场景文本检测识别学习 day07(BERT论文精读)
在CV领域,可以通过训练一个大的CNN模型作为预训练模型,来帮助其他任务提高各自模型的性能,但是在NLP领域,没有这样的模型,而BERT的提出,解决了这个问题 BERT和GPT、ELMO的区别:
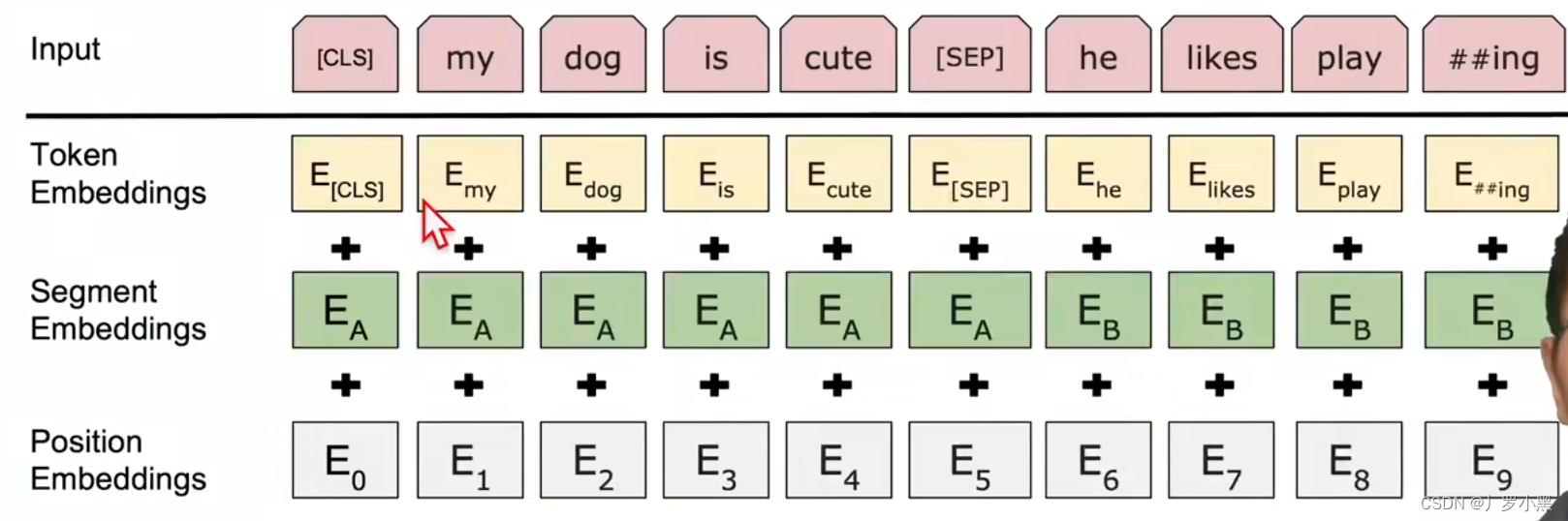
BERT是用来预训练深双向的表示,并且使用没有标号的数据,同时上下文信息是左右都可以用来推测。而训练好的BERT只需要增加一个输出层就可以在很多NLP的任务上得到不错的结果,同时不需要对模型进行很多针对下游任务的改动 GPT使用了新架构Transformer,但是只能从单向(左侧)的上下文信息来推测,ELMO虽然可以双向,但是架构比较老–RNN,则在用到下游的任务时,需要对模型进行针对任务的改动 语言模型过去只有单向,没有双向,而在预训练的任务中,双向应该可以更好的表示特征,因此为了解决这个问题,BERT提出了双向表征,这是通过带掩码的语言模型来实现的,即给定一个句子,挖掉其中的一个词,然后根据词的左右两边的上下文来预测该位置的词是什么 但这样来说,BERT模型就不是预测未来的语言模型,而是类似完形填空的语言模型 由于BERT的数据量很大,所以直接按照空格来切词,那么生成的词典大小会特别大(百万级别),会占用很多学习参数来生成词典。因此BERT切词策略为WordPiece:将出现频率不高的词切开,观察它的子序列的出现频率,如果频率很高那么保留这个子序列,作为词根就可以了,最后的词典大小为30000左右。 由于Transformer的输入为一个序列(一个句子或两个句子):编码器和解码器都有输入,因此Transformer可以处理需要一个输入句子的下游任务,也可以处理需要两个输入句子的下游任务 但是BERT只有一个编码器,所以它想解决需要两个输入句子的下游任务,就需要将两个输入句子变成一个序列。同时在一个序列中判断这些词分别是哪个输入句子,是通过一个段嵌入来实现,并且在两个句子之间通过 [SEP] 来区分 BERT的输入序列的第一个词为 [CLS],并用这个词的输出作为整个序列的输出(因为有自注意力层,所以这个词可以看作拥有整个序列的信息),位置嵌入的大小为序列中最长词元的长度 不同于Transformer,而BERT的位置嵌入和哪一个句子的嵌入,都是通过学习得来的 综上:进入BERT的序列嵌入为:词元本身的嵌入 + 词元在哪一个句子的嵌入 + 位置嵌入 BERT流程:
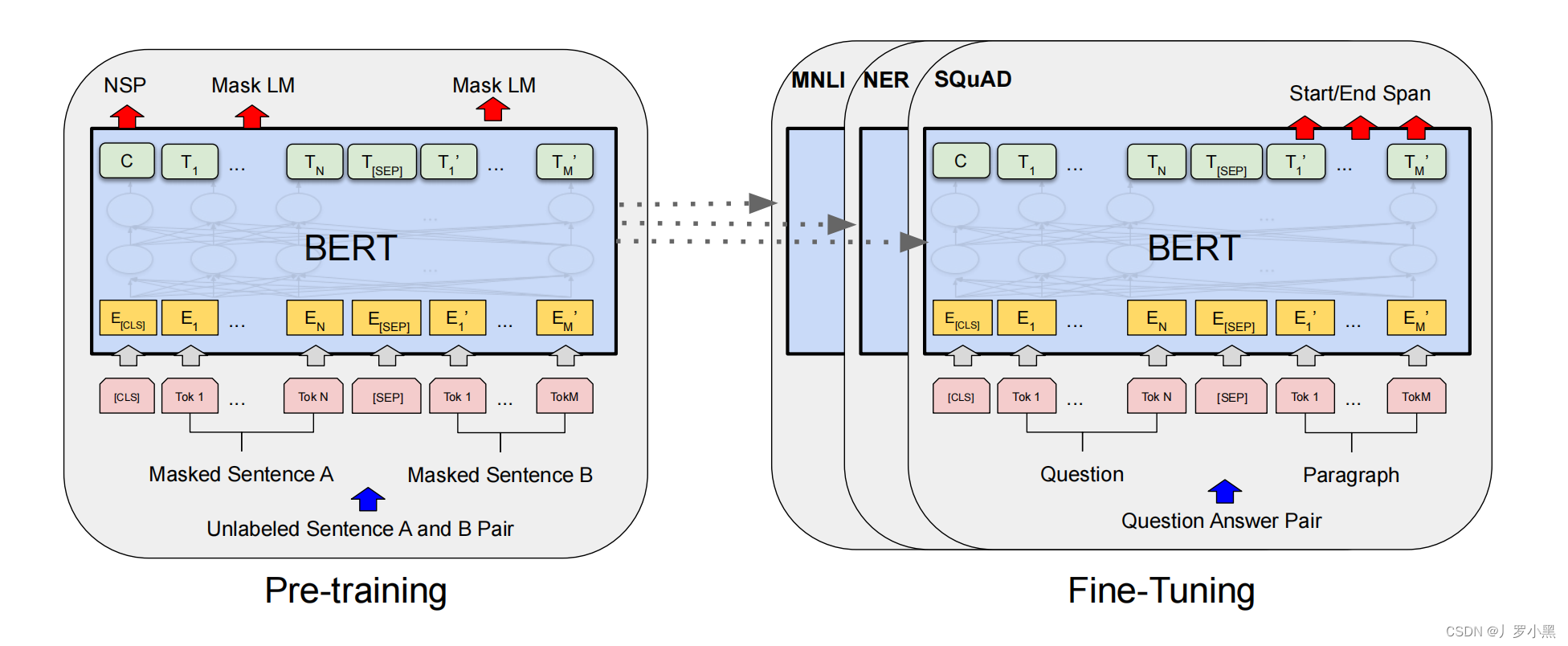
将一个输入序列转换为词嵌入,并加上 [CLS]、[SEP]、位置编码,作为BERT的输入 输入经过很多个transformer encoder块后,在最后一个encoder块得到整个输入序列的BERT输出表示 在BERT后,添加额外的输出层来得到下游任务的具体结果 BERT模型主要解决两种问题:MLM:完形填空,随机选择一些单词并用[MASK]来替换它们,模型的任务是预测被替换的单词。NSP:预测一个句子是否是另一个句子的下一句 由于Transformer采用的编码器-解码器架构,输入序列是分成两部分,分别输入到编码器和解码器的,所以一个注意力层不能同时拿到完整的输入序列。但是BERT是编码器架构,输入序列是完整的输入到编码器的,所以一个注意力层可以同时看到完整的输入序列,但是因此BERT做机器翻译也就不是很好做了 通过在一个大数据集上预训练一个模型,将这个模型应用在其他任务上,并使在其他数据集上训练的其他模型性能有提高 在BERT中,是将BERT模型在一个没有标号的大数据集上预训练,然后在多个下游任务中都初始化一个新的BERT模型(权重参数使用上一步预训练好的),之后对模型进行微调参数,得到一个适配该下游任务的BERT模型 使用预训练模型来做特征表示的时候,有以下两种策略:
基于特征:对于每一个下游任务,都要构建一个新的模型,并将在预训练模型中训练好的表示(作为额外特征)和输入一起输入进新的模型中,由于额外特征意见有了比较好的表示,所以新模型训练起来比较容易 基于微调:对于每一个下游任务,将预训练好的模型直接放进下游任务模型中,并根据下游任务的数据集,稍微修改(微调)模型的参数
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1633634.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!



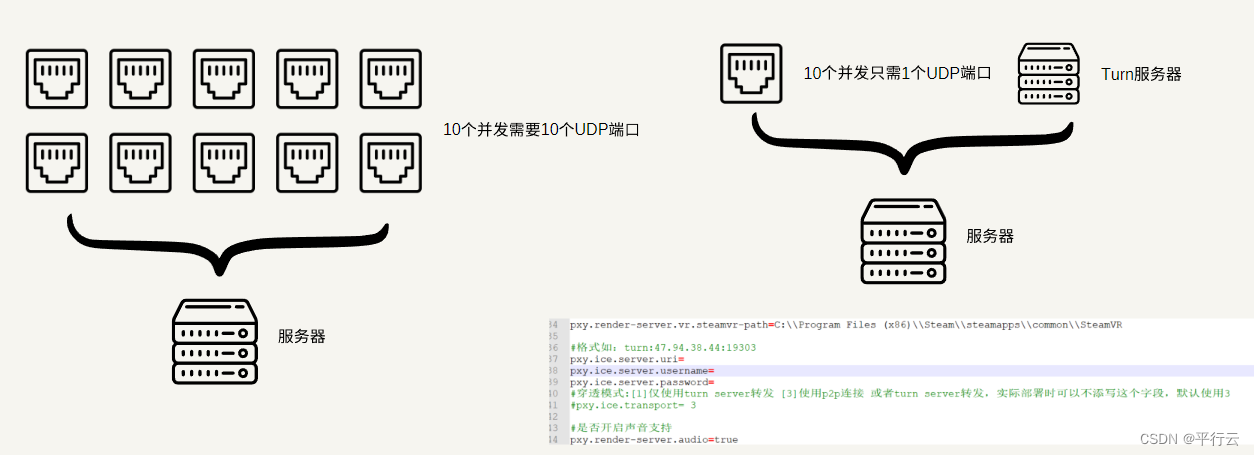


![[详解]Spring AOP](https://img-blog.csdnimg.cn/direct/8867272fd9bd40e1a0ff4cb4ceac3fee.png)