音频编解码技术的目标是,通过减少音频文件的大小来节省存储空间或减轻网络传输的负担。理想的情况下,即使音频被压缩,我们听到的声音与原版也应该没有任何区别。
过去,已经有不少编解码技术被开发出来,满足了这些需求,比如Opus和EVS这两种编解码器就很出名。
Opus是一个多才多艺的音频编解码器,它适用于各种应用,从视频会议(比如 Google Meet)到在线视频流(比如 YouTube)。Opus支持的压缩比率非常灵活,从每秒6千比特到每秒510千比特都可以。
而EVS,是由3GPP标准化组织针对移动电话>)开发的最新编解码器。它也支持不同的压缩比率,从每秒5.9千比特到每秒128千比特。使用Opus和EVS,我们能在中低比特率(每秒12-20千比特)下得到很高的音频质量,但是如果比特率太低(比如每秒小于3千比特),音质就会显著下降。
这些编解码器都是基于对人类听觉系统的深入了解和精心设计的信号处理流程来优化压缩效率的。但现在,研究人员开始探索使用机器学习技术来优化这一过程。
一个名为SoundStream的神经网络编解码器在这方面取得了突破。它不仅能处理语音和音乐,还能在智能手机的CPU上实时运行。SoundStream可以利用单个模型,在一个很宽的比特率范围内提供极高的音质,这是学习型编解码器一个重要的进步。
预备知识
音频基础
在音频编解码的世界里,有一个非常重要的概念叫做“比特率”,有时候也被叫做“码率”。这个概念告诉我们在每一秒钟内,有多少比特(数据的基本单位)被用来存储或传输音频。比特率的单位是bps,即每秒比特数。
在一段音频被压缩后,它的比特率会告诉我们这段压缩音频每秒钟包含多少比特。当我们提高了比特率,意味着我们用更多的比特来存储或传输同样长度的音频,这样相应的文件大小也就变大了。因此,如果我们说一个音频的压缩比特率很低,那通常也意味着我们把它压得非常紧,但这样可能会影响音质。
我们可以用一个简单的公式来计算比特率:比特率(以千比特每秒kbps计)等于文件大小(以千字节KB为单位)乘以8(因为1字节包含8比特),然后除以时间(秒)。举个例子,有一段24千赫兹(也就是采样率,表示每秒采样的次数),16位深度的PCM编码音频,它的比特率是384千比特每秒(kbps)。如果我们有一段这样的2秒音频文件,文件大小会是96千字节(KB),计算出来的比特率就是384千比特每秒。
在音频质量的评价中,我们通常会用到两个评分系统:MUSHRA分数和MOS(Mean Opinion Score,平均意见得分)分数。这两个得分系统都是用来评估人们听后对音频质量的主观感受。MUSHRA分数的一大优势在于,即使是少量的测试人员也能提供具有统计意义的结果。如果你想了解更多关于MUSHRA的信息,可以参考它的[维基百科页面](https://en.wikipedia.org/wiki/MUSHRA](https://en.wikipedia.org/wiki/MUSHRA)。
传统的音频编(解)码方法可以分为两大类:波形编(解)码和参数编(解)码。
波形编码(非参数编码)
波形编码,也叫非参数编码,其主要目标是让解码后的音频信号尽可能地与原始音频信号在波形形状上保持一致。这意味着波形编码尽力精确复现原音频的所有采样点,就像给音频做一个全面且详细的复印。
在波形编码的过程中,音频先从时间上的波形转换成频率上的表示形式,然后将这些频率内容进行量化(也就是根据一定的规则简化)和熵编码(一种根据数据内容复杂度来压缩数据的方法)。解码的时候,就是做相反的工作,从简化后的频率内容恢复还原成原始的时间波形。在量化的过程中,考虑到人耳对不同频率的敏感程度不一样,会根据这一心理声学原理分配不同的数据量给不同的频段。
波形编码不需要对音频内容是语音、音乐、噪声或是混响有任何特别的假设,它把音频信号看作普通的波形来处理,所以这种方法非常通用。为了获得高质量的音频,它通常需要较高的比特率(每秒16到64千比特),如果比特率太低,音质就会降低。
声码化编码(参数编码)
另一方面,声码化编码,也称为参数编码或模型编码,采用不同的策略。它对音频信号,尤其是语音信号,有一些特定的假设。通过使用一个参数化的模型,它引入了强有力的先验知识。编码器的工作是估计这个模型的参数并量化它们,而解码器则利用这些参数重建出音频波形。
与波形编码不同,声码化编码更关注音频信号重建后的感知相似度而不是每个采样点的准确度。重建出来的音频可能在波形上与原音比较不同,但目的是保留其语义。声码化编码的好处是比特率低,但缺点是音质通常不如波形编码自然,而且这种编码方式也比较敏感:在安静环境下的音质更好,在噪声较大的环境或信号有错误时音质下降。
总结这两种传统的音频编解码方式,都需要精心设计的信号处理流程和工程设计。要提高编码效果,还需要借助心理声学和语音合成领域的知识。现在,业界常用的编码器如Opus和EVS(增强语音服务),都是基于这些传统方法,并且能够确保在低延迟和实时通讯条件下,在多种内容、比特率和采样率下保持高效率的表现。
神经网络音频编解码
近些年,基于机器学习和深度学习的方法已经应用于音频编解码方向,主要分为以下两类思想:
-
作为音频解码器的后处理模块:比如,在现有音频解码器恢复出的音频基础上,使用音频超分(super-resolution)的方法扩展频带;或者使用音频降噪的思想去除编码损失带来的失真;或者使用丢包补偿的方法。
-
集成到音频编解码器中:语音合成中的神经网络声码器,可以自然地应用于音频编解码(同样是音频波形压缩到某一种低维特征,再从低维特征恢复生成原始的音频信息),不同的工作主要体现在模型结构的差异:WaveNet 使用的是全卷积结构,LPCNet 使用的是 WaveRNN,而 Google 2021 年 2 月提出的 Lyra 使用的是 WaveGRU,以上这些工作主要针对的都是低比特率的音频编解码场景。
SoundStream模型
SoundStream 编解码器是全卷积的网络结构。输入是原始的音频波形,Encoder 将其映射为较低采样率的 embedding 序列,RVQ 残差向量器对 embedding 序列进行量化;Decoder 输入是量化的 embedding,预测目标是恢复原始波形。
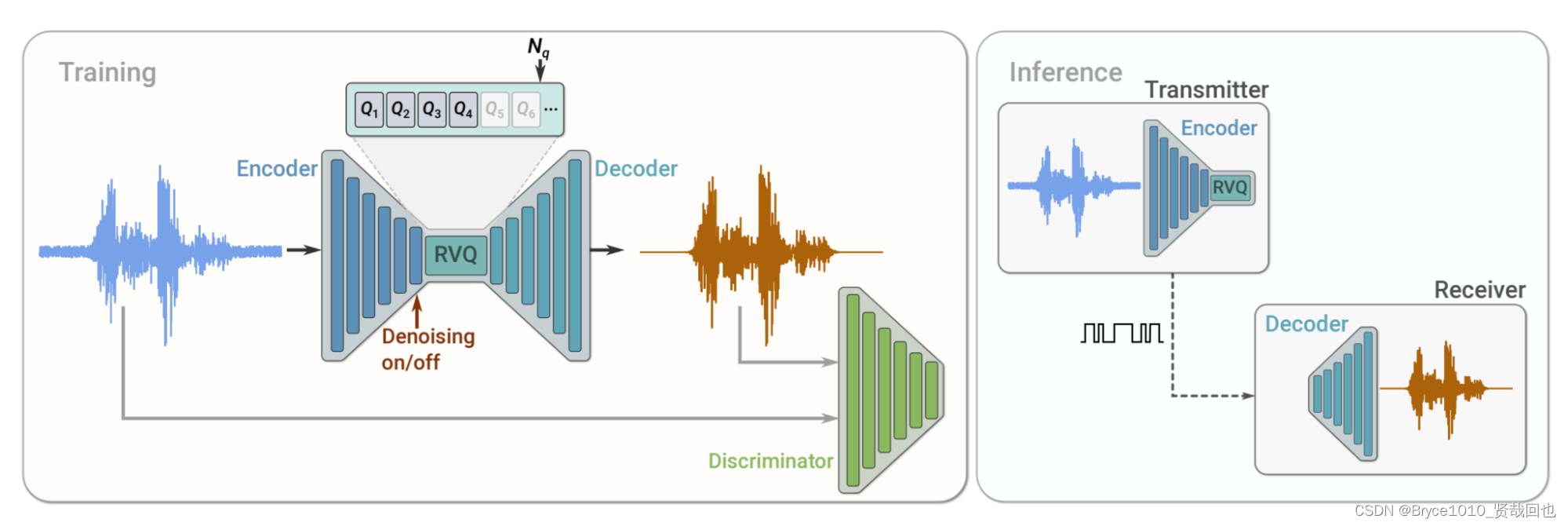
编码器结构
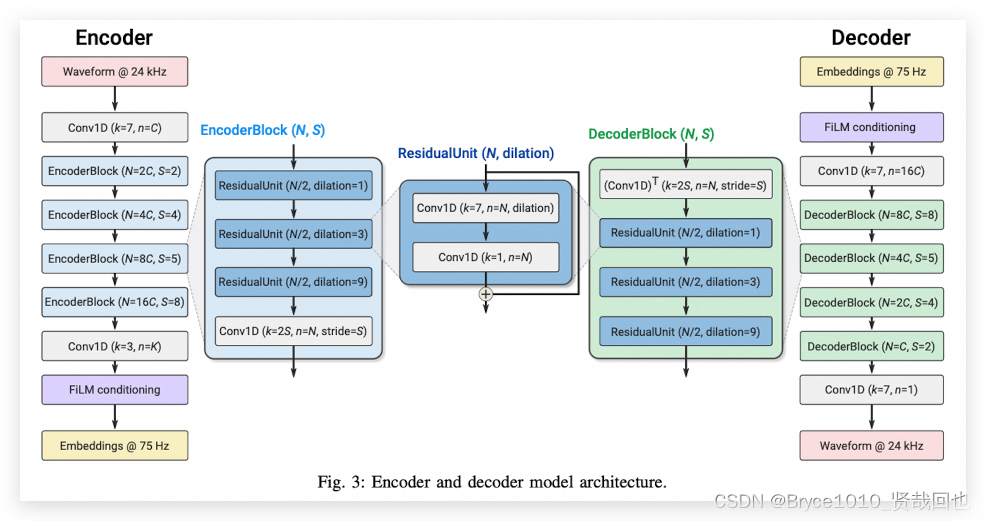
我们的编码器是用来处理声音波形的,它的工作起点是每秒24,000个声波样本。首先,声音会通过一个特殊的过滤器,这个过滤器看起来有点像漏斗,能把声音的特征捕捉出来。接下来,声音还会穿过一系列的处理单元,我们叫它们EncoderBlock,每个单元都有三个特别的创新点叫做"ResidualUnit"。
这个ResidualUnit非常聪明,里面有两层过滤器,第一层是擅长扩展的,可以抓住声音中更多的细节,有点像放大镜。第二层过滤器则有点像我们大脑中的神经元,帮助将所捕捉到的信息汇总起来。
而一个EncoderBlock会重复用三个不同放大能力的ResidualUnit来分析声音,它们能逐步探索声音的深层细节。每个EncoderBlock 还会使声音样本"稀疏"一些,也就是降低样本的数量,但仍然保留关键信息。
我们一共用了四个不同的EncoderBlock,每个都以不同的速度"稀疏"声音。最终,我们将声音的样本量减少了320倍。也就是说,如果原来每秒钟有24,000个样本的话,通过这些过程处理后,就只剩下每秒75个样本了。而且,每经过一个EncoderBlock,我们收集的细节就会加倍。
最后,声音会通过一个最终的过滤器,这个过滤器的作用是给出最终的声音"指纹",也就是我们所说的声音特征或嵌入(embedding),这些特征包含了所有我们关心的声音信息。
解码器
解码器采用的是和编码器完全对偶的结构,就不再赘述。
残差向量量化器
SoundStream 整体的编解码器结构比较直观,但论文的关键技术点之一是引入了残差向量量化(RVQ)模块,目的是将 Encoder 输出的 embedding 通过量化层压缩到目标的比特率。
VQ(Vector Quantization)回顾
Vector quantization - Wikipedia
向量量化是一种数据压缩技术,其基本想法是把一堆数据点分成几组,每组的数据点都彼此接近。想象一下,你有一堆点在纸上,现在你用几个不同颜色的圆圈来围起这些点,每个圆圈中的点都靠得比较近。然后你在每个圆圈里画一个点,代表这个圆圈中所有点的中央或者平均位置,我们叫这个点为“质心”。这个过程跟K-Means聚类算法很像,用来在数据分析中找到数据的自然分组。
在这篇论文中,我们运用向量量化的技巧来处理音频信号。具体地说,我们想要学习一套N个向量的集合,我们称之为“codebook”或“码本”。码本里的每个向量都代表着音频信号中的一种基本特征,就像一个词典里面的单词一样,每个单词表示一种意义。我们的目标是将音频编码器(Encoder)输出的一串特征(我们称这些为“embedding”)转换成码本中相应的向量。
举个例子,如果编码器输出了一个长度为S的特征序列,每个特征都是一个D维的点,那我们使用向量量化后,每个点会被转换成一个包含了一个1和很多0的特殊向量,这称为one-hot向量。这里的1所在的位置表示了它对应码本中哪一个向量。量化后的序列变成了SxN的大小,而且因为我们用one-hot向量来表示,所以只需要log2N比特来存储这个信息。
总之,码本就是一个包含了所有基本特征向量的集合。在实践中,为了表明哪一个特征被选择了,我们只需要用log2N这么多比特,这大大节省了存储空间。
普通 VQ 的局限性
向量量化(VQ)是音频编码中使用的一种技术,但普通的VQ面临一个问题,那就是它需要一个庞大的码本(codebook)来进行工作。码本就像是一本厚厚的图书馆索引,它列出了所有可能的音频片段特征的编码方式。
想象一下,如果我们有一段音频,比如说24kHz的高质量音频,我们希望用VQ技术将其压缩到6千比特每秒(kbps)的比特率。首先,我们得通过编码器将这段音频处理成一个“简化版”,这个过程就像是把音频“稀疏”化,我们称之为降采样,这里提到的降采样倍数是320倍。经过这个处理,原始音频里每75 ( 24 k / 320 = 75 ) (24k / 320 = 75) (24k/320=75) 个音频片段特征就变成了一个“embedding”,而这个embedding需要80 ( 6 k / 75 = 80 b i t ) (6k/75=80bit) (6k/75=80bit) 个比特来表示。
但问题在于,要描述所有不同的embedding,我们需要的码本大小是2的80次方,这是一个天文数字,用现实中的技术和资源根本无法存储这么大规模的码本。
残差 VQ/多阶段
为了解决普通VQ的这个问题,研究者们提出了残差VQ或多阶段VQ的方案。在这个系统中,我们用多层次的VQ来处理音频。这就像是你不是一次性把整个音频全都打包好,而是先打一个包裹,然后对这个包裹再进行打包,如此多次。
在多阶段VQ中,我们先用第一层VQ来处理原始编码器输出的embedding,然后计算出它和原始信号之间的差异,我们称之为残差。接着,第二层VQ只处理这个残差,而不是整个信号,然后第三层处理第二层的残差,以此类推。
通过这种方法,如果我们有8个这样的VQ层次,每一层都有自己的小型码本,那么每个层级的码本大小就变成了2的10次方
2
80
/
8
=
2
10
=
1024
2^{80/8}=2^{10}=1024
280/8=210=1024 ,也就是1024个可能的选项。这比起一开始天文数字的量级,变成了一个我们可以实际管理和存储的数量。通过这种多层次的方式,我们就可以用合理的资源来压缩并存储高质量的音频了。

判别器
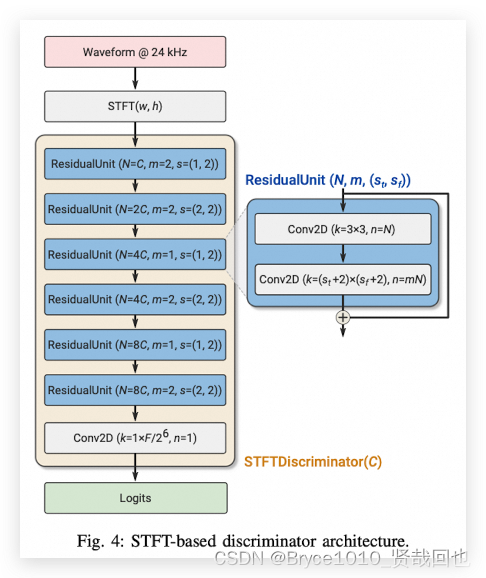
为了确保压缩再解压(编解码)的音频听起来像原来一样好,论文介绍了两种特殊的“音质判断工具”,我们称之为判别器。这些判别器的工作是分辨一段音频是不是经过编解码处理的,还是原始未经处理的真实音频。
第一种判别器关注的是音频的波形,也就是声音波动的形状。这个工具用了一种叫做多精度(multi-resolution)的技术,类似于已经存在的一些高清音质生成技术,比如MelGAN和HiFI-GAN。这种方法不仅会检查整个原始波形,还会查看它被压缩两倍和四倍后的情况,这样可以从不同层面上检测波形的细节。
第二种判别器则是基于STFT——短时傅里叶变换。这是一种将音频信号转换成时间和频率两个维度上的信息的技术。简单来说,判别器先拿到24kHz的音频,然后把它通过STFT转换成一个有时间和频率信息的二维图像。在这个过程中,我们用到了一个特定大小的窗口(窗长W=1024)去“观察”音频,并且以一个固定的步长(H=256采样点)在音频上移动这个窗口。这样处理之后,我们得到了一个包含时间点(T)数量和频率块(F)数量( F = W / 2 = 512 F=W/2=512 F=W/2=512)的二维表盘。
接下来,这个二维的信息会被送进一个特殊的过滤器,也就是一个7×7大小的二维卷积层。这个层的作用就像是一种复杂的过滤网,可以捕获音频的细节。而且,它后面还有其他几层增强的过滤器,它们在论文里被称作ResidualUnit,只不过这次我们使用的是二维版本来处理我们的音频“图像”。
最终,一个全连接层(也就是一个将信息汇集起来的网络层)会把这些数据汇总并生成一个单一的数值,我们称之为logits。此数值的目的是给出一个信号,说明正在检查的波形是经过编解码的音频还是真实的、未经处理的音频。
训练目标
SoundStream 整体使用 GAN(生成对抗网络)作为训练目标,采用 hinge loss 形式的对抗 loss。
对应到 GAN 模型中,整个编解码器作为 Generator 生成器,使用前文所述的两种 Discriminator 判别器:一个 STFT 判别器和三个参数不同的 multi-resolution 判别器。判别器用来区分是解码出的音频还是真实的原始音频,本文采用 hinge loss 形式的损失函数进行真假二分类:
![![[Pasted image 20240423155935.png]]](https://img-blog.csdnimg.cn/direct/31b8cbcc3bd444c1a21f9279ba10ce0c.png)
- L_D 是判别器损失函数。
- Ex 表示对真实样本 x 的期望。
- G(x) 是生成器根据 x 生成的样本。
- K 表示判别器的个数。
- T_k 表示第 k 个判别器logits的时间维度大小
- D_k,t(x) 和 D_k,t(G(x)) 分别表示第 k 个判别器在时间步 t 对真实样本 x 和生成样本 G(x) 的预测。
这个损失函数由两部分组成:
第一部分惩罚判别器将真实样本误判为生成的错误。max(0, 1 - D_k,t(x)) 确保当判别器预测真实样本时,损失为0,否则损失为预测误差的绝对值。
第二部分惩罚判别器将生成样本误判为真实的错误。max(0, 1 + D_k,t(G(x))) 确保当判别器预测生成样本时,损失为0,否则损失为预测误差的绝对值。
总的来说,这个损失函数旨在让判别器区分真实和生成的样本,使其预测尽可能接近真实情况。
K 表示 K 个独立的判别器,K=0时表示 STFT-based 的叛变起,K>1 时表示multi-resolution 判别器。
生成器的损失函数是为了让生成器的输出被分类为 1 类别,已达到以假乱真的目的,损失函数为:
![![[Pasted image 20240423160525.png]]](https://img-blog.csdnimg.cn/direct/45cfbc3bb3e349d0b9d8b85c0047fd6c.png)
训练目标中还增加了 GAN 中常用的 feature matching 损失函数和多尺度频谱重建的损失函数。feature matching 就是让生成器恢复出的音频和真实的音频,在判别器的中间层上达到相近的分布,用 表示在中间层
l
l
l上进行求和,feature matching 的损失函数为:
![![[Pasted image 20240423160634.png]]](https://img-blog.csdnimg.cn/direct/b51929a7e4194bdb9e2ad6100d59021c.png)
多尺度频谱重建损失函数为:
![![[Pasted image 20240423160712.png]]](https://img-blog.csdnimg.cn/direct/02613030b2f14a058583657d1ca46a7d.png)
综上所述,GAN 的训练损失函数为:
![![[Pasted image 20240423160752.png]]](https://img-blog.csdnimg.cn/direct/0b8f72ca133949aeb69945319705d496.png)
λ \lambda λ 表示加权值,实验中设置为: λ a d v = 1 , λ f e a t = 100 , λ r e c = 1 \lambda_{adv}=1, \lambda_{feat}=100, \lambda_{rec}=1 λadv=1,λfeat=100,λrec=1 。
SoundStream评测
评测准备
评测数据集
评测覆盖多种类型的音频,包括干净和带噪的语音和音乐,都是 24kHz 采样率。干净的语音来自 LibriTTS,带噪的语音是将 LibriTTS 和 freesound 里的噪声叠加,叠加时噪声的增益系数在 -30dB 和 0 dB 之间;音乐数据来源是 MagnaTagATune;论文还采集了真实场景的音频数据集,覆盖了近场、远场(带混响)和背景噪声的音频。相当于共四个测试集,每个测试集是 50 个待测样本。
评测指标
模型最终评测的指标采用前文所述的 MUSHRA 分数,评测人母语均为英语,戴耳机进行评测。但是在模型训练和调参时,留出一个验证集,在上面计算客观指标进行模型评价,可以用 PESQ 和 POLQA 的,本文选择的是开源的 ViSQOL 评测指标。
评测baseline
Opus 是传统的音频编解码方法,支持 4kHz ~ 24 kHz 的采样率和 6 kbps ~ 510 kbps 的比特率,在 Youtube 流媒体上都在使用。另外 EVS (增强语音服务) 也是一种新编解码方法,支持 4kHz ~ 20 kHz 的采样率和 5.9 kbps ~ 128 kbps 的比特率。Google 还提出了基于自回归模型的 Lyra 编解码器,可以在 3 kbps 的低比特率下使用。本文将以上三种方法作为基线。
评测结果
不同比特率下的结果
![![[Pasted image 20240423163357.png]]](https://img-blog.csdnimg.cn/direct/25adaf23d86a493a8ee04671f21f9297.png)
其中 scalable 的 SoundStream 代表一个支持多比特率的模型,不带 scalable 的模型表示给当前比特率专门训练的模型,可以看出模型是否 scalable 差别不大,尤其是高比特率下几乎无差别。相同比特率下,SoundStream 碾压其他三个基线模型。
不同类型音频的结果
![![[Pasted image 20240423163419.png]]](https://img-blog.csdnimg.cn/direct/38d4d168d3384d3f84591df19da2548e.png)
SoundStream @ 3kbps 相当于 EVS @ 9.6kbps 和 Opus@12kbps,SoundStream@6kbps 相当于 Opus @ 16kbps 和 EVS @ 13.2kbps,SoundStream @ 12kbps 超过了 Opus @ 20kbps 和 EVS @ 16.4kbps。普遍性地,编解码后恢复的音频,MUSHRA 分数上:干净语音 > 真实场景音频 > 带噪语音 > 音乐。
参考文献
- 详解SoundStream:一款端到端的神经音频编解码器_AI&大模型_谷歌研究团队_InfoQ精选文章
- soundstream - mdnice 墨滴
- ViSQOL 指标: Chinen, Michael, et al. “ViSQOL v3: An open source production ready objective speech and audio metric.” 2020 twelfth international conference on quality of multimedia experience (QoMEX). IEEE, 2020.
- 官方博客: https://opensource.googleblog.com/2022/09/lyra-v2-a-better-faster-and-more-versatile-speech-codec.html
- 示例音频: https://google-research.github.io/seanet/soundstream/examples
- 官方开源: https://github.com/google/lyra
- 非官方实现(PyTorch)Lucidrains: https://github.com/lucidrains/audiolm-pytorch/blob/main/audiolm_pytorch/soundstream.py
- 非官方实现(Pytorch)wesbz: https://github.com/wesbz/SoundStream
- 非官方实现(PyTorch)Lucidrains: https://github.com/lucidrains/audiolm-pytorch/blob/main/audiolm_pytorch/soundstream.py
- 非官方实现(Pytorch)wesbz: https://github.com/wesbz/SoundStream