文章目录
- 2.Linux 文件管理命令
- 2.44 awk:模式匹配语言
- 1.变量
- 2.运算符
- 3.awk 的正则
- 4.字符串函数
- 5.数学函数
- 案例练习
- 2.45 wc:输出文件中的行数、单词数、字节数
- 案例练习
- 2.46 comm:比较排序文件
- 案例练习
- 2.47 join:将两个文件中指定栏位内容相同的行连接起来
- 2.48 fmt:编排文本文件
2.Linux 文件管理命令
2.44 awk:模式匹配语言
-
作用:利用一组用户提供的命令来将一组文件和用户提供的扩展正则表达式进行比较,一 次一行,然后在任何与扩展正则表达式匹配的行上执行操作。
-
用法:
awk [options] 'script' var=value file(s)
awk [options] -f scriptfile var=value file(s)
主要选项如下:
| 命令 | 描述 |
|---|---|
-F fs or --field-separator fs | 指定输入文件的分隔符,fs 是一个字符串或是一个正则表达式,如-F:。 |
-v var=value or --asign var=value | 赋值一个用户定义变量。 |
-f scripfile or --file scriptfile | 从脚本文件中读取 awk 命令。 |
-mf nnn and -mr nnn | 对 nnn 值设置内在限制,-mf 选项限制分配给 nnn 的最大块数目;-mr 选项限制记录的最大数目。这两个功能是 Bell 实验室版 awk 的扩展功能,在标准 awk中不适用。 |
-W compact or --compat, -W traditional or –traditional | 在兼容模式下运行 awk。所以 gawk的行为和标准的 awk 完全一样,所有的 awk 扩展都被忽略。 |
-W copyleft or --copyleft, -W copyright or –copyright | 打印简短的版权信息。 |
-W help or --help, -W usage or –usage | 打印全部 awk 选项和每个选项的简短说明。 |
-W lint or –lint | 打印不能向传统 UNIX 平台移植的结构的警告。 |
-W lint-old or --lint-old | 打印关于不能向传统 UNIX 平台移植的结构的警告。 |
-W posix | 打开兼容模式。但有以下限制,不识别\x、函数关键字、func、换码序列;当 fs 是一个空格时,将新行作为一个域分隔符;操作符和=不能代替和=;fflush无效。 |
-W re-interval or --re-inerval | 允许间隔正则表达式的使用,参考 grep 中的 POSIX 字符类,如括号表达式[[:alpha:]]。 |
-W source program-text or --source program-text | 使用 program-text 作为源代码,可与-f命令混用。 |
awk 脚本是由模式和操作组成的,即 pattern {action},如$ awk ‘/root/’ test,$ awk ‘$3 < 100’ test。二者是可选的,如果没有模式,则 action 应用到全部记录;如果没有 action,则输出匹配 全部记录。在默认情况下,每一个输入行都是一条记录,但用户可通过 RS 变量指定不同的分 隔符进行分隔。
说明 awk 命令的模式搜索比 grep 命令的搜索更常用,且它允许用户在输入文本行上执 行多个操作。awk 命令编程语言不需要编译,并允许用户使用变量、数字函数、字符 串函数和逻辑运算符。awk 命令受到 LANG、LC_ALL、PATH 等环境变量的影响。
awk 是 Linux 下的一个命令,它对其他命令的输出、对文件的处理都十分强大。其实它更 像一门编程语言,可以自定义变量,有条件语句,有循环,有数组,有正则,有函数等。它读 取输出或者文件的方式是一行一行地读,根据用户给出的条件进行查找,并在找出的行中进行 操作,感觉它的设计思想真的很简单,但是结合实际情况,具体操作起来就没有那么简单了。 它有 3 种形式:awk,gawk,nawk,平时所说的 awk 其实就是 gawk。
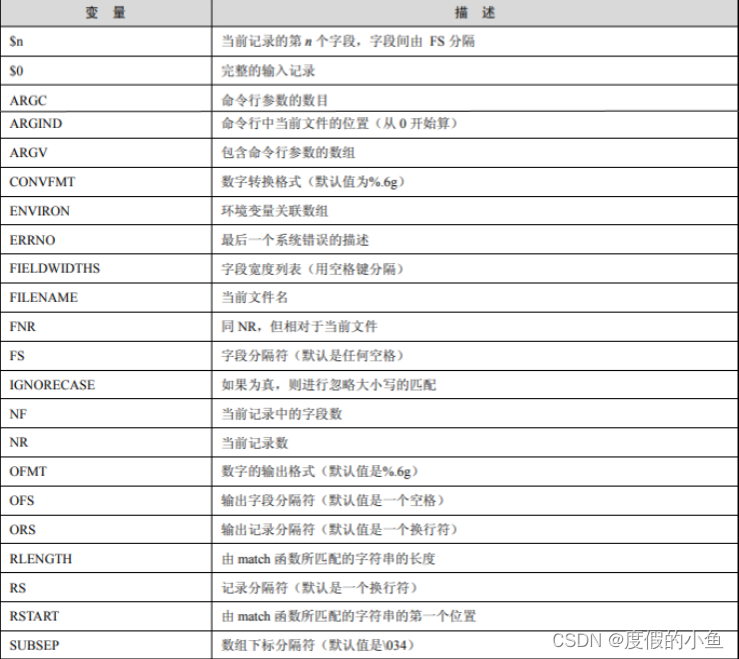
1.变量
变量及其描述如表
2.运算符
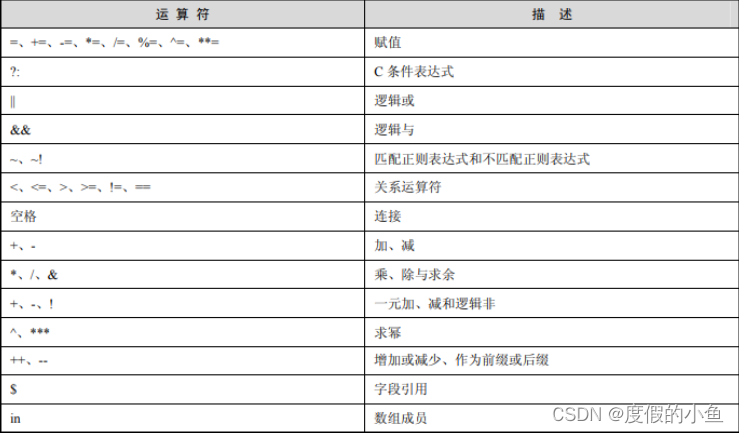
运算符及其描述如表
3.awk 的正则
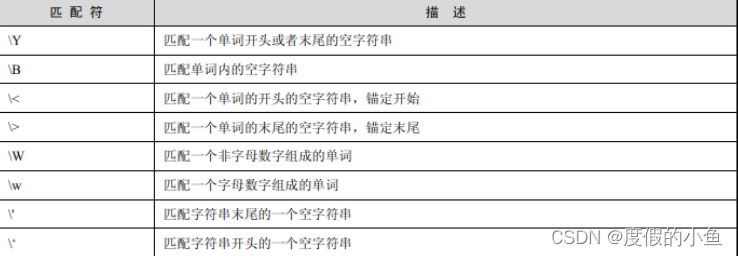
匹配符及其描述如表
4.字符串函数
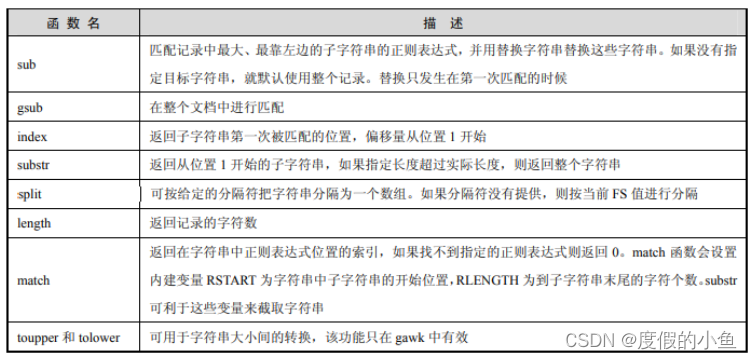
字符串函数及其描述如表
5.数学函数
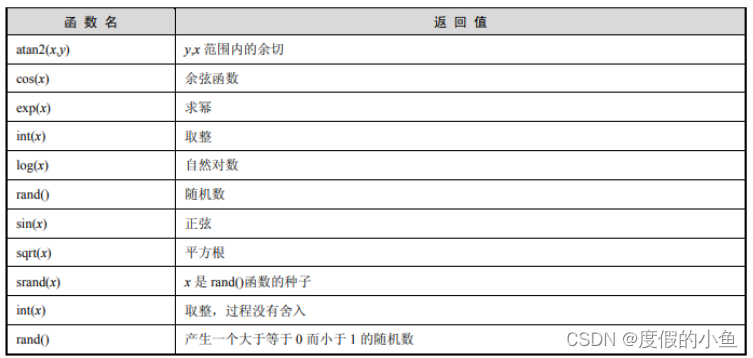
数学函数及其返回值如表
案例练习
(1)显示文件 hello.c 中的行号和第三字段。
#awk '{printf"%03d%s\n",NR,$1}' hello.c
001/*
002#include
003int
004{
005printf("Hello,
006return
007}
(2)显示长于 7 个字符的文件的行。
# awk 'length >7' hello.c
/* hello.c - Canonical "Hello, World!" program */
#include <stdio.h>
int main(void)
printf("Hello, Linux programming world!\n");
return 0;
(3)以相反顺序打印前两个字段。
awk 'length >7' hello.c
/* hello.c - Canonical "Hello, World!" program */
#include <stdio.h>
int main(void)
printf("Hello, Linux programming world!\n");
return 0;
[root@localhost tmp]# awk '{ print $2, $1 }' hello.c
hello.c /*
<stdio.h> #include
main(void) int
{
Linux printf("Hello,
0; return
}
2.45 wc:输出文件中的行数、单词数、字节数
-
作用:对每个文件输出行、单词和字节统计数,如果指定了多于一个文件,则还有一个行数的总计。如果指定的文件是“-”,则读取标准输入。
-
用法:wc [选项]…[文件]
-
主要选项如下。
主要选项如下:
命令 描述 -c, --bytes, --chars输出字节统计数。 -l, --lines输出换行符统计数 -L, --max-line-length输出最长的行的长度 -w, --words输出单词统计数。 案例练习
显示文件 hello.c 中的单词数。
# wc -w hello.c 20 hello.c
2.46 comm:比较排序文件
-
作用:逐行比较两个已排序的文件。
-
用法:
comm [选项]...文件 1 文件 2 -
主要选项如下
如果不附带选项,程序会生成三列输出。第一列包含文件 1 特有的行,第二列包含文件 2 特有的行,而第三列包含两个文件共有的行。
| 命令 | 描述 |
|---|---|
-1 | 不输出文件 1 特有的行。 |
-2 | 不输出文件 2 特有的行。 |
-3 | 不输出两个文件共有的行。 |
--check-order | 检查输入是否被正确排序,即使所有输入行均成对。 |
--nocheck-order | 不检查输入是否被正确排序。 |
--output-delimiter=STR | 依照 STR 分列 |
--help | 显示此帮助信息并退出。 |
--version | 显示版本信息并退出。 |
案例练习
比较排序 FILE1 和 FILE2,共有部分不显示。
comm -3 FILE1 FILE2
SSSS
222
2.47 join:将两个文件中指定栏位内容相同的行连接起来
- 作用:找出两个文件中指定栏位内容相同的行并加以合并,再输出到标准输出设备。
- 用法:
join [选项]文件 1 文件 2 - 主要选项如下
针对每一对具有相同内容的输入行,整合为一行写到标准输出,默认的内容连接区块是由 第一个空白符代表的分界符号。当文件 1 或文件 2 都被指定为“-”时,程序将从标准输入读 取数据。
| 命令 | 描述 |
|---|---|
-a 文件编号 | 文件编号的值可以是 1 或 2,分别对应文件 1 和文件 2。此选项用于根据指定文件编号输出不成对的行目。 |
-e 字符 | 将缺失的输入区块替换为指定字符。 |
-i,--ignore-case | 比较时忽略大小写。 |
-j 域 | 等于“-1 域-2 域”。 |
-o 格式 | 按照指定格式构造输出行。 |
-t 字符 | 使用指定字符作为输入和输出的分隔符。 |
-v 文件编号 | 类似-a 文件编号,但禁止组合输出行。 |
-1 域 | 在文件 1 的此域组合。 |
-2 域 | 在文件 2 的此域组合。 |
--check-order | 检查输入行是否正确排序,即使所有输入行均是成对的。 |
--nocheck-order | 不检查输入是否正确排序。 |
--header | 将首行视作域的头部,直接输出而不对其进行匹配。 |
--help | 显示此帮助信息并退出。 |
--version | 显示版本信息并退出。 |
2.48 fmt:编排文本文件
-
作用:从指定的文件里读取内容,将其按照指定格式重新编排后,输出到标准输出设备。
若指定的文件名为“-”,则 fmt 命令会从标准输入设备读取数据。
-
用法:fmt [-宽度] [选项]… [文件]…
重新格式化文件中的每个段落并输出到标准输出。
选项“-宽度”是“–width=数字”的缩写。
-
主要选项如下。
长选项必须使用的参数对于短选项也是必须使用的。
命令 描述 -c --crown-margin 保持前两行的缩进。 -p,–prefix=字符串 只对以指定字符串开头的行重新格式化,将前缀重新附着到被重新格式化的行上。 -s,–split-only 分割过长的行,但不自动补足。 -t,–tagged-paragraph 缩进首行以使其不同于第二行。 -u,–uniform-spacing 每两个单词间保留一个空格,每句之后保留两个空格。 -w,–width=宽度 最大行宽(默认为 75 列宽度)。 –help 显示此帮助信息并退出。 –version 显示版本信息并退出。 应用实例如下。
重新排版 hello.c 文件。
# fmt hello.c /* hello.c - Canonical "Hello, World!" program */ #include <stdio.h> int main(void) { printf("Hello, Linux programming world!\n"); return 0; }