问题背景:
用户在对一套Oracle11.2.0.4的RAC集群进行OCR掉盘测试,验证NORMAL冗余的OCR磁盘组的可用性。测试通过将udev配置里面的一块OCR盘注释,然后重启服务器集群模拟OCR磁盘组出现掉盘的情况。用户在测试中,注释掉udev配置里面的一块OCR磁盘asm-ocr02之后,重启集群没有按照预想依靠剩余两块OCR磁盘asm-ocr01/asm-ocr03正常启动,因此,想分析集群在丢掉一块OCR盘之后为什么无法正常启动以及NORMAL冗余的OCR磁盘组,磁盘组是否具备冗余作用。
问题分析:
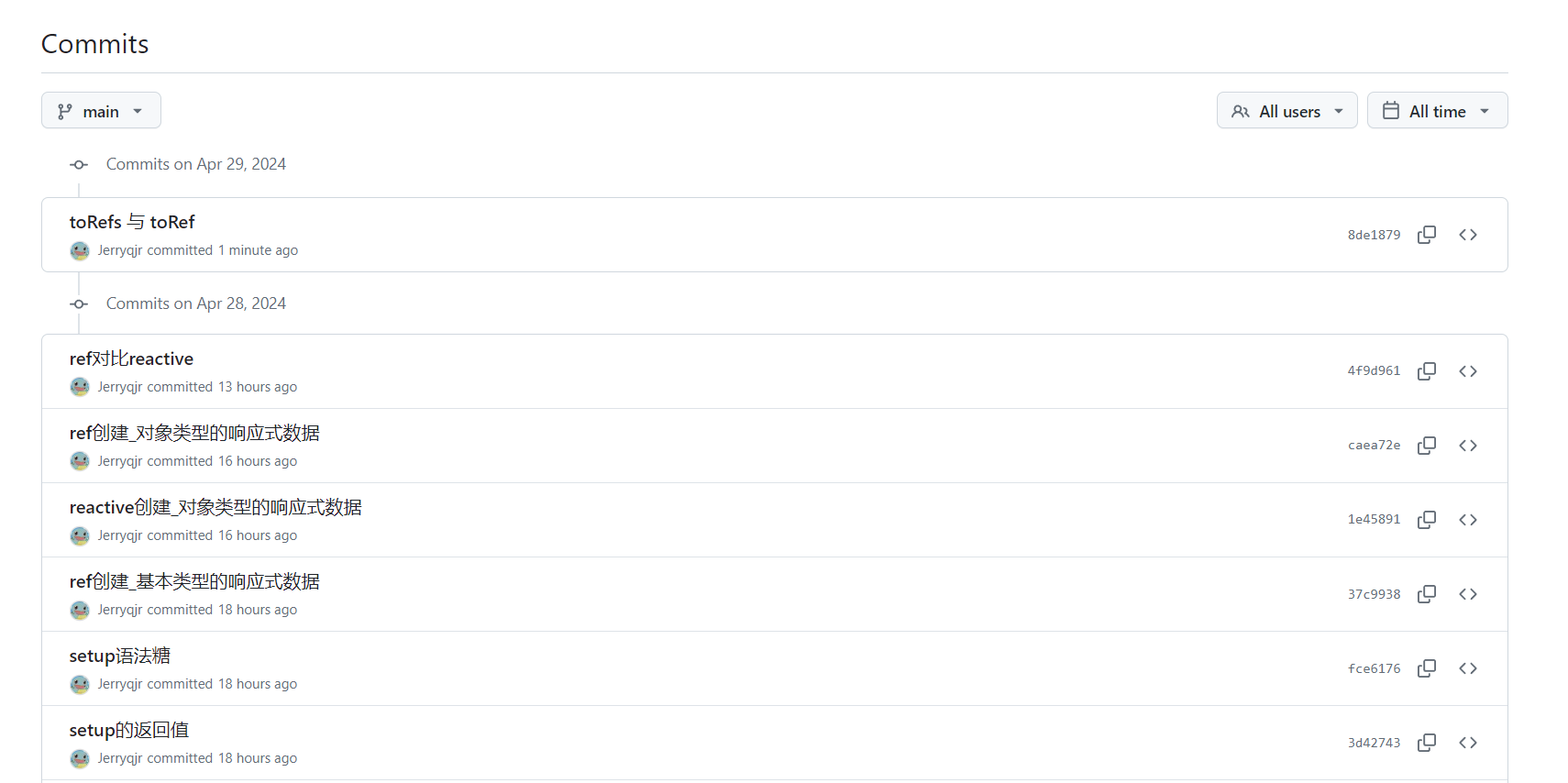
检查集群的进程状态和启动alert日志,可以看到集群只有OHASD服务进程启动,在启动OCSSD进程时失败停止。
检查OCSSD进程的trc日志,可以看到OCSSD进程只成功确认了asm-ocr03磁盘的状态,asm-ocr01磁盘也被OCSSD进程发现,但由于从asm-ocr01磁盘发现的cluster guid与gpnp profile里面的guid不匹配,导致该磁盘不能被OCSSD进程所使用,因此,当前OCSSD进程只发现了一块OCR盘,不满足至少两块OCR磁盘的要求,所以集群无法正常启动。
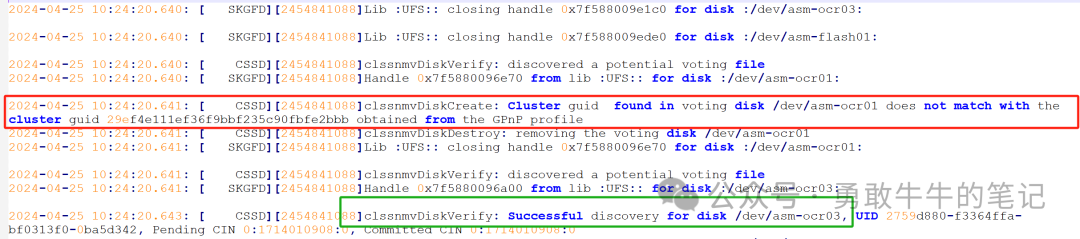
检查节点本地的gpnp profile里面的cluster guid信息,跟OCSSD进程日志日志里面显示的一致,都为29ef4e111ef36f9bbf235c90fbfe2bbb,进一步排查cluster guid不一致的原因。

cluster guid不一致,除了OCR磁盘属于其他集群和集群安装问题导致之外,还有可能是磁盘之前已经被从OCR磁盘组剔除导致,检查asm的alert日志,可以看到OCRDG之前已经drop过disk ocrdg_0000,从磁盘号来看这个磁盘应该就是asm-ocr01。

为了验证以上分析,我们先将udev配置里面注释的asm-ocr02磁盘恢复正常,让集群可以正常的启动,然后再次查看OCR磁盘组使用情况,可以看到磁盘asm-ocr01的确已经被剔除OCR磁盘组,所以检查asm-ocr01会发现cluster guid不一致的情况

问题修复:
需要先将asm-ocr01通过force add disk或是dd磁盘头再add disk的方式重新加回OCR磁盘组,再重新进行掉盘测试。
在进行掉盘测试时,集群OHASD,OCSSD进程可以正常启动,但CRSD服务进程会无法正常启动,这是由于OCR磁盘组无法自动正常挂载导致,因为掉的OCR磁盘还没正式从OCR磁盘组里面删除,所以自动mount的时候会发现磁盘找不到的问题,出现以下ORA-15032/15040/15042错误:
ORA-15032: not all alterations performed
ORA-15040: diskgroup is incomplete
ORA-15042: ASM disk "0" is missing from group number "2"
在这种情况下可以通过手动强制alter diskgroup OCRDG mount force的方式,将OCR磁盘组强制拉起,然后再恢复集群的CRSD服务以及数据库。
Tip:欢迎关注公众号:勇敢牛牛的笔记,超100+的原创内容,每周不定期更新数据库技术文章

![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-8.1](https://img-blog.csdnimg.cn/direct/cc35d49f3146474487d83473a00c4d9e.png)