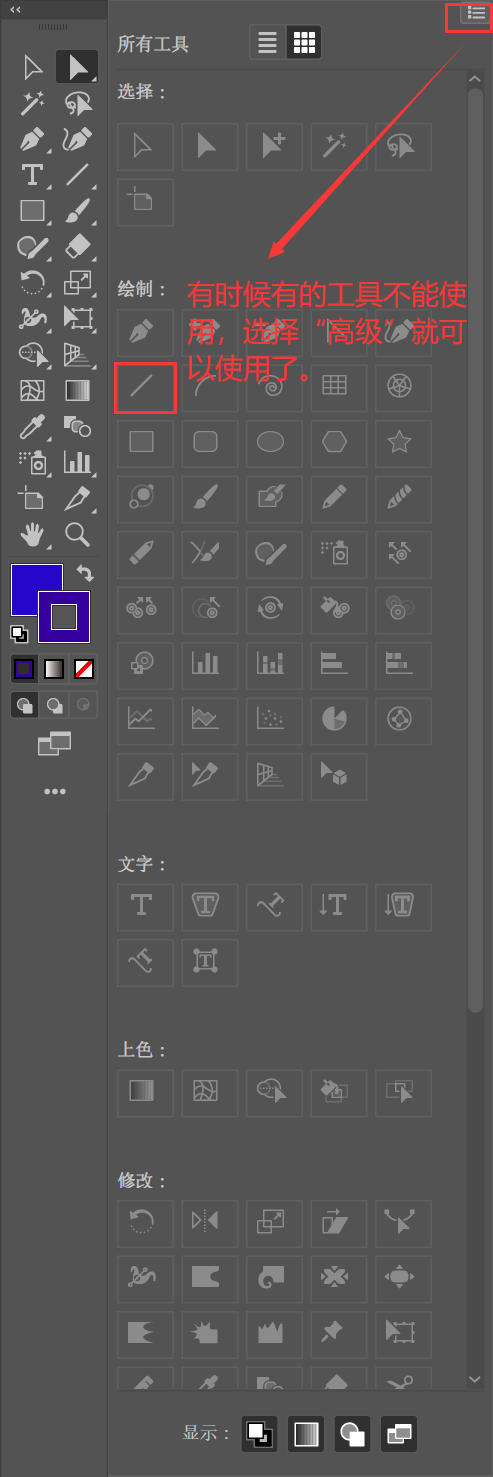
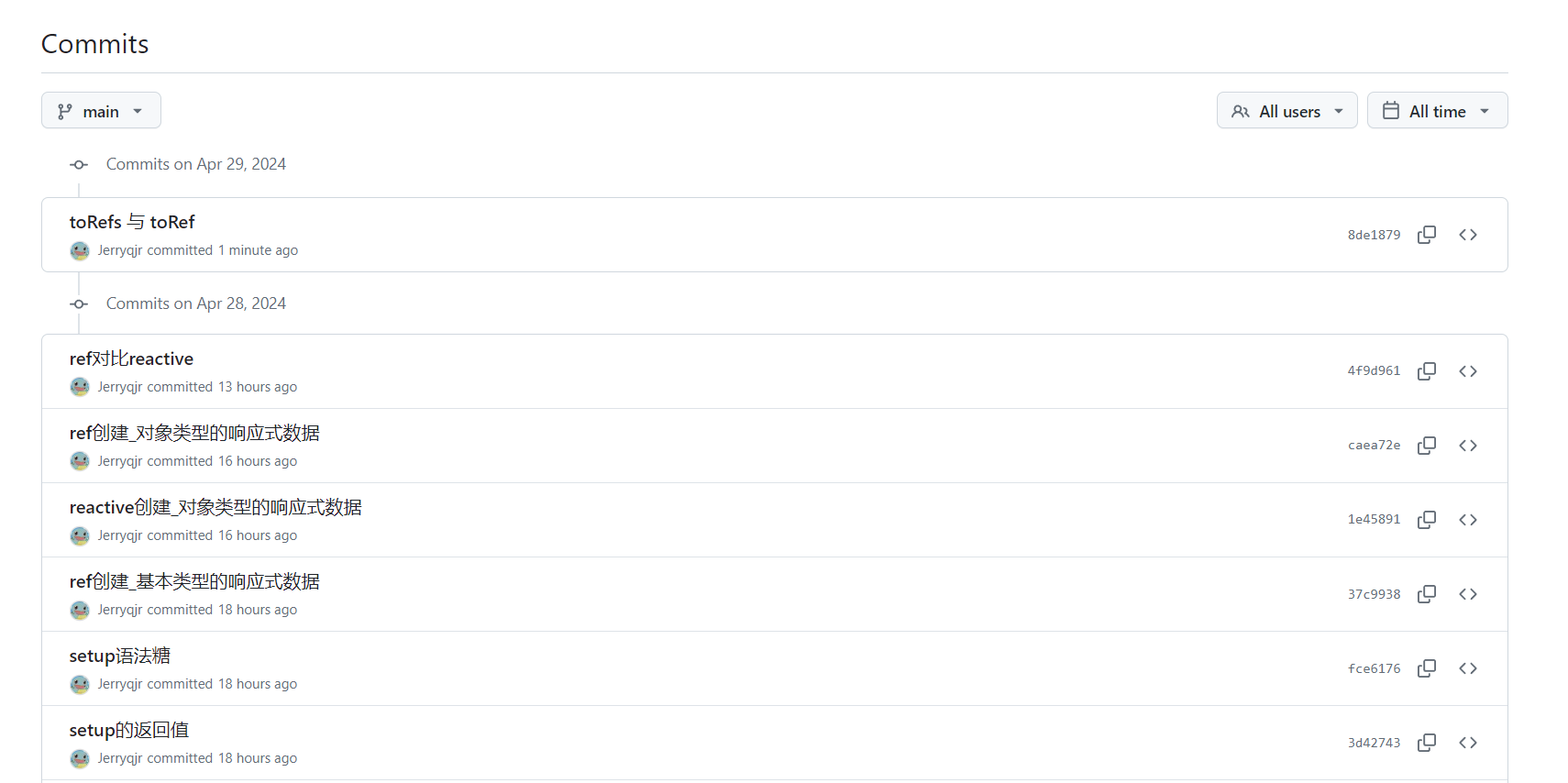
目录
简介
设置
加载数据集
准备数据
设置嵌入生成器模型
建立连体网络模型
将一切整合在一起
训练
检查网络的学习成果
摘要
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: TensorFlow与Keras机器学习实战
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
本文目标:使用三重损失函数训练连体网络,以比较图像的相似性。
简介
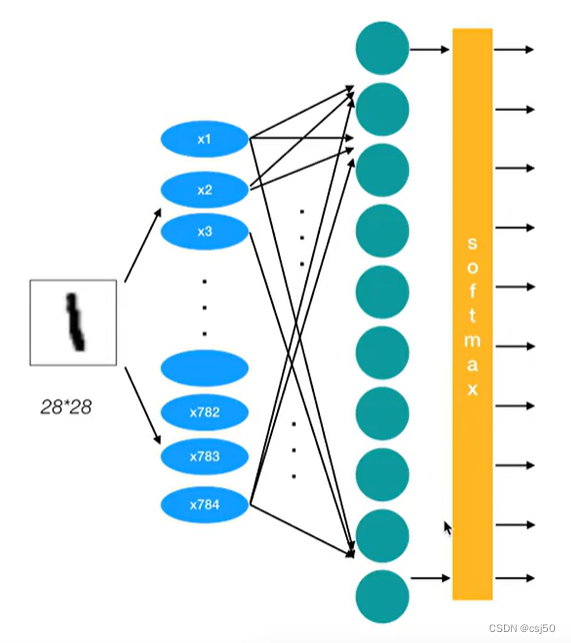
连体网络是一种网络架构,包含两个或多个相同的子网络,用于为每个输入生成特征向量并进行比较。
连体网络可应用于不同的使用场景,如检测重复数据、查找异常数据和人脸识别。
本例使用的连体网络有三个相同的子网络。我们将向模型提供三张图片,其中两张是相似的(锚和正样本),第三张是不相关的(负样本)。
为了让网络学习,我们使用了三重损失函数。您可以在 Schroff 等人 2015 年发表的 FaceNet 论文中找到有关三重损失的介绍。
在本例中,我们将三重损失函数定义如下:
L(A, P, N) = max(‖f(A) - f(P)‖² - ‖f(A) - f(N)‖² + margin, 0)
设置
import matplotlib.pyplot as plt
import numpy as np
import os
import random
import tensorflow as tf
from pathlib import Path
from keras import applications
from keras import layers
from keras import losses
from keras import ops
from keras import optimizers
from keras import metrics
from keras import Model
from keras.applications import resnet
target_shape = (200, 200)加载数据集
我们将加载 Totally Looks Like 数据集,并将其解压缩到本地环境中的 ~/.keras 目录中。
数据集由两个独立文件组成:
left.zip 包含我们将用作锚点的图像。
right.zip包含我们将用作正样本(与锚点相似的图像)的图像。
cache_dir = Path(Path.home()) / ".keras"
anchor_images_path = cache_dir / "left"
positive_images_path = cache_dir / "right"!gdown --id 1jvkbTr_giSP3Ru8OwGNCg6B4PvVbcO34
!gdown --id 1EzBZUb_mh_Dp_FKD0P4XiYYSd0QBH5zW
!unzip -oq left.zip -d $cache_dir
!unzip -oq right.zip -d $cache_dir演绎展示:
Downloading...
From (uriginal): https://drive.google.com/uc?id=1jvkbTr_giSP3Ru8OwGNCg6B4PvVbcO34
From (redirected): https://drive.google.com/uc?id=1jvkbTr_giSP3Ru8OwGNCg6B4PvVbcO34&confirm=t&uuid=be98abe4-8be7-4c5f-a8f9-ca95d178fbda
To: /home/scottzhu/keras-io/scripts/tmp_9629511/left.zip
100%|█████████████████████████████████████████| 104M/104M [00:00<00:00, 278MB/s]
/home/scottzhu/.local/lib/python3.10/site-packages/gdown/cli.py:126: FutureWarning: Option `--id` was deprecated in version 4.3.1 and will be removed in 5.0. You don't need to pass it anymore to use a file ID.
Downloading...
From (uriginal): https://drive.google.com/uc?id=1EzBZUb_mh_Dp_FKD0P4XiYYSd0QBH5zW
From (redirected): https://drive.google.com/uc?id=1EzBZUb_mh_Dp_FKD0P4XiYYSd0QBH5zW&confirm=t&uuid=0eb1b2e2-beee-462a-a9b8-c0bf21bea257
To: /home/scottzhu/keras-io/scripts/tmp_9629511/right.zip
100%|█████████████████████████████████████████| 104M/104M [00:00<00:00, 285MB/s]准备数据
我们将使用 tf.data 管道加载数据,并生成训练连体网络所需的三元组。
我们将使用一个包含锚文件名、正文件名和负文件名的压缩列表作为源文件来设置管道。管道将加载并预处理相应的图像。
def preprocess_image(filename):
"""
Load the specified file as a JPEG image, preprocess it and
resize it to the target shape.
"""
image_string = tf.io.read_file(filename)
image = tf.image.decode_jpeg(image_string, channels=3)
image = tf.image.convert_image_dtype(image, tf.float32)
image = tf.image.resize(image, target_shape)
return image
def preprocess_triplets(anchor, positive, negative):
"""
Given the filenames corresponding to the three images, load and
preprocess them.
"""
return (
preprocess_image(anchor),
preprocess_image(positive),
preprocess_image(negative),
)让我们使用一个以锚、正片和负片图像文件名为源的压缩列表来设置我们的数据管道。管道的输出包含已加载和预处理的每张图像的相同三元组。
# We need to make sure both the anchor and positive images are loaded in
# sorted order so we can match them together.
anchor_images = sorted(
[str(anchor_images_path / f) for f in os.listdir(anchor_images_path)]
)
positive_images = sorted(
[str(positive_images_path / f) for f in os.listdir(positive_images_path)]
)
image_count = len(anchor_images)
anchor_dataset = tf.data.Dataset.from_tensor_slices(anchor_images)
positive_dataset = tf.data.Dataset.from_tensor_slices(positive_images)
# To generate the list of negative images, let's randomize the list of
# available images and concatenate them together.
rng = np.random.RandomState(seed=42)
rng.shuffle(anchor_images)
rng.shuffle(positive_images)
negative_images = anchor_images + positive_images
np.random.RandomState(seed=32).shuffle(negative_images)
negative_dataset = tf.data.Dataset.from_tensor_slices(negative_images)
negative_dataset = negative_dataset.shuffle(buffer_size=4096)
dataset = tf.data.Dataset.zip((anchor_dataset, positive_dataset, negative_dataset))
dataset = dataset.shuffle(buffer_size=1024)
dataset = dataset.map(preprocess_triplets)
# Let's now split our dataset in train and validation.
train_dataset = dataset.take(round(image_count * 0.8))
val_dataset = dataset.skip(round(image_count * 0.8))
train_dataset = train_dataset.batch(32, drop_remainder=False)
train_dataset = train_dataset.prefetch(tf.data.AUTOTUNE)
val_dataset = val_dataset.batch(32, drop_remainder=False)
val_dataset = val_dataset.prefetch(tf.data.AUTOTUNE)让我们来看几个三连拍的例子。请注意,前两幅图像看起来很相似,而第三幅总是不同的。
def visualize(anchor, positive, negative):
"""Visualize a few triplets from the supplied batches."""
def show(ax, image):
ax.imshow(image)
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
fig = plt.figure(figsize=(9, 9))
axs = fig.subplots(3, 3)
for i in range(3):
show(axs[i, 0], anchor[i])
show(axs[i, 1], positive[i])
show(axs[i, 2], negative[i])
visualize(*list(train_dataset.take(1).as_numpy_iterator())[0])演绎展示:

设置嵌入生成器模型
我们的连体网络将为三胞胎中的每个图像生成嵌入。为此,我们将使用在 ImageNet 上预先训练好的 ResNet50 模型,并在其中连接几个 Dense 层,以便学习如何分离这些嵌入。
我们将冻结模型所有层的权重,直到层 conv5_block1_out。这对于避免影响模型已经学习到的权重非常重要。我们将保留可训练的底层,以便在训练过程中微调它们的权重。
base_cnn = resnet.ResNet50(
weights="imagenet", input_shape=target_shape + (3,), include_top=False
)
flatten = layers.Flatten()(base_cnn.output)
dense1 = layers.Dense(512, activation="relu")(flatten)
dense1 = layers.BatchNormalization()(dense1)
dense2 = layers.Dense(256, activation="relu")(dense1)
dense2 = layers.BatchNormalization()(dense2)
output = layers.Dense(256)(dense2)
embedding = Model(base_cnn.input, output, name="Embedding")
trainable = False
for layer in base_cnn.layers:
if layer.name == "conv5_block1_out":
trainable = True
layer.trainable = trainable建立连体网络模型
连体网络将接收每张三连拍图像作为输入,生成嵌入,并输出锚点与正嵌入之间的距离,以及锚点与负嵌入之间的距离。
为了计算距离,我们可以使用一个自定义层 DistanceLayer,它可以将两个值作为一个元组返回。
class DistanceLayer(layers.Layer):
"""
This layer is responsible for computing the distance between the anchor
embedding and the positive embedding, and the anchor embedding and the
negative embedding.
"""
def __init__(self, **kwargs):
super().__init__(**kwargs)
def call(self, anchor, positive, negative):
ap_distance = ops.sum(tf.square(anchor - positive), -1)
an_distance = ops.sum(tf.square(anchor - negative), -1)
return (ap_distance, an_distance)
anchor_input = layers.Input(name="anchor", shape=target_shape + (3,))
positive_input = layers.Input(name="positive", shape=target_shape + (3,))
negative_input = layers.Input(name="negative", shape=target_shape + (3,))
distances = DistanceLayer()(
embedding(resnet.preprocess_input(anchor_input)),
embedding(resnet.preprocess_input(positive_input)),
embedding(resnet.preprocess_input(negative_input)),
)
siamese_network = Model(
inputs=[anchor_input, positive_input, negative_input], outputs=distances
)将一切整合在一起
现在,我们需要实现一个带有自定义训练循环的模型,这样就能利用连体网络生成的三个嵌入计算三重损失。
让我们创建一个平均度量实例来跟踪训练过程中的损失。
class SiameseModel(Model):
"""The Siamese Network model with a custom training and testing loops.
Computes the triplet loss using the three embeddings produced by the
Siamese Network.
The triplet loss is defined as:
L(A, P, N) = max(‖f(A) - f(P)‖² - ‖f(A) - f(N)‖² + margin, 0)
"""
def __init__(self, siamese_network, margin=0.5):
super().__init__()
self.siamese_network = siamese_network
self.margin = margin
self.loss_tracker = metrics.Mean(name="loss")
def call(self, inputs):
return self.siamese_network(inputs)
def train_step(self, data):
# GradientTape is a context manager that records every operation that
# you do inside. We are using it here to compute the loss so we can get
# the gradients and apply them using the optimizer specified in
# `compile()`.
with tf.GradientTape() as tape:
loss = self._compute_loss(data)
# Storing the gradients of the loss function with respect to the
# weights/parameters.
gradients = tape.gradient(loss, self.siamese_network.trainable_weights)
# Applying the gradients on the model using the specified optimizer
self.optimizer.apply_gradients(
zip(gradients, self.siamese_network.trainable_weights)
)
# Let's update and return the training loss metric.
self.loss_tracker.update_state(loss)
return {"loss": self.loss_tracker.result()}
def test_step(self, data):
loss = self._compute_loss(data)
# Let's update and return the loss metric.
self.loss_tracker.update_state(loss)
return {"loss": self.loss_tracker.result()}
def _compute_loss(self, data):
# The output of the network is a tuple containing the distances
# between the anchor and the positive example, and the anchor and
# the negative example.
ap_distance, an_distance = self.siamese_network(data)
# Computing the Triplet Loss by subtracting both distances and
# making sure we don't get a negative value.
loss = ap_distance - an_distance
loss = tf.maximum(loss + self.margin, 0.0)
return loss
@property
def metrics(self):
# We need to list our metrics here so the `reset_states()` can be
# called automatically.
return [self.loss_tracker]训练
现在我们准备训练模型。
siamese_model = SiameseModel(siamese_network)
siamese_model.compile(optimizer=optimizers.Adam(0.0001))
siamese_model.fit(train_dataset, epochs=10, validation_data=val_dataset)Epoch 1/10
1/151 [37m━━━━━━━━━━━━━━━━━━━━ 1:21:32 33s/step - loss: 1.5020
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1699919378.193493 9680 device_compiler.h:187] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
151/151 ━━━━━━━━━━━━━━━━━━━━ 80s 317ms/step - loss: 0.7004 - val_loss: 0.3704
Epoch 2/10
151/151 ━━━━━━━━━━━━━━━━━━━━ 20s 136ms/step - loss: 0.3749 - val_loss: 0.3609
Epoch 3/10
151/151 ━━━━━━━━━━━━━━━━━━━━ 21s 140ms/step - loss: 0.3548 - val_loss: 0.3399
Epoch 4/10
151/151 ━━━━━━━━━━━━━━━━━━━━ 20s 135ms/step - loss: 0.3432 - val_loss: 0.3533
Epoch 5/10
151/151 ━━━━━━━━━━━━━━━━━━━━ 20s 134ms/step - loss: 0.3299 - val_loss: 0.3522
Epoch 6/10
151/151 ━━━━━━━━━━━━━━━━━━━━ 20s 135ms/step - loss: 0.3263 - val_loss: 0.3177
Epoch 7/10
151/151 ━━━━━━━━━━━━━━━━━━━━ 20s 134ms/step - loss: 0.3032 - val_loss: 0.3308
Epoch 8/10
151/151 ━━━━━━━━━━━━━━━━━━━━ 20s 134ms/step - loss: 0.2944 - val_loss: 0.3282
Epoch 9/10
151/151 ━━━━━━━━━━━━━━━━━━━━ 20s 135ms/step - loss: 0.2893 - val_loss: 0.3046
Epoch 10/10
151/151 ━━━━━━━━━━━━━━━━━━━━ 20s 134ms/step - loss: 0.2679 - val_loss: 0.2841
<keras.src.callbacks.history.History at 0x7f6945c08820>检查网络的学习成果
此时,我们可以检查网络是如何学会根据是否属于相似图像来分离嵌入的。
我们可以使用余弦相似度来衡量嵌入式之间的相似性。
让我们从数据集中选取一个样本,检查为每张图像生成的嵌入式之间的相似性。
sample = next(iter(train_dataset))
visualize(*sample)
anchor, positive, negative = sample
anchor_embedding, positive_embedding, negative_embedding = (
embedding(resnet.preprocess_input(anchor)),
embedding(resnet.preprocess_input(positive)),
embedding(resnet.preprocess_input(negative)),
)
最后,我们可以计算锚点和正像之间的余弦相似度,并将其与锚点和负像之间的相似度进行比较。
我们应该期望锚点和正图像之间的相似度大于锚点和负图像之间的相似度。
cosine_similarity = metrics.CosineSimilarity()
positive_similarity = cosine_similarity(anchor_embedding, positive_embedding)
print("Positive similarity:", positive_similarity.numpy())
negative_similarity = cosine_similarity(anchor_embedding, negative_embedding)
print("Negative similarity", negative_similarity.numpy())演绎展示:
Positive similarity: 0.99608964
Negative similarity 0.9941576摘要
通过 tf.data API,您可以为模型建立高效的输入管道。如果您有一个大型数据集,它尤其有用。有关 tf.data 管道的更多信息,请参阅 tf.data:构建 TensorFlow 输入管道。
在本例中,我们使用预先训练好的 ResNet50 作为生成特征嵌入的子网络的一部分。
通过使用迁移学习,我们可以大大减少训练时间和数据集的大小。
请注意,我们对 ResNet50 网络最后几层的权重进行了微调,但其余各层保持不变。利用分配给各层的名称,我们可以将权重冻结在某一点上,并保持最后几层的开放。
我们可以创建一个继承自 tf.keras.layers.Layer 的类来创建自定义层,就像我们在 DistanceLayer 类中所做的那样。
我们使用余弦相似度指标来衡量两个输出嵌入的相似程度。
train_step() 使用了 tf.GradientTape,它会记录你在其中执行的每个操作。在本例中,我们使用它访问传递给优化器的梯度,以便在每一步更新模型权重。更多详情,请查看 Keras 入门(面向研究人员)和从头开始编写训练循环。




![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-8.1](https://img-blog.csdnimg.cn/direct/cc35d49f3146474487d83473a00c4d9e.png)