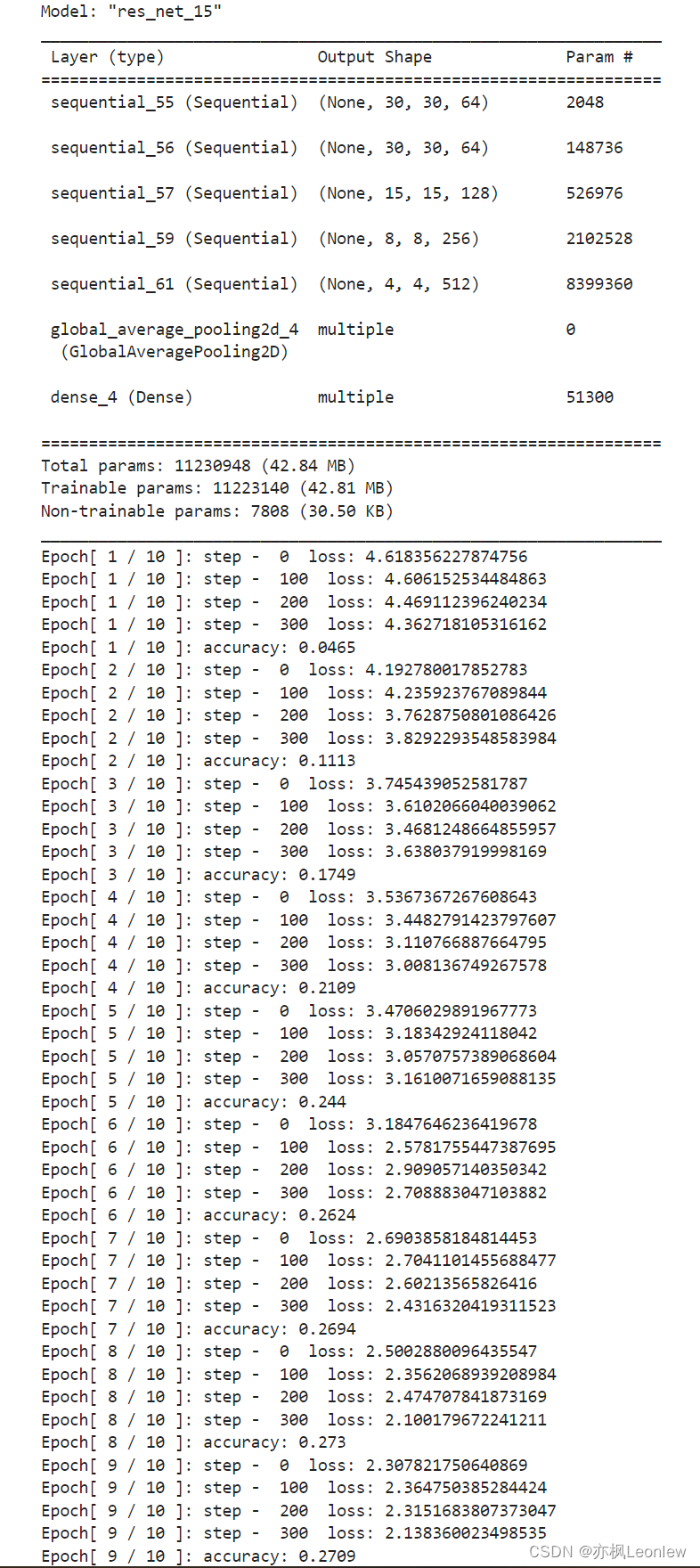
本笔记记录使用ResNet18网络结构,进行CIFAR100数据集的训练和验证。由于参数较多,训练时间会比较长,因此只跑了10个epoch,准确率还没有提升上去。
import os
import time
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics, Input
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
#tf.random.set_seed(12345)
tf.__version__
#关于ResNet的描述,可以参考如下链接:
#https://blog.csdn.net/qq_39770163/article/details/126169080
#代码基于ResNet18结构,有少许不一样
class BasicBlock(layers.Layer):
def __init__(self, filter_num, strides = 1):
super(BasicBlock, self).__init__()
#卷积层1
self.conv1 = layers.Conv2D(filter_num, (3,3), strides = strides, padding='same')
#BN层
self.bn1 = layers.BatchNormalization()
#Relu层
self.relu = layers.Activation('relu')
#卷积层2,BN层2,
self.conv2 = layers.Conv2D(filter_num, (3,3), strides = 1, padding='same')
self.bn2 = layers.BatchNormalization()
#Shortcut
if strides != 1:
#如果strides不为1,需要下采样
self.downsample = Sequential()
self.downsample.add(layers.Conv2D(filter_num, (1,1), strides=strides))
else:
#strides为1, 直接返回原始值即可
self.downsample = lambda x:x
def call(self, inputs, training = None):
#经过第一个卷积层,BN和Relu
out = self.conv1(inputs)
out = self.bn1(out)
out = self.relu(out)
#经过第二个卷积层
out = self.conv2(out)
out = self.bn2(out)
#Shortt处理,out和输入相加
identity = self.downsample(inputs)
output = layers.add([out, identity])
#再经过一个relu
output = tf.nn.relu(output)
return output
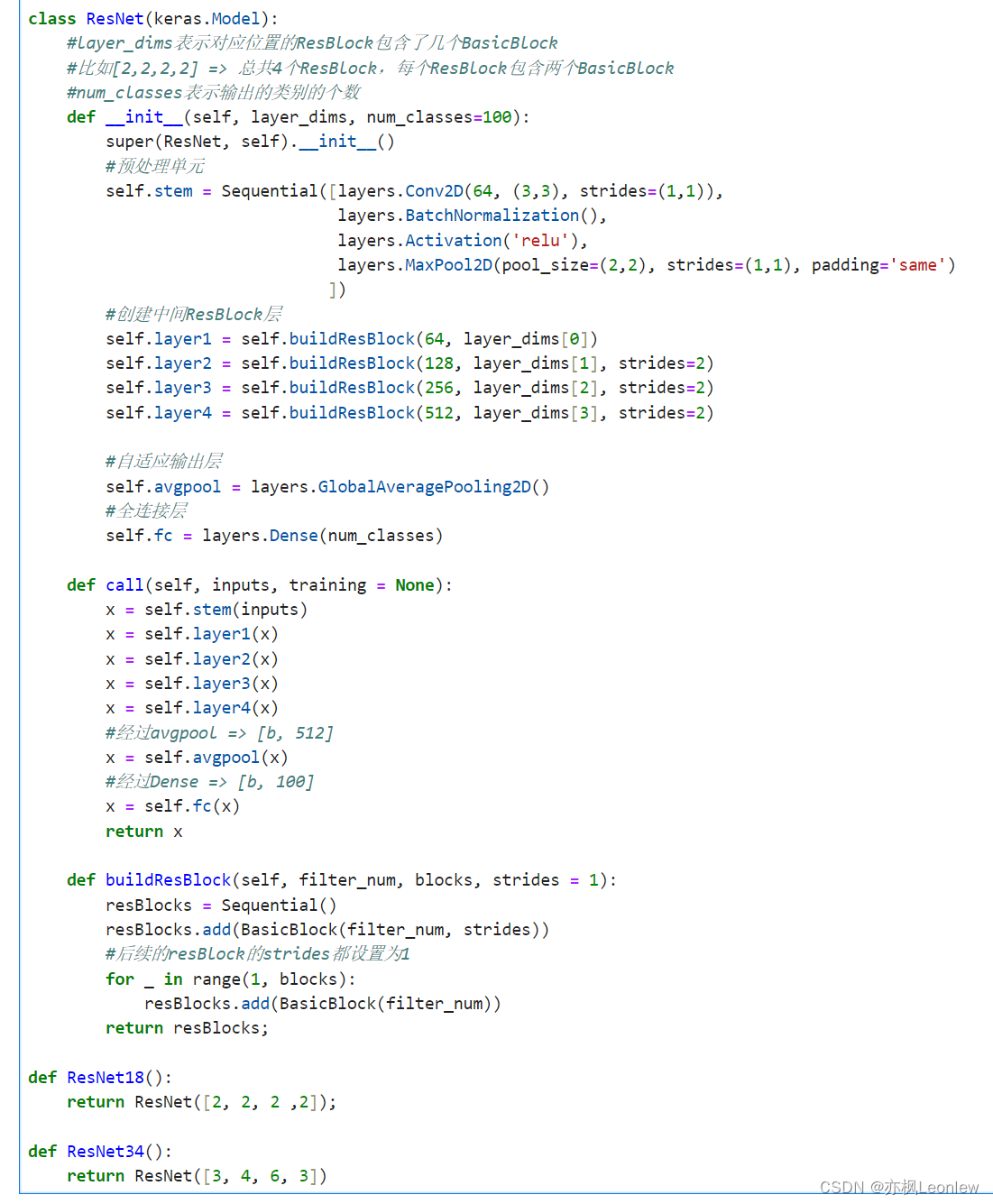
class ResNet(keras.Model):
#layer_dims表示对应位置的ResBlock包含了几个BasicBlock
#比如[2,2,2,2] => 总共4个ResBlock,每个ResBlock包含两个BasicBlock
#num_classes表示输出的类别的个数
def __init__(self, layer_dims, num_classes=100):
super(ResNet, self).__init__()
#预处理单元
self.stem = Sequential([layers.Conv2D(64, (3,3), strides=(1,1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(pool_size=(2,2), strides=(1,1), padding='same')
])
#创建中间ResBlock层
self.layer1 = self.buildResBlock(64, layer_dims[0])
self.layer2 = self.buildResBlock(128, layer_dims[1], strides=2)
self.layer3 = self.buildResBlock(256, layer_dims[2], strides=2)
self.layer4 = self.buildResBlock(512, layer_dims[3], strides=2)
#自适应输出层
self.avgpool = layers.GlobalAveragePooling2D()
#全连接层
self.fc = layers.Dense(num_classes)
def call(self, inputs, training = None):
x = self.stem(inputs)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
#经过avgpool => [b, 512]
x = self.avgpool(x)
#经过Dense => [b, 100]
x = self.fc(x)
return x
def buildResBlock(self, filter_num, blocks, strides = 1):
resBlocks = Sequential()
resBlocks.add(BasicBlock(filter_num, strides))
#后续的resBlock的strides都设置为1
for _ in range(1, blocks):
resBlocks.add(BasicBlock(filter_num))
return resBlocks;
def ResNet18():
return ResNet([2, 2, 2 ,2]);
def ResNet34():
return ResNet([3, 4, 6, 3])
#加载CIFAR100数据集
#如果下载很慢,可以使用迅雷下载到本地,迅雷的链接也可以直接用官网URL:
# https://www.cs.toronto.edu/~kriz/cifar-100-python.tar.gz
#下载好后,将cifar-100.python.tar.gz放到 .keras\datasets 目录下(我的环境是C:\Users\Administrator\.keras\datasets)
# 参考:https://blog.csdn.net/zy_like_study/article/details/104219259
(x_train,y_train), (x_test, y_test) = datasets.cifar100.load_data()
print("Train data shape:", x_train.shape)
print("Train label shape:", y_train.shape)
print("Test data shape:", x_test.shape)
print("Test label shape:", y_test.shape)
def preprocess(x, y):
x = tf.cast(x, dtype=tf.float32) / 255.
y = tf.cast(y, dtype=tf.int32)
return x,y
y_train = tf.squeeze(y_train, axis=1)
y_test = tf.squeeze(y_test, axis=1)
batch_size = 128
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_db = train_db.shuffle(1000).map(preprocess).batch(batch_size)
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_db = test_db.map(preprocess).batch(batch_size)
sample = next(iter(train_db))
print("Train data sample:", sample[0].shape, sample[1].shape,
tf.reduce_min(sample[0]), tf.reduce_max(sample[0]))
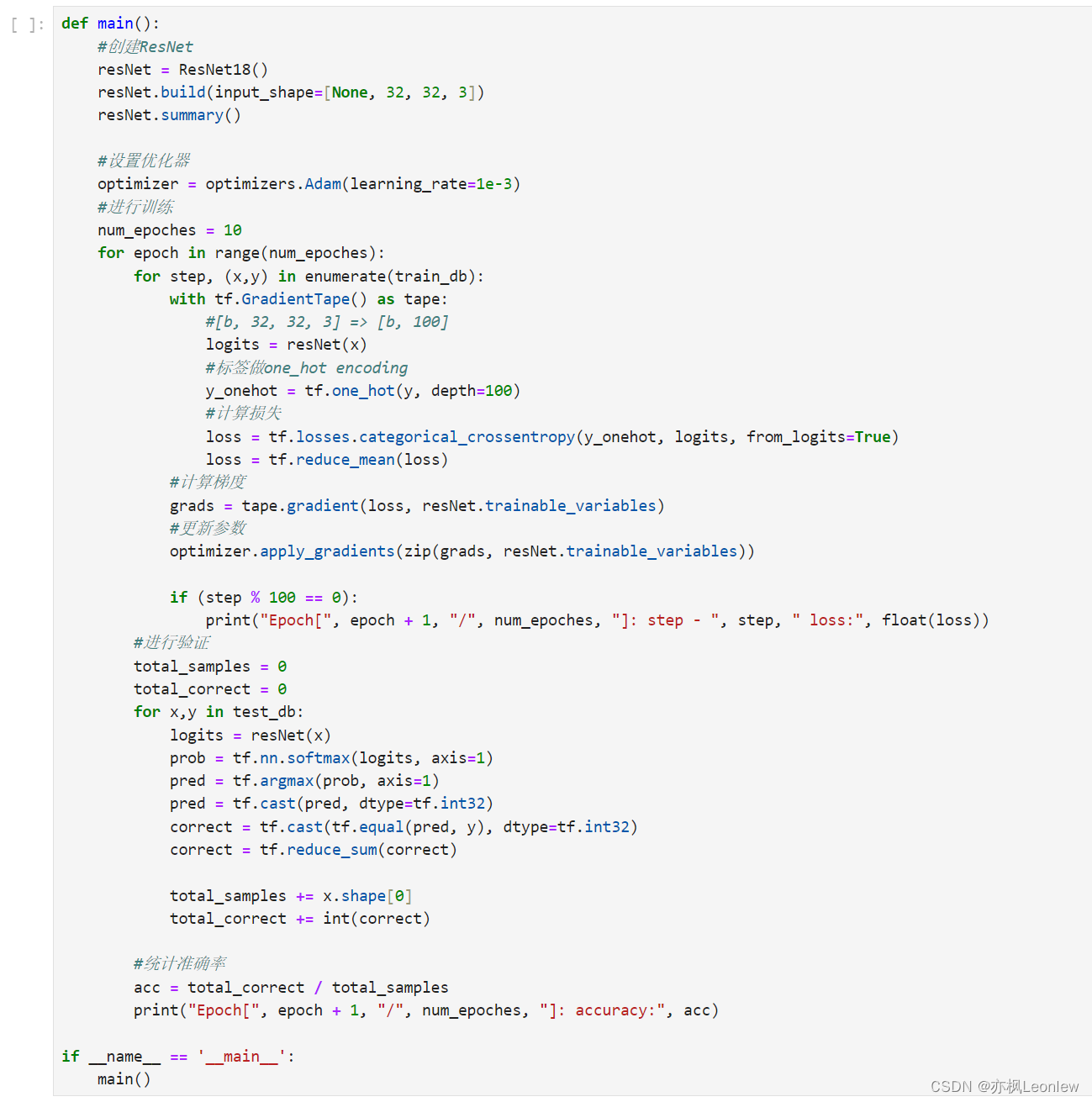
def main():
#创建ResNet
resNet = ResNet18()
resNet.build(input_shape=[None, 32, 32, 3])
resNet.summary()
#设置优化器
optimizer = optimizers.Adam(learning_rate=1e-3)
#进行训练
num_epoches = 10
for epoch in range(num_epoches):
for step, (x,y) in enumerate(train_db):
with tf.GradientTape() as tape:
#[b, 32, 32, 3] => [b, 100]
logits = resNet(x)
#标签做one_hot encoding
y_onehot = tf.one_hot(y, depth=100)
#计算损失
loss = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=True)
loss = tf.reduce_mean(loss)
#计算梯度
grads = tape.gradient(loss, resNet.trainable_variables)
#更新参数
optimizer.apply_gradients(zip(grads, resNet.trainable_variables))
if (step % 100 == 0):
print("Epoch[", epoch + 1, "/", num_epoches, "]: step - ", step, " loss:", float(loss))
#进行验证
total_samples = 0
total_correct = 0
for x,y in test_db:
logits = resNet(x)
prob = tf.nn.softmax(logits, axis=1)
pred = tf.argmax(prob, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
correct = tf.cast(tf.equal(pred, y), dtype=tf.int32)
correct = tf.reduce_sum(correct)
total_samples += x.shape[0]
total_correct += int(correct)
#统计准确率
acc = total_correct / total_samples
print("Epoch[", epoch + 1, "/", num_epoches, "]: accuracy:", acc)
if __name__ == '__main__':
main()运行结果: