一、题目描述
给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。
示例 1:

输入:head = [1,2,3,3,4,4,5] 输出:[1,2,5]
示例 2:
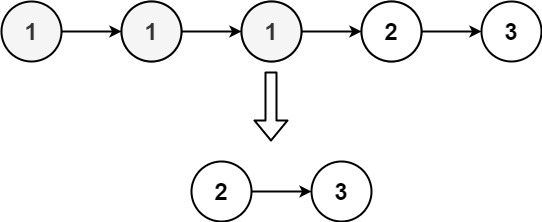
输入:head = [1,1,1,2,3] 输出:[2,3]
提示:
- 链表中节点数目在范围
[0, 300]内 -100 <= Node.val <= 100- 题目数据保证链表已经按升序 排列
二、解题思路
- 创建一个哑结点作为新链表的头部,这样我们就不需要单独处理头结点可能被删除的情况。
- 使用两个指针,
prev指针初始化指向哑结点,curr指针初始化指向链表的头结点。 - 遍历链表,如果
curr指针和curr.next指针的值相同,那么就继续移动curr指针,直到遇到一个不同的值或者到达链表末尾。 - 检查
prev指针的next指针是否等于curr指针,如果不等,说明prev和curr之间有重复元素,将prev的next指针指向curr的next指针,这样就跳过了所有重复元素。 - 如果
prev的next指针等于curr指针,说明没有重复元素,移动prev指针到curr指针的位置。 - 重复步骤3-5,直到
curr指针为空。 - 返回哑结点的
next指针,这就是删除重复元素后的链表。
三、具体代码
class Solution {
public ListNode deleteDuplicates(ListNode head) {
if (head == null) return null;
ListNode dummy = new ListNode(0); // 创建哑结点
ListNode prev = dummy;
dummy.next = head;
ListNode curr = head;
while (curr != null) {
// 跳过重复元素
while (curr.next != null && curr.val == curr.next.val) {
curr = curr.next;
}
// 如果prev的next指针和curr不相等,说明有重复元素,跳过这些元素
if (prev.next != curr) {
prev.next = curr.next;
} else {
// 如果没有重复元素,移动prev指针
prev = prev.next;
}
curr = curr.next;
}
return dummy.next;
}
}
四、时间复杂度和空间复杂度
1. 时间复杂度
- 我们遍历了整个链表一次,其中 n 是链表的长度。
- 在最坏的情况下,每个元素都需要被比较一次,因此时间复杂度是 O(n)。
2. 空间复杂度
- 我们只使用了几个额外的指针(
dummy,prev,curr),它们使用的空间是常数级别的。 - 我们没有使用任何与链表长度成比例的额外空间,因此空间复杂度是 O(1)。
五、总结知识点
-
链表操作:链表是线性数据结构,由一系列节点组成,每个节点包含数据和指向下一个节点的引用。代码中涉及了链表的遍历、节点的删除和链表头的调整。
-
哑结点(Dummy Node):哑结点是一个附加的节点,通常位于链表的头部,它的值不包含在实际数据中。使用哑结点可以简化链表操作,尤其是在处理链表头部节点的删除时。
-
指针的概念:在Java中,我们使用引用来模拟指针的概念。
prev和curr是两个指针,分别用于跟踪当前遍历的位置和前一个不重复元素的位置。 -
循环结构:代码中使用了
while循环来遍历链表。循环结构是控制流的一种,它重复执行一段代码,直到满足某个条件为止。 -
条件语句:代码中使用了
if-else条件语句来判断是否有重复元素,并根据条件执行不同的代码块。 -
链表节点的删除:当发现重复元素时,通过调整指针来跳过这些元素,实现删除操作。这是通过将
prev.next指向curr.next来完成的。 -
链表的有序性:题目指出链表已经按升序排列,这是解决问题的关键,因为重复的元素在链表中是连续的,这使得我们可以通过比较相邻元素的值来检测重复。
-
边界条件的处理:代码中首先检查了链表是否为空,这是一种常见的边界条件处理,确保了代码的鲁棒性。
以上就是解决这个问题的详细步骤,希望能够为各位提供启发和帮助。