Llama 开源吗?
我在写《有趣的大模型之我见 | Mistral 7B 和 Mixtral 8x7B》时曾犹豫,在开源这个事儿上,到底哪个大模型算鼻祖?2023 年 7 月 18 日,Meta 推出了最受欢迎的大型语言模型(LLM)的第二个版本-Llama 2,并主张可免费用于研究和商业用途。Llama 2 模型附带许可证,允许社区使用、复制、分发、创作由 Meta 发布的 Llama Materials 的衍生作品和进行修改。Llama 2 可以被下载并在应用程序中使用,也可以通过 Hugging Face**、Amazon Web Services 或 Microsoft Azure 等服务租用。然而它的开源属性却被严重质疑,原因是授权许可受到来自 Meta 的诸多限制,比如:Meta 可以自行决定向申请者授予许可,除非或直到 Meta 明确授予此类权利,否则无权行使本协议规定的任何权利。再比如:不得使用 Llama Materials 或 Llama Materials 的任何输出或结果来改进任何其他大型语言模型(不包括 Llama 2 或其衍生作品)。这意味着不能使用 Llama 2 生成用于构建或微调任何其他模型的训练数据,这是一个更大的问题,因为很多人可能想这样做。开源不仅意味着源代码的可访问性,还意味着对协作、透明度和社区驱动开发的承诺。开发者们认为 Llama 2 的开源许可是 Meta 自己的许可,而那些限制是为了保护 Meta 的市场份额而精心设计的限制。
亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库!
2024 年 4 月 18 日发布的 Llama 3 也将继续延用之前“负责任”的开放方式。
关于 Meta、Meta AI 和 Llama
Meta,前身 Facebook Reality Labs,是 Facebook 旗下的研究实验室,专注于探索和开发增强现实和虚拟现实技术。Meta 最初的目标是构建一个能够让人们以全新方式相互连接和互动的虚拟现实世界,也就是我们所说的“元宇宙”。为了全面拥抱“元宇宙”,2021 年 10 月 28 日,Facebook CEO 扎克伯格在公司一年一度的虚拟现实大会 Connect Conference 上宣布,Facebook 公司改名为 Meta。
除了元宇宙,Meta AI 的布局从十年前就开始了,其成果也没有在这股 AI 的浪潮中掉队。从招募 Yann LeCun 等顶级 AI 学者加入,到主导的深度学习框架 PyTorch 被广泛使用,势头曾一度碾压谷歌的 TensorFlow,再到发布大语言模型 Llama。
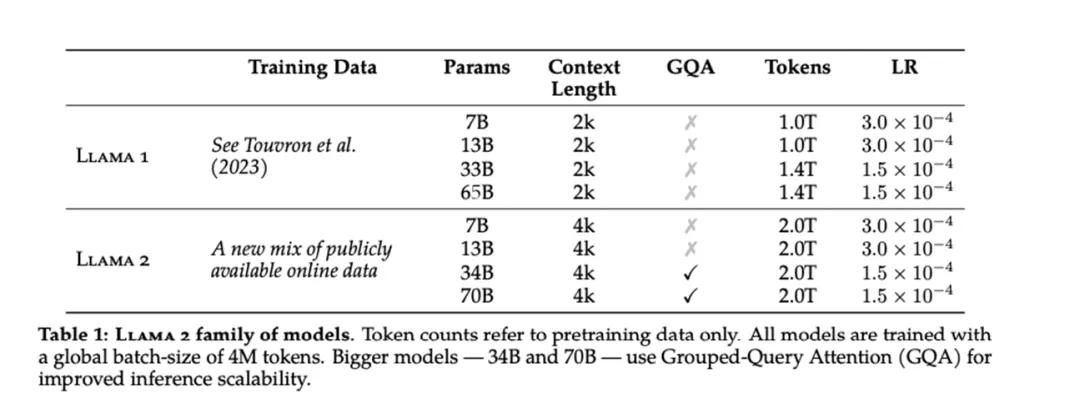
Llama 2 是 Llama 的第二个版本。除了可以免费下载,并且在这里 Meta 用一篇 77 页的 PDF 介绍了它的技术细节。与 Llama 1 的发布一样,Llama 2 的预训练版本有多种尺寸:7B、13B 和 70B 参数。(Meta 还训练了一个 34B 参数 Llama 2 模型,但没有发布它。)参数值越大,模型越准确。参数大小越大,表示模型使用大量语料库进行训练,从而得到更准确、更可靠的响应。与 Llama 1 不同,Llama 2 提供了对话增强版本的 Llama-Chat 和代码增强版本 Code Llama,供开发者和研究人员使用。
- 技术细节
https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/?trk=cndc-detail
Llama 2 模型是根据各种公开的在线数据进行训练的,训练数据较 Llama 1 扩大了 40%,达到 2 万亿个 token,并且可处理的上下文长度增倍,达到 4096 个 token。整体 finetuning 过程使用了 1 百万人工标记数据。
Llama 3 于 2024 年 4 月 18 日正式发布,目前提供 8B 和 70B 两个版本,8k 上下文长度。在定制的 24k GPU 集群上使用 15 万亿个 broken 进行训练。并在计划未来几个月推出更多版本。其实今年 1 月,Meta CEO 马克·扎克伯格在 Instagram 视频中宣布,Meta AI 已经开始训练 Llama 3。
在 Instagram 视频中,小扎就表示,预计到 2024 年底,Meta 将拥有 350000 块英伟达 H100,算上其他算力资源将达到近 600000 块 H100。言下之意,Meta 有足够的 AI 算力资源来支持 Llama 3 的大规模预训练以及生成式 AI 的技术研究。如今大模型普遍转向多模态大模型的研究,Meta 也不例外。小扎虽然只确认 Llama 3 和 Llama 2 一样将包含代码生成功能,并没有明确提及其他多模式功能,不过他在官宣视频谈到了人工智能与元宇宙相结合的设想,再加上这次 Llama 3 发布时 Meta 曾表示,最终的 Llama 3 模型是多模态的。大胆猜测,有了元宇宙领域的丰厚积累,Meta 的 AI 模型同时具备自然语言理解、视觉和听觉能力指日可待。Meta 的目标还在于使模型具有更大的“上下文窗口”,这意味着可以为它们提供充足的数据进行分析或汇总。(事实证明,更大的上下文窗口可以降低模型的幻觉率,或者降低模型根据提示输出不准确信息的频率。)根据 Meta 的说法,Llama 3 也将改进推理和编码能力。
总之,我理解这是两个较小的版本,更准确地说,Meta 在其新的 Llama 3 系列中首次亮相了两款模型,其余的将在未来日期上市。
虽然只是最初的两个版本,但 Meta 指出,与上一个版本 Llama 2 相比,Llama 3 在性能方面是“重大飞跃”。Meta 表示,后期训练程序的改进大大降低了错误拒绝率,提高了对齐度,并增加了模型响应的多样性。同时,Llama 3 在推理、代码生成和指令跟踪等能力也有了很大提高,这使得 Llama 3 的可操控性更强。就各自的参数数量而言,在两个定制的 24,000 个 GPU 集群上训练的 Llama 3 8B 和 Llama 3 70B 是当今性能最好的生成人工智能模型之一。
听起来起来不错,那让我们一起看一下 Llama 3 在人工智能 benchmark 的分数,例如 MMLU(试图衡量知识)、ARC(试图衡量技能习得)和 DROP(在大块文本上测试模型的推理)。

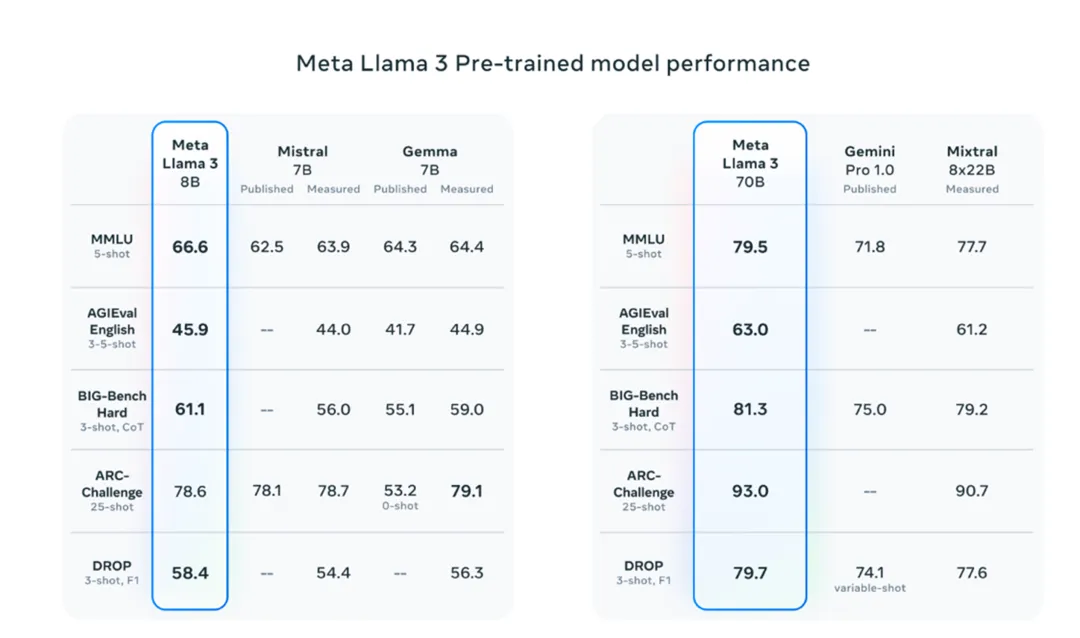
图片来源:https://ai.meta.com/blog/meta-llama-3/
Llama 3 8B 在至少九个基准测试中击败了其他开放模型,例如 Mistral 的 Mistral 7B 和 Google 的 Gemma 7B,这两个模型都包含 70 亿参数:MMLU、ARC、DROP、GPQA(一组与生物、物理和化学相关的问题)、HumanEval(代码生成测试)、GSM-8K(数学单词问题)、math(另一个数学基准)、AgieVal(一组与生物、物理和化学相关的问题)、HumanEval(代码生成测试)、和 Big-Bench Hard(常识性推理评估)。现在,Mistral 7B 和 Gemma 7B 并不完全处于前沿(Mistral 7B 于去年 9 月发布),在 Meta 引用的一些基准测试中,Llama 3 8B 的得分仅比两者高出几个百分点。但是 Meta 声称,参数数量更大的版本 Llama 3 70B 在旗舰级别的 AI model 中具有竞争力,包括 google Gemini 系列最新版本的 Gemini 1.5 Pro。
Llama 3 70B 在 MMLU、HumanEval 和 GSM-8K 上击败了 Gemini 1.5 Pro,尽管它无法与 Anthropic 性能最高的机型 Claude 3 Opus 相提并论,但在五个基准(MMLU、GPQA、HumaneVal、GSM-8K 和 MATH)上,Llama 3 70B 的得分高于 Claude 3 系列中第二弱的模型 Claude 3 Sonnet。
Llama 的技术特点
Llama 2 和初代模型相比,仍然延续 Transformer’s decoder-only 架构,仍然使用 Pre-normalization、SwiGLU 激活函数、旋转嵌入编码(RoPE),区别仅在于前述的 40%↑ 的训练数据、更长的上下文和分组查询注意力机制(GQA, Grouped-Query Attention)。
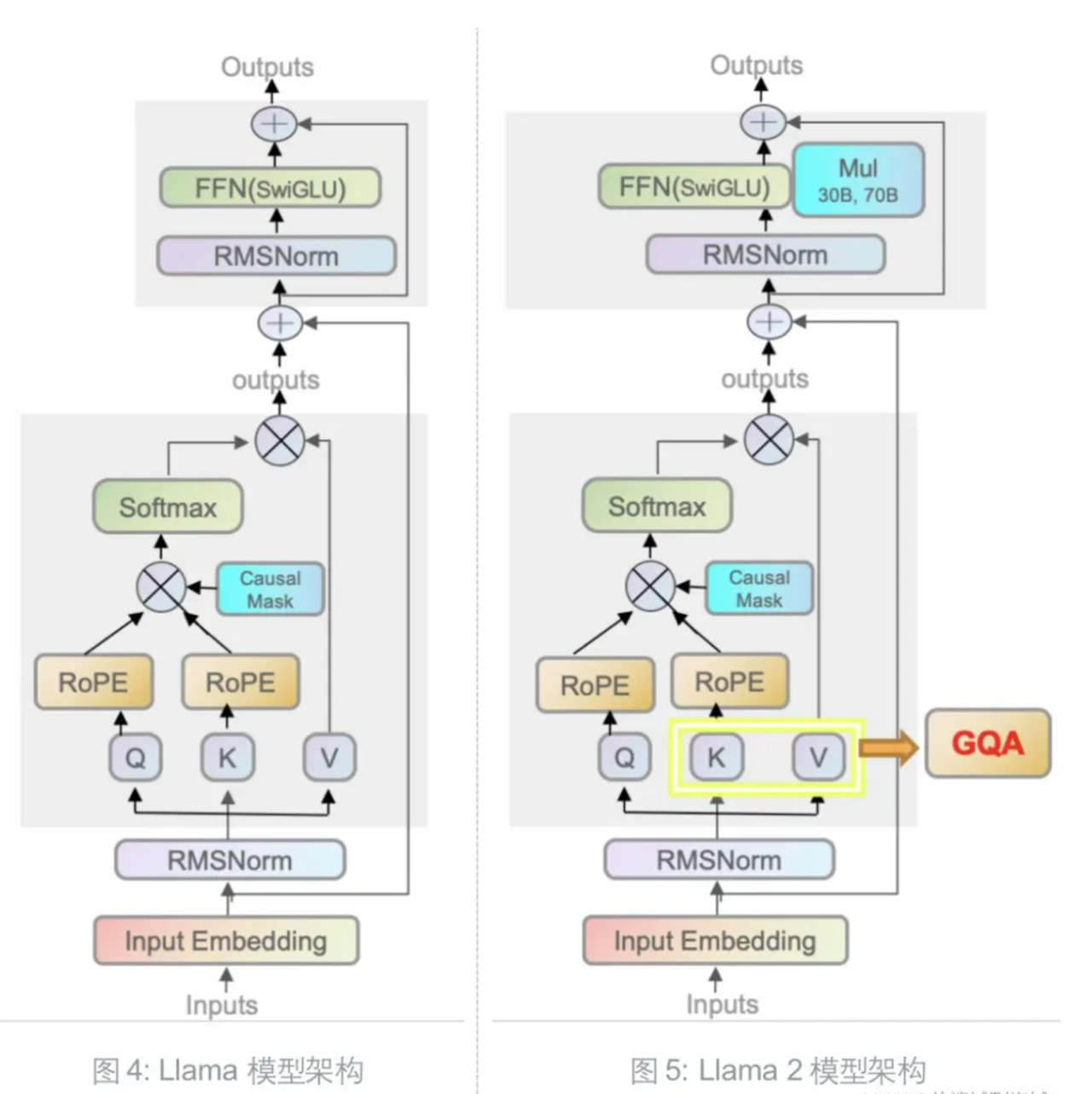
Group-Query Attention
引入 GQA 的主要目的是提升推理速度,这种注意力机制由 transformer 的 Multi-head Attention 简化而来,再辅以 KV cache 的 checkpoint 机制进一步提速。
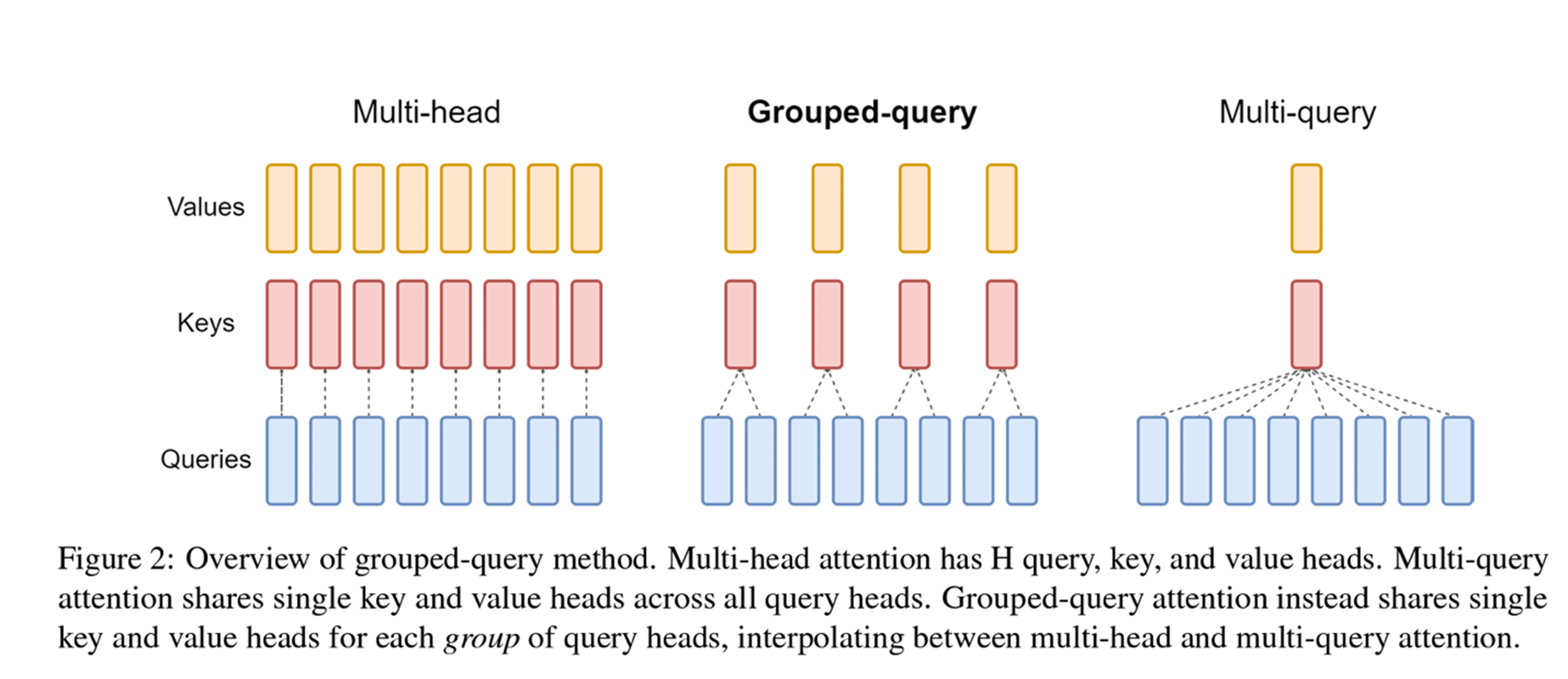
如上图:
- 左边是 transformer 原始的 Multi-head Attention,它有 H 个 query,key,value,即每个 query 单独配一个 key 和 value。
- 右边是其他研究者提出的 Multi-query Attention,它在多个 query 共享同一个 key 和 value。
- 中间则是折中的 Grouped-query Attention,它将 query 进行了分组,仅在组内共享同一个 key 和 value。
具体而言,Llama 2 使用了 8 组 KV 映射,即 GQA-8,实测效果上接近 MHA,推理速度上接近 MQA,尽可能做到了效果和速度兼得。

Llama-chat 训练流程
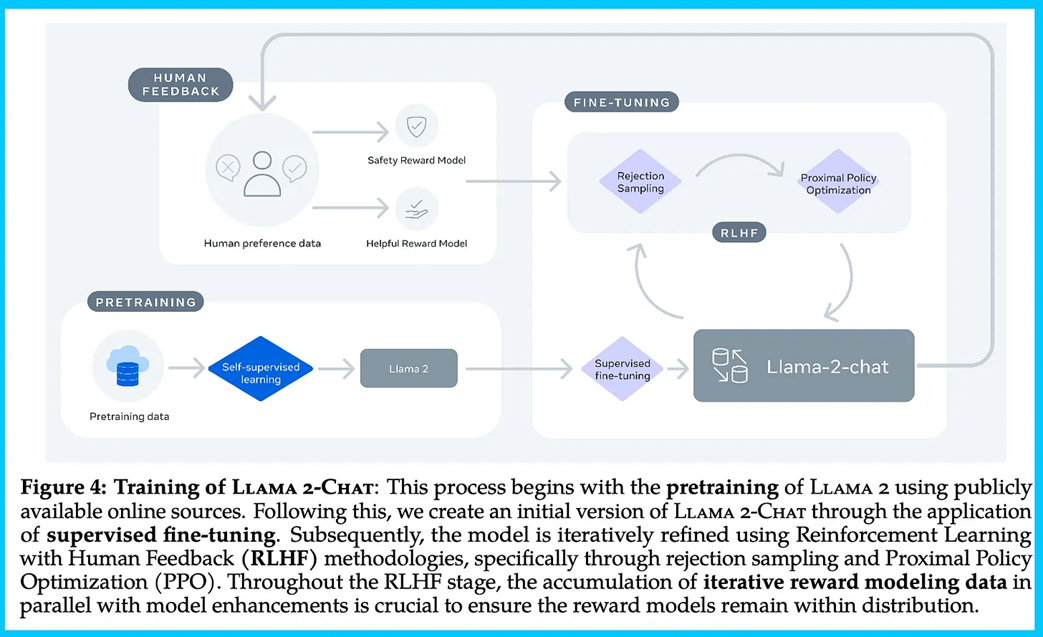
原技术论文详细的介绍了 Llama-chat 的训练流程。总结下来包括以下:
-
自监督预训练
-
监督精调
-
RLHF
a. 自人类偏好数据集中训练 2 个奖励模型,分别是 Safety Reward Model 和 Helpful Reward Model,一个用于对人类偏好进行奖励建模,一个对安全合规进行奖励建模。
b. 先使用 Helpful Reward 模型进行 RLHF,基于 Rejection Sampling 和 PPO。
c. 在 helpful 的基础上进一步提升安全性,使用 Safety Reward Model 进行 RLHF,也是基于 Reject Sampling 和 PPO,实验证明,Safety RLHF 能在不损害 helpfulness 的前提下有更好的长尾 safety 棒性。
- 原技术论文
https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/?trk=cndc-detail
重要的细节上:
- PPO(Proximal Policy Optimization),即标准的 RLHF 使用的方法。
- Rejection Sampling fine-tuning(拒绝采样微调):采样模型的 k 个输出,并选择奖励模型认为最好的样本作为输出进行梯度更新。
两种 RL 算法的区别是:
- 广度上:PPO 仅进行一次生成;Reject Sampling 会生成 k 个样本,从中选取奖励最大化的样本。
- 深度上:PPO 的第 t 步训练过程的样本是 t-1 步更新的模型策略函数;Reject Sampling 的训练过程相当于对模型当前策略下的所有输出进行采样,相当于是构建了一个新的数据集,然后在进行类似于 SFT 的微调。
Meta 仅在最大的 Llama 2 70B 使用了 Reject Sampling,其余模型仅使用了 PPO。
Code-Llama
2023 年 8 月 24 日,Meta 推出了面向代码的可商用代码大模型 Code Llama,包括 7B/13B/34B,支持多种编程语言,包括 Python、C++、Java、PHP、Typescript (Javascript)、C# 和 Bash。2024 年 1 月 9 日推出了更大、性能更好的 Code Llama 70B。
与之前发布的 Code Llama 模型一样,有三个版本,均可免费用于研究和商业用途:
- CodeLlama 70B,基础代码模型;
- CodeLlama 70B Python,专门用于 Python 的 70B;
- 以及 Code Llama 70B Instruct 70B,它针对理解自然语言指令进行了微调。
训练流程如图:
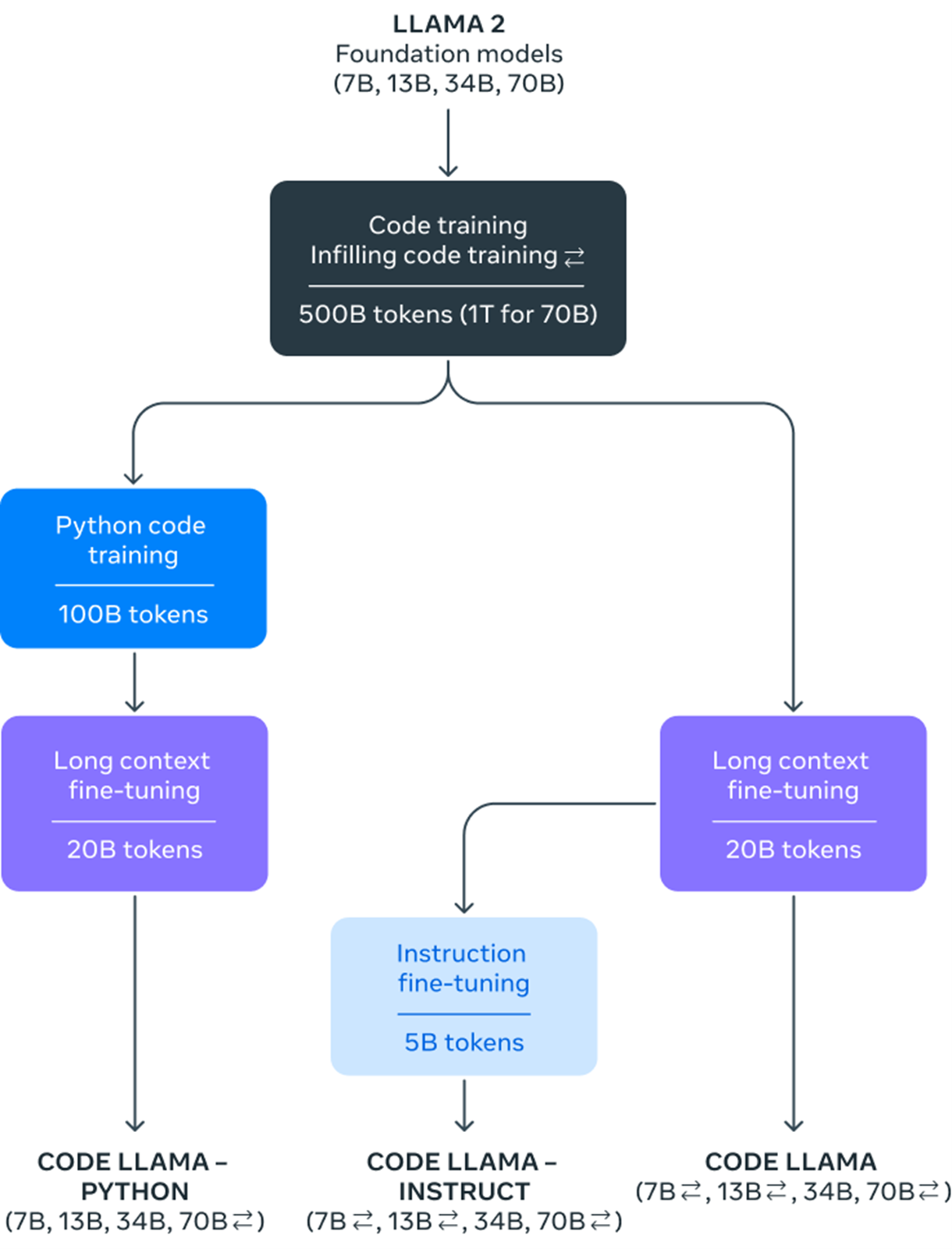
如图所示,包含 3 个分支模型,每个分支模型的第一步都是使用 500B 的 token 进行 Code Training 和 Infilling code training:
- Code Llama-Python(面向 python 语言的代码模型),第一步之后先用 100B token 的 python 代码进行训练,然后再使用 20B 的 token 在长上下文的场景上进行 finetuning 得到最终模型。
- Code Llama(通用代码模型),第一步之后使用 20B 的 token 在长上下文的场景上进行 finetuning 得到最终模型。
- Code Llama-Instruct(面向对话的代码模型),第一步之后同 Code Llama 使用 20B 的 token 在长上下文的场景上进行 finetuning,然后再在 5B 的 token 上进行指令精调。
参考白皮书,它的训练集详情如下:
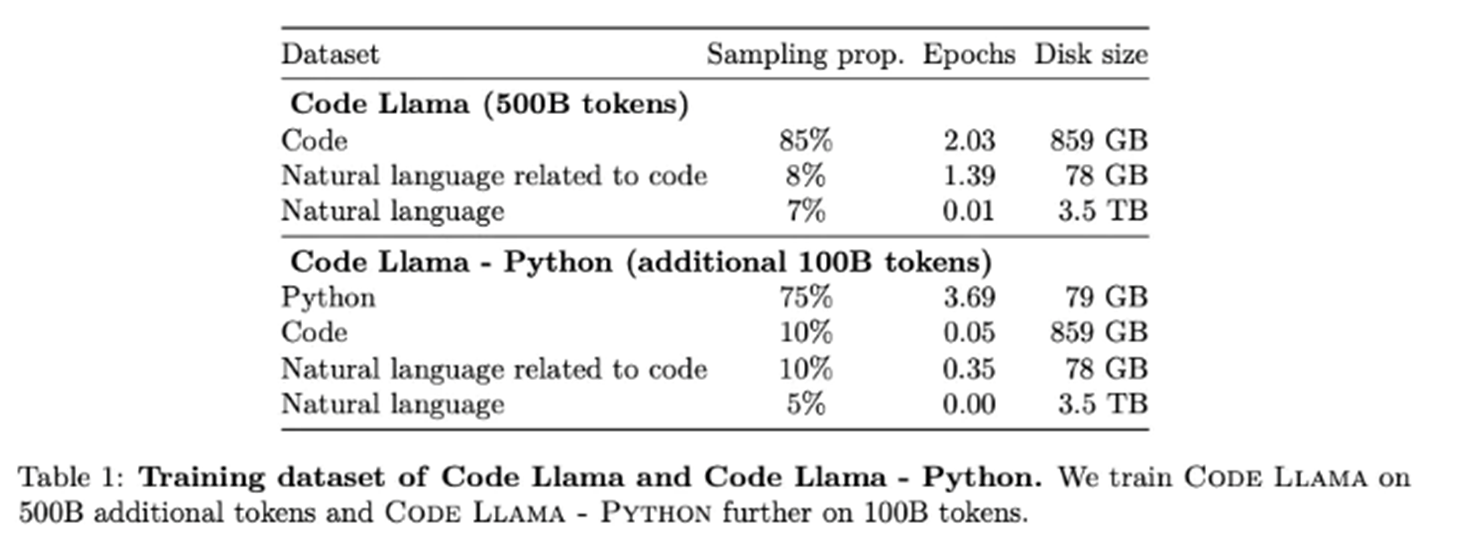
细节上:
-
Code Training 即使用代码数据进行训练。
-
Code Infilling 值得是根据代码上下文预测残缺的代码部分,仅针对代码文本进行挖空预测,方法与 Bert 的挖空预测类似:
a. 从完整的代码中选择一部分进行掩码(mask)并替换为符号,构成上下文作为输入。
b. 然后采用自回归的方式对 mask 进行预测。
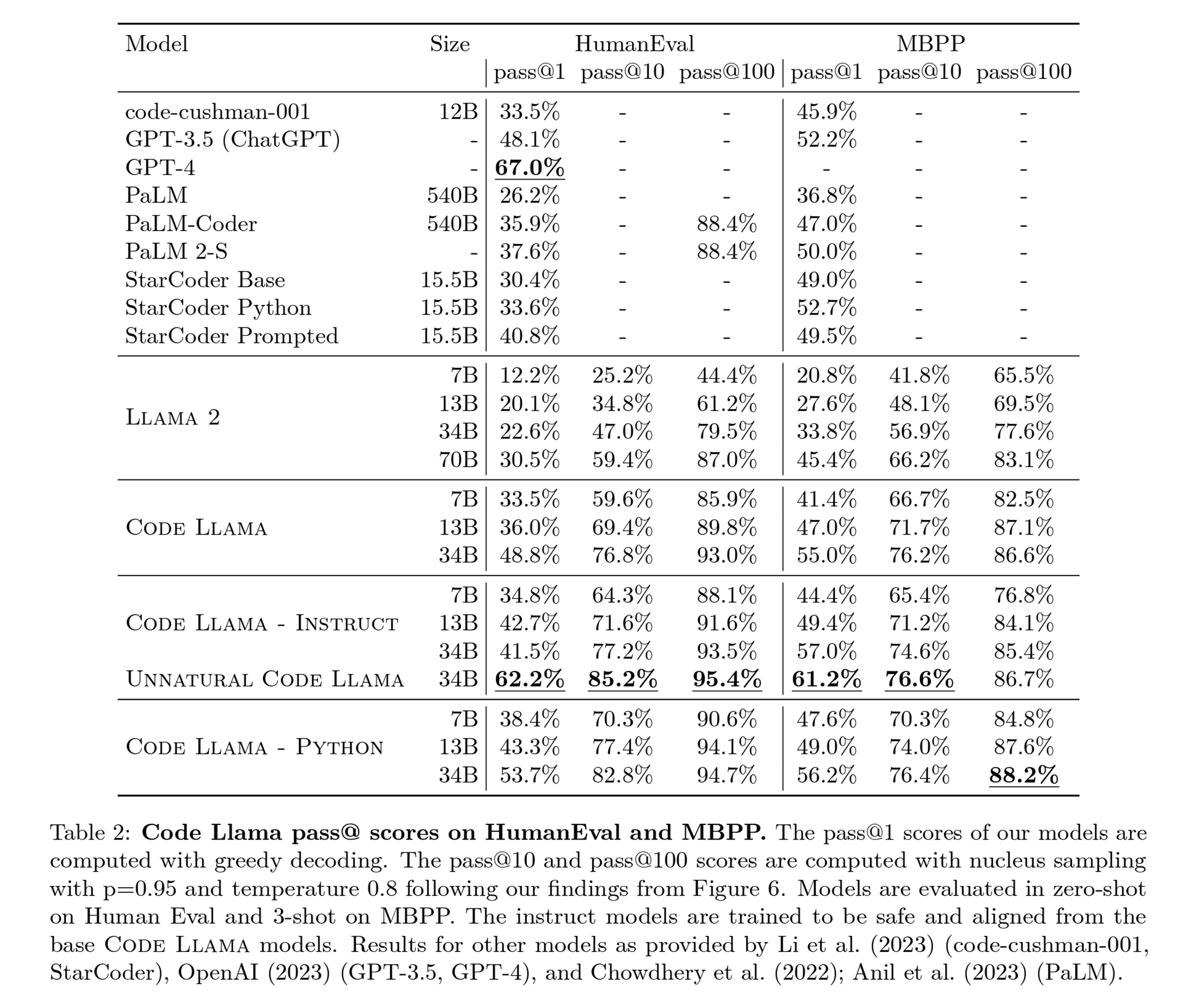
模型效果对比上:
神秘的 unnatural 版本在 HumanEval 的 pass@1 上领先 GPT-3,接近于 GPT-4(5% 左右差距),其余部分明显领先 PaLM 系列和 StarCoder 系列模型:
- 白皮书
https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/?trk=cndc-detail
由于 Llama 3 家族成员还没有全部面世,因此 Llama 3 详细的技术白皮书也会迟一些发布。根据 Meta 提供的技术博客来看,Llama 3 做了几项关键改进:
模型架构
Llama 3 选择了一个相对标准的纯解码器 Transformer 架构。相比 Llama 2 的改进之处有:Llama 3 使用一个包含 128K tokens 的分词器,可以更有效地编码语言,从而显著提高模型性能;在 8B 和 70B 两种规模上都采用了分组查询注意力(GQA)机制来提高模型推理效率;同时在 8192 个 tokens 的序列上训练模型,使用掩码确保自注意力不会跨越文档边界。
训练数据
Meta 认为训练出最佳 LLM 的关键是要整理一个大型高质量训练数据集,为此他们投入了大量资源:Llama 3 在超过 15 万亿个公开可用来源的 token 上进行了预训练,比训练 Llama 2 时的数据集足足大 7 倍,代码量是 Llama 2 的 4 倍。其中超过 5% 来自高质量非英语数据,总共涵盖了 30 多种语言,以为即将到来的多语言使用场景做准备。
Llama 3 团队开发了一系列数据过滤管道来保证数据质量。他们还进行了大量实验,来评估在最终预训练数据集中混合不同来源数据的最佳方式,以此来选择一个包括 STEM、编码、历史知识等等数据类别的最优数据组合,确保 Llama 3 在各种使用场景中表现良好。
扩大预训练规模
为了更有效利用预训练数据,Meta 针对下游基准评估开发了一系列详细的扩展法则,在实际训练模型之前就能预测最大模型在关键任务上的性能,来确保最终模型在各种使用场景和能力上都有出色的表现。
在 Llama 3 的开发过程中,团队也对扩展行为有了一些新的观察。例如,尽管一个 8B 参数模型对应的最佳训练计算量是 200B 个 tokens,但他们的 8B 和 70B 参数模型在接受高达 15 万亿个 token 训练后,性能仍然呈对数线性提高。
Meta 结合了三种并行化方式:数据并行、模型并行和管道并行,来训练最大的 Llama 3 模型。最高效地实现在同时使用 16K 个 GPU 训练时,每个 GPU 的计算利用率超过 400 TFLOPS。他们还开发了一个先进的新训练堆栈,可以自动进行错误检测、处理和维护,并进行了一系列硬件和可扩展存储系统的改进。最终使总体有效训练时间超过 95%,与 Llama 2 相比训练效率提升了约 3 倍。
指令微调方法创新
为了在聊天场景中充分释放预训练模型的潜力,Meta 也在指令微调方法上进行了创新。后训练方法采用监督微调(SFT)、拒绝采样、邻近策略优化(PPO)和直接策略优化(DPO)的组合。在模型质量上的最大改进来自于仔细整理的训练数据,并对人工标注人员提供的标注进行多轮质量保证。
通过 PPO 和 DPO 从偏好排序中学习,也大大提高了 Llama 3 在推理和编码任务上的性能。团队发现,当你问模型一个它难以回答的推理问题时,模型会产生正确的推理轨迹:知道如何得出正确答案,但不知道如何选择它。通过在偏好排序上进行训练,模型就能学会如何去选择正确答案。
如何在 Amazon Web Service 上运行 Llama AI 模型
在亚马逊云科技提供的 Amazon Bedrock 上轻松调用 Llama 2。
Amazon Bedrock 控制台页面
Amazon Bedrock 提供了一个单一的 API 接口,可连接各种先进的人工智能模型,例如 AI21 Labs、Anthropic、Cohere、Meta、Stability AI、Amazon 以及现在的 Mistral AI。
- Amazon Bedrock
Build Generative AI Applications with Foundation Models - Amazon Bedrock - AWS
要在 Amazon Web Services 账户中访问这些模型,需要执行以下操作:
- 在 Amazon Web Services console 中导航进入到 Amazon Bedrock 页面。Claude 模型已在俄勒冈州上线,因此确认选择“us-west-2”地区。(更多地区即将推出,请检查其他地区是否支持。)
- 展开左侧的菜单,向下滚动并选择“Model access(模型访问权限)”。
Amazon Bedrock Console Page-Menu
- 选择橙色的“Manage model acess/管理模型访问权限”按钮,然后向下滚动以查看新的 Meta AI 模型。点击你需要模型旁边的复选框,然后单击“save change/保存更改”。
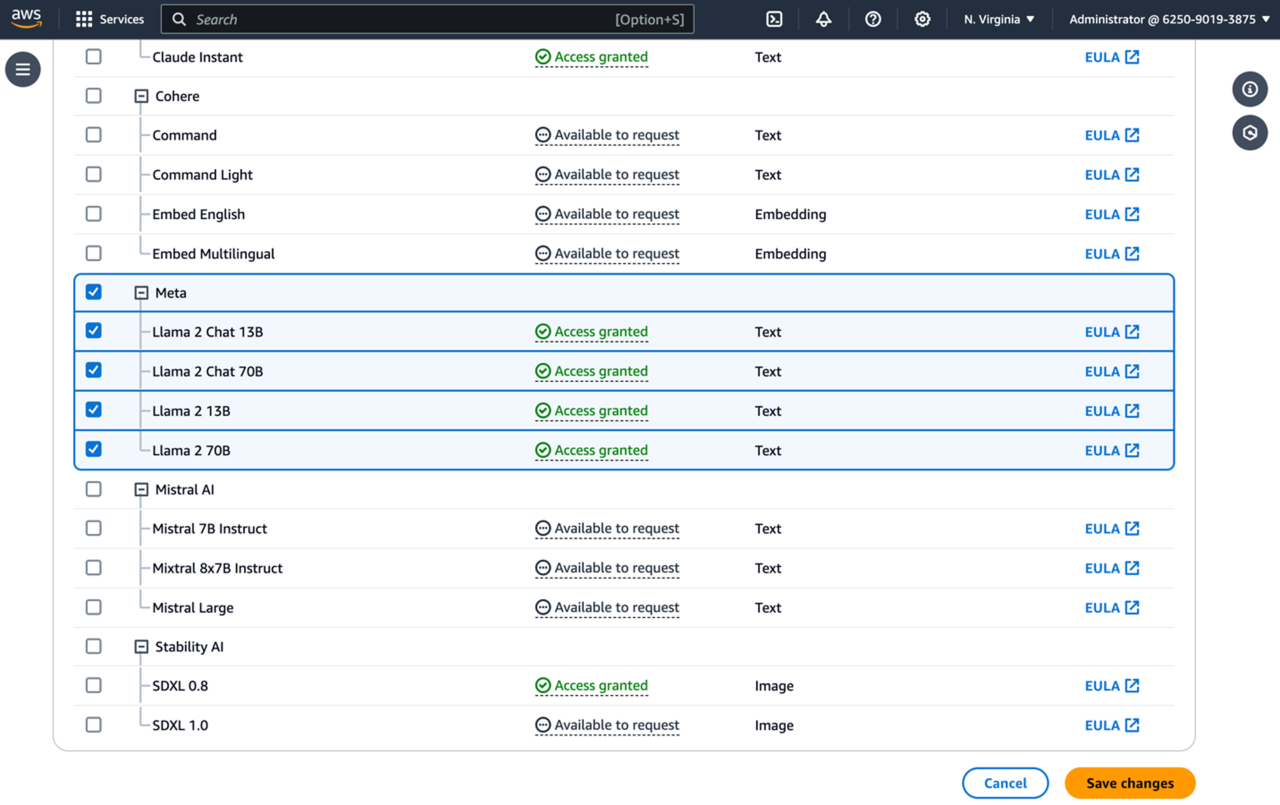
Amazon Bedrock-Model Access
您现在可以访问模型了!前往 Amazon Bedrock text playground,通过 prompt 开始你的体验。需要代码实现时,可以参考 Amazon SDK 代码示例。
- Amazon SDK 代码示例
Invoke the Mistral 7B model on Amazon Bedrock for text generation - AWS SDK Code Examples
Amazon SageMaker JumpStart 现在已经对 Meta Llama 3 提供支持
现在可以通过 SageMaker Studio UI 中的 SageMaker JumpStart 和 SageMaker Python SDK 访问基础模型。
SageMaker Studio 是一个集成开发环境(IDE),它提供了一个基于 Web 的可视化界面,可以访问专用工具来执行从准备数据到构建、训练和部署 ML 模型的所有 ML 开发步骤。有关如何开始和设置 SageMaker Studio 的详细信息,请参阅 Amazon SageMaker Studio。
在 SageMaker Studio 中,可以访问预建和自动解决方案下的 SageMaker JumpStart,其中包含预训练模型、笔记本和预建解决方案。具体的部署步骤参看博客。
Happy Prompt!
文章引用:
- https://juejin.cn/post/7303386068606386215?trk=cndc-detail
- https://ai.meta.com/?trk=cndc-detail
- Microsoft News

作者郑予彬
亚马逊云科技资深开发者布道师,软件工程硕士,超过 20 年 ICT 行业和数字化转型实践积累。现任亚马逊云科技资深开发者布道师,专注于云原生、云安全以及生成式 AI 的技术内容创建及推广。亚马逊云科技首位专注于开发者的女性技术布道者,活跃在全球中文开发者社区。18 年的架构师经验,专注为金融、教育、制造以及世界 500 强企业客户提供数据中心建设,软件定义数据中心等解决方案的咨询及技术落地。
文章来源:有趣的大模型之我见 | Llama AI Model