论文地址:https://arxiv.org/abs/2404.10518
代码地址:https://github.com/tensorflow/models/blob/master/official/vision/modeling/backbones/mobilenet.py
解决了什么问题?
边端设备的高效神经网络不仅能带来实时交互的体验,也会减少公网上个人数据的传输。但是,移动设备的算力限制很难平衡准确率和效率。
提出了什么方法?
MobileNetV4 是针对移动设备设计的高效通用的模型架构。其核心是 Universal Inverted Bottleneck(UIB)、ConvNext、FFN 和一个新的 Extra Depthwise 变种模块。除了 UIB,作者提出了 Mobile MQA,它是针对移动加速器设计的一个注意力模块,能提速 39 % 39\% 39%。此外,作者为了提升 MNv4 的搜索效率,使用了 NAS 方法。整合 UIB、Mobile MQA 和 NAS 后,MNv4 模型在移动 CPU、GPU、DSP 、苹果神经引擎及谷歌 Pixel EdgeTPU 上接近帕累托最优。作者也提出了一个新的蒸馏方法。MNv4-Hybrid-Large 模型在 ImageNet-1K 上取得了 87 % 87\% 87% 的准确率,在 Pixel 8 EdgeTPU 的运行时间仅为 3.8 毫秒。
UIB 模块通过融合两个可选的深度卷积,改进了 Inverted Bottleneck 模块。尽管很简洁,UIB 整合了 Inverse Bottleneck、ConvNext 和 FFN,引入了 Extra Depthwise IB 模块。UIB 在空间和通道混合方面提供了灵活性,扩展了感受野和计算效率。
在移动加速器上,针对多头注意力,Mobile MQA 取得了 39 % 39\% 39% 的加速。
两阶段 NAS 方法进行粗粒度和细粒度的搜索,极大地提升了搜索效率,可以创造出比以前 SOTA 模型大得多的模型。此外,融入离线蒸馏数据集后,可以降低 NAS 的噪声,提高模型质量。
Hardware-Independent Pareto Efficiency

Roofline Model
要想一个模型能够足够地通用高效,无论模型搭载什么样的 bottlenecks,它都能在各种硬件平台上表现良好。这些 bottlenecks 基本是由硬件的峰值计算吞吐和峰值内存带宽决定的。
作者使用 Roofline 模型来估计给定负载下的表现,预测它是否是内存瓶颈或计算瓶颈。简言之,它涵盖了硬件的一些细节信息,只考虑负载的运算强度( LayerMACs i / ( WeightBytes i i + ActivationBytes i ) \text{LayerMACs}_i / (\text{WeightBytes}_ii + \text{ActivationBytes}_i) LayerMACsi/(WeightBytesii+ActivationBytesi)) vs. \text{vs.} vs. 硬件处理器和内存的理论上限。内存和计算操作基本是并行的,这两项的速度基本决定了延迟瓶颈。为了将 Roofline 模型应用到神经网络(层索引用 i i i表示),我们可以计算模型的推理速度,ModelTime:
ModelTime = ∑ i max ( MACTime i , MemTime i ) \text{ModelTime} = \sum_i \max{(\text{MACTime}_i, \text{MemTime}_i)} ModelTime=i∑max(MACTimei,MemTimei)
MACTime i = LayerMACs i PeakMACs , MemTime i = WeightBytes i + ActivationBytes i PeakMemBW \text{MACTime}_i=\frac{\text{LayerMACs}_i}{\text{PeakMACs}}, \quad \quad \text{MemTime}_i=\frac{\text{WeightBytes}_i + \text{ActivationBytes}_i}{\text{PeakMemBW}} MACTimei=PeakMACsLayerMACsi,MemTimei=PeakMemBWWeightBytesi+ActivationBytesi
在 Roofline 模型中,硬件行为可以总结为 Ridge Point,即硬件 PeakMACs 和 PeakMemBW 的比值,取得最优表现所需的最低计算强度。Roofline 模型只取决于用于计算的数据传输的比值,从延迟的角度来说,相同 RP 的硬件的负载就是相同的。
Ridge Point Sweep Analysis
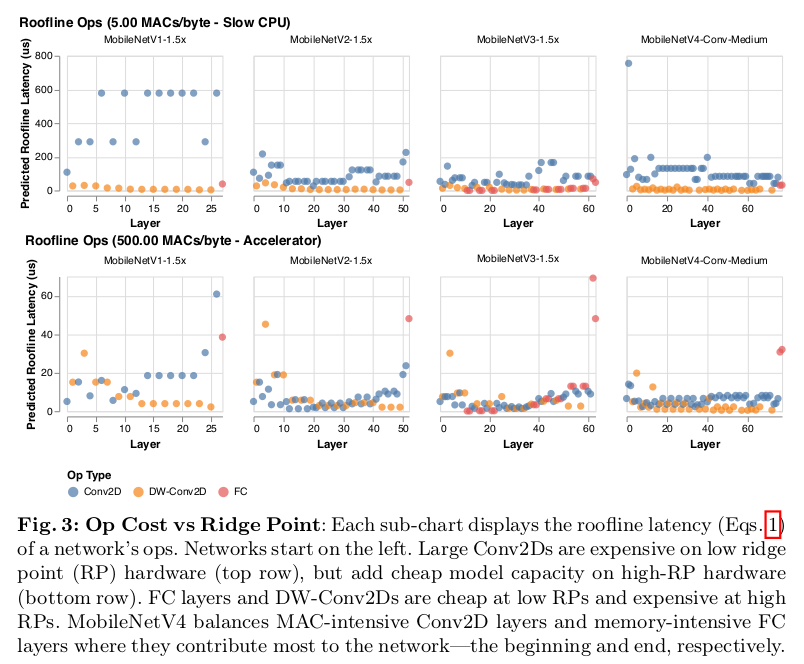
Roofline 模型阐明了 MobileNetV4 如何相对于其它 MobileNets 实现帕累托最优表现的。在低 PR 硬件上(如 CPU),模型更可能受限于算力,而非内存;因此为了改善延迟,我们要尽可能降低 MACs,哪怕会增加内存复杂度(MobileNetV3Large-1.5x)。在高 RP 设备上,数据移动是一大瓶颈,因此 MACs 不会降低模型的速度,但会增加模型的能力(MobileNetV1-1.5x)。因此,针对低 RP 优化的模型跑在高 RP 的设备上就会比较慢;因为对于内存占用高但 MAC 低的全连接层,内存带宽就成了一个瓶颈,它无法利用高可用的 PeakMACs。
MobileNetV4 设计
MobileNetV4 平衡了 MACs 和内存带宽投入,提供最高的投资回报比,尤其关注在网络的开始和结束位置。在网络的开始,MobileNetV4 使用了较大且昂贵的初始层,提升模型的表现和下游准确率。这些初始层的 MACs 比较高,因此只在低 PR 设备上比较昂贵。在网络的末尾,MobileNetV4 使用相同大小的 FC 层,最大化准确率,尽管这会造成 MNV4 变种在高 RP 设备上也要面对高 FC 延迟。初始卷积层大,在低 RP 设备上比较昂贵,但在高 RP 设备上并不昂贵。最后的全连接层在高 RP 设备上比较昂贵,但在低 RP 设备上并不昂贵。MobileNetV4 模型不会同时遇到二者同时出现性能下降。换句话说,MNv4模型能够使用昂贵的层,这些层虽然会不成比例地提高准确性,但不会同时承受这些层的联合成本,从而在所有ridge points(可能指特定的性能评估点或模型参数设置点)上主要实现了帕累托最优性能。
Universal Inverted Bottleneck
本文提出了 UIB 模块,可灵活地适配构建各种优化目标的高效模型,无需复杂的搜索。UIB 扩展了MobileNetV2 的 inverted bottleneck。
MobileNet 最成功的组成就是 depthwise conv 和 pointwise expansion and projection (扩展和映射层)倒转瓶颈结构,本文介绍了一个新的模块 UIB,如下图所示。该结果非常简单。作者在 inverted bottleneck 模块中引入了两个可选的深度卷积,一个在扩展层之前,一个在扩展和映射层之间。NAS 优化中研究了这些深度卷积的作用。尽管改动不大,该模块很好地整合了现有的关键模块,包括 IB 模块、ConvNeXt 模块和 FFN 模块。此外,UIB 提出了一个新的变种:Extra depthwise IB 模块。
作者避免了像 EfficientNet 中那样的人工缩放规则,单独根据每个模型的尺寸做优化。为了避免 NAS SuperNet 的太庞大,作者共享了常用的模块(pointwise expansion and projection),只将深度卷积作为额外的搜索项。

UIB 实例化 UIB 模块中有两个可选的深度卷积,这样就有四个可能的结果。
Inverted Bottleneck 在扩展后的特征激活图上进行空间混合,成本增加且能提供更强的模型能力。
ConvNeXt 在扩展之前进行空间混合,允许用更大的卷积核做更廉价的空间混合。
ExtraDW 是本文提出的新变种,可以较低的代价增加网络的深度和感受野。
FFN 是两个
1
×
1
1\times 1
1×1 pointwise conv,包含了激活函数和归一化层。PW 是对加速器最友好的操作。
在每个网络阶段,UIB 为下面三点提供了灵活性:
- 特定的空间和通道混合
- 增大感受野
- 最大化算力利用率
Mobile MQA
这部分介绍了 Mobile MQA,一个针对加速器特别优化的新注意力模块,能提速 39 % 39\% 39%。
Importance of operational intensity
最近的研究大多关注在降低 MACs(算术运算) 上,以提高效率。但是,移动加速器的真正瓶颈通常不是算力,而是内存进入。这是因为加速器能提供远超内存贷款的强大算力。因此,仅缩小 MAC 不会带来更好的性能。我们必须考虑 operation intensity,算术运算和内存进入的比值。
在混合模型中 MQA 很高效
MHSA 将 queries, keys, values 映射到多个空间,获取不同角度的信息。Multi-query attention 通过在多头中共享 keys 和 values 简化了这个操作。Multi-query heads 很重要,大语言模型能有效地共享一个 keys 和 values 的头,不会牺牲准确率。Keys 和 values 的共享头极大地降低了内存进入的需要,当 tokens 的个数低于特征维度时,从而提升了 operational intensity。这就很适合移动设备的混合视觉模型,因为注意力只用于网络的低分辨率的后期阶段,这时候特征维度很高,batch size 通常为
1
1
1。
Incorporate asymmetric spatial down-sampling
受到 MQA 启发,它对 queries, keys, values 使用了非对称的计算,作者在优化的 MQA 中加入了空间降维注意力(spatial reduction attention),缩小 keys 和 values 的分辨率,但保持高分辨率的 queries。通过非对称的空间下采样,作者保持了输入和输出之间的 token 数量,保留了注意力的高分辨率,提高了效率。该方法将
AvgPooling
\text{AvgPooling}
AvgPooling 替换成了一个步长为
2
2
2的
3
×
3
3\times 3
3×3深度卷积,做空间下采样。
Mobile MQA
Mobile_MQA ( X ) = Concat ( attention 1 , . . . , attention n ) W O \text{Mobile\_MQA}(\bm{X})=\text{Concat}(\text{attention}_1,...,\text{attention}_n)\bm{W}^O Mobile_MQA(X)=Concat(attention1,...,attentionn)WO
其中, attention j = softmax ( ( X W Q j ) ( S R ( X ) W K ) T d k ) ( S R ( X ) W V ) \text{attention}_j=\text{softmax}(\frac{(\bm{XW}^{Q_j})(SR(\bm{X})\bm{W}^K)^T}{\sqrt{d_k}})(SR(\bm{X})\bm{W}^V) attentionj=softmax(dk(XWQj)(SR(X)WK)T)(SR(X)WV)
S R SR SR 可以是空间下采样,或者该方案中使用的步长为 2 2 2 的 D W DW DW ,或者恒等映射函数(如果没有做空间下采样)。
Design of MNv4 Models
设计思想:简洁、高效
设计 MobileNets 的核心目标就是在不同的移动设备上实现帕累托最优。为此,作者进行了广泛的模型和硬件设备的关系分析。
该研究发现了以下几点洞见:
- 多路径效率的顾虑:分组卷积类似于多路径设计,虽然 FLOPs 低,但由于内存进入复杂度高,分组卷积效率并不低。
- 硬件支持顾虑:DSP 没有很好地支持像 SE、GELU、LayerNorm 这样的操作,LayerNorm 比 BN 慢,SE 在加速器上速度慢。
- 简洁性考虑:Depthwise and pointwise 卷积、RELU、BN 和简单的注意力展现了优异的性能和硬件兼容性。
基于这些发现,作者构建了下述设计原则:
- 标准组件:作者优先支持广泛使用的算子,从而实现流畅的部署和硬件高效率。
- 灵活的 UIB 模块:新的 UIB 模块允许自适应的空间和通道混合,修正感受野,最大化算力利用,通过 NAS 更好地平衡效率和准确率。
Refining NAS for Enhanced Architectures
为了有效地实例化 UIB 模块,作者改良了 TuNAS 以提升模型表现。
Enhanced Search Strategy
该方法通过两阶段的搜索,缓解了 TuNAS 对小滤波器和扩展系数的偏见。该策略解决了 UIB 深度层和其它搜索选项之间参数个数的差异问题。
Coarse-Grained Search:开始时我们关注在找到最优的滤波器大小上,并保持固定的参数:一个 inverted bottleneck 模块,扩展系数默认为
4
4
4,深度卷积核是
3
×
3
3\times 3
3×3。
Fine-Grained Search:有了上一步的搜索结果,我们搜索 UIB 两个深度层的配置项(包括它们是否参与,卷积核大小是
3
×
3
3\times 3
3×3或
5
×
5
5\times 5
5×5),扩展系数为常数
4
4
4。
Enhancing TuNAS with Robust Training
TuNAS 的成功主要是因为能准确地评估模型架构的质量,这对奖励计算和策略学习很重要。TuNAS 使用 ImageNet-1K 训练 SuperNet,模型的表现受到数据增强、正则和超参选取影响。给定 TuNAS 不断进化的网络架构,找到最优的超参是很有挑战的。
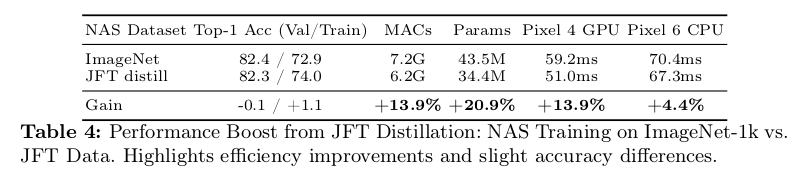
作者通过一个离线的蒸馏数据集解决了这个问题,无需额外的数据增强,降低了正则和优化设定对模型的影响。作者使用了 JFT 蒸馏数据集。作者认为 depth-scaled 模型要比 width-scaled 模型更优异,于是将 TuNAS 训练增加到了 750 个epochs,这样模型更深、表现更优。



![制造企业如何打造客户服务核心竞争力?[AMT企源典型案例]](https://img-blog.csdnimg.cn/direct/5292314e9dbb41c9a5151a991c653594.jpeg)