一、机器阅读理解任务
1.1 概念理解
机器阅读理解(Machine Reading Comprehension, MRC)就是给定一篇文章,以及基于文章的一个问题,让机器在阅读文章后对问题进行作答。
在机器阅读理解领域,模型的核心能力体现在对给定文档集合P的理解以及对相关问题Q的准确应答,从而输出答案A。MRC任务可根据问题的形式和答案的生成方式,分为以下几种类型:
- 完形填空(Cloze-Style):在这种任务中,文章中的某些单词被隐去,模型需基于上下文信息推断出最可能的单词填充空白。这种方法考验模型对语境的理解以及对词汇的准确预测能力。
- 多项选择(Multiple-Choice):此任务为模型提供一篇文章和一个问题,模型需从多个备选答案中选择一个最符合问题要求的答案。这种类型的任务评估模型区分不同选项并做出最佳选择的能力。
- 片段抽取(Span-Extraction):在此任务中,模型需从给定文章中抽取一个连续的单词序列作为问题的答案。这种方法强调模型对文章细节的理解和定位关键信息的能力。
- 自由作答(Free-Answering):与片段抽取不同,自由作答任务要求模型生成一个单词序列作为答案,而不局限于文章中的现有句子。这种方法不仅考察模型的文本理解能力,还考察其生成连贯、准确答案的能力。
本次内容主要针对片段抽取(Span-Extraction)任务进行实战。
例子:
文档P:
“昨天,NASA宣布了一个关于火星上潜在生命迹象的重大发现。这个发现是基于好奇号火星车在盖尔陨石坑的探测结果。好奇号火星车自2012年登陆火星以来,一直在寻找火星上可能存在生命的迹象。NASA表示,这一发现可能是火星上曾经存在微生物生命的证据。”
问题Q:
“好奇号火星车在哪个陨石坑发现了潜在的生命迹象?”
答案A:
“盖尔陨石坑”
在这个例子中,机器阅读理解模型的任务是从给定的文档P中抽取与问题Q相关的连续文本片段作为答案A。模型需要准确地理解文档的内容,并定位到与问题直接相关的信息,即“盖尔陨石坑”。这种任务不仅要求模型理解文本的字面意义,还要求它能够从复杂的信息中抽取和识别关键信息。
1.2 评价指标
- 精准匹配度(Exact Match, EM):
- 计算方法:将预测结果与标准答案进行一对一比对,判断是否完全匹配。
- 意义:衡量模型输出与真实标签之间的精确一致性,是评估模型准确性的重要指标之一。
- 优点:直观反映模型预测的准确性,适合于单标签分类任务。
- 局限性:对于多标签或模糊匹配场景不适用,可能导致评分偏低。
- 模糊匹配度(F1):
- 计算方法:综合考虑精准匹配度和召回率,得到一个平衡的分数。
- 意义:考虑了模型在所有类别上的表现,适用于多标签分类任务。
- 优点:能够处理部分匹配的情况,更好地适应实际应用场景。
- 局限性:可能会掩盖模型在某些类别的性能短板。
- EM和F1的关系:
- EM关注的是绝对的正确性,F1关注的是整体的精确性和召回率。
- 在理想情况下,EM和F1都应该接近1,但实际情况中两者往往无法同时达到最高值。
- 根据具体任务需求,可以选择不同的评估指标来优化模型性能。
例子:
- 评估指标
- 精准匹配度(Exact Match, EM):计算预测结果与标准答案是否完全匹配。
- 模糊匹配度(F1):计算预测结果与标准答案之间字级别的匹配程度。
- 简单示例
- 数据
- 模型预测结果:西湖
- 真实标签结果:杭州西湖
- 计算结果
- EM = 0,P = 2/2 R=2/4 F1 = (2 * 2/2 * 2/4) / (2/2 + 2/4) = 2/3~= 0.66
- 数据
在评估机器阅读理解模型的性能时,应根据任务类型和目标选择合适的评估指标。精准匹配度适合于单标签任务,而模糊匹配度更适合于多标签任务。同时,需要认识到这些指标的局限性,并结合其他信息来全面评估模型的性能。
二、实战
2.1 加载数据集
datasets = load_dataset("cmrc2018", cache_dir="data")
datasets
DatasetDict({
train: Dataset({
features: ['id', 'context', 'question', 'answers'],
num_rows: 10142
})
validation: Dataset({
features: ['id', 'context', 'question', 'answers'],
num_rows: 3219
})
test: Dataset({
features: ['id', 'context', 'question', 'answers'],
num_rows: 1002
})
})
查看下数据
datasets["train"][1]
{'id': 'TRAIN_186_QUERY_1',
'context': '范廷颂枢机(,),圣名保禄·若瑟(),是越南罗马天主教枢机。1963年被任为主教;1990年被擢升为天主教河内总教区宗座署理;1994年被擢升为总主教,同年年底被擢升为枢机;2009年2月离世。范廷颂于1919年6月15日在越南宁平省天主教发艳教区出生;童年时接受良好教育后,被一位越南神父带到河内继续其学业。范廷颂于1940年在河内大修道院完成神学学业。范廷颂于1949年6月6日在河内的主教座堂晋铎;及后被派到圣女小德兰孤儿院服务。1950年代,范廷颂在河内堂区创建移民接待中心以收容到河内避战的难民。1954年,法越战争结束,越南民主共和国建都河内,当时很多天主教神职人员逃至越南的南方,但范廷颂仍然留在河内。翌年管理圣若望小修院;惟在1960年因捍卫修院的自由、自治及拒绝政府在修院设政治课的要求而被捕。1963年4月5日,教宗任命范廷颂为天主教北宁教区主教,同年8月15日就任;其牧铭为「我信天主的爱」。由于范廷颂被越南政府软禁差不多30年,因此他无法到所属堂区进行牧灵工作而专注研读等工作。范廷颂除了面对战争、贫困、被当局迫害天主教会等问题外,也秘密恢复修院、创建女修会团体等。1990年,教宗若望保禄二世在同年6月18日擢升范廷颂为天主教河内总教区宗座署理以填补该教区总主教的空缺。1994年3月23日,范廷颂被教宗若望保禄二世擢升为天主教河内总教区总主教并兼天主教谅山教区宗座署理;同年11月26日,若望保禄二世擢升范廷颂为枢机。范廷颂在1995年至2001年期间出任天主教越南主教团主席。2003年4月26日,教宗若望保禄二世任命天主教谅山教区兼天主教高平教区吴光杰主教为天主教河内总教区署理主教;及至2005年2月19日,范廷颂因获批辞去总主教职务而荣休;吴光杰同日真除天主教河内总教区总主教职务。范廷颂于2009年2月22日清晨在河内离世,享年89岁;其葬礼于同月26日上午在天主教河内总教区总主教座堂举行。',
'question': '1990年,范廷颂担任什么职务?',
'answers': {'text': ['1990年被擢升为天主教河内总教区宗座署理'], 'answer_start': [41]}}
2.2 数据预处理
接下来是当前整个任务最复杂的内容,因为数据格式我们需要进行处理成下面格式:

- 数据处理格式:
- [CLS]:表示分类标记,用于指示输入数据的类别。
- Question:问题的文本内容。
- [SEP]:分隔符,用于区分问题和上下文。
- Context:问题的上下文信息,即问题所处的环境或背景。
- [SEP]:分隔符,用于结束上下文的标注。
- 如何准确定位答案位置:
- 使用
start_positions / end_positions来指示答案在原始文本中的起始和结束位置。 - 通过
offset_mapping映射原始文本到转换后的序列,从而确定答案的位置。
- 使用
- Context过长时的解决策略:
- 策略1:直接截断(例如,当问题长度超过一定阈值时):这种方法简单且易于实现,但可能会导致答案靠后的部分被忽略。
- 策略2:滑动窗口(例如,通过多个窗口遍历原始文本):这种方法虽然复杂,但可以保留更多的上下文信息,尽管它会丢失一部分原文本。(下篇再讲)
2.2.1 滑动窗口
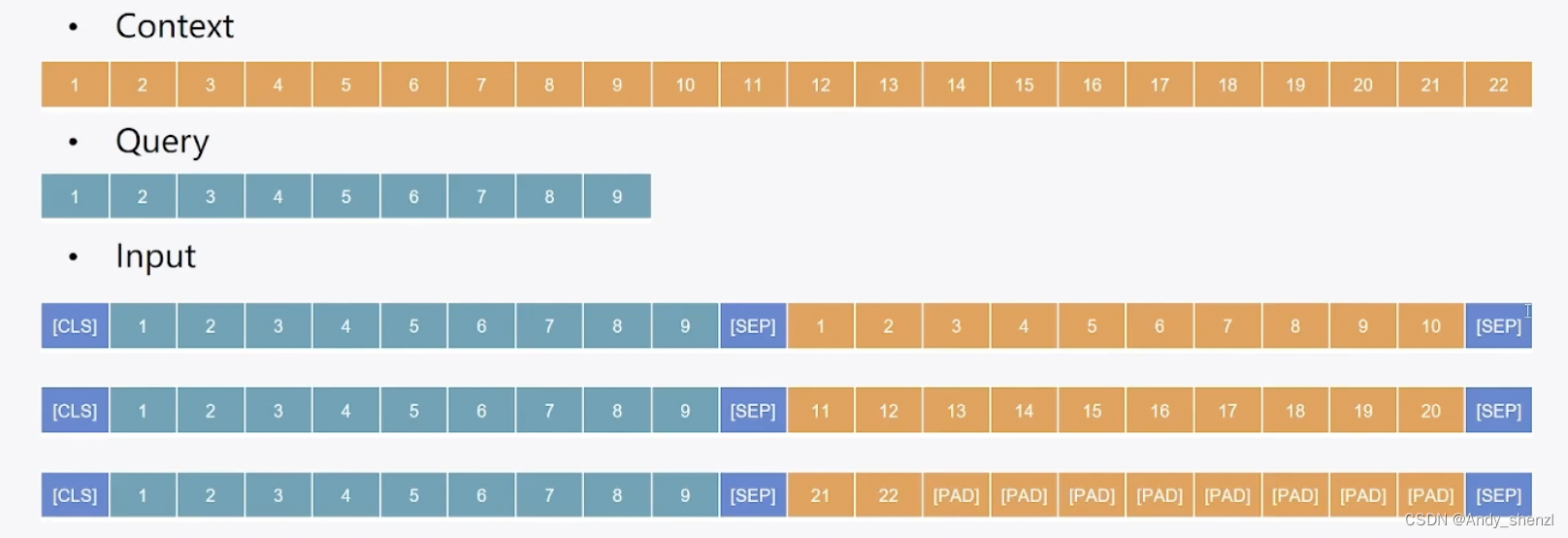
但是如果我们直接截断的这种滑动窗口会影响上下文的理解,所以我们一般会让后面加一段前面一段的内容来维系文本的连贯性
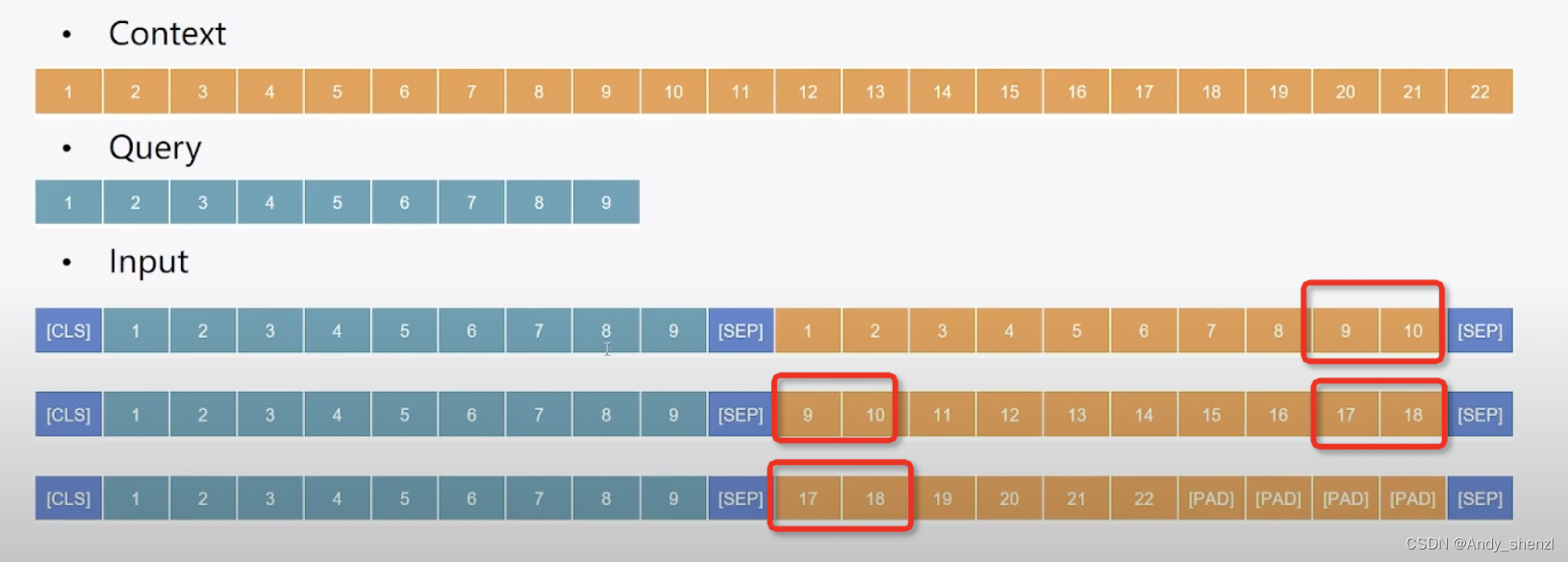
示例:
问题:中国的首都是哪里?
上下文:北京是中国的首都,它是一座历史悠久的城市,有着丰富的文化遗产和现代化的城市景观。
在这个例子中,我们可以将问题标记为“Question”,上下文标记为“Context”。然后使用start_positions / end_positions来定位答案“北京”在原始文本中的起始和结束位置,并将其与问题一起组成一个完整的输入样本供模型学习。
2.2.2 offsets_mapping
在使用transformers库进行文本处理时,offset_mapping 是一个非常重要的概念。它是一个与分词结果相关联的列表,其中每个元素是一个元组,表示一个token在原始文本中的字符级别位置。
demo = datasets["train"].select(range(10))
tokenized_demo = tokenizer(text=demo["question"],
text_pair=demo["context"],
return_offsets_mapping=True,
return_overflowing_tokens=True,
stride=128,
max_length=384, truncation="only_second", padding="max_length")
print(tokenized_demo["offset_mapping"][25], len(tokenized_demo["offset_mapping"][25]))
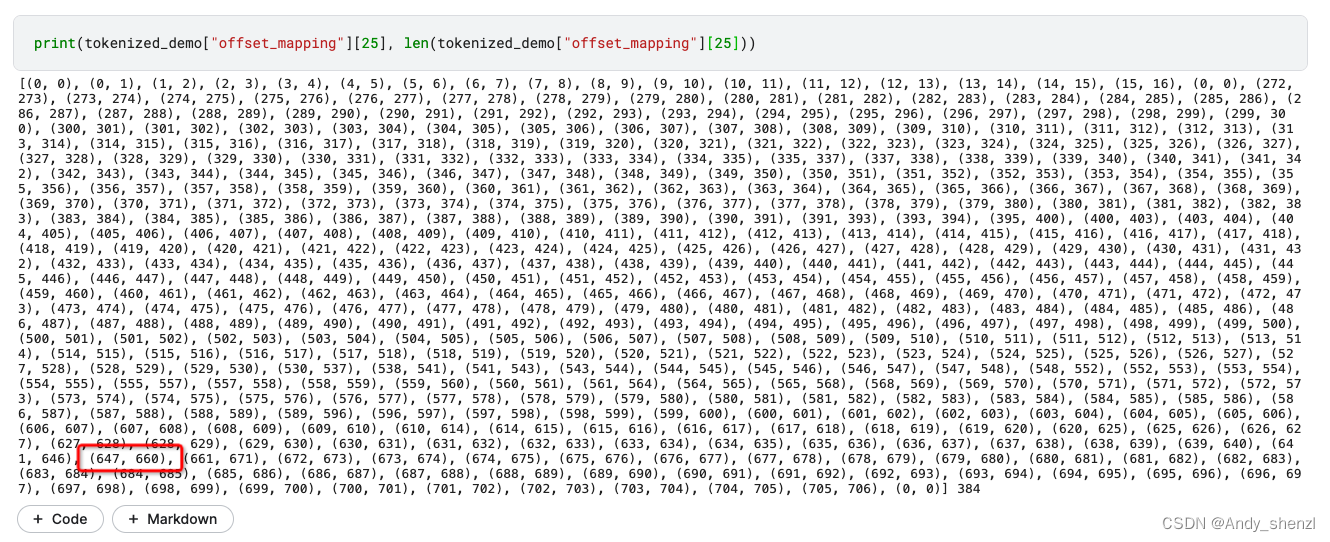
这个个token下面有多个offsets_mapping索引,我们实际找一个看看
demo[8]
{'id': 'TRAIN_54_QUERY_3',
'context': '安雅·罗素法(,),来自俄罗斯圣彼得堡的模特儿。她是《全美超级模特儿新秀大赛》第十季的亚军。2008年,安雅宣布改回出生时的名字:安雅·罗素法(Anya Rozova),在此之前是使用安雅·冈()。安雅于俄罗斯出生,后来被一个居住在美国夏威夷群岛欧胡岛檀香山的家庭领养。安雅十七岁时曾参与香奈儿、路易·威登及芬迪(Fendi)等品牌的非正式时装秀。2007年,她于瓦伊帕胡高级中学毕业。毕业后,她当了一名售货员。她曾为Russell Tanoue拍摄照片,Russell Tanoue称赞她是「有前途的新面孔」。安雅在半准决赛面试时说她对模特儿行业充满热诚,所以参加全美超级模特儿新秀大赛。她于比赛中表现出色,曾五次首名入围,平均入围顺序更拿下历届以来最优异的成绩(2.64),另外胜出三次小挑战,分别获得与评判尼祖·百克拍照、为柠檬味道的七喜拍摄广告的机会及十万美元、和盖马蒂洛(Gai Mattiolo)设计的晚装。在最后两强中,安雅与另一名参赛者惠妮·汤姆森为范思哲走秀,但评判认为她在台上不够惠妮突出,所以选了惠妮当冠军,安雅屈居亚军(但就整体表现来说,部份网友认为安雅才是第十季名副其实的冠军。)安雅在比赛拿五次第一,也胜出多次小挑战。安雅赛后再次与Russell Tanoue合作,为2008年4月30日出版的MidWeek杂志拍摄封面及内页照。其后她参加了V杂志与Supreme模特儿公司合办的模特儿选拔赛2008。她其后更与Elite签约。最近她与香港的模特儿公司 Style International Management 签约,并在香港发展其模特儿事业。她曾在很多香港的时装杂志中任模特儿,《Jet》、《东方日报》、《Elle》等。',
'question': '毕业后的安雅·罗素法职业是什么?',
'answers': {'text': ['售货员'], 'answer_start': [202]}}
这里有英文,我们拿出来进行分词
tokenizer("Russell Tanoue")
{'input_ids': [101, 13481, 30594, 11010, 10112, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1]}
对于英文来讲,如果一个单词没有在此表中出现那么它就需要进行分解,一个单词可以分解多次,直到能在此表中找到,进行表示。
我们可以分别对上面的几个input_ids进行解码看看
tokenizer.decode([101, 13481, 30594, 11010, 10112, 102])
'[CLS] Russell Tanoue [SEP]'
tokenizer("Russell Tanoue").word_ids()
[None, 0, 1, 1, 1, None]
可以发现第一个单词Russell在此表中是有的,但是Tanoue被分解成了三个token
我们分别解码看看
tokenizer.decode([101, 30594, 102]),tokenizer.decode([101, 11010, 102]),tokenizer.decode([101, 10112, 102])
('[CLS] Tan [SEP]', '[CLS]ou [SEP]', '[CLS]e [SEP]')
也就是Tanoue被分解成了【Tan, ou, e 】
后面处理的难点就是我们需要把Tan, ou, e对应的input_ids:30594, 11010, 10112,进新计数的时候要根据实际的文本计算
也就是Tanoue在原始文本中占一个字符,但是分词后,它占了三个,所以我们在定位答案的起始位置时需要根据一个字符进行定位,但是我们训练处理的时候时使用编码后的input_ids,所以我们就必须把offsets_mapping和原始的内容匹配好才能根据起始位置找到真正的答案。
2.2.3 overflow
for sen in tokenizer.batch_decode(tokenized_demo["input_ids"][:6]):
print(sen)
[CLS] 范 廷 颂 是 什 么 时 候 被 任 为 主 教 的 ? [SEP] 范 廷 颂 枢 机 ( , ) , 圣 名 保 禄 · 若 瑟 ( ) , 是 越 南 罗 马 天 主 教 枢 机 。 1963 年 被 任 为 主 教 ; 1990 年 被 擢 升 为 天 主 教 河 内 总 教 区 宗 座 署 理 ; 1994 年 被 擢 升 为 总 主 教 , 同 年 年 底 被 擢 升 为 枢 机 ; 2009 年 2 月 离 世 。 范 廷 颂 于 1919 年 6 月 15 日 在 越 南 宁 平 省 天 主 教 发 艳 教 区 出 生 ; 童 年 时 接 受 良 好 教 育 后 , 被 一 位 越 南 神 父 带 到 河 内 继 续 其 学 业 。 范 廷 颂 于 1940 年 在 河 内 大 修 道 院 完 成 神 学 学 业 。 范 廷 颂 于 1949 年 6 月 6 日 在 河 内 的 主 教 座 堂 晋 铎 ; 及 后 被 派 到 圣 女 小 德 兰 孤 儿 院 服 务 。 1950 年 代 , 范 廷 颂 在 河 内 堂 区 创 建 移 民 接 待 中 心 以 收 容 到 河 内 避 战 的 难 民 。 1954 年 , 法 越 战 争 结 束 , 越 南 民 主 共 和 国 建 都 河 内 , 当 时 很 多 天 主 教 神 职 人 员 逃 至 越 南 的 南 方 , 但 范 廷 颂 仍 然 留 在 河 内 。 翌 年 管 理 圣 若 望 小 修 院 ; 惟 在 1960 年 因 捍 卫 修 院 的 自 由 、 自 治 及 拒 绝 政 府 在 修 院 设 政 治 课 的 要 求 而 被 捕 。 1963 年 4 月 5 日 , 教 宗 任 命 范 廷 颂 为 天 主 教 北 宁 教 区 主 教 , 同 年 8 月 15 日 就 任 ; 其 牧 铭 为 「 我 信 [SEP]
[CLS] 范 廷 颂 是 什 么 时 候 被 任 为 主 教 的 ? [SEP] 越 南 民 主 共 和 国 建 都 河 内 , 当 时 很 多 天 主 教 神 职 人 员 逃 至 越 南 的 南 方 , 但 范 廷 颂 仍 然 留 在 河 内 。 翌 年 管 理 圣 若 望 小 修 院 ; 惟 在 1960 年 因 捍 卫 修 院 的 自 由 、 自 治 及 拒 绝 政 府 在 修 院 设 政 治 课 的 要 求 而 被 捕 。 1963 年 4 月 5 日 , 教 宗 任 命 范 廷 颂 为 天 主 教 北 宁 教 区 主 教 , 同 年 8 月 15 日 就 任 ; 其 牧 铭 为 「 我 信 天 主 的 爱 」 。 由 于 范 廷 颂 被 越 南 政 府 软 禁 差 不 多 30 年 , 因 此 他 无 法 到 所 属 堂 区 进 行 牧 灵 工 作 而 专 注 研 读 等 工 作 。 范 廷 颂 除 了 面 对 战 争 、 贫 困 、 被 当 局 迫 害 天 主 教 会 等 问 题 外 , 也 秘 密 恢 复 修 院 、 创 建 女 修 会 团 体 等 。 1990 年 , 教 宗 若 望 保 禄 二 世 在 同 年 6 月 18 日 擢 升 范 廷 颂 为 天 主 教 河 内 总 教 区 宗 座 署 理 以 填 补 该 教 区 总 主 教 的 空 缺 。 1994 年 3 月 23 日 , 范 廷 颂 被 教 宗 若 望 保 禄 二 世 擢 升 为 天 主 教 河 内 总 教 区 总 主 教 并 兼 天 主 教 谅 山 教 区 宗 座 署 理 ; 同 年 11 月 26 日 , 若 望 保 禄 二 世 擢 升 范 廷 颂 为 枢 机 。 范 廷 颂 在 1995 年 至 2001 年 期 间 出 任 天 主 教 越 南 主 教 团 主 席 。 2003 年 4 [SEP]
[CLS] 范 廷 颂 是 什 么 时 候 被 任 为 主 教 的 ? [SEP] 日 擢 升 范 廷 颂 为 天 主 教 河 内 总 教 区 宗 座 署 理 以 填 补 该 教 区 总 主 教 的 空 缺 。 1994 年 3 月 23 日 , 范 廷 颂 被 教 宗 若 望 保 禄 二 世 擢 升 为 天 主 教 河 内 总 教 区 总 主 教 并 兼 天 主 教 谅 山 教 区 宗 座 署 理 ; 同 年 11 月 26 日 , 若 望 保 禄 二 世 擢 升 范 廷 颂 为 枢 机 。 范 廷 颂 在 1995 年 至 2001 年 期 间 出 任 天 主 教 越 南 主 教 团 主 席 。 2003 年 4 月 26 日 , 教 宗 若 望 保 禄 二 世 任 命 天 主 教 谅 山 教 区 兼 天 主 教 高 平 教 区 吴 光 杰 主 教 为 天 主 教 河 内 总 教 区 署 理 主 教 ; 及 至 2005 年 2 月 19 日 , 范 廷 颂 因 获 批 辞 去 总 主 教 职 务 而 荣 休 ; 吴 光 杰 同 日 真 除 天 主 教 河 内 总 教 区 总 主 教 职 务 。 范 廷 颂 于 2009 年 2 月 22 日 清 晨 在 河 内 离 世 , 享 年 89 岁 ; 其 葬 礼 于 同 月 26 日 上 午 在 天 主 教 河 内 总 教 区 总 主 教 座 堂 举 行 。 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
[CLS] 1990 年 , 范 廷 颂 担 任 什 么 职 务 ? [SEP] 范 廷 颂 枢 机 ( , ) , 圣 名 保 禄 · 若 瑟 ( ) , 是 越 南 罗 马 天 主 教 枢 机 。 1963 年 被 任 为 主 教 ; 1990 年 被 擢 升 为 天 主 教 河 内 总 教 区 宗 座 署 理 ; 1994 年 被 擢 升 为 总 主 教 , 同 年 年 底 被 擢 升 为 枢 机 ; 2009 年 2 月 离 世 。 范 廷 颂 于 1919 年 6 月 15 日 在 越 南 宁 平 省 天 主 教 发 艳 教 区 出 生 ; 童 年 时 接 受 良 好 教 育 后 , 被 一 位 越 南 神 父 带 到 河 内 继 续 其 学 业 。 范 廷 颂 于 1940 年 在 河 内 大 修 道 院 完 成 神 学 学 业 。 范 廷 颂 于 1949 年 6 月 6 日 在 河 内 的 主 教 座 堂 晋 铎 ; 及 后 被 派 到 圣 女 小 德 兰 孤 儿 院 服 务 。 1950 年 代 , 范 廷 颂 在 河 内 堂 区 创 建 移 民 接 待 中 心 以 收 容 到 河 内 避 战 的 难 民 。 1954 年 , 法 越 战 争 结 束 , 越 南 民 主 共 和 国 建 都 河 内 , 当 时 很 多 天 主 教 神 职 人 员 逃 至 越 南 的 南 方 , 但 范 廷 颂 仍 然 留 在 河 内 。 翌 年 管 理 圣 若 望 小 修 院 ; 惟 在 1960 年 因 捍 卫 修 院 的 自 由 、 自 治 及 拒 绝 政 府 在 修 院 设 政 治 课 的 要 求 而 被 捕 。 1963 年 4 月 5 日 , 教 宗 任 命 范 廷 颂 为 天 主 教 北 宁 教 区 主 教 , 同 年 8 月 15 日 就 任 ; 其 牧 铭 为 「 我 信 天 主 [SEP]
[CLS] 1990 年 , 范 廷 颂 担 任 什 么 职 务 ? [SEP] 民 主 共 和 国 建 都 河 内 , 当 时 很 多 天 主 教 神 职 人 员 逃 至 越 南 的 南 方 , 但 范 廷 颂 仍 然 留 在 河 内 。 翌 年 管 理 圣 若 望 小 修 院 ; 惟 在 1960 年 因 捍 卫 修 院 的 自 由 、 自 治 及 拒 绝 政 府 在 修 院 设 政 治 课 的 要 求 而 被 捕 。 1963 年 4 月 5 日 , 教 宗 任 命 范 廷 颂 为 天 主 教 北 宁 教 区 主 教 , 同 年 8 月 15 日 就 任 ; 其 牧 铭 为 「 我 信 天 主 的 爱 」 。 由 于 范 廷 颂 被 越 南 政 府 软 禁 差 不 多 30 年 , 因 此 他 无 法 到 所 属 堂 区 进 行 牧 灵 工 作 而 专 注 研 读 等 工 作 。 范 廷 颂 除 了 面 对 战 争 、 贫 困 、 被 当 局 迫 害 天 主 教 会 等 问 题 外 , 也 秘 密 恢 复 修 院 、 创 建 女 修 会 团 体 等 。 1990 年 , 教 宗 若 望 保 禄 二 世 在 同 年 6 月 18 日 擢 升 范 廷 颂 为 天 主 教 河 内 总 教 区 宗 座 署 理 以 填 补 该 教 区 总 主 教 的 空 缺 。 1994 年 3 月 23 日 , 范 廷 颂 被 教 宗 若 望 保 禄 二 世 擢 升 为 天 主 教 河 内 总 教 区 总 主 教 并 兼 天 主 教 谅 山 教 区 宗 座 署 理 ; 同 年 11 月 26 日 , 若 望 保 禄 二 世 擢 升 范 廷 颂 为 枢 机 。 范 廷 颂 在 1995 年 至 2001 年 期 间 出 任 天 主 教 越 南 主 教 团 主 席 。 2003 年 4 月 26 日 , [SEP]
[CLS] 1990 年 , 范 廷 颂 担 任 什 么 职 务 ? [SEP] 廷 颂 为 天 主 教 河 内 总 教 区 宗 座 署 理 以 填 补 该 教 区 总 主 教 的 空 缺 。 1994 年 3 月 23 日 , 范 廷 颂 被 教 宗 若 望 保 禄 二 世 擢 升 为 天 主 教 河 内 总 教 区 总 主 教 并 兼 天 主 教 谅 山 教 区 宗 座 署 理 ; 同 年 11 月 26 日 , 若 望 保 禄 二 世 擢 升 范 廷 颂 为 枢 机 。 范 廷 颂 在 1995 年 至 2001 年 期 间 出 任 天 主 教 越 南 主 教 团 主 席 。 2003 年 4 月 26 日 , 教 宗 若 望 保 禄 二 世 任 命 天 主 教 谅 山 教 区 兼 天 主 教 高 平 教 区 吴 光 杰 主 教 为 天 主 教 河 内 总 教 区 署 理 主 教 ; 及 至 2005 年 2 月 19 日 , 范 廷 颂 因 获 批 辞 去 总 主 教 职 务 而 荣 休 ; 吴 光 杰 同 日 真 除 天 主 教 河 内 总 教 区 总 主 教 职 务 。 范 廷 颂 于 2009 年 2 月 22 日 清 晨 在 河 内 离 世 , 享 年 89 岁 ; 其 葬 礼 于 同 月 26 日 上 午 在 天 主 教 河 内 总 教 区 总 主 教 座 堂 举 行 。 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
我们滑动窗口进行分解后,那么答案可能位于任何一个窗口里,所以我们在处理的时候,需要便利每一个窗口;同时答案可能同时出现了多个窗口,因为有数据的重复,而且相似的答案也可能会出现在不同的位置,所以我们后面处理的时候需要进行对比。
def process_func(examples):
tokenized_examples = tokenizer(text=examples["question"],
text_pair=examples["context"],
return_offsets_mapping=True,
return_overflowing_tokens=True,
stride=128,
max_length=384, truncation="only_second", padding="max_length")
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
start_positions = []
end_positions = []
example_ids = []
for idx, _ in enumerate(sample_mapping):
answer = examples["answers"][sample_mapping[idx]]
start_char = answer["answer_start"][0]
end_char = start_char + len(answer["text"][0])
# 定位答案在token中的起始位置和结束位置
# 一种策略,我们要拿到context的起始和结束,然后从左右两侧向答案逼近
context_start = tokenized_examples.sequence_ids(idx).index(1)
context_end = tokenized_examples.sequence_ids(idx).index(None, context_start) - 1
offset = tokenized_examples.get("offset_mapping")[idx]
# 判断答案是否在context中
if offset[context_end][1] < start_char or offset[context_start][0] > end_char:
start_token_pos = 0
end_token_pos = 0
else:
token_id = context_start
while token_id <= context_end and offset[token_id][0] < start_char:
token_id += 1
start_token_pos = token_id
token_id = context_end
while token_id >= context_start and offset[token_id][1] > end_char:
token_id -=1
end_token_pos = token_id
start_positions.append(start_token_pos)
end_positions.append(end_token_pos)
example_ids.append(examples["id"][sample_mapping[idx]])
tokenized_examples["offset_mapping"][idx] = [
(o if tokenized_examples.sequence_ids(idx)[k] == 1 else None)
for k, o in enumerate(tokenized_examples["offset_mapping"][idx])
]
tokenized_examples["example_ids"] = example_ids
tokenized_examples["start_positions"] = start_positions
tokenized_examples["end_positions"] = end_positions
return tokenized_examples
上面代码定义了一个名为 process_func 的函数,其目的是对阅读理解任务的数据进行预处理。这个函数接受一个参数 examples,它是一个包含问题和上下文的数据集。函数的目的是将这个数据集转换成一个适合模型处理的格式。
以下是代码的主要步骤:
- 使用
tokenizer对问题和上下文进行分词。这里设置了几个关键参数:return_offsets_mapping=True:返回每个token与原始文本中字符的对应关系。return_overflowing_tokens=True:当文本长度超过模型最大序列长度时,返回分割的token。stride=128:当进行文本分割时,每次移动的字符数。max_length=384:模型能够处理的最大序列长度。truncation="only_second":如果文本过长,只截断上下文。padding="max_length":对序列进行填充以使它们都具有相同的长度。
sample_mapping被用来处理文本过长被分割的情况。它包含了分割后的部分与原始样本的对应关系。- 初始化
start_positions、end_positions和example_ids三个列表,用于存储答案的起始和结束位置以及问题的ID。 - 对于每个样本,根据
sample_mapping找到对应的答案,并计算答案在token中的起始和结束位置。这是通过比较答案的字符位置和token的字符位置来完成的。 - 如果答案在上下文中,则通过遍历token的偏移量来找到答案的起始和结束token位置。
- 将起始和结束位置以及问题ID添加到对应的列表中。
- 更新
tokenized_examples中的offset_mapping,确保只有上下文的token的偏移量被保留。 - 将
example_ids、start_positions和end_positions添加到tokenized_examples中。 - 返回处理后的
tokenized_examples。
总的来说,这个函数的主要目的是为机器阅读理解任务准备数据,包括对问题和上下文进行分词,并确定答案在分词后的文本中的位置。这对于训练模型来预测答案在文本中的位置是至关重要的。
tokenied_datasets = datasets.map(process_func, batched=True, remove_columns=datasets["train"].column_names)
tokenied_datasets
DatasetDict({
train: Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'offset_mapping', 'example_ids', 'start_positions', 'end_positions'],
num_rows: 19069
})
validation: Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'offset_mapping', 'example_ids', 'start_positions', 'end_positions'],
num_rows: 6286
})
test: Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'offset_mapping', 'example_ids', 'start_positions', 'end_positions'],
num_rows: 1971
})
})
tokenied_datasets["train"]["example_ids"][:10]
['TRAIN_186_QUERY_0',
'TRAIN_186_QUERY_0',
'TRAIN_186_QUERY_0',
'TRAIN_186_QUERY_1',
'TRAIN_186_QUERY_1',
'TRAIN_186_QUERY_1',
'TRAIN_186_QUERY_2',
'TRAIN_186_QUERY_2',
'TRAIN_186_QUERY_2',
'TRAIN_186_QUERY_3']
‘TRAIN_186_QUERY_0’,
‘TRAIN_186_QUERY_0’,
‘TRAIN_186_QUERY_0’,
表示第一个被分成了三块,把分割的滑动窗口跟原始的记录进行映射
import collections
example_to_feature = collections.defaultdict(list)
for idx, example_id in enumerate(tokenied_datasets["train"]["example_ids"][:10]):
example_to_feature[example_id].append(idx)
example_to_feature
defaultdict(list,
{'TRAIN_186_QUERY_0': [0, 1, 2],
'TRAIN_186_QUERY_1': [3, 4, 5],
'TRAIN_186_QUERY_2': [6, 7, 8],
'TRAIN_186_QUERY_3': [9]})
2.3 创建模型
model = AutoModelForQuestionAnswering.from_pretrained("google-bert/bert-base-multilingual-cased")
2.4 创建评估函数
import numpy as np
import collections
def get_result(start_logits, end_logits, exmaples, features):
predictions = {}
references = {}
# example 和 feature的映射
example_to_feature = collections.defaultdict(list)
for idx, example_id in enumerate(features["example_ids"]):
example_to_feature[example_id].append(idx)
# 最优答案候选
n_best = 20
# 最大答案长度
max_answer_length = 30
for example in exmaples:
example_id = example["id"]
context = example["context"]
answers = []
for feature_idx in example_to_feature[example_id]:
start_logit = start_logits[feature_idx]
end_logit = end_logits[feature_idx]
offset = features[feature_idx]["offset_mapping"]
start_indexes = np.argsort(start_logit)[::-1][:n_best].tolist()
end_indexes = np.argsort(end_logit)[::-1][:n_best].tolist()
for start_index in start_indexes:
for end_index in end_indexes:
if offset[start_index] is None or offset[end_index] is None:
continue
if end_index < start_index or end_index - start_index + 1 > max_answer_length:
continue
answers.append({
"text": context[offset[start_index][0]: offset[end_index][1]],
"score": start_logit[start_index] + end_logit[end_index]
})
if len(answers) > 0:
best_answer = max(answers, key=lambda x: x["score"])
predictions[example_id] = best_answer["text"]
else:
predictions[example_id] = ""
references[example_id] = example["answers"]["text"]
return predictions, references
上面代码定义了一个名为 get_result 的函数,其目的是从模型输出的开始和结束logits中提取预测的答案,并将它们与参考答案进行比较。这个函数接受四个参数:start_logits、end_logits、examples 和 features。这些参数用于生成预测答案和参考答案的字典,以便进行评估。
以下是代码的主要步骤:
- 初始化两个字典:
predictions用于存储预测答案,references用于存储参考答案。 - 建立一个从
example_id到feature_idx的映射,以便能够将预测的答案与原始问题和上下文对应起来。 - 对于每个问题(
example),找到与其相关的特征索引(feature_idx),并使用这些索引来获取对应的开始和结束的logits。 - 对于每个特征索引,找到最可能的开始和结束索引,并使用这些索引来提取文本中的答案片段。
- 将每个答案片段及其得分存储在一个列表中。
- 从这个列表中选择得分最高的答案作为最佳答案,并将其存储在
predictions字典中。 - 将参考答案存储在
references字典中。 - 返回
predictions和references两个字典。
这个函数的输出可以用于评估模型的性能,例如通过计算F1分数和精确匹配(EM)分数。这些分数可以帮助您了解模型在给定数据集上的表现。
from metirc.cmrc_eval import evaluate_cmrc
def metirc(pred):
start_logits, end_logits = pred[0]
if start_logits.shape[0] == len(tokenied_datasets["validation"]):
p, r = get_result(start_logits, end_logits, datasets["validation"], tokenied_datasets["validation"])
else:
p, r = get_result(start_logits, end_logits, datasets["test"], tokenied_datasets["test"])
return evaluate_cmrc(p, r)
评估代码
2.5 创建训练器
args = TrainingArguments(
output_dir="models_for_qa",
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
evaluation_strategy="epoch",
save_strategy="epoch",
logging_steps=50,
num_train_epochs=1,
report_to=['tensorboard']
)
2.6 开始训练
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenied_datasets["train"],
eval_dataset=tokenied_datasets["validation"],
data_collator=DefaultDataCollator(),
compute_metrics=metirc
)
trainer.train()

2.7 评估
trainer.evaluate(eval_dataset=tokenied_datasets["test"])
{'eval_loss': 1.1424208879470825,
'eval_avg': 49.33014028955766,
'eval_f1': 66.72415283460434,
'eval_em': 31.936127744510976,
'eval_total': 1002,
'eval_skip': 0,
'eval_runtime': 32.0109,
'eval_samples_per_second': 61.573,
'eval_steps_per_second': 1.937,
'epoch': 1.0}
预测的效果有点差
2.8 预测
from transformers import pipeline
pipe = pipeline("question-answering", model=model, tokenizer=tokenizer, device=0)
pipe(question="马云在哪里创建了阿里巴巴?", context="马云在杭州创建了阿里巴巴")
{'score': 0.8899545669555664, 'start': 3, 'end': 5, 'answer': '杭州'}
完整代码