文章目录
- Java 语言特性
- 形参和实参的区别是什么?
- 值传递和引用传递的区别?
- Java 是值传递还是引用传递?
- final 的作用是什么?
- final finally finalize 有什么不同?
- static 的作用是什么?
- static 和 final 的区别是什么?
- Java 数据类型
- Java基本数据类型有几种? 各占多少位?
- 基础类型和包装类型有什么区别?
- 自动装箱和自动拆箱了解吗? 有什么区别?
- Integer 的缓存机制
- Java 常见类
- Object 类的常见方法有哪些?
- == 和 equals() 的区别?
- 为什么要有 hashCode ?
- 为什么重写 equals() 时要重写 hashCode() 方法?
- 深拷贝和浅拷贝有什么区别?
- 深拷贝有几种实现方式?
- 实现 Cloneable 接口, 重写 clone 方法
- 使用JSON字符串转换
- 还可以使用第三方库实现深克隆
- String StringBuffer StringBuilder 有什么区别?
- Java 中的 String 为什么不可变?
- Java 异常
- 介绍 Java 的异常体系
- 受检异常和未受检异常的区别是什么?
- 如何自定义异常?
Java 语言特性
形参和实参的区别是什么?
- 形参就是形式参数, 就是定义方法的时候使用的参数, 是用来接收调用者传递的参数的.
- 实参就是实际参数, 是用于传递给方法时使用的参数, 在传递时需要进行赋值.
简单来说就是, 形参是用来接收值用的参数, 而实参是传递值时用的参数.
值传递和引用传递的区别?
- 值传递就是在调用方法的时候, 将实际参数拷贝一份传递给方法, 这样在方法中修改形式参数的时候, 不会影响到实际参数.
- 引用传递也叫地址传递, 就是在调用方法的时候, 将实际参数的地址传递给方法, 这样在方法种修改形式参数就会影响到实际参数.
Java 是值传递还是引用传递?
Java 不管传递的是基本数据类型还是引用数据类型, 都是值传递, 没有引用传递
- 传递基础数据类型的时候, 实参和形参都是存储在不同的栈帧内, 修改形参的栈帧数据, 不会影响实参的数
- 传递引用数据类型的时候, 形参和实参指向同一个地址的时候, 修改形参的内容就会影响到实参, 当形参和实参的地址不一样时, 就不影响.
final 的作用是什么?
final 表示不可变性, 可以用来修饰 类, 方法, 变量, 修饰类时, 表示这个类不能被继承, 修饰方法时, 表示这个方法不能被重写, 修饰变量时, 表示这个变量不能被修改.
- 使用 final 修饰的变量在初始化后就不能被修改了, 这就能确保变量的值不变, 避免了意外的修改, 提高了代码可靠性. (不可变性)
- 使用 final 修饰就不可变了, 在多线程情况下是线程安全的.(线程安全)
- 由于 final 变量的值不变, 编译器可以在编译的时候进行一些优化, 比如在循环中提前计算表达式的结果, 缓存变量值等, 从而提高了运行效率.(性能优化)
- 被 final 修饰的变量, 具有强有力的可见性, 当一个线程在写 final 的值时, 其他线程能立马看见. 而不会出现脏读的情况.(不存在可见性问题)
- 通过 final 修饰, 明确表示这个变量是一个常量, 不应该被修改, 这也提高了代码的可读性, 让其他开发人员容易理解.(代码的可读性)
final finally finalize 有什么不同?
- final 表示不可变性, 可以用来修饰 类, 方法, 变量, 修饰类时, 表示这个类不能被继承, 修饰方法时, 表示这个方法不能被重写, 修饰变量时, 表示这个变量不能被修改.
- finally 是用于在 try-catch 后面的一个代码块, 无论是否有异常抛出, 都会执行到这个代码块, 比如 关闭 JDBC 连接.
- finailze 是 Object 类的一个方法, 用于在对象被垃圾回收之前的一些清理工作, 但是垃圾回收的时机是不确定的, 所以 finalize 的执行时机也是不确定的, 在 JDK 9 之后标位弃用.
static 的作用是什么?
用一句话来说, 方便在没有创建对象的时候进行调用.
也就是说, 被 static 修饰的不需要通过创建对象的方式去调用, 可以直接通过类名去访问.
static 可以用来修饰 类(内部类), 方法, 变量, 代码块.
- static 修饰的成员被所有对象共享.
- static 修饰的成员优于对象存在, 在类加载时候就有了.
- 直接通过类名调用.
- 修饰的数据时共享数据, 对象中存储的特有数据.
static 和 final 的区别是什么?
它们是两个不同的关键字, 有着不同的作用和含义.
- static 表示创建一个静态成员(内部类, 方法, 变量, 代码块).
- final 表示 不可变性, 可以用来修饰类, 方法, 变量.
主要区别有:
- static 修饰的变量可以被修改, 而 final 修饰的变量不能被修改.
- static 修饰的变量可以被初始化多次, 而 final 修饰的变量只能被初始化一次(创建的时候初始化或在构造方法中初始化)
- static 修饰的变量在类加载的时候初始化, 而 final 修饰的变量在对象创建的时候初始化.
Java 数据类型
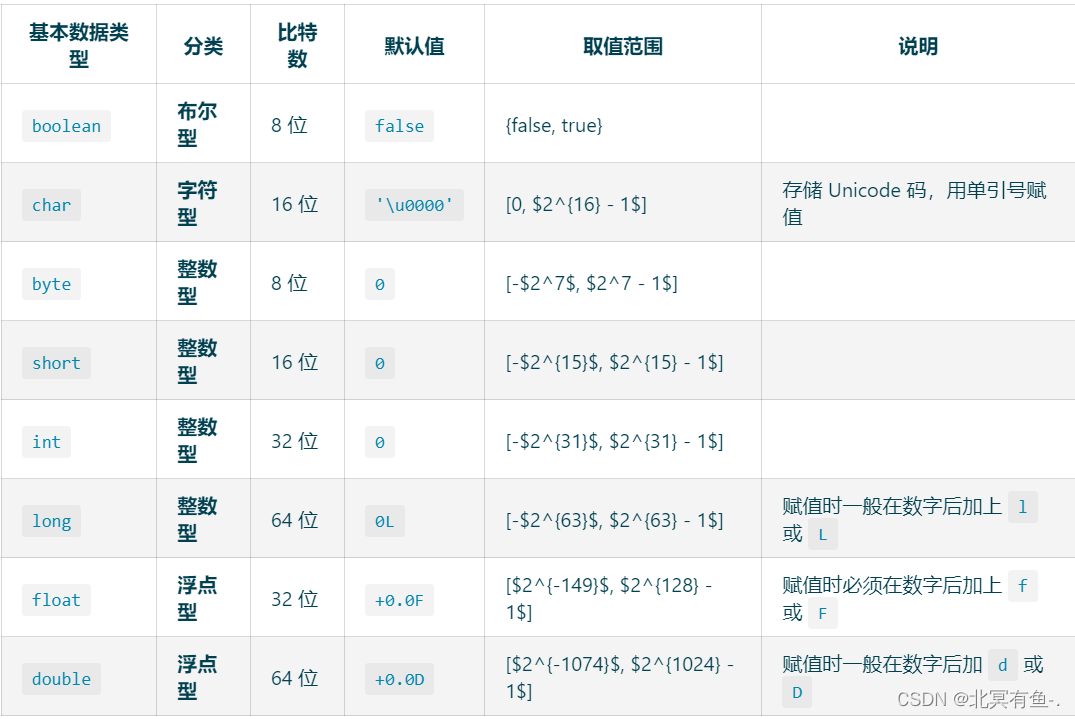
Java基本数据类型有几种? 各占多少位?
Java 中基本数据类型有 8 种.
基础类型和包装类型有什么区别?
- 包装类型可以表示 null 值, 而基本数据类型不行, 比如在接口传参中, 如果使用包装类即使前端不传参也不会报错, 如果使用基础类型, 前端忘记传参就会报错.
- 包装类可以用于泛型, 而基础数据类型不能, 泛型要求不能使用基础数据类型, 使用基础类型会报错, 因为泛型在编译的时候, 会进行类型擦除, 最后只保留原始类型, 原始类型只能是 Object 或其子类.
- 包装类中提供更多的功能和方法, 基础数据类型是没有的, 比如说 数学运算, 比较大小等.
自动装箱和自动拆箱了解吗? 有什么区别?
- 自动装箱就是 基础类型转换成包装类型的过程.
- 自动拆箱就是 包装类型转换成基础类型的过程.
public class AutoBoxingUnboxingExample {
public static void main(String[] args) {
// 自动装箱:将基本数据类型转换为对应的包装类对象
int primitiveInt = 10;
Integer boxedInt = primitiveInt; // 自动装箱
// 自动拆箱:将包装类对象转换为对应的基本数据类型
Integer boxedInteger = 20;
int unboxedInt = boxedInteger; // 自动拆箱
System.out.println("Boxed Integer: " + boxedInt);
System.out.println("Unboxed int: " + unboxedInt);
}
}
那么底层是怎么实现的呢?
我们进行反编译
public class AutoBoxingUnboxingExample {
public AutoBoxingUnboxingExample() {
}
public static void main(String[] var0) {
int primitiveInt = 10;
Integer boxedInt = Integer.valueOf(primitiveInt); // 自动装箱
Integer boxedInteger = Integer.valueOf(20);
int unboxedInt = boxedInteger.intValue(); // 自动拆箱
System.out.println("Boxed Integer: " + boxedInt);
System.out.println("Unboxed int: " + unboxedInt);
}
}
通过反编译我们可以知道 自动装箱是通过 Integer.valueOf() 实现的, 自动拆箱是通过 Integer.intValue() 实现的.
Integer 的缓存机制
在 Java 中, Integer 类实现了一个简单的缓存机制, 对于在范围 -128 到 127 之间的整数, 会进行缓存, 以便重复使用相同值的 Integer 对象, 从而节省内存和提高性能.
public class IntegerCacheExample {
public static void main(String[] args) {
// 测试缓存范围内的整数
Integer integer1 = 100;
Integer integer2 = 100;
System.out.println("integer1 == integer2: " + (integer1 == integer2));
// 输出 true,因为范围在 -128 到 127 之间的整数被缓存
// 测试超出缓存范围的整数
Integer integer3 = 200;
Integer integer4 = 200;
System.out.println("integer3 == integer4: " + (integer3 == integer4));
// 输出 false,因为超出缓存范围的整数没有被缓存
}
}
Java 常见类
Object 类的常见方法有哪些?
Java Object 类是所有类的父类, 也就是说 Java 的所有类都继承了 Object 类, 可以使用 Object 的所有方法.
位于 java.lang 包中, 在编译的时候会自动导入.
-
protected Object clone()
创建并返回一个对象的克隆 -
boolean equals(Object obj)
比较两个对象是否相等 -
protected void finalize()
当 GC (垃圾回收器)确定不存在对该对象的有更多引用时,由对象的垃圾回收器调用此方法。 -
Class<?> getClass()
获取对象的运行时对象的类 -
int hashCode()
获取对象的 hash 值 -
void notify()
唤醒在该对象上等待的某个线程 -
void notifyAll()
唤醒在该对象上等待的所有线程 -
String toString()
返回对象的字符串表示形式 -
void wait()
让当前线程进入等待状态。直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法。 -
void wait(long timeout)
让当前线程处于等待(阻塞)状态,直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法,或者超过参数设置的timeout超时时间。 -
void wait(long timeout, int nanos)
与 wait(long timeout) 方法类似,多了一个 nanos 参数,这个参数表示额外时间(以纳秒为单位,范围是 0-999999)。 所以超时的时间还需要加上 nanos 纳秒。。
具体信息可看 Object 类
== 和 equals() 的区别?
- == 是操作符, 用于基础数据类型的时候, 是比较两个变量的值是否相同, 用于引用数据类型的时候, 是比较两个对象的引用是否相同.
- equals() 是Object 类的一个方法, 默认是用来比较两个对象的引用是否相同, 但是在大部分时候都被重写为比较两个对象的值是否相同.
通常情况下, 我们会使用 == 比较两个基本数据类型是否相等和两个对象的引用是否相同, 使用 equals() 来比较两个对象的值是否相同(前提是重写了 equals() 方法).
为什么要有 hashCode ?
hashCode 的作用是获取哈希值, 这个哈希值的作用就是确定对象在哈希表中的索引位置, 这个HashCode 和 equals 共同协作来判断两个对象想否相等, 主要就是突出性能.
当我们比较两个对象是否相等的时候, 我们就可以先使用 hashCode 进行比较, 如果比较是 ture , 就可以使用 equals 再次确定两个对象是否相等, 如果比较结果是 true, 那么这两个对象就是相等的, 否则就不相等, 这就大大提高了对象比较的性能.
那为什么不直接使用 hashCode 就确定两个对象是否相等呢?
这是因为不同对象的 hashCode 可能相同;但 hashCode 不同的对象一定不相等,所以使用 hashCode 可以起到快速初次判断对象是否相等的作用。
为什么重写 equals() 时要重写 hashCode() 方法?
在 Java 中, 如果两个对象根据 equals() 判断相等, 那么他们的 hashCode() 也必须相等, 这是因为使用哈希数据结构(HashMap, HashSet 等)时, hashCode() 的返回值被用来确定对象在哈希表中的索引位置, 如果两个对象被 equals() 判断是相等时, hashCode() 却不相等, 这就会导致在哈希数据结构中无法正确的找到对象.
深拷贝和浅拷贝有什么区别?
- 浅拷贝就是只拷贝栈内存中的数据, 不拷贝堆内存中的数据, 也就是浅拷贝只会拷贝原型对象, 不会拷贝引用对象.
- 深拷贝就是既拷贝栈内存中的数据, 也拷贝堆内存中的数据, 也就是深拷贝既拷贝原型对象, 也拷贝引用对象.
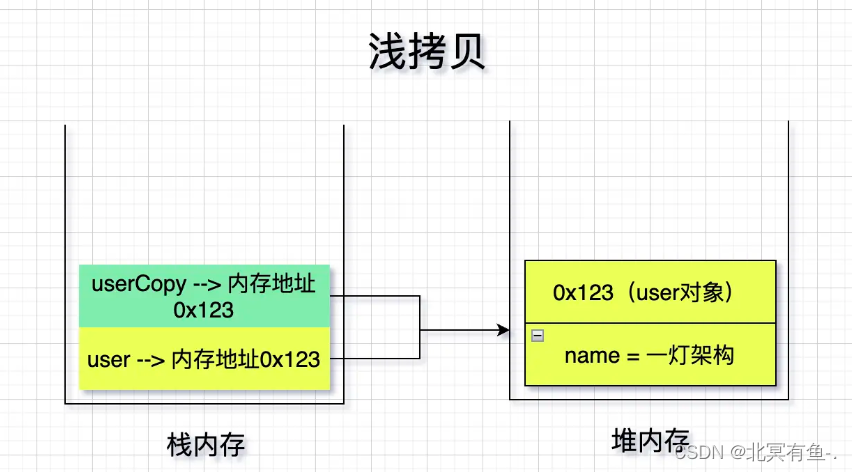
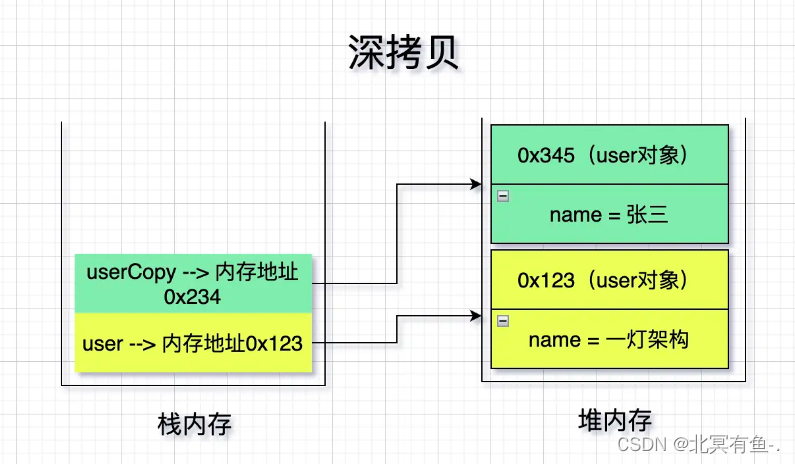
更多信息深拷贝与浅拷贝的实现原理
深拷贝有几种实现方式?
实现 Cloneable 接口, 重写 clone 方法
class Address {
private String city;
public Address(String city) {
this.city = city;
}
// 实现深拷贝的 clone 方法
@Override
public Object clone() {
return new Address(this.city); // 创建新的 Address 对象并返回
}
public String getCity() {
return city;
}
}
class Person implements Cloneable {
private String name;
private int age;
private Address address;
public Person(String name, int age, Address address) {
this.name = name;
this.age = age;
this.address = address;
}
// 实现深拷贝的 clone 方法
@Override
public Object clone() throws CloneNotSupportedException {
// 克隆 Person 对象
Person clonedPerson = (Person) super.clone();
// 克隆 Address 对象
clonedPerson.address = (Address) address.clone();
return clonedPerson;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
public Address getAddress() {
return address;
}
}
public class DeepCopyExample {
public static void main(String[] args) {
try {
// 创建一个 Person 对象
Address address = new Address("New York");
Person originalPerson = new Person("Alice", 30, address);
// 克隆该对象
Person clonedPerson = (Person) originalPerson.clone();
// 输出克隆后的对象的属性值
System.out.println("Cloned Person: " + clonedPerson.getName() + ", " + clonedPerson.getAge() + ", " + clonedPerson.getAddress().getCity());
// 修改原始对象的属性值
originalPerson.getName().replace("Alice", "Bob");
originalPerson.getAge() = 25;
originalPerson.getAddress().setCity("Los Angeles");
// 输出原始对象和克隆对象的属性值,验证克隆是深拷贝
System.out.println("Original Person: " + originalPerson.getName() + ", " + originalPerson.getAge() + ", " + originalPerson.getAddress().getCity());
System.out.println("Cloned Person: " + clonedPerson.getName() + ", " + clonedPerson.getAge() + ", " + clonedPerson.getAddress().getCity());
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
}
}
Java中最常见的实现方式是通过实现 Cloneable 接口的方式来实现深拷贝.
缺点是比较麻烦,需要所有实体类都实现Cloneable接口,并重写clone方法。如果实体类中新增了一个引用对象类型的属性,还需要添加到clone方法中。
使用JSON字符串转换
import com.google.gson.Gson;
class Address {
private String city;
public Address(String city) {
this.city = city;
}
// Getter 和 Setter 方法
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
}
class Person {
private String name;
private int age;
private Address address;
public Person(String name, int age, Address address) {
this.name = name;
this.age = age;
this.address = address;
}
// Getter 和 Setter 方法
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Address getAddress() {
return address;
}
public void setAddress(Address address) {
this.address = address;
}
}
public class DeepCopyUsingJSON {
public static void main(String[] args) {
// 创建一个 Person 对象
Address address = new Address("New York");
Person originalPerson = new Person("Alice", 30, address);
// 使用 Gson 序列化和反序列化实现深克隆
Gson gson = new Gson();
String json = gson.toJson(originalPerson);
Person clonedPerson = gson.fromJson(json, Person.class);
// 修改原始对象的属性值
originalPerson.setName("Bob");
originalPerson.setAge(25);
originalPerson.getAddress().setCity("Los Angeles");
// 输出原始对象和克隆对象的属性值,验证克隆是深拷贝
System.out.println("Original Person: " + originalPerson.getName() + ", " + originalPerson.getAge() + ", " + originalPerson.getAddress().getCity());
System.out.println("Cloned Person: " + clonedPerson.getName() + ", " + clonedPerson.getAge() + ", " + clonedPerson.getAddress().getCity());
}
}
还可以使用第三方库实现深克隆
String StringBuffer StringBuilder 有什么区别?
- String 是线程安全的不可变字符串类, 每次修改都会创建一个新的对象.
- StringBuffer 是线程安全的可变字符串, 它提供了 append() 或 add() 方法, 进一步提高了性能, 修改时不再创建新的对象.
- StringBuilder 是线程不安全的可变字符串, 在能力上, 和StringBuffer 没有本质区别, 但是它去掉了线程安全部分, 有效减小了开销.
Java 中的 String 为什么不可变?
- 能使 Java 节省大量的内存空间, 多个引用可以指向同一个字符串,(在字符串常量池中)
- 第二个重要原因是安全性, 不可变字符串可以防止恶意代码通过修改字符串来破坏系统安全, 比如说, 在进行密码检验的时候, 攻击者可以通过修改字符串来绕过密码验证.
- 线程安全, 不可变字符串是线程安全的, 在多线程环境下使用没有问题.
Java 异常
介绍 Java 的异常体系
异常主要分为 Exception 和 Error 两种, 它们都继承了 Throwable 类, Exception 又分为 运行时异常, 和非运行时异常.
- 运行时异常, 就是RunTimeException类及其子类的异常, 在编译的时候不会检查的异常, 比如说空指针异常, 下标越界异常等, 程序中可以选择捕获处理, 也可以选择不捕获处理, 在编译时能顺利通过, 但是在运行的时候, 会被系统抛出.
- 非运行时异常, 就是RunTimeException之外的异常, 就是必须要处理的异常, 不处理编译就不能通过, 比如 IOException, SQLException 自定义异常等.
- Error 是虚拟机内部错误, 比如系统错误, 栈内存溢出错误(递归层数太多等), 堆溢出错误(创建的对象太多等) , 一般是运行环境中的严重问题, 也可能是因为程序员代码的问题(比如递归调用自身),
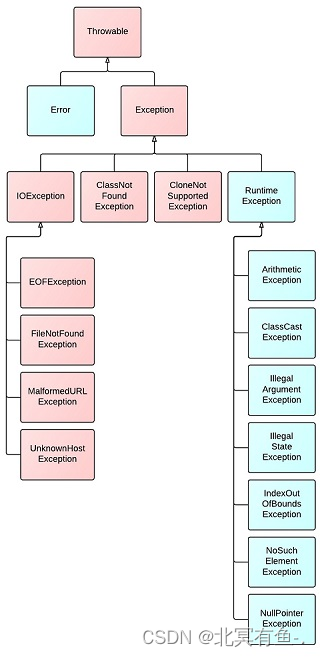
受检异常和未受检异常的区别是什么?
- 受检异常就是可查异常, 编译器要求必须处理的异常, 除了 RunTimeException 和其子类的异常意外, 其他的 Exception 及其子类都属于 受检异常, 必须进行捕获处理, 不然编译不能通过.
- 未受检异常就是不可查异常, 编辑器不要求强制处理的异常, 包括 RunTimeException(运行时异常) 和 Error (错误)
如何自定义异常?
- 自定义异常类,然后继承自Exception 或者 RunTimeException
- 实现一个带有String类型参数的构造方法,参数含义:出现异常的原因
// 自定义异常类
class CustomException extends Exception {
// 构造方法
public CustomException(String message) {
super(message);
}
}
// 使用自定义异常的示例
public class SimpleCustomExceptionExample {
// 抛出自定义异常的方法
public static void checkValue(int value) throws CustomException {
if (value < 0) {
throw new CustomException("Value cannot be negative");
}
// 其他处理逻辑
}
public static void main(String[] args) {
try {
checkValue(-1);
} catch (CustomException e) {
// 捕获自定义异常并处理
System.out.println("Error message: " + e.getMessage());
}
}
}
异常机制详解-点击跳转