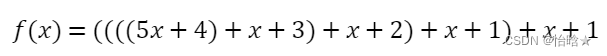基于扩散模型的文本到音频生成:突破数据局限,优化音频概念与时间顺序
- 一、现有模型的局限与挑战
- 二、偏好数据集的构建与利用
- 三、Diffusion-DPO损失的应用与模型微调
- 四、实例与代码展示
- 五、总结与展望
随着数字化技术的迅猛发展,音乐和电影行业对音频生成技术的需求日益旺盛。其中,从文本提示生成音频的技术正成为研究的热点。然而,现有的基于扩散模型的文本到音频生成方法,往往受限于数据集的大小和复杂性,难以准确捕捉并反映输入提示中的概念与事件的时间顺序。近日,一篇新的论文提出了一种在数据有限的情况下提升音频生成性能的方法,引发了业界的广泛关注。
一、现有模型的局限与挑战
当前,许多基于扩散模型的文本到音频方法主要依赖于大量的提示音频对进行训练。虽然这些模型在音频生成方面取得了一定的进展,但它们并没有显式地关注输出音频与输入提示之间的概念匹配和事件顺序。这导致了生成的音频中可能出现概念缺失、顺序混乱等问题,无法满足高质量音频生成的需求。
二、偏好数据集的构建与利用
为了克服上述局限,研究团队提出了一种新的方法。他们首先利用现有的文本到音频模型Tango,合成创建了一个偏好数据集。在这个数据集中,每个文本提示都对应着一组音频输出,其中包括一个与提示高度匹配的“好”音频输出和若干个与提示不匹配或匹配度较低的“不合适”音频输出。这些不合适的音频输出中,往往包含了概念缺失或顺序错误的问题,为模型提供了宝贵的学习机会。
三、Diffusion-DPO损失的应用与模型微调
接下来,研究团队利用扩散-DPO(直接偏好优化)损失对公开的Tango文本到音频模型进行微调。他们通过在偏好数据集上进行训练,使模型能够学会区分好的音频输出和不合适的音频输出,从而优化其音频生成性能。通过不断调整模型的参数和结构,研究团队成功地提升了模型在自动和手动评估指标上的表现,使其相比原始的Tango和AudioLDM2模型有了显著的改善。
四、实例与代码展示
为了更直观地展示这种方法的优势,我们通过一个具体的实例来进行说明。假设我们有一个文本提示:“夜晚的森林,风吹过树叶的声音”。基于这个提示,我们希望生成的音频能够准确地反映出夜晚森林的氛围,包括树叶的沙沙声和风的声音。
首先,我们利用Tango模型生成一组初始的音频输出。然后,我们根据音频的质量与文本提示的匹配度,从中挑选出一个好的音频输出和若干个不合适的音频输出。这些不合适的音频输出可能包含了噪音、声音不连贯或概念不符等问题。
接下来,我们利用Diffusion-DPO损失对这些音频输出进行训练。通过不断调整模型的参数和结构,我们使模型能够逐渐学会区分好的音频输出和不合适的音频输出。在训练过程中,我们不断监控模型的性能,并根据评估指标进行调整和优化。
最终,经过多次迭代和微调,我们得到了一个优化后的模型。这个模型能够更准确地捕捉文本提示中的概念和时间顺序,生成出更加符合要求的音频输出。
五、总结与展望
这篇论文提出的基于扩散模型的文本到音频生成方法,为音乐和电影行业带来了全新的可能性。通过构建偏好数据集并利用Diffusion-DPO损失进行模型微调,该方法在数据有限的情况下实现了音频生成性能的显著提升。未来,随着技术的不断进步和应用的不断拓展,我们有理由相信,文本到音频生成技术将在更多领域发挥重要作用,为人们带来更加丰富的听觉体验。
值得注意的是,虽然这种方法在音频生成方面取得了显著进展,但仍存在一些挑战和待解决的问题。例如,如何进一步提高模型的生成速度和效率、如何更好地处理复杂场景下的音频生成等。这些问题将是未来研究的重要方向。