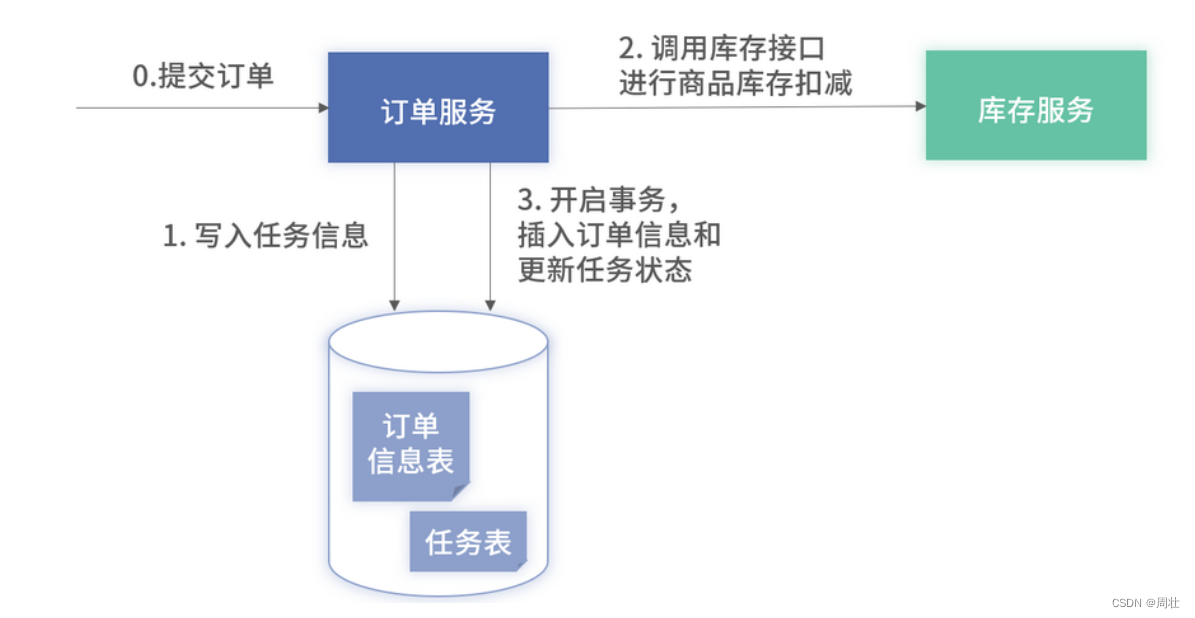
编译器在某些情况下会对程序进行转化,有些是编译器需要的,有些是出于性能考虑的,转化可能会产生出乎意料的结果
文章目录
- 明确的初始化操作
- 参数的初始化
- 返回值的初始化
- 在使用者层面做优化
- 在编译器层面做优化
- NRV 优化
- NRV优化的弊端
- 参考资料
明确的初始化操作
已知有这样的定义
X x0;
下面有三个定义,每一个都明显地以 x0 来初始化其类对象
void foo_bar() {
X x1( x0 );
X x2 = x0;
X x3 = X( x0 );
}
必要的程序转化有两个阶段:
- 重写每一个定义,其中的初始化操作会被剥离。
- 类的拷贝构造函数的会被安插进去
其 C++ 伪码可能像下面这样:
void foo_bar() {
X x1;
X x2;
X x3;
x1.X::X( x0 );
x2.X::X( x0 );
x3.X::X( x0 );
}
参数的初始化
C++ 标准说,把一个类对象当做参数传给一个函数(或是作为一个函数的返回值),相当于以下形式的初始化操作:
X xx = arg;
其中 xx 代表形式参数 (或返回值) 而 arg 代表真正的参数值。因此,若已知这个函数:
void foo( X x0 );
下面这样的调用方式:
X xx;
foo( xx );
将会要求局部实体 x0 以逐成员的方式将 xx 当作初值。在编译器实现技术上,有一种策略是导入所谓的暂时性对象(或临时对象),并调用拷贝构造函数将它初始化,然后将该暂时性对象(或临时对象)交给函数。
例如将前一段程序代码转换如下:
X __temp0;
__temp0.X::X( xx );
foo( __temp0 ):
然而这样的转换是有问题的,因为我们又要调用 foo( X x0 ) 再展开下去,产生无穷无尽的调用,因此这种情况,函数声明也相当于改为 void foo( X& x0 )。
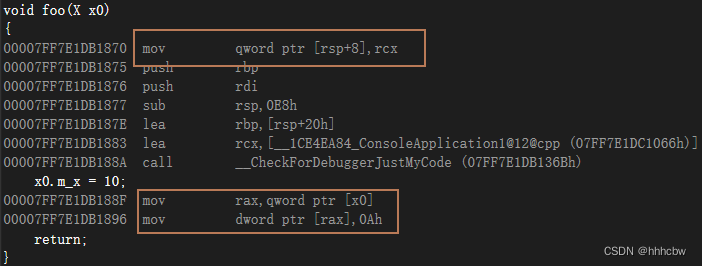
下面的为vs2022下的汇编代码
可以看到在调用 foo 之前先调用了X的拷贝构造函数

在拷贝构造函数中可以看到对于变量的地址

之后将rax的值传给了rcx,可以看到rax中的值就是之前this指针的地址,然后调用 foo

可以看到 x0 的地址为之前 this 指针的地址,说明确实是 void foo( X& x0 )
返回值的初始化
已知下面这个函数定义
X bar()
{
X xx;
return xx;
}
那么 bar() 的返回值如何从局部对象 xx 中拷贝过来,在 cfront 中的解决方法是一个双阶段转化:
- 首先加上一个额外参数,类型是类对象的一个引用。这个数将用来放置拷贝构造得到的返回值
- 在return指令之前安插一个拷贝构造调用操作,以便将想传回的对象的内容当做上述新增参数的初值
真正的返回值是什么?最后一个转化操作会重新改写函数,使它不传回任何值,bar() 转换如下:
void bar( X& __result )
{
X xx;
xx.X::X();
__result.X::XX( xx );
return;
}
现在编译器必须转换每一个 bar() 调用操作,以反映其新定义。例如:
X xx = bar();
将被转换为下列两个指令句:
X xx;
bar( xx );
将被转换为下列两个指令句:
X xx;
bar( xx );
而对于语句:
bar().memfunc();
可能被转化为:
X __temp0;
( bar( __temp0 ), __temp0 ).memfunc();
同样道理,如果程序声明了一个函数指针,像这样:
X ( *pf )();
pf = bar;
它也必须被转化为:
void ( *pf )( X& );
pf = bar;
在使用者层面做优化
比如下面的函数
X bar (const T &y, const T &z)
{
X xx;
xx.m_x = y + z;
return xx;
}
如果使用者将这个函数改为
X bar( const T &y, const T &z)
{
return X( y, z );
}
于是当 bar() 的定义被转换之后,效率会比较高:
void bar( X &__result )
{
__result.X::X( y, z );
return;
}
__result 被直接计算出来,而不是经由拷贝构造拷贝而得。
在编译器层面做优化
NRV 优化
在一个如 bar() 这样的函数中,所有的 return 指令传回相同的具名数值,比如上面实例中的局部变量 xx,编译器有可能自己做优化,方法是以 result 参数取代 named return value。例如下面的 bar() 定义:
X bar()
{
X xx;
// ... 处理 xx
return xx;
}
编译器把其中的 xx 以 __result 取代:
void bar( X& __result )
{
__result.X::X();
// ... 直接处理__result
return ;
}
这样的编译器优化操作,有时候被称为 Named Return Value(NRV) 优化。
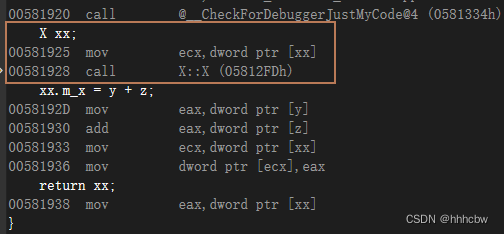
看下 VS2022中,下面的实例
X bar(const int y, const int z)
{
X xx;
xx.m_x = y + z;
return xx;
}
int main()
{
X xxx = bar(1, 2);
}
可以看到像实参一样将 xxx 的地址进行了压栈

可以看到,这里的 xx 的值实际就是 xxx 的地址,然后调用了默认构造函数,就是相当于xxx.X::X()

VS2022貌似默认就算未有明确定义的拷贝构造函数,也会进行NRV优化,看下面这个case
#include <iostream>
class test {
friend test foo(double);
public:
test()
{
memset(array, 0, 100 * sizeof(double));
}
private:
double array[100];
};
test foo(double val)
{
test local;
local.array[0] = val;
local.array[99] = val;
return local;
}
int main()
{
for (int cnt = 0; cnt < 100000000; cnt++)
{
test t = foo(double(cnt));
}
return 0;
}
这里可以看到 ebp-334h 就等于 &t
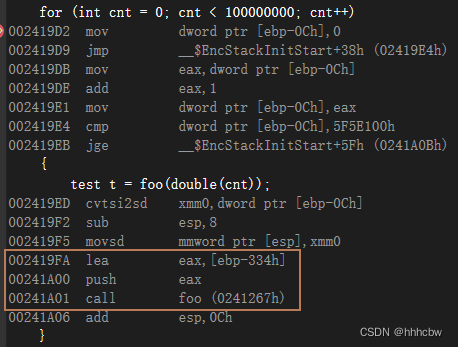

且 foo 函数中的 local 可以看到就是 t 的地址,说明进行了 NRV 优化

NRV优化的弊端
虽然NRV优化提供了重要的效率改善,还是有有一些弊端:
- 优化由编译器默默完成,而它是否真的被完成,并不十分清楚(因为很少由编译器会说明其实现程度,或是否实现)。
- 一旦函数变得比较复杂,优化也就变得比较难以施行。在 cfront 中,只有当所有的 named return 指令句发生于函数的 top level 时,优化才施行。如果导入 “a nested local block with a return statement”,cfront 就会静静地将优化关闭
- NRV 优化可能会带来意想不到的问题
第三点,可以考虑下面这个case,我们在上面的 test 类中,加入一个类静态变量 count,其初始值为 0,加入一个析构函数
~test()
{
count++;
}
最后输出这个 test::cout,完整代码如下:
#include <iostream>
using namespace std;
class test {
friend test foo(double);
public:
static int count;
test()
{
memset(array, 0, 100 * sizeof(double));
}
~test()
{
count++;
}
private:
double array[100];
};
int test::count = 0;
test foo(double val)
{
test local;
local.array[0] = val;
local.array[99] = val;
return local;
}
int main()
{
for (int cnt = 0; cnt < 100000000; cnt++)
{
test t = foo(double(cnt));
}
cout << test::count << endl;
return 0;
}
正常不被NRV优化,我们期望的应该是 200000000,但实际输出了 100000000

参考资料
《深度探索C++对象模型》—— Stanley B.Lippman著,侯捷译