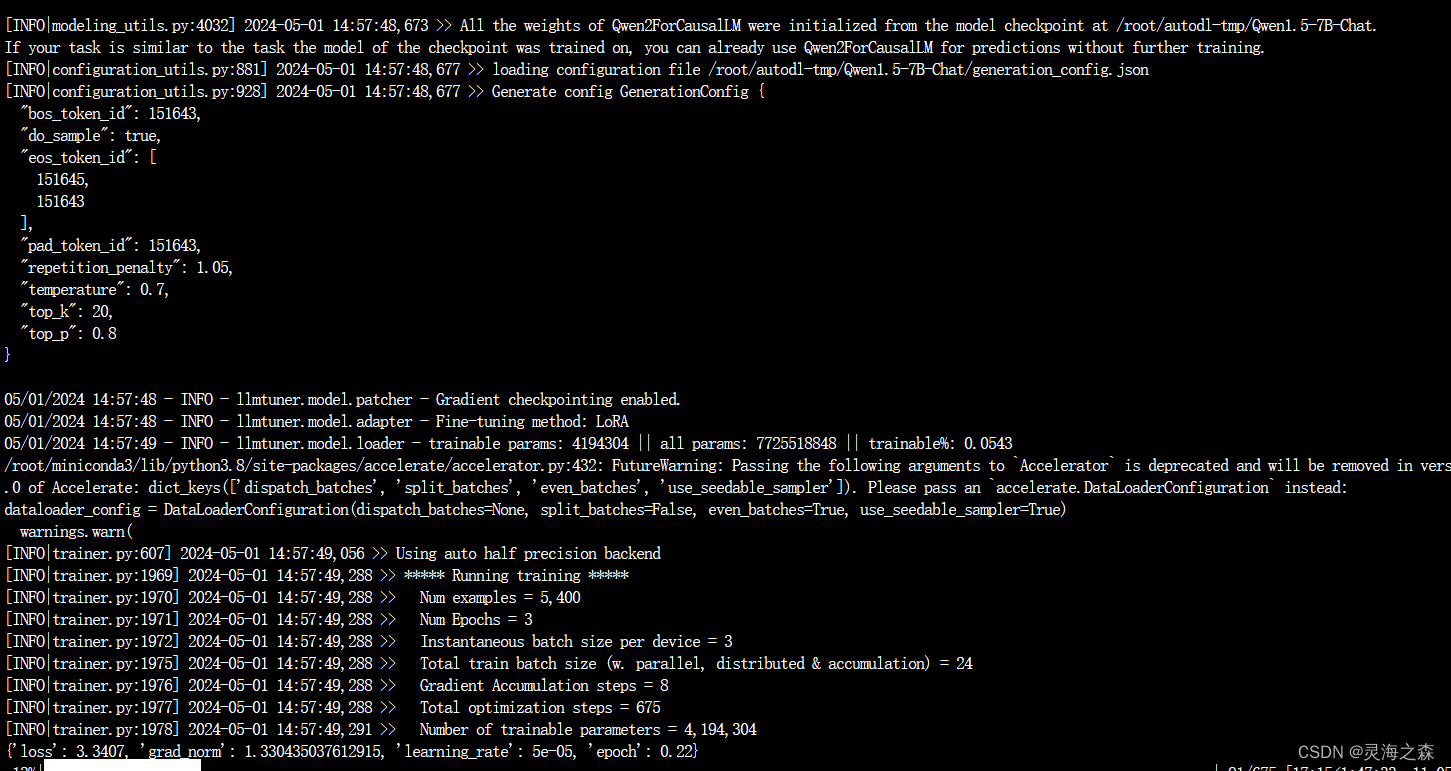
将batch_size设为3,梯度累积设为8步,因此每24步更新一次。
用了两个多小时,训练完成:
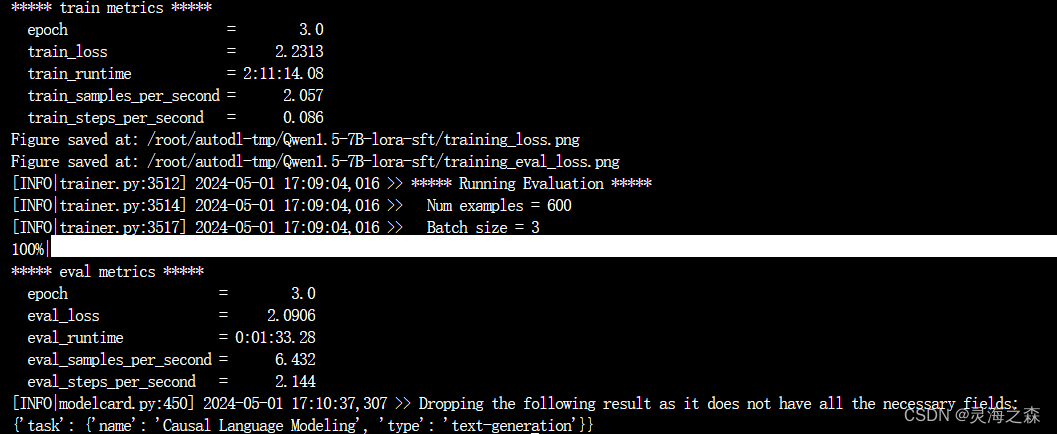
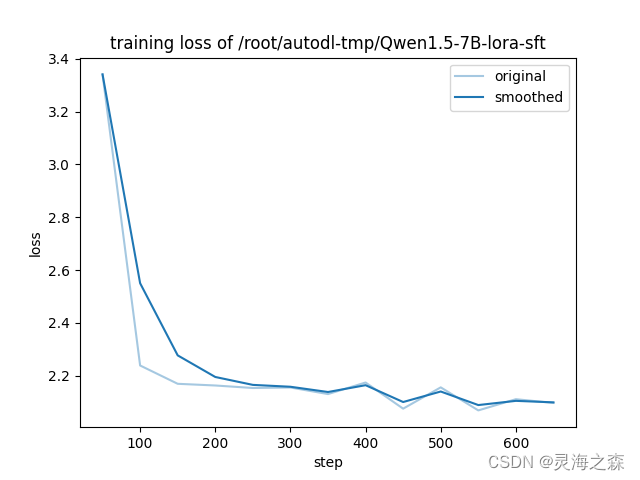
训练过程的loss,可以看到还是加epoch的,最后的的loss看着还有下降空间。
三、dpo微调
采用相同的配置,但是OOM。可能是因为一个样本里有两个output。
设置为1试试。成功
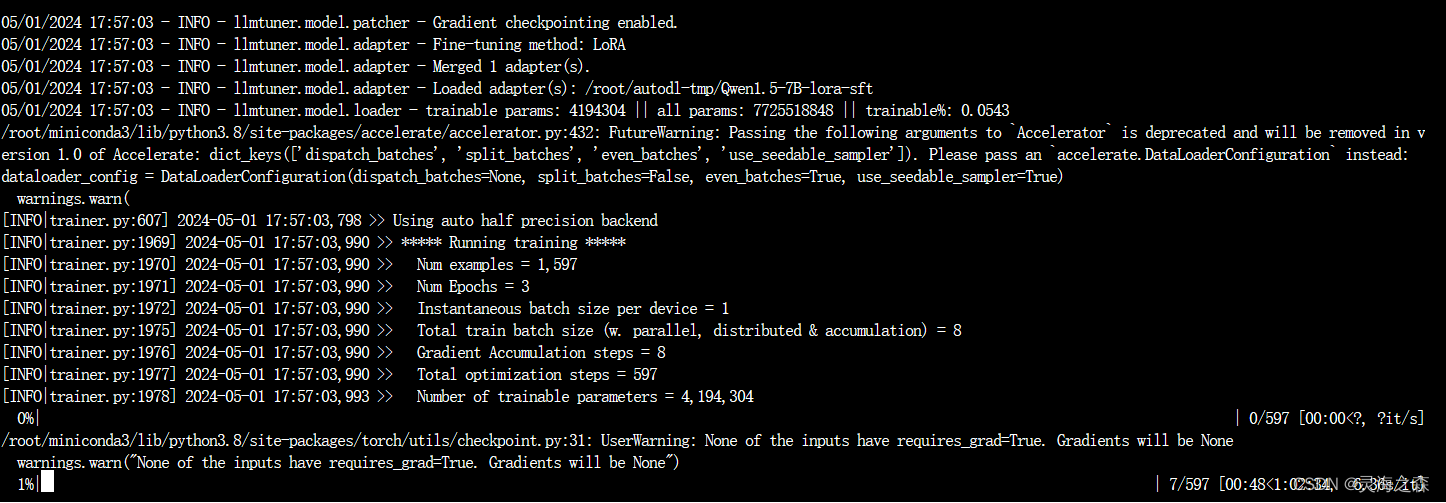 终于结束了,花了近3个小时,主要是批次为1,太慢了。
终于结束了,花了近3个小时,主要是批次为1,太慢了。

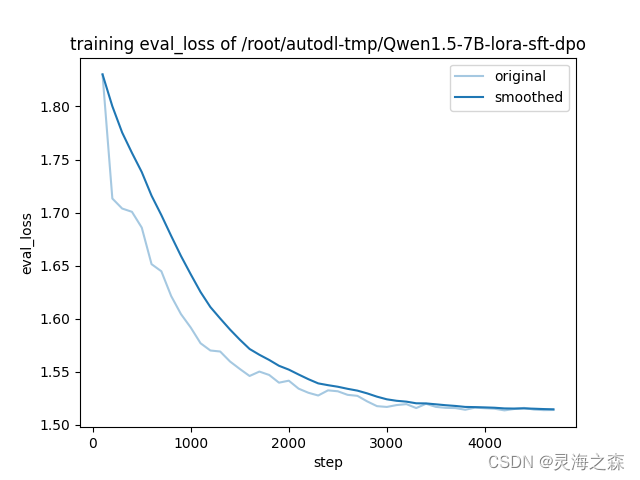
看验证集的损失函数曲线还是不错,训练趋于平稳了。
四、模型评测
大模型评测一直是个难题,模型能力一般可以分为通用能力和特色能力,评测方式可分为客观评测和主观评测。
例如千问1.5,就使用客观评测评估其通用能力。我们可以通过司南这个开源项目在本地评测。
CMMLU是一个综合性的中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力。
Question:同一物种的两类细胞各产生一种分泌蛋白,组成这两种蛋白质的各种氨基酸含量相同,但排列顺序不同。其原因是参与这两种蛋白质合成的:
A. tRNA种类不同
B. 同一密码子所决定的氨基酸不同
C. mRNA碱基序列不同
D. 核糖体成分不同
Answer:C
以该基准为例,评测也就是设置prompt引导模型给出对应的答案,回答应该是如C,C.核糖体成分不同等。但是大模型回复的不稳定性导致有可能是C,C核糖体不同,所以无法精准匹配,司南认为只要是符合人工评判标准的都算对,所以针对其回答做了后处理。

具体到该样本,其函数是:
@TEXT_POSTPROCESSORS.register_module('first-capital')
def first_capital_postprocess(text: str) -> str:
for t in text:
if t.isupper():
return t
return ''
也就是返回回复文本中的第一个大写字母。
对于多项选择的后处理是
@TEXT_POSTPROCESSORS.register_module('first-capital-multi')
def first_capital_postprocess_multi(text: str) -> str:
match = re.search(r'([A-D]+)', text)
if match:
return match.group(1)
return ''
返回文本中由 A 到 D 大写字母组成的字符串。
使用的评测指标是准确率,具体实现如下:
@ICL_EVALUATORS.register_module()
class AccEvaluator(HuggingfaceEvaluator):
"""Accuracy evaluator."""
def __init__(self) -> None:
super().__init__(metric='accuracy')
def _preprocess(self, predictions: List, references: List) -> dict:
"""Preprocess the final predictions and references to needed format.
Args:
predictions (List): List of predictions of each sample.
references (List): List of targets for each sample.
Returns:
dict: preprocessed results.
"""
mapping_to_int_dict = {
label: idx
for idx, label in enumerate(set(map(str, references)))
}
pred_set = set(predictions)
for pred in pred_set:
if str(pred) not in mapping_to_int_dict.keys():
mapping_to_int_dict[str(pred)] = len(mapping_to_int_dict)
golds = [mapping_to_int_dict[str(gold)] for gold in references]
preds = [mapping_to_int_dict[str(pred)] for pred in predictions]
return {
'predictions': preds,
'references': golds,
}
def _postprocess(self, scores: dict) -> dict:
"""Postprocess for final scores.
Args:
scores (dict): Dict of calculated scores of metrics.
Returns:
dict: postprocessed scores.
"""
scores['accuracy'] *= 100
return scores
AccEvaluator 类继承自 HuggingfaceEvaluator,通过预处理、评估、后处理的流程来评估模型的准确性。预处理将标签和预测转换为整数列表,并提供映射;后处理则将准确性转换为百分比。
实操
我们现在需要使用该评测基准评估我们sft和dpo微调后模型的性能,是损失了性能还是增长了。步骤如下:
1.安装司南:见https://github.com/open-compass/opencompass
2.下载数据集到本地,也可以使用hf线上实时下载
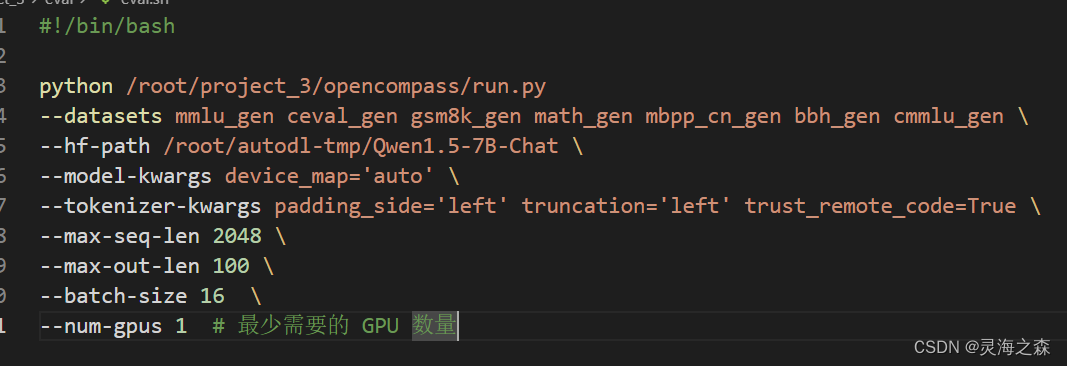
3.新建sh文件编写评测配置,可以命名为run.sh等
 4.如果不想编写sh文件,也可以新建一个Python文件,把配置都写上去,自由度更高
4.如果不想编写sh文件,也可以新建一个Python文件,把配置都写上去,自由度更高
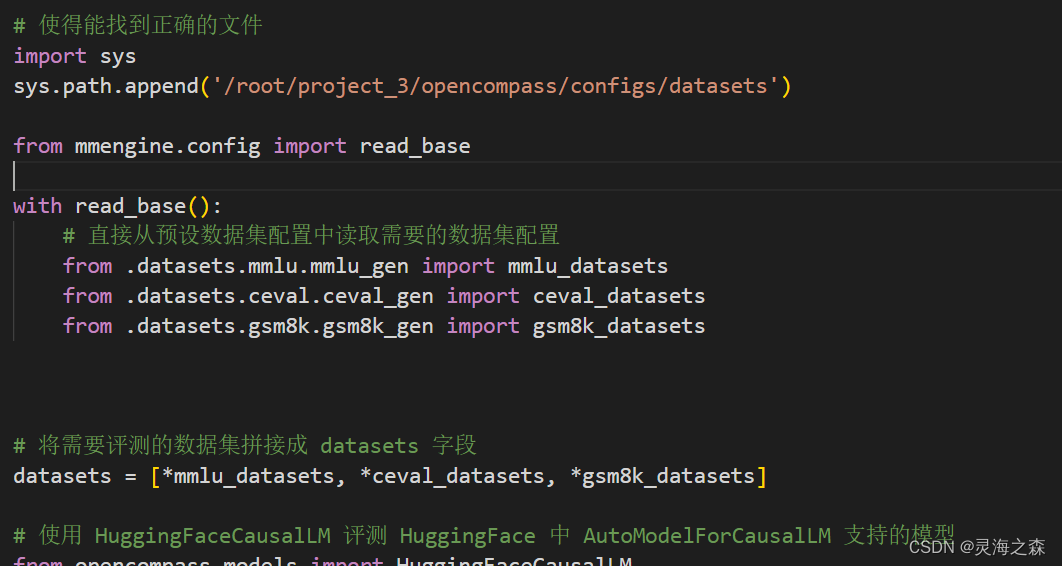 我这里把文件都放在了另外的目录下,所以需要让sh和Python脚本知道所正确引用的文件路径
我这里把文件都放在了另外的目录下,所以需要让sh和Python脚本知道所正确引用的文件路径
报错:
mmengine.config.utils.ConfigParsingError: datasets/mmlu/mmlu_gen.py not found! It means that incorrect module is defined in `with read_base(): = from .datasets.mmlu.mmlu_gen import .