Java集合框架-容器&源码分析
文章目录
- Java集合框架-容器&源码分析
- @[TOC](文章目录)
- 前言
- 一、集合框架概述
- 二、Collection接口及其子接口(List/Set)及实现类
- 2.1 Collection接口中方法
- 2.2 遍历:Iterator迭代器接口&foreach(5.0新特性)
- 2.3 Connection子接口1:List接口及其实现类区别(ArrayList/LinkedList/Vevtor)
- 2.4 Connection子接口2:Set接口及其实现类区别(HashSet/LinkedHashSet/TreeSet)
- 三、Map接口及其实现类(HashMap/LinkedHashMap/TreeMap/Hashtable/Properties)
- 3.1 Map接口中常用的方法&特点
- 3.2 Map主要实现类HashMap/LinkedHashMap
- 3.3 Map实现类TreeMap
- 3.4 Map实现类Hashtable/Properties
- 四、Collections工具类
- 五、企业真题
文章目录
- Java集合框架-容器&源码分析
- @[TOC](文章目录)
- 前言
- 一、集合框架概述
- 二、Collection接口及其子接口(List/Set)及实现类
- 2.1 Collection接口中方法
- 2.2 遍历:Iterator迭代器接口&foreach(5.0新特性)
- 2.3 Connection子接口1:List接口及其实现类区别(ArrayList/LinkedList/Vevtor)
- 2.4 Connection子接口2:Set接口及其实现类区别(HashSet/LinkedHashSet/TreeSet)
- 三、Map接口及其实现类(HashMap/LinkedHashMap/TreeMap/Hashtable/Properties)
- 3.1 Map接口中常用的方法&特点
- 3.2 Map主要实现类HashMap/LinkedHashMap
- 3.3 Map实现类TreeMap
- 3.4 Map实现类Hashtable/Properties
- 四、Collections工具类
- 五、企业真题
前言
补充知识点UML图描述的系统中的类(对象)本身的组成和类(对象)之间的各种静态关系
- 继承关系:【空心三角+实线】(泛化)子类继承父类或子接口继承父接口,并可以增加自己额外的一些功能。
- 实现关系:【空心三角+虚线】class类实现接口(可以实现多个)
- 依赖关系:【虚线】表示一个类A依赖于另一个类B的定义。
A离不开B
举例:类A依赖于类B,即类A中使用到了B对象(表现形式为:成员变量、局域变量、方法的形参、方法返回值、对类B中静态方法的调用)。如果A对象离开B对象,A对象就不能正常编译。 - 关联关系:【实线】类与类之间的联接,一个类知道另一个类的属性和方法(实例变量体现)。A类依赖于B对象,并且把B作为A的一个成员变量, 则A和B存在关联关系。关联可以是双向的,也可以是单向的。两个类之前是一个层次的,不存在部分跟整体之间的关系。
- 聚合关系:【空心菱形】体现整体与部分,“弱拥有”,“has-a”。
两个类不是一个层次上的,可以独立存在。 - 组合关系:【实心菱形】关联关系的一种特例,整体和个体
不能独立存在,“强聚合”,“contains-a”
为什么需要重写自定义类中的equals()、hashCode()、toString()方法?结合下面的源码分析
- Object类中源码实现:hashCode()根据对象的堆内存地址来计算;equals():比较对象的堆内存地址;toString():计算对象的哈希值输出对应的地址值
这些都是针对对象的地址,但是实际中主要是想比较/输出对象具体属性内容。重写方式:hashCode()让属性也参与计算;equals()逐个比较他们的属性;ToString()逐个输出属性内容 - 什么时候会调用到这些方法:自己创建类的对象直接调、将这些对象作为元素存储到集合、数组中时使用其中方法时(这些方法的底层源码也会调用)
比如:Collection接口:contains、equals、remove;Set中重写父类的add()。 - 一个栗子:理解HashSet添加元素的过程:add()方法中调用hashCode()计算其哈希值,计算出在内存中存储的位置,然后再调用equals()比较是否与当前这个位置上的元素相同,如果不相同再存储到单向链表中。【因此需要重写这两个方法,为了比较的是相同内容的对象,而不是内存地址】。ArrayList的add()方法和这个实现是不一样的,因此就造成了不能的功能!!!
→这也就说明了为什么重写equals()同时也要重写hashCode()?保证equals和hashCode的一致性:保证内容相同的对象哈希值一样,通过equals比较也是相等的。就比如在HashSet中会先比较hashCode(),再调用equals()比较
Object类中定义的toString源码、equals源码、hashCode
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
public boolean equals(Object obj) {
return (this == obj);
}
@IntrinsicCandidate
public native int hashCode();
Objects类中equals()、hash()源码、Arrays类中hashCode()源码
public static boolean equals(Object a, Object b) {
return (a == b) || (a != null && a.equals(b));
}
public static int hash(Object... values) {
return Arrays.hashCode(values);
}
public static int hashCode(Object a[]) {
if (a == null)
return 0;
int result = 1;
for (Object element : a)
result = 31 * result + (element == null ? 0 : element.hashCode());//可以看到如果不重写hashCode方法调用的是原来的
return result;
}
重写equals()、hashCode()
@Override
public boolean equals(Object o){
if(this==o) return true;
if(o==null || getclass()!=o.getclass()) return false;
Person person=(Person) o;
return age==person.age && Objects.equals(name,person.name);
}
@Override
public int hashCode(){
//让属性值都参与运算
return Objects.hash(属性1,属性2);//可以理解为给这个对象按照统一的标准计算一个哈希值,如果不重写的话计算出来的哈希值不一样,这样会导致对象属性一样但是却可以同时存储
}
一、集合框架概述
对比点:增删改查插、长度、遍历
内存层面需要针对于多个数据进行存储。此时,可以考虑的容器有:数组、集合类
回顾数组:
- 特点:一旦初始化长度确定、元素类型确定;连续内存空间、有序、可重复;可以存储基本/引用数据类型
- 缺点:长度不可变;单一数据类型;无序、不可重复场景不适用;方法、属性较少;插入、删除性能较差(尾部除外)
数组与集合之间的相互转换
集合—>数组:toArray()
数组—>集合:调用Arrays的静态方法asList(0bject…objs)
int[] arr = new int[10];
arr[0]= 1;
arr[1]="AA";//编译报错
0bject[] arr1 = new 0bject[10];arr1[0]= new String();
arr1[1]= new Date();
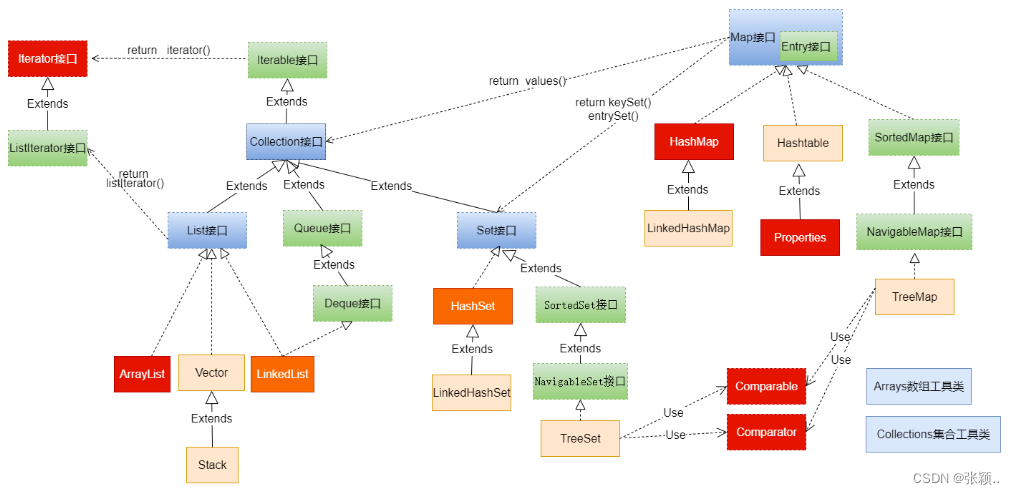
关于其中依赖关系的使用举例
//Map接口依赖于Collection接口: return values()
Map map = new HashMap();
Collection values = map.values();
//Map接口依赖于Set接口: return keySet()、return entrySet();
Set keyset = map.keySet();
Set entryset = map.entrySet();
//Collection接口依赖于Iterator接口: return iterator()
Collection arr = new ArrayList();
Iterator iterator = arr.iterator();
1、Java集合框架体系:也称容器,在java.util包下
- 接口Collection:存储一个一个的数据
- 实现接口List:有序,可重复数据(
动态数组)- 实现类ArrayList:List的主要实现类,线程不安全,效率高
- 实现类LinkedList:同时也是队Deque接口的实现类
- 实现类Vector:List的古老实现类,是栈stack的父类,线程安全,效率低
- 接口Queue:按特定的排队规则确定先后顺序
- 实现接口Set:无序、不可重复,类似高中学习的集合。底层是Hash
- 实现类HashSet:无序,不可重复,底层是数组+单链表+数组+单向链表+红黑树结构,比较是否相等使用hashCode+equals
- LinkedHashSet:HashSet子类,在HashSet基础上多了双向链表维护添加的顺序
- TreeSet:set实现接口SortedSet的子接口的实现类,调用元素对象的comparaTo()方法进行比较,实现排序。
这些底层都已经实现,比如我们在调用add()时,底层会自动调用相关方法。因为要排序所以只能添加同一种类型的数据
- 实现类HashSet:无序,不可重复,底层是数组+单链表+数组+单向链表+红黑树结构,比较是否相等使用hashCode+equals
- 实现接口List:有序,可重复数据(
- 接口Map:存储一堆一堆的数据(key-value键值对),类似于函数。key 是无序的、不可重复的,value 是无序的、可重复的。
- HashMap、LinkedHashMap、TreeMap、Hashtable、Properties
说明:顺序的理解:添加的顺序、集合中存储的顺序、集合中属性元素大小的顺序
2、如何选用集合?
Map接口下k-v键值对,TreeMap排序时,不需要时选HashMap,ConcurrentHashMap可以保证线程安全
Collection 接口下存放元素,唯一Set(如TreeSet 或 HashSet,其中TreeSet排序时用),不需要时选List(如 ArrayList 或 LinkedList)
为什么使用集合?提高了数据的存储和处理灵活性,更好地适应多样化的数据需求。
数组存储一组类型相同的数据。当数据类型多种多样且数量不确定时,就需要使用Java 集合。Java 集合框架中的各种集合类和接口可以存储不同类型和数量的对象,同时还具有多样化的操作方式。Java 集合的优势在于它们的大小可变、支持泛型、具有内建算法等
3、学习的程度把握
- 层次1:针对于具体特点的多个数据,知道选择相应的适合的接口的主要实现类,会实例化,会调用常用的方法。
- 层次2:区分接口中不同的实现类的区别。
- 层次3:① 针对于常用的实现类,需要熟悉底层的源码 ② 熟悉常见的数据结构
二、Collection接口及其子接口(List/Set)及实现类
2.1 Collection接口中方法
1、说明:JDK不提供此接口的任何直接实现,而是提供更具体的子接口(如:Set和List)去实现。该接口里定义的方法既可用于操作 Set 集合,也可用于操作 List 集合。
Collection仅是接口,方法的具体实现是由真正的子类实现的,Set、List也都只是接口
2、具体的方法有:对于List、Set接口下的实现类,这些方法都是通用的。add、remove、size三大方法
- 增:
- add(Object obj):添加元素对象到当前集合中。注意这里是引用类型(如果添加的是基本则会发生自动装箱)
- addAll(Collection other):添加其他集合中所有元素到当前集合中,即this = this ∪ other
- 删
- void clear():清空集合元素,clear()源码本质也是一个一个=null清掉
- boolean remove(Object obj):删除第一个找到的与obj对象equals返回true的元素
- boolean removeAll(Collection coll):从当前集合中删除所有与coll集合中相同的元素。即this = this - this ∩ coll
- retainAll(Collection coll):从当前集合中删除两个集合中不同的元素,使得当前集合仅保留与coll集合中的元素相同的元素,即当前集合中仅保留两个集合的交集,即this = this ∩ coll;
- 长度:
- int size():集合元素个数
- 遍历:
- iterator():返回迭代器对象,用于集合遍历
- foreach循环:即增强for循环
- 判断:
- boolean isEmpty():判空
- boolean contains(Object obj):是否存在与obj对象equals的元素,其中如果对象中重写了equals()表示比较对象内容,否则默认为地址也要一样
- boolean contains(Collection coll):coll是否是是"子集"
- boolean equals(Object obj):判断obj是否相等
- 其他
- Object[] toArray():返回包含当前集合中所有元素的数组
- hashCode():获取集合对象的哈希值
总结:开发中建议:contains、equals、remove等方法时,建议重写元素所属类的的equals()值比较对象属性
举例contain(Object obj)源码中实现:可以看到o.equals(es[i]),使用的是equals,如果obj对象的类中没有重写equals比较的就是对象的地址是否是同一个!!
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
public int indexOf(Object o) {
return indexOfRange(o, 0, size);
}
int indexOfRange(Object o, int start, int end) {
Object[] es = elementData;
if (o == null) {
for (int i = start; i < end; i++) {
if (es[i] == null) {
return i;
}
}
} else {
for (int i = start; i < end; i++) {
if (o.equals(es[i])) {
return i;
}
}
}
return -1;
}
2.2 遍历:Iterator迭代器接口&foreach(5.0新特性)
可以理解为指针,获取集合的迭代器!!
1、接口java.util.Iterator:迭代器接口,不提供存储对象的能力,主要用于遍历Collection中的元素。Iterator迭代器对象在遍历集合时,内部采用指针的方式来跟踪集合中的元素。
2、Iterator接口的常用方法如下:对于List、Set接口下的实现类,这些方法都是通用的
- 删:
default void remove():使用Iterator迭代器删除元素- removeIf(Predicate xx):根据过滤器的规则返回指定元素对象
关于Predicate:可以使用泛型,必须要实现方法public boolean test(Object o){return false}
- 遍历:
public E next():指针下移;下移以后集合位置上的元素返回。配合it.hasNext()进行检测,否则会抛出NoSuchElementException异常。public boolean hasNext():如果仍有元素可以迭代,则返回 true。
3、如何获取迭代器对象:Collection接口依赖Iterator接口,返回一个实现了Iterator接口的对象。
public Iterator iterator(): 获取集合对应的迭代器,用来遍历集合中的元素的。
集合对象每次调用iterator()方法都得到一个全新的迭代器对象,默认游标都在集合的第一个元素之前。
获取集合迭代器对象→遍历集合中的元素:迭代器Iterator、foreach
通常只进行遍历元素,不要在遍历的过程中对集合元素进行增删操作。
Collection coll = new ArrayList();
coll.add("小李广");
coll.add("扫地僧");
coll.add("石破天");
coll.add("佛地魔");
Iterator iter = coll.iterator();//获取迭代器对象,默认游标都在集合的第一个元素之前。
//遍历方式1:Iterator使用集合迭代器对象遍历集合
while(iter.hasNext()){
Object obj = iter.next();
if(obj.equals("Tom")){
iter.remove();//迭代器的remove()可以按指定的条件进行删除
}
}
//遍历方式2:foreach遍历,集合中的都是引用类型数据,即便存的是基本数据类型也会自动装箱
for(Object a : arr){//这里a指的是集合arr中的一个个对象
a = "MM";//赋值操作不一定是修改原集合中的,具体问题具体分析
}
//错误写法1:
while(iter.next()!=null){//每次调用next方法指针都会移动
System.out.print(iter.next());//这相当于又一次移动
}
//错误写法3:每次调用coll.iterator()都会返回一个新的迭代器对象
while(coll.iterator().next()!=null){
System.out.print(coll.iterator().next());//这又是一个新的迭代器对象
}
//新特性:删除元素
coll.removeIf(new Predicate() {
@Override
public boolean test(Object o) {
String str = (String) o;
return str.contains("地");
}
});
removeIf:结合泛型实现对元素对象为偶数的过滤
@Test
public void test3(){
List<Integer> list = new ArrayList<>();//jdk7新特性:类型推断
list.add(12);
list.add(123);
list.add(124);
Iterator<Integer> it = list.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
Predicate<Integer> pre = new Predicate<Integer>() {
@Override
public boolean test(Integer num) {
return num%2==0;//true即为偶数时过滤,false时不过滤
}
};
list.removeIf(pre);
System.out.println(list.toString());
}
对数组的操作
int[] nums = {1,2,3,4,5};
for (int num : nums) {
num=2;//这里修改的不是原数组中的,原数组没有变化
System.out.println(num);
}
System.out.println("-----------------");
String[] names = {"张三","李四","王五"};
for (String name : names) {
name = "石辽旺"//这里修改的也不是原数组
System.out.println(name);
}
4、foreach循环(也称增强for循环):JDK5.0中定义的一个高级for循环,专门用来遍历数组和集合的。集合只能存引用类型!
内部原理是个Iterator迭代器。
foreach循环的语法格式:
for(元素的数据类型 局部变量 : Collection集合或数组){
//操作局部变量的输出操作
}
//这里局部变量就是一个临时变量,自己命名就可以

5、总结
删除集合中元素的几种方式:迭代器的remove()方法VSCollection中的VSJDK8.0新特性removeIf() 方法
遍历集合:获取集合的的迭代器、foreach遍历,其中foreach也可以遍历数组
迭代器的remove()可以指定条件删除,集合中的的remove()方法不能,但是新特性removeif()方法可以
注意:集合只能存引用类型数据,基本类型会自动装箱!
2.3 Connection子接口1:List接口及其实现类区别(ArrayList/LinkedList/Vevtor)
1、List集合类的特点:有序、可重复,“动态数组”
2、List接口中的方法:add、remove、size三大方法
Collection接口中的:增、删、判断、其他、迭代器相关的操作;因为List是有序的,进而就有索引,额外加了一些针对索引操作的方法
- 增:在集合中添加元素。add(Object obj)、addAll(Collection other)
- 删、改:在指定
索引操作Object remove(int index):移除指定index位置的元素,并返回此元素Object set(int index, Object ele):设置指定index位置的元素为ele
- 查:查询指定
索引元素Object get(int index):获取指定index位置的元素- List subList(int fromIndex, int toIndex):返回从fromIndex到toIndex位置的子集合
- 插:指定
索引位置插入元素void add(int index, Object ele):在index位置插入ele元素- boolean addAll(int index, Collection eles):从index位置开始将eles中的所有元素添加进来
- 长度:size()
- 获取元素索引
- int indexOf(Object obj):返回obj在集合中首次出现的位置
- int lastIndexOf(Object obj):返回obj在当前集合中末次出现的位置
- 遍历:
- Iterator iterator():迭代器
- foreach循环
- 一般for循环:利用索引遍历
注意:remove(int index)、remove(Object obj),传入int数字,优先按索引删除。如果想删除元素,把它包装成引用类型
3、List接口及其实现类特点
首先:接口Collection:存储一个一个的数据→Collection的子接口List:有序,可重复数据(动态数组)
- ArrayList:List的主要实现类,线程不安全,效率高;底层使用Object[]数组存储。添加、查找效率高,插入、删除效率低
- Vector:List的古老实现类,线程安全,效率低;底层使用Object[]数组存储。
- 特有方法(古老,了解):void addElement(Object obj)、void insertElementAt(Object obj,int index)、void setElementAt(Object obj,int index)、void removeElement(Object obj)、void removeAllElements()
- LinkedList:底层使用双向链表方式存储。插入、删除效率高,添加、查找效率低
- 特有方法(对首位的操作):void addFirst(Object obj)、void addLast(Object obj) 、Object getFirst()、Object getLast()、Object removeFirst()、Object removeLast()
选择:频繁插入、删除时使用LinkedList
“动态体现”:底层的数组的长度是确定的,使用集合后java有自动扩容机制,创建集合后一开始分配固定长度,满了会自动创建一个容量的数组,再把数据复制过去。
ArrayList删除、插入等操作不用再一个一个移动元素了,但是底层还是在移动的。LinkedList底层不需要移动,因为使用的是链表
理解:Vector是1.0就有的,List接口1.2才出现,出现了以后让Vector成为List接口的实现类,既有它原本对元素的操作方法,同时对于List接口中定义的方法也是适用的,比如Vector中有addElements(Object obj),而List中add(Object obj)也是一样的效果
Vector相当于是上一朝的大呈,改朝换代后成为了List的呈子,既有自己独特的方法,也继承了List提供的接口方法。
ArrayList使用泛型的方式实现
@Test
public void test3(){
List<Integer> list = new ArrayList<>();//jdk7新特性:类型推断
list.add(12);
//list.add("Tom");//编译报错
Iterator<Integer> it = list.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
}
2.4 Connection子接口2:Set接口及其实现类区别(HashSet/LinkedHashSet/TreeSet)
1、Set特点:无序、不可重复,如果试图添加重复的会添加失败(自动去重)
选择:相较于List、Hash使用频率较少,主要功能用来过滤重复数据。
2、Set接口是Collection的子接口,Set接口相较于Collection接口没有提供额外的方法。遍历只有迭代器、foreach
- HashSet:主要实现类,底层使用HashMap,即是用数组+单向链表+红黑树结构进行存储(jdk8中)
- LinkedHashSet:HashSet子类,底层实现,在现有结构基础上,添加了一组双向链表用于记录添加元素的先后顺序→便于
频繁的查询操作,可以按照元素的添加顺序进行遍历。
- LinkedHashSet:HashSet子类,底层实现,在现有结构基础上,添加了一组双向链表用于记录添加元素的先后顺序→便于
- TreeSet:底层使用红黑树,可以按照添加元素的指定的属性的大小顺序进行遍历。(底层用比较器实现,因此必须添加同一类型对象,否则底层比不了大小,会报错ClassCastException)
3、Set的无序性、不可重复性的理解(以HashSet及其子类为例说明)
- 无序性:!=随机性
- 添加元素的顺序和遍历元素的顺序不一致,是不是就是无序性呢? No!
- 无序性:与添加的元素的位置有关,不像ArrayList一样是依次紧密排列的。
- 根据添加的元素的哈希值,计算的其在数组中的存储位置。此位置不是依次排列的,表现为无序性。
- 不可重复性:添加到Set中的元素是不能相同的。
- 比较的标准,需要判断hashCode()得到的哈希值以及equals()得到的boolean型的结果。
- 哈希值相同且equals()返回trve,则认为元素是相同的。因此如果相比较相同内容的对象:如果只重写equals()没重写hashCode(),那么不同对象的哈希值不相等根本比不到equals了,也达不到目的
其一、关于HashSet
1、向HashSet中添加元素的过程
- step1:当向 HashSet 集合中存入一个元素时,HashSet 会调用该对象的 hashCode() 方法得到该对象的 hashCode值,然后根据 hashCode值,通过某个散列函数决定该对象在 HashSet 底层数组中的存储位置。
- step2:如果该数组上没有元素,则直接添加成功。【元素会保存在底层数组中】
- step3:如果有就继续比较两个元素的hashCode值,如果不相等则添加成功。否则会调用该对象的equals()方法,如果为false则添加成功,否则添加失败。【会通过
链表的方式继续链接,存储】
2、添加到HashSet/LinkedHashSet中元素的要求:为了比较对象的内容,而非地址
要求元素所在的类要重写两个方法:equals()和hashCode()
同时,要求equals()和 hashcode()要保持一致性!我们只需要在IDEA中自动生成两个方法的重写即可,即能保证两个方法的一致。
其二、关于LinkedHashSet:是HashSet的子类,在此基础上使用双向链表维护元素的顺序,看起来是有序添加的,插入性能低于HashSet但是适合迭代访问

创建示例:LinkedHasSet
源码add(),会先计算对象的哈希值,如果哈希值一样就再调用对象的equals比较如果一样那么就添加失败。底层是对元素一个一个操作的,调用的元素的方法比较,因此才需要重写哈希方法、equals(),为了保证对象内容相同的哈希值一样。【让对象的属性也参与计算哈希值】
//LinkedHashSet可以按照元素添加的顺序遍历,不是说HashSet不能遍历,只不过它是无序的,我们也不知道其中数据的具体顺序
LinkedHashSet set = new LinkedHashSet();
set.add("11");
set.add("12");
set.add("13");
System.out.println(set.toString());//[11, 12, 13]
其三、关于TreeSet:底层是红黑树。是 SortedSet 接口的实现类,TreeSet 可以按照添加的元素的指定的属性的大小顺序进行遍历。
特点:不可重复,可以实现排序(自然、定制)。因为只有相同类的两个实例才会比较大小,因此向 TreeSet 中是同一个类的对象,并且添加的元素需要考虑排序。
TreeSet特点:不允许重复、实现排序(自然排序或定制排序)。
自然排序:在调用add()方法时,TreeSet 底层源码中会调用集合元素对象中的 compareTo(Object obj) 方法来比较元素之间的大小关系,然后将集合元素按升序(默认情况)排列。- 如果试图把一个对象添加到 TreeSet 时,则该对象的类必须实现 Comparable 接口。
- 实现 Comparable 的类必须实现 compareTo(Object obj) 方法,两个对象即通过 compareTo(Object obj) 方法的返回值来比较大小。
定制排序:如果元素所属的类没有实现Comparable接口,或不希望按照升序(默认情况)的方式排列元素或希望按照其它属性大小进行排序,则考虑使用定制排序。定制排序,通过Comparator接口来实现。需要重写compare(T o1,T o2)方法。- 利用int compare(T o1,T o2)方法,比较o1和o2的大小:如果方法返回正整数,则表示o1大于o2;如果返回0,表示相等;返回负整数,表示o1小于o2。
- 要实现定制排序,需要将实现Comparator接口的实例作为形参传递给TreeSet的构造器。
说明:底层会判断使用的是哪种,if-else对应调用compara(o1,o2)或者comparaTo(obj)两种不同的方法
TreeSet集合如何判断两个对象是否相等的唯一标准?这与HashSet()比较的方式不一样!这里的类不要求重写equals()\hashCode()方法
两个对象通过 compareTo(Object obj) 或compare(Object o1,Object o2)方法比较返回值。返回值为0,则认为两个对象相等。
TreeSet的使用方式:自然排序、定制排序(new比较器对象,作为TreeSet构造器参数newTreeSet集合)
TreeSet添加元素时,底层调用数据元素对象的比较器方法来比较大小,因此只能添加同一类型的,否则会报错ClassCastException
因此在自定义类中,需要实现Comparable接口,进而必须实现该接口下的public int compareTo(Object o)方法
只要涉及到对象排序都是和这两个接口打交道!!!Arrays.sort(arr,comparator )中都可以将比较器作为参数传入定制排序.new TreeSet(),不加比较器,默认的元素对象中就要有比较器按照自然排序
/*
* 方式1:自然排序:针对User类的对象
* */
@Test
public void test2(){
TreeSet set = new TreeSet();
set.add(new User("Tom",12));
set.add(new User("Rose",23));
set.add(new User("Jerry",2));
set.add(new User("Eric",18));
set.add(new User("Tommy",44));
set.add(new User("Jim",23));
set.add(new User("Maria",18));
//set.add("Tom");
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
System.out.println(set.contains(new User("Jack", 23))); //true
}
/*
* 方式2:定制排序
* */
@Test
public void test3(){
//按照User的姓名的从小到大的顺序排列
Comparator comparator = new Comparator() {
@Override
public int compare(Object o1, Object o2) {
if(o1 instanceof User && o2 instanceof User){
User u1 = (User)o1;
User u2 = (User)o2;
int value = u1.name.compareTo(u2.name);
if(value != 0){
return value;
}
return -(u1.age - u2.age);
}
throw new RuntimeException("输入的类型不匹配");
}
};
TreeSet set = new TreeSet(comparator);
set.add(new User("Tom",12));
set.add(new User("Rose",23));
set.add(new User("Jerry",2));
set.add(new User("Eric",18));
set.add(new User("Tommy",44));
set.add(new User("Jim",23));
set.add(new User("Maria",18));
//set.add(new User("Maria",28));
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
//自定义的实体类
public class User implements Comparable{
String name;
int age;
public User() {}
public User(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "User{" + "name='" + name + '\'' + ", age=" + age + '}';
}
/*
举例:按照age从小到大的顺序排列,如果age相同,则按照name从大到小的顺序排列
* */
public int compareTo(Object o) {//从root节点依次left/right遍历的元素对象.comparaTo(当前元素对象)
if(this == o){//如果即节点对象==当前元素对象
return 0;//表示他们相等
}
if(o instanceof User){//判断是否是同一类型的,同一类型才能比较
User user = (User)o;
int value = this.age - user.age;
if(value != 0){
return value;
}
return -this.name.compareTo(user.name);//按照那么来比较
}
throw new RuntimeException("输入的类型不匹配");
}
}
最后:对比Set、List添加不能重复的数据思路
Set底层使用哈希算法:先计算HashCode值,使用散列函数计算到具体存储位置,判断是否有值,再用HashCode比较,在比较equals()。这个算法在添加add()时,底层源码已经调用实现了。
List底层:从前往后一个一个对比
一些练习题:
- List去重小技巧——转换为Set
- 获取10个1-20的随机数,要求随机数不能重复,并输出到控制台
//题目1
HashSet set = new HashSet(List类型);//会自动转换并去重,底层实现还是一个一个遍历List,然后赋值给set。
List list = new ArrayList(Set类型);//同样的道理
//题目2:对于Set集合下的add()方法底层使用的hash算法。
@Test
public void test1(){
HashSet set = new HashSet();
while(set.size() <= 10){
set.add((int)(Math.random()*20)+1);
}
Iterator it = set.iterator();
while(it.hasNext()){
System.out.print(it.next() + " ");
}
}
//面试题:p1指向的内存地址与set添加的元素指向的地址一样,因为同步改变。当调用set.remove(p1)底层计算的是哈希值,(重写了hashCode()方法)计算属性的哈希值得到的与原来的不一样,因此删不了。
@Test
public void test1(){
HashSet set = new HashSet();
Person p1 = new Person( id: 1001,name: "AA");
Person p2 = new Person( id: 1002, name: "BB");
set.add(p1);
set.add(p2);
System.out.println(set);//[Person{id=1002,name='BB'},Person{id=1001,name='AA'}]
p1.name ="CC";
set.remove(p1);
System.out.println(set);//[Person{id=1002,name='BB'},Person{id=1001,name='CC'}]
//可以添加成功,因为上面的是以”AA“计算出来的哈希值,而现在这个是以"CC"计算出来的哈希值自然不一样
//[Person{id=1002,name='BB'},Person{id=1001,name='CC'},Person{id=1001,name='CC'}]
set.add(new Person( id: 1001, name: "CC"))
//计算出来的哈希值和1001/'CC'(因为它是以'AA'计算出来的)一样,但是会再调用equals()对比发现不一样
set.add(new Person( id: 1001, name: "AA"))
}
三、Map接口及其实现类(HashMap/LinkedHashMap/TreeMap/Hashtable/Properties)
java.util.Map:存储一对一对的数据(key-value键值对)——类似于函数。
- HashMap:主要实现类,线程不安全,效率高,可以添加null的key和value值。底层数组+单向链表+红黑树结构(jdk8)
- LinkedHashMap:HashMap子类,在此基础上增加双向链表用于记录添加的元素先后顺序,进而遍历元素可以按照添加的顺序。
适用于频繁的遍历操作
- LinkedHashMap:HashMap子类,在此基础上增加双向链表用于记录添加的元素先后顺序,进而遍历元素可以按照添加的顺序。
- TreeMap:底层使用红黑树存储,可以按照添加的key-value中的key元素的指定属性的大小顺序进行排序(自然、定制排序)
Hashtable:古老实现类,线程安全,效率低,不可以添加null的key和value值。数组+单向链表(本来就要过时了,也就没改它)- Properties:其key和value都是String类型,常用来处理属性文件,也是线程安全的
HashMap与Hashtable的关系和ArrayList与Vector的关系比较像,源码中线程安全的类中相关的方法都加了synchronized修饰
[面试题]:区别HashMap和Hashtable、区别HashMap和LinkedHashMap、关于HashMap的底层实现(①new HashMap底层做什么;②put(key,value)底层怎么放)
3.1 Map接口中常用的方法&特点
1、Map接口的常用方法:key就像索引
- 增、改也一样
- Object put(Object key,Object value):将指定key-value添加到(或修改)当前map对象中
- void putAll(Map m):将m中的所有key-value对存放到当前map中
- 删
- Object remove(Object key):移除指定key的key-value对,并返回value
- void clear():清空当前map中的所有数据
- 查元素:
- Object get(Object key):获取指定key对应的value
- 长度
- int size():返回map中key-value对的个数
- 遍历:
- 遍历key集:Set keySet():返回所有key构成的Set集合
- 遍历value集:Collection values():返回所有value构成的Collection集合
- 遍历entry集:Set entrySet():返回所有key-value对构成的Set集合
- 判断
- boolean isEmpty():判断当前map是否为空
- boolean containsKey(Object key):是否包含指定的key
- boolean containsValue(Object value):是否包含指定的value
- boolean equals(Object obj):判断当前map和参数对象obj是否相等
对于单独一个节点:mapnode.getKey(),mapnode.getValue()
3.2 Map主要实现类HashMap/LinkedHashMap
1、HashMap特点:线程不安全,允许添加nul键和null值,底层采用一维数组+单向链表+红黑树进行key-value的存储,与HashSet一样不能保证存取元素的顺序一致。
LinkedHashMap特点:HashMap的子类,底层实现:一维数组+单向链表+红黑树,添加了双向链表记录添加元素中的key元素的先后顺序,保证遍历元素与添加的顺序一致。键所在类需要重写equals()和hashCode()方法,为了保证key的不可重复性
2、HashMap元素特点:
- key不可重复、无序→所有单独的key构成一个set集合→key的所在类要重写hashCode()、equals()方法【和HashSet一样会调用key元素对象进行计算比较,比地址没有意义,这里为了比对象内容,让对象属性也参与哈希值的计算】
- value可重复、无序→所有单独的value可以构成一个Collection集合→value的所在类重写equals()方法。value存放的位置是由key决定的!
- 一个key-value构成了一个entry→不可重复,无序→所有的entry构成了一个Set集合【entry也成为Node节点】
3、判断两个key相等的标准:hashCode()值,在比较equals()
判断value相等的标准:equals比较

方法的使用示例:主要关于三种集合的遍历
@Test
public void test1(){
HashMap map = new HashMap();
map.put(11,"21");
map.put(12,"22");
map.put(13,"23");
map.put(14,"24");
Set set = map.keySet();
//遍历键key集合
Iterator keyit = set.iterator();
while(keyit.hasNext()){
System.out.print(keyit.next()+" ");//11 12 13 14
}
//遍历value方式1:获取值value集合并遍历
Collection values = map.values();
for(Object value : values){
System.out.print(value+" ");//21 22 23 24
}
//遍历value方式2:利用key,结合map.get()方法以键取值
Set keyset = map.keySet();
for(Object key : keyset){
System.out.print(map.get(key)+" ");//21 22 23 24
}
//遍历key-value构成的set集合方式1
Iterator entryit1 = entry.iterator();
while(entryit1.hasNext()){
//法1:直接输出
System.out.print(entryit1.next()+" ");//11=21 12=22 13=23 14=24
//法2:获取到节点
Map.Entry mapnode = (Map.Entry)entryit1.next();
System.out.print(mapnode+" ");//11=21 12=22 13=23 14=24
System.out.println(mapnode.getKey()+"---->"+mapnode.getValue());//可以把key,value按照自定义的方式输出
}
//遍历entry集:利用遍历key的方式,再以键取值
//遍历value方式2:利用key,结合map.get()方法以键取值
Set keyset1 = map.keySet();
for(Object key : keyset1){
System.out.print(key+"-----》"+map.get(key)+" ");
}
}
HashMap使用泛型定义:指定里面可以存储的类型,避免出现类型转换异常
@Test
public void test4(){
Map<String,Integer> map = new HashMap<>();//这里也存在一个类型推断
//Map<String,Integer> map = new HashMap<String,Integer>();
map.put("zhangying",123);
map.put("shi",23);
map.put("xiaoshi",321);
//遍历方式1:获取key/value的set集合
var entryset = map.entrySet();//有一个类型推断,避免太复杂了
var it = entryset.iterator();//获取set集合的迭代器
//Set<Map.Entry<String,Integer>> entryset = map.entrySet();
//Iterator<Map.Entry<String,Integer>> it = entryset.iterator();
while(it.hasNext()){
var entry = it.next();//类型推断
//Map.Entry<String,Integer> entry = it.next();
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println(key+"------>"+value);
}
//遍历方式2:获取key的set然后遍历
var keyset = map.keySet();
var values = map.values();
var itkey = keyset.iterator();
//Set<String> keyset = map.keySet();
//Collection<Integer> values = map.values();
//Iterator<String> itkey = keyset.iterator();
while(itkey.hasNext()){
String key = itkey.next();
System.out.println(key+"----->"+map.get(key));
}
}
3.3 Map实现类TreeMap
1、TreeMap特点:底层使用红黑树,可以按照key-value中的key元素指定的属性大小顺序进行遍历(自然排序、定制排序),TreeMap 可以保证所有的 key-value 对处于有序状态。
使用方式和TreeSet一样,这里key元素所在类要实现比较器,并且key元素要是同一个类型的才能比较
2、TreeMap 的 Key 的排序:
自然排序:TreeMap 的所有的 Key 必须实现 Comparable 接口,而且所有的 Key 应该是同一个类的对象,否则将会抛出 ClasssCastException定制排序:创建 TreeMap 时,构造器传入一个 Comparator 对象,该对象负责对 TreeMap 中的所有 key 进行排序。此时不需要 Map 的 Key 实现 Comparable 接口
3、TreeMap判断两个key相等的标准:两个key通过compareTo()方法或者compare()方法返回0。
3.4 Map实现类Hashtable/Properties
1、Hashtable:古老实现类,线程安全,效率低,不可以添加null的key和value值。数组+单向链表(本来就要过时了,也就没改它)
Properties:Hashtable的子类,其key和value都是String类型,常用来处理属性文件,也是线程安全的。key、value都是字符串型
判断key是否相等:hashCode()、equals();判断value是否相等:equals(),与HashMap判断方法一致
2、使用Properties存取数据:setProperty(String key,String value)、getProperty(String key)
比如存储用户名-密码到文件中,修改数据时,与代码无关,代码照常读取即可
优点:将数据封装到具体的配置文件中,在程序中读取配置文件中的信息。实现了数据和代码的解耦;由于我们没有修改代码,就省去了重新编译和打包的过程。
Properties使用
@Test
public void test01() {
Properties properties = System.getProperties();
String fileEncoding = properties.getProperty("file.encoding");//当前源文件字符编码
System.out.println("fileEncoding = " + fileEncoding);
}
@Test
public void test02() {
Properties properties = new Properties();
properties.setProperty("user","songhk");
properties.setProperty("password","123456");
System.out.println(properties);
}
@Test
public void test03() throws IOException {
Properties pros = new Properties();
pros.load(new FileInputStream("jdbc.properties"));
String user = pros.getProperty("user");
System.out.println(user);
}
四、Collections工具类
1、Collections工具类定义:是一个操作 Set、List 和 Map 等集合的工具类。参考操作数组的工具类:Arrays
Collections 中提供了一系列静态的方法对集合元素进行排序、查询和修改等操作,还提供了对集合对象设置不可变、对集合对象实现同步控制等方法(均为static方法)
[面试题]区分Collection与Collections
Collection:集合框架中的用于存储一个一个元素的接口,又分为List和Set等子接口。
Collections:用于操作集合框架的一个工具类。此时的集合框架包括:Set、List、Map
用到比较器的:TreeSet、TreeMap可以自然排序,利用实现comparable接口的元素对象,调用该对象的comparaTo(Object obj)方法进行对比。Collections工具类中sort(List,comparator)方法,需要传入比较器对象,当然也可以使用自然排序sort(List)→之前是TreeMap、TreeSet可以实现排序,现在可以是使用这个方法对List进行排序。还有binarySearch方法
可以定制排序,即构造器传入一个Comparator对象,该对象负责对其中的元素对象进行排序。
Comparable接口中需要重写的方法comparaTo(Object obj);Comparator接口中需要重写的方法compara(Object o1,Object o2)
2、常用的方法
- 增:
- boolean addAll(Collection c,T… elements)将所有指定元素添加到指定 collection 中。
- 复制、替换
- void copy(List dest,List src):将src中的内容复制到dest中
- boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换 List 对象的所有旧值
- 提供了多个unmodifiableXxx()方法,该方法返回指定 Xxx的不可修改的视图。
- 排序操作:
- reverse(List):反转 List 中元素的顺序
- shuffle(List):对 List 集合元素进行随机排序
- sort(List):根据元素的自然顺序对指定 List 集合元素按升序排序
- sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
- swap(List,int, int):将指定 list 集合中的 i 处元素和 j 处元素进行交换
- 查找
- Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素【自然排序后最右边最大取最右边】
- Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素【定制排序后取最右边的,无论min/max】
- Object min(Collection):根据元素的自然顺序,返回给定集合中的最小元素
- Object min(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最小元素【Comparator重写compara(o1,o2)】
- int binarySearch(List list,T key):二分法查找,List得是有序的。
- int binarySearch(List list,T key,Comparator c):二分法查找,List必须要按照c比较器规则进行排序过的。
- int frequency(Collection c,Object o):返回指定集合中指定元素的出现次数
- 同步
- Collections 类中提供了多个 synchronizedXxx() 方法,该方法可使将指定集合包装成线程同步的集合,从而可以解决多线程并发访问集合时的线程安全问题:
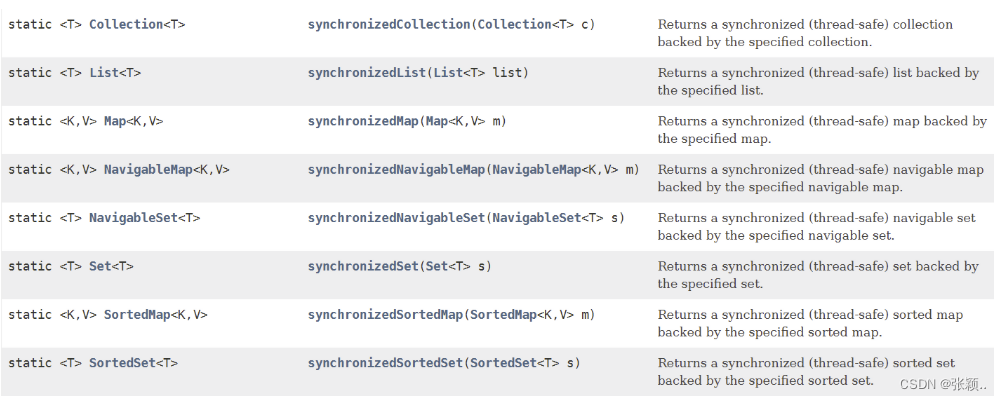
- Collections 类中提供了多个 synchronizedXxx() 方法,该方法可使将指定集合包装成线程同步的集合,从而可以解决多线程并发访问集合时的线程安全问题:
五、企业真题
1、说说List,Set,Map三者的区别(民银行)
- List:可重复,有序
- ArrayList:底层是数组存储的,主要实现类,线程不安全,效率高
- LinkedList:底层是双向链表结构
- Vector:古老实现类,线程安全,效率较低
- Set:不可重复,无序
- HashSet:底层实现数组+单向链表+红黑树
- LinkedHashSet:HashSet的子类,在此基础上添加了双向链表维护添加元素的顺序
- TreeSet:可以实现按元素属性的大小进行排序,结合比较器使用,这就要求添加的元素必须是同一类型的
- HashSet:底层实现数组+单向链表+红黑树
- Map:键值对的形式
- HashMap:主要实现类,存储key-value,判断key相等的标准(hashCode()、equals()),判断value相等的标准equals(),因此需要重写他们,value随着key的位置
- LinkedHashMap:HashMap的子类,在此基础上添加了双向链表维护添加元素的顺序
- Hashtable:古老实现类,底层数组+单向链表,线程安全,底层方法使用synchronized修饰
- Properties:是Hashtable的子类,主要用于读取属性文件,key-value是字符串型
- TreeMap:底层是红黑树,实现按key元素属性的大小实现排序,因此key只能是同一类型的
- HashMap:主要实现类,存储key-value,判断key相等的标准(hashCode()、equals()),判断value相等的标准equals(),因此需要重写他们,value随着key的位置
其中:HashSet底层就是HashMap;LinkedHashSet底层就是LinkedHashMap;TreeSet底层就是TreeMap
2、集合的父类是谁?哪些安全的?(北京中信)
不安全:ArrayList、HashMap、HashSet ; 安全:Vector、Hashtable、Properties
3、遍历集合的方式有哪些?(恒电子)
- 迭代器Iterator用来遍历Collection,不能用来遍历Map!
- 增强for
- 一般的for:可以用来遍历List
4、ArrayList与LinkedList区别?&ArrayList与Vector区别?
ArrayList与LinkedList:底层数据结构的不同
ArrayList与Vector:线程安全/效率的问题
类似:HashMap和Hashbable的区别?HashMap和LinkedHashMap的区别——数据结构方面
线程安全/效率
5、Set里的元素是不能重复的,那么用什么方法来区分重复与否呢? 是用==还是equals()? 它们有何区别?
HashSet、LinkedHashSet底层数组+单向链表+红黑树(+双向链表)每次调用元素对象的hashCode() 、 equals()进行比较
TreeSet:底层红黑树,调用Comparable接口下的comparaTo(Object obj)方法或者Comparator接口下的compara(Object o1,Object o2)
6、TreeSet两种排序方式在使用的时候怎么起作用?(拓软件)
在添加新的元素时,需要调用compareTo() 或 compare()
7、final怎么用,修饰Map可以继续添加数据吗?可以!
final HashMap map = new HashMap();
map.put(“AA”,123);
8、HashMap里面实际装的是什么?
JDK7:HashMap内部声明了Entry,实现了Map中的Entry接口。(key,value作为Entry的两个属性出现)
JDK8:HashMap内部声明了Node,实现了Map中的Entry接口。(key,value作为Node的两个属性出现)
HashMap的key存储在数组+链表+红黑树。 key、value作为Node的属性出现
9、自定义类型可以作为Key么?
可以! 要重写hashCode() 和equals()
10、ArrayList 如何实现排序
Collections.sort(list) 或 Collections.sort(list,comparator)
补充Set中有实现类TreeSet、Map中又TreeMap可以实现排序


![[蓝桥杯2024]-PWN:fd解析(命令符转义,标准输出重定向,利用system(‘$0‘)获取shell权限)](https://img-blog.csdnimg.cn/direct/fe37ee3eed4841558d05d5ad0f674fc9.png)