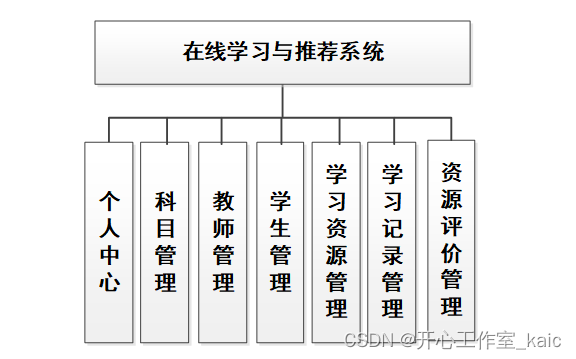
一、self-attention流程
自注意力机制和注意力机制的区别在于,注意力机制中的Q(查询向量),K(键向量),V(值向量)是同源的,而一般的注意力机制,Q和K,V不同源。例如,Transformer结构中,Encoder结构中的Multi-head self-attention模块的Q,K,V是同源的,而Decoder结构中的cross-attention是不同源的,K,V来自Encoder的Multi-head self-attention模块,而Q来自Decoder的Multi-head self-attention模块。
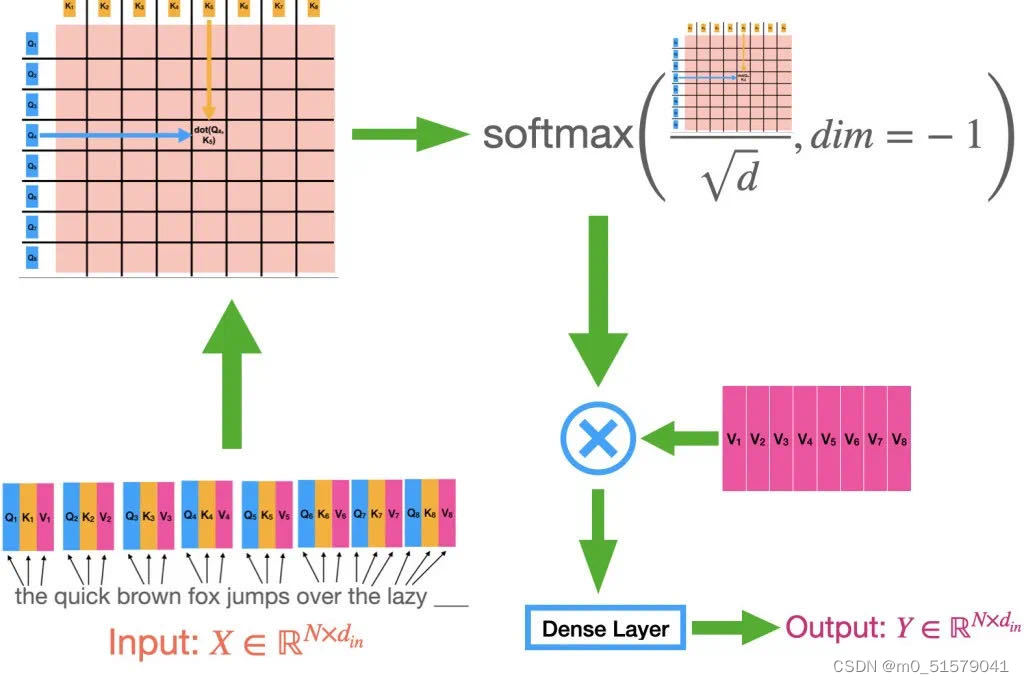
计算流程:
(1)Q叉乘K的转置,再除以转置
(2)对(1)的结果取sofxmax,得到注意力值
(3)将(2)的注意力再和V叉乘,得到输出
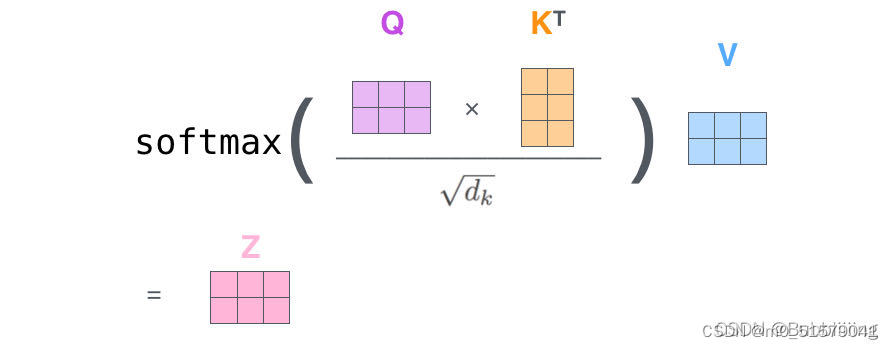
二、self-attention简单例子实现
(1)Q叉乘K的转置,再除以转置
scores = Query @ Key.T
(2)对(1)的结果取sofxmax,得到注意力值
def soft_max(z):
t = np.exp(z)
a = np.exp(z) / np.expand_dims(np.sum(t, axis=1), 1)
return a
scores = soft_max(scores)
(3)将(2)的注意力再和V叉乘,得到输出
out = scores @ Value
三、完整代码
import numpy as np
def soft_max(z):
t = np.exp(z)
a = np.exp(z) / np.expand_dims(np.sum(t, axis=1), 1)
return a
Query = np.array([
[1,0,2],
[2,2,2],
[2,1,3]
])
Key = np.array([
[0,1,1],
[4,4,0],
[2,3,1]
])
Value = np.array([
[1,2,3],
[2,8,0],
[2,6,3]
])
scores = Query @ Key.T
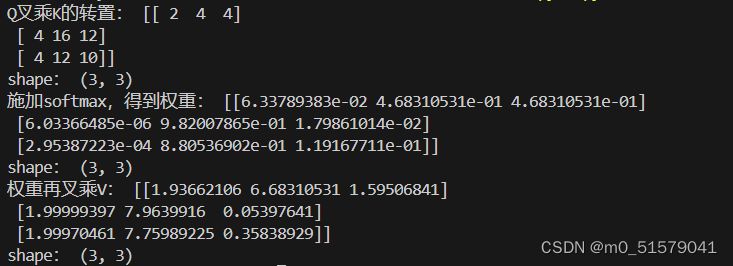
print("Q叉乘K的转置:",scores)
print("shape:",scores.shape)
scores = soft_max(scores)
print("施加softmax,得到权重:",scores)
print("shape:",scores.shape)
out = scores @ Value
print("权重再叉乘V:",out)
print("shape:",out.shape)