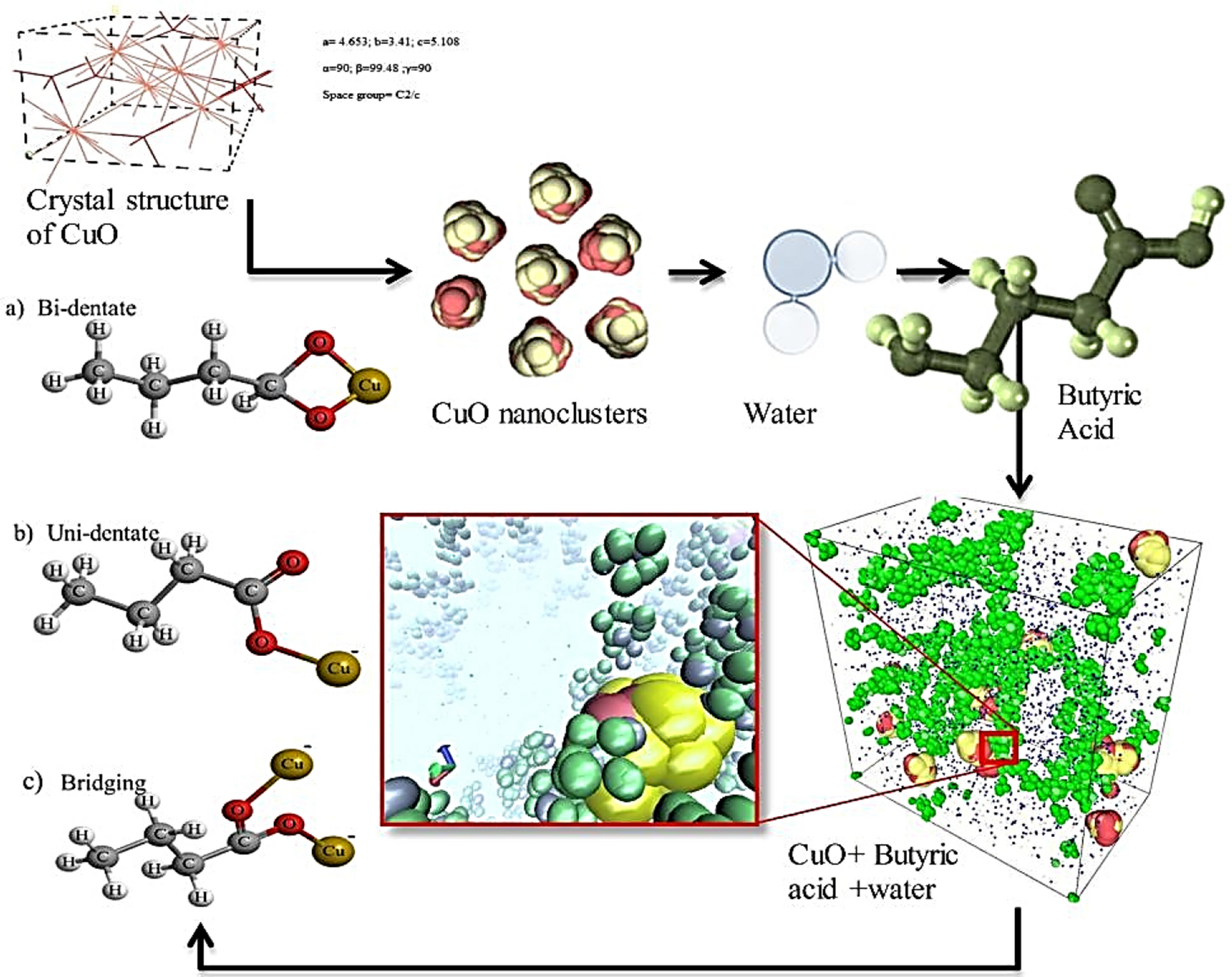
用PPO算法求解整个神经网络在迭代过程中的梯度问题
每走一步就会得到一个新的状态,把这个状态传到网络里面,会得到一个 action,执行这个 action 又会到达一个新状态
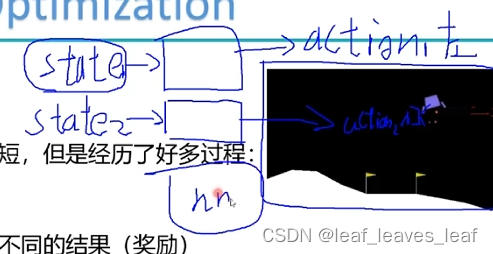
policy 中由状态 st 生成动作 at,生成的这个 at 是由整个网络的所有权重参数 决定的。最终目标是优化整个网络模型,使得这个网络模型在每一个状态都能给出正确的答案
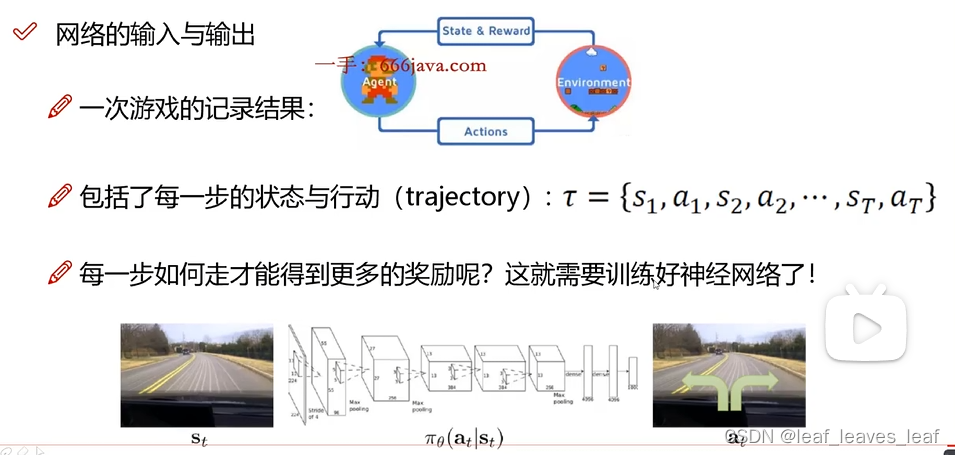
我们的目标是训练一个网络模型,只不过背景和数据有一些变化,数据是不断地由自己生成的,也就是智能体在玩的过程中不断生成出来的。用一系列生命周期记录数据,目的是训练好当前的网络模型。
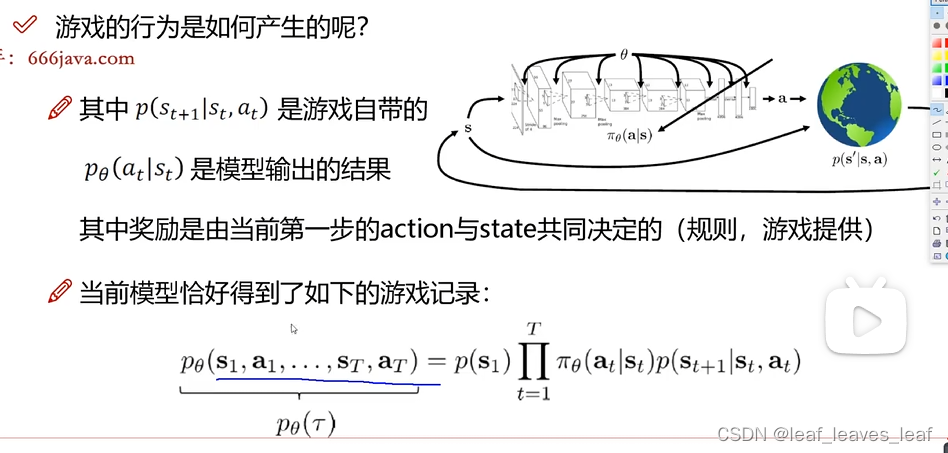
一(下一个状态是什么)和三(规则)都是游戏自带的,只有第二个是我们需要考虑的,我们只需要操心怎么把模型训练的更好
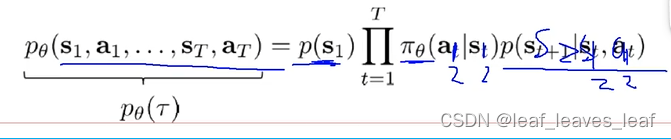
我们的目的是求出一个神经网络模型,帮我去玩这个游戏,帮我去得到每一步的 action 是什么,把神经网络中的模型参数 求出一个合适的值,所以我们优化的是网络中的权重参数
需要找到一组最优的 使得整个生命周期做完之后整体的奖励最大,这是一个梯度上升问题

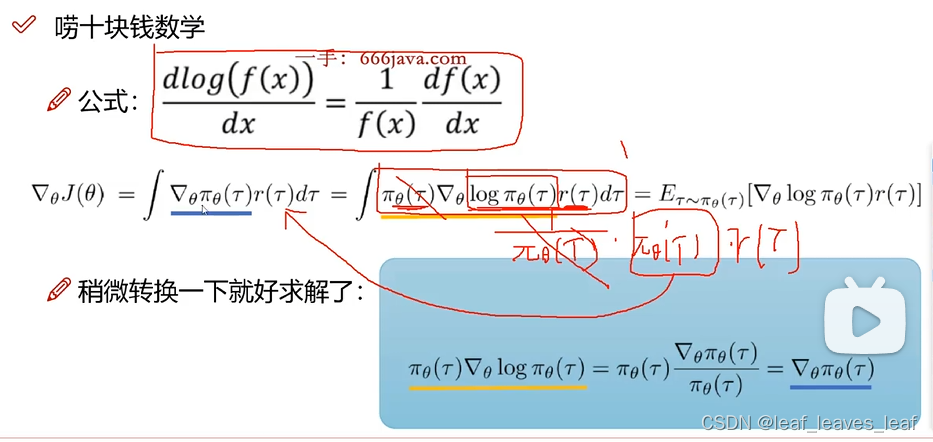
求 等于什么的时候能够使得期望 J(
) 最大



下面终极版的公式需要很多数据,有没有巧妙的方法帮我们收集这些数据?
到此为止我们还没有提到 PPO,只是在算梯度,一会会说 PPO 是帮助我们求解的
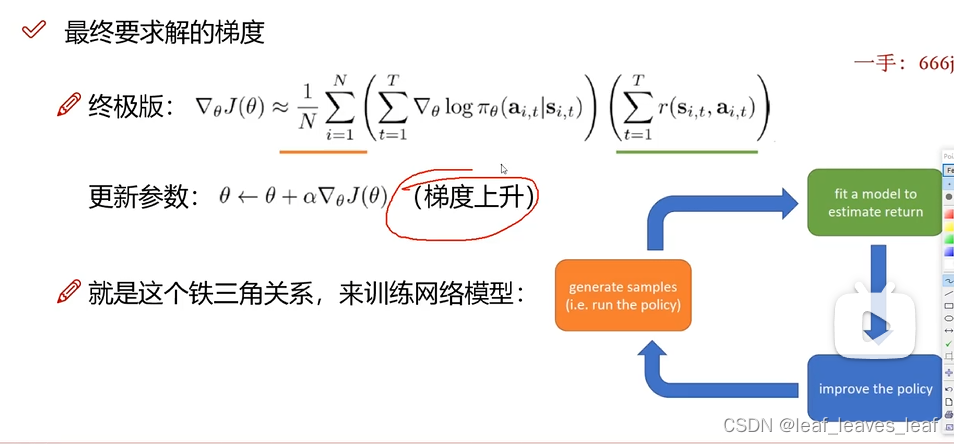
每玩一把都是在攒数据,把数据代入即可求解

PPO 的一些技巧方法:
baseline 去均值,使得奖惩分明,奖励是正的,惩罚是负的
不用总的奖励,用去均值之后的

之前讲的只是策略梯度(policy gradient),没有任何 PPO 的概念,下面看一下 PPO 到底是怎样帮助我们优化当前任务的






在实际中,和 2 最像的就是前一步的迭代结果
1,用前一步迭代结果的时候用到的
1产生大量数据供当前的
2 进行学习,学习完之后变成
3,
3 的时候狸猫变成
2,
4 的时候狸猫变成
3
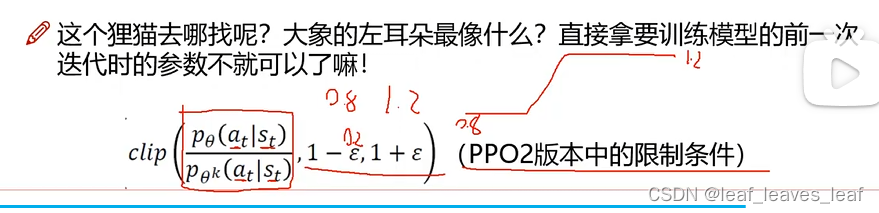
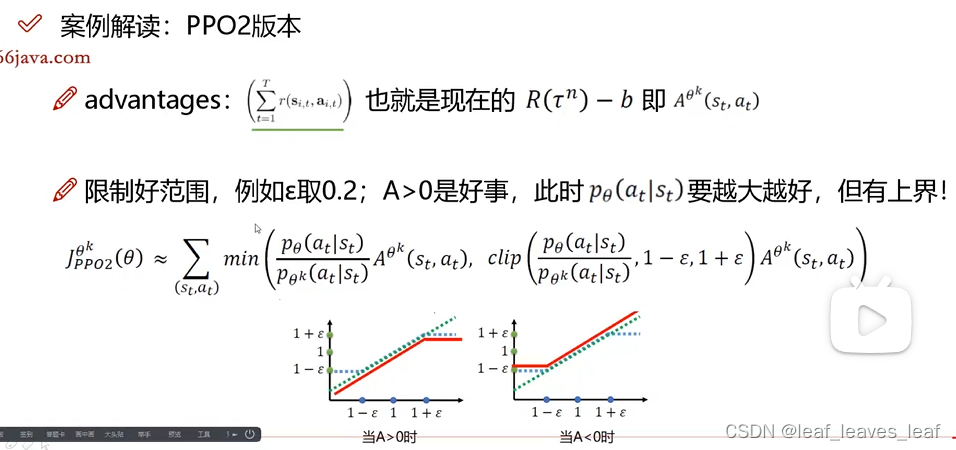
PPO2 只是多加了一个限制条件,做一个截断的操作,把他俩的相似范围限制到了一个区间
actor 网络输入的是 state,会帮我们决定当前什么样的 action 是最合适的
critic 也是一个网络,会输出 value 值,这个 value 值来评估我当前这个水平做的这个事情是否合适
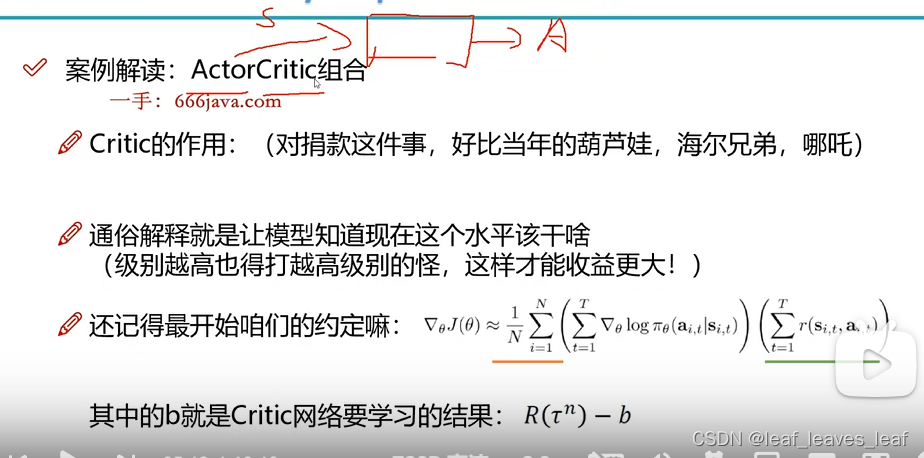
b 是 critic 网络要学习的结果,是 critic 网络的输出值 value,如果当前智能体水平很高但是还在打低级怪物,获得比较低的奖励,那么此时当他再减去一个 value 之后可能会得到一个负值,意味着当前做这件事不合适

之所以取 min 值,是希望不论 A 大于 0 还是小于 0,p_ 和 p_
k 都不能相差太远