目录
- 一、实验目的与要求
- 二、实验任务
- 三、主要程序清单和运行结果
- (一)对chipotle.csv文件的销售数据进行分析
- (二)对描述泰坦尼克号成员的信息进行可视化和相关分析
- 四、实验体会
一、实验目的与要求
1、目的:
掌握数据预处理和分析的常用库Pandas的基本用法,学生能应用Pandas库实现对数据的有效查询、统计分析,以及进行必要的数据预处理;能使用Matplotlib库进行数据可视化,从而为进一步的机器学习应用做好必要的准备。
2、要求:
(1)应用Pandas库对于给定的销售数据集进行必要的数据预处理和统计分析;(2)应用Matplotlib库对描述泰坦尼克号成员的信息进行必要的可视化展示。
二、实验任务
使用Pandas和Matplotlib库分别完成以下要求:
- 把包含销售数据的chipotle.csv文件内容读取到一个名为chipo的数据框中,并显示该文件的前10行记录
- 获取chipo数据框中每列的数据类型
- 获取数据框chipo中所有订单购买商品的总数量
- 给出数据框chipo中包含的订单数量
- 查询出购买同一种商品数量超过3个的所有订单
- 查询出同时购买‘Chicken Bowl’和’Chicken Soft Tacos’商品的所有订单
- 找出购买商品数量最多的5个订单
- 找出choice_description字段缺失的商品名称及其订单编号
- 将item_price列的数据转换为浮点数类型
- 找出销售额最多的前5个订单
- 找出单价最高的商品
- 找出平均单价最高的商品打开描述泰坦尼克号成员的信息train.csv文件,把其内容读入到一个
- 名为titanic的数据框中,并绘制一个展示幸存者 (Survived字段值为1) 中男女乘客比例的扇形图
- 通过直方图统计幸存者中各年龄段中的人数
- 统计不同等级舱位 (通过Pclass字段值表示舱位等级) 的存活率并通过柱形图加以展示
- 以数据透视表形式展示不同等级舱位、不同性别的遇难者/幸存者人数
本实验所需的数据集chipotle.csv和train.csv下载地址:
链接:https://pan.quark.cn/s/7098e8f8eb59
提取码:ffdR

三、主要程序清单和运行结果
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
(一)对chipotle.csv文件的销售数据进行分析
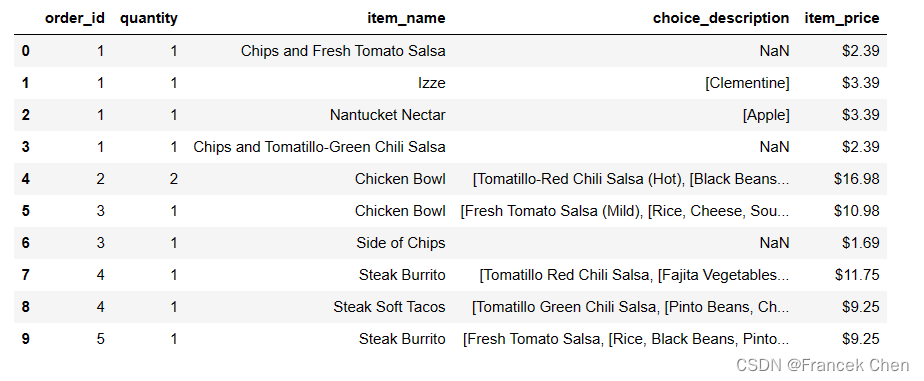
1、把包含销售数据的chipotle.csv文件内容读取到一个名为chipo的数据框中,并显示该文件的前10行记录
chipo = pd.read_csv("chipotle.csv")
chipo.head(10)
2、获取chipo数据框中每列的数据类型
chipo.dtypes

3、获取数据框chipo中所有订单购买商品的总数量
chipo['quantity'].sum()
4972
4、给出数据框chipo中包含的订单数量
chipo['order_id'].unique().size
# chipo['order_id'].nunique()
1834
5、查询出购买同一种商品数量超过3个的所有订单
chipo.loc[chipo['quantity']>3,'order_id':'item_name']
# chipo[chipo['quantity'] > 3][['order_id', 'quantity', 'item_name']]

6、查询出同时购买’Chicken Bowl’和’Chicken Soft Tacos’商品的所有订单
df1 = chipo.loc[chipo['item_name']=='Chicken Bowl',["order_id","item_name"]]
df2 = chipo.loc[chipo['item_name']=='Chicken Soft Tacos',["order_id","item_name"]]
df3 = df1.merge(df2,on="order_id")
df3.drop_duplicates()
首先从chipo数据框中分别选取了 “Chicken Bowl” 和 “Chicken Soft Tacos” 两种商品的订单号和商品名称,然后使用merge()方法将这两个数据框按订单号进行合并,最后使用drop_duplicates()方法去除重复的行。

7、找出购买商品数量最多的5个订单
chipo.groupby("order_id").sum().sort_values("quantity",ascending=False).head()
或者
top_orders = chipo.groupby('order_id')['quantity'].sum()
top_5_quantity = top_orders.nlargest(5)
top_5_quantity_df = top_5_quantity.reset_index()
top_5_quantity_df.set_index('order_id',inplace=True)
top_5_quantity_df
首先通过groupby()方法按订单号 (‘order_id’) 分组,并计算每个订单的商品数量总和。然后,使用nlargest(5)方法选取数量前五的订单,得到了一个包含订单号和对应数量总和的 Series。接着,使用reset_index()方法将 Series 转换为数据框,并将 ‘order_id’ 列设置为索引。最后,得到的数据框 top_5_quantity_df 包含了数量前五的订单及其对应的数量总和。

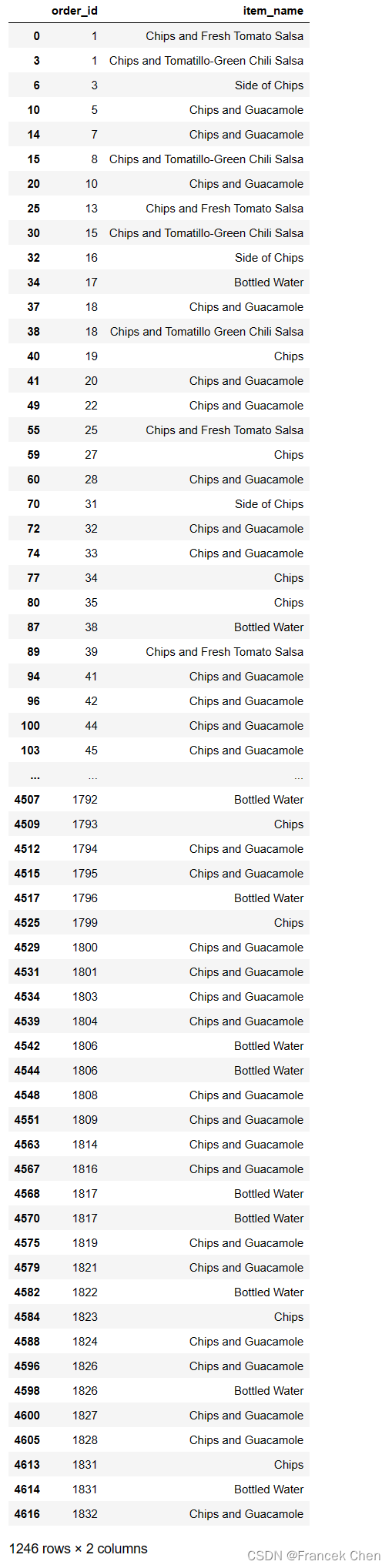
8、找出choice_description字段缺失的商品名称及其订单编号
chipo.loc[chipo['choice_description'].isnull(),["order_id",'item_name']]
# chipo[chipo['choice_description'].isnull()][['order_id','item_name']]
9、将item_price列的数据转换为浮点数类型
#dollarizer = lambda x: float(x[1:])
#chipo['item_price'] = chipo['item_price'].apply(dollarizer)
chipo['item_price'] = chipo['item_price'].str[1:]
chipo['item_price']=chipo['item_price'].astype(float)
chipo.dtypes
chipo.head()
或者
chipo['item_price'] = chipo['item_price'].apply(lambda x: float(x[1:]))
chipo.head()
在处理过程中,使用了一个lambda函数,将每个元素(表示商品价格的字符串)的第一个字符(即美元符号 “$”)去掉,然后将剩余部分转换为浮点数类型,以去除价格字符串中的美元符号并将其转换为浮点数。
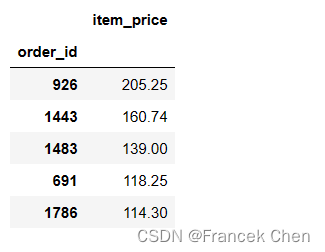
10、找出销售额最多的前5个订单
# 计算单价(item_price)最多的前5个订单
chipo.groupby("order_id").agg({"item_price":"sum"}).sort_values("item_price",ascending=False).head()
或者
# 计算单价(item_price)最多的前5个订单
top_orders = chipo.groupby('order_id')['item_price'].sum()
top_5_price = top_orders.nlargest(5)
top_5_price_df = top_5_price.reset_index()
top_5_price_df.set_index('order_id',inplace=True)
top_5_price_df
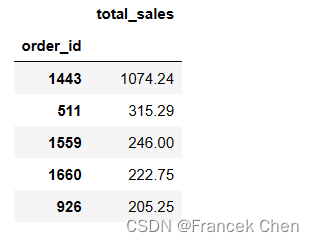
# 计算总销售额最多的前5个订单
chipo['total_sales'] = chipo['quantity'] * chipo['item_price']
top_5_price = chipo.groupby('order_id')['total_sales'].sum().nlargest(5)
top_5_price_df = top_5_price.reset_index()
top_5_price_df.set_index('order_id', inplace=True)
top_5_price_df
11、找出单价最高的商品
# chipo.loc[chipo['item_price'].argmax(),:]
chipo.sort_values(by='item_price', ascending=False).iloc[0]
使用sort_values()方法对数据框进行排序,按照 ‘item_price’ 列的值进行降序排列(ascending=False)。然后使用iloc[0]选择排序后的第一行,即价格最高的商品对应的行数据。

12、找出平均单价最高的商品
average_prices = chipo.groupby('item_name')['item_price'].mean()
print(average_prices.nlargest(1))
# chipo.groupby("item_name")["item_price"].mean().sort_values(ascending=False).head(1)

(二)对描述泰坦尼克号成员的信息进行可视化和相关分析
13、打开描述泰坦尼克号成员的信息train.csv文件,把其内容读入到一个名为titanic的数据框中,并绘制一个展示幸存者 (Survived字段值为1) 中男女乘客比例的扇形图
titanic = pd.read_csv("train.csv") # 加载泰坦尼克号乘客数据集
plt.rcParams['font.sans-serif']=['SimHei'] # 设置中文显示字体
df4 = titanic[titanic['Survived'] == 1]['Sex'].value_counts() # 数据处理:统计幸存者中男性和女性的数量
plt.pie(df4, explode=(0,0.1), labels=['女性','男性'], colors=['r','g'], autopct='%1.1f%%', startangle=205) # 绘制饼图
plt.title("泰坦尼克号幸存者性别比例统计") # 添加图表标题
plt.axis("equal") # 设置坐标轴比例为相等,使饼图呈现为圆形
plt.show() # 显示图表
使用 Matplotlib 的plt.pie()函数绘制饼图,传入幸存者男性和女性数量的数据df4,并设置了一些参数:
explode=(0,0.1):将饼图中的男性部分稍微突出显示。labels=['女性','男性']:设置饼图各部分的标签。colors=['r','g']:设置饼图各部分的颜色。autopct='%1.1f%%':设置饼图中显示百分比,并保留一位小数。startangle=205:设置饼图起始绘制的角度。plt.axis("equal"):设置坐标轴比例为相等,使饼图呈现为圆形。

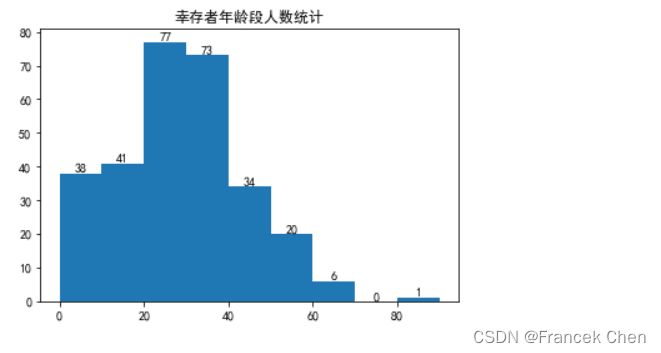
14、通过直方图统计幸存者中各年龄段中的人数
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文显示字体
plt.title("幸存者年龄段人数统计") # 添加图表标题
df5 = titanic.loc[titanic["Survived"] == 1, 'Age'] # 从泰坦尼克号数据集中选择幸存者的年龄数据
n, bins, patches = plt.hist(df5, bins=9, range=(0, 90)) # 绘制直方图
# 在每个柱子上添加文字标签
for i in range(len(n)):
mid_point = bins[i]+(bins[i+1]-bins[i])/2
plt.text(mid_point, n[i], str(int(n[i])), ha='center', va='bottom')
plt.show() # 显示图表
使用plt.hist()函数绘制直方图,其中:
df5是待绘制的数据,即幸存者的年龄数据。bins=9指定了直方图的柱子数量为 9 个。range=(0, 90)指定了绘制的年龄范围为 0 到 90 岁。
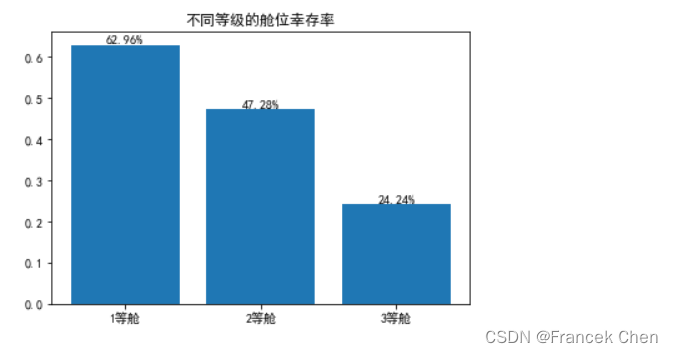
15、统计不同等级舱位 (通过Pclass字段值表示舱位等级) 的存活率并通过柱形图加以展示
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文显示字体
plt.title("不同等级的舱位幸存率") # 添加图表标题
df6 = titanic.groupby('Pclass')['Survived'].mean() # 计算不同舱位的幸存率
# 定义舱位的标签和位置
labels = ['1等舱', '2等舱', '3等舱']
position = np.arange(3)
plt.xticks(rotation=0) # 设置 x 轴刻度的旋转角度为水平
plt.bar(left=position, height=df6, width=0.8, tick_label=labels) # 绘制柱状图
# 在每个柱子上添加文字标签(幸存率百分比)
for i, rate in enumerate(df6):
plt.text(i, rate, f'{rate*100:.2f}%', ha='center', va='bottom')
plt.show() # 显示图表
使用plt.bar()函数绘制柱状图,其中:
left=position指定了柱子的位置。height=df6指定了柱子的高度,即幸存率。width=0.8指定了柱子的宽度。tick_label=labels指定了 x 轴刻度的标签。
16、以数据透视表形式展示不同等级舱位、不同性别的遇难者/幸存者人数
titanic.pivot_table(index='Survived',columns=['Pclass','Sex'],aggfunc='count',values="PassengerId")

四、实验体会
在本次实验中,我学习了如何使用Pandas和Matplotlib库进行数据预处理和可视化分析。通过完成各种任务,我掌握了使用Pandas读取CSV文件并将数据加载到DataFrame中,如何查看DataFrame中每列的数据类型以及如何获取数据的基本统计信息。学会了如何对数据进行筛选、查询和统计分析,例如计算订单数量、查询特定条件下的订单等。了解了如何处理缺失值,并将数据类型转换为适合分析的格式。
使用Matplotlib库绘制了各种类型的图表,包括扇形图、直方图和柱形图,用于更直观地展示数据分布和关系。通过数据透视表的形式对数据进行了多维度的汇总和分析,帮助我更深入地理解数据之间的关联性。
通过这次实验,我不仅掌握数据预处理和分析的常用库Pandas的基本用法,能应用Pandas库实现对数据的有效查询、统计分析,以及进行必要的数据预处理;能使用Matplotlib库进行数据可视化,从而为进一步的机器学习应用做好必要的准备。