在深度优先遍历中:有三个顺序,前中后序遍历 这里前中后,其实指的就是中间节点的遍历顺序,只要记住 前中后序指的就是中间节点的位置就可以了。
如图
1二叉树的前序遍历
给你二叉树的根节点 root ,返回它节点值的 前序 遍历。
示例 1:
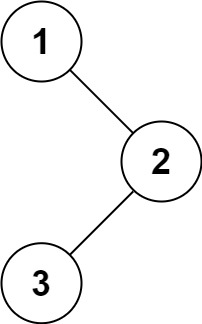
输入:root = [1,null,2,3] 输出:[1,2,3]
示例 2:
输入:root = [] 输出:[]
示例 3:
输入:root = [1] 输出:[1]
示例 4:

输入:root = [1,2] 输出:[1,2]
示例 5:

输入:root = [1,null,2] 输出:[1,2]
提示:
- 树中节点数目在范围
[0, 100]内 -100 <= Node.val <= 100
递归思路:
递归是一种在算法中使用函数自身来解决问题的方法。在递归算法中,函数会重复调用自身来处理问题的每一步,直到达到某个终止条件为止。递归算法通常包括三个重要部分:
-
确定递归函数的参数和返回值:确定哪些参数是递归过程中需要处理的,以及每次递归的返回值是什么进而确定递归函数的返回类型。
-
确定终止条件:为了避免无限循环或栈溢出错误,在递归算法中必须定义递归终止的条件,当满足终止条件时递归停止。
-
确定单层递归的逻辑:确定每一层递归需要处理的信息,并实现递归过程。通常在单层递归的逻辑中包含当前节点的处理逻辑以及对子节点的递归调用。
在递归算法中,需要注意以下几点:
-
确定递归函数的参数和返回值:在这段代码中,递归函数的参数为当前节点指针和存储节点值的数组,返回类型为void。这样做可以处理当前节点的值并在递归过程中更新结果数组。
-
确定终止条件:在递归中,一定要有终止条件,否则会导致栈溢出错误。在这段代码中,终止条件是当前节点为空(cur == NULL),此时直接返回,结束当前递归。
-
确定单层递归的逻辑:在前序遍历中,需要先处理当前节点的值,然后递归遍历左子树,最后递归遍历右子树。这种顺序符合前序遍历的要求。
代码:
class Solution {
public:
// 定义一个辅助函数,用来递归遍历二叉树并将节点值存入结果数组
void traversal(TreeNode* cur, vector<int>& vec) {
// 若当前节点为空,则返回
if (cur == NULL) return;
vec.push_back(cur->val); // 中序遍历,将当前节点的值加入结果数组
traversal(cur->left, vec); // 递归遍历左子树
traversal(cur->right, vec); // 递归遍历右子树
}
// 定义前序遍历函数,返回一个存储节点值的数组
vector<int> preorderTraversal(TreeNode* root) {
vector<int> result;
// 从根节点开始遍历
traversal(root, result); // 调用辅助函数,从根节点开始前序遍历
return result;
}
};
迭代思路:
迭代的思想是通过循环重复执行某段代码来解决问题,而不是通过递归的方式调用函数自身。迭代通常通过循环结构来实现,每次循环迭代处理一部分信息,直到达到预定的终止条件为止。
栈的特点是一种后进先出(LIFO)的数据结构,即最后入栈的元素会最先出栈
前序遍历的迭代法思路是通过使用栈数据结构来模拟递归的过程。具体步骤如下:
-
创建一个栈(stack)用于存储节点指针和一个结果数组(result)用于存储节点值。
-
将根节点压入栈中。
-
循环执行以下操作,直到栈为空:
a. 弹出栈顶节点(当前访问的节点)。
b. 将节点值加入结果数组。
c. 如果节点的右子节点不为空,则将右子节点压入栈中。
d. 如果节点的左子节点不为空,则将左子节点压入栈中。 -
遍历结束后,返回结果数组作为前序遍历的结果。
代码:
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
stack<TreeNode*> st; // 定义栈用来存储节点指针
vector<int> result; // 定义结果数组
if (root == NULL) return result; // 如果根节点为空则直接返回空数组
st.push(root); // 将根节点压入栈中
while (!st.empty()) {
TreeNode* node = st.top(); // 获取栈顶节点
st.pop(); // 弹出栈顶节点
result.push_back(node->val); // 将节点值加入结果数组
if (node->right) st.push(node->right); // 若右子节点不为空,则压入栈中
if (node->left) st.push(node->left); // 若左子节点不为空,则压入栈中
}
return result; // 返回结果数组
}
};2二叉树的后序遍历
给你一棵二叉树的根节点 root ,返回其节点值的 后序遍历 。
示例 1:
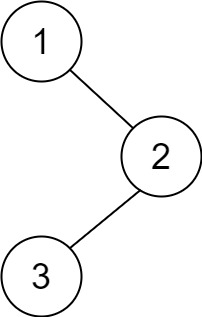
输入:root = [1,null,2,3] 输出:[3,2,1]
示例 2:
输入:root = [] 输出:[]
示例 3:
输入:root = [1] 输出:[1]
提示:
- 树中节点的数目在范围
[0, 100]内 -100 <= Node.val <= 100
递归思路 代码:
class Solution {
public:
// 定义一个辅助函数,用来递归遍历二叉树并将节点值存入结果数组(后序遍历)
void traversal(TreeNode *cur, vector<int>& vec) {
if (cur == nullptr) return;
traversal(cur->left, vec); // 递归遍历当前节点的左子树
traversal(cur->right, vec); // 递归遍历当前节点的右子树
vec.push_back(cur->val); // 将当前节点的值加入结果数组
}
// 定义后序遍历函数,返回一个存储节点值的数组
vector<int> postorderTraversal(TreeNode* root) {
vector<int> result;
traversal(root, result); // 开始后序遍历,将结果存入数组
return result;
}
};迭代思路
-
栈的应用:题目要求实现二叉树的后序遍历,可以考虑使用栈来辅助实现。栈可以帮助我们模拟递归的过程,从而遍历树的节点。
-
迭代法的核心:迭代法的核心是通过循环结构不断处理节点,模拟递归的过程。在后序遍历中,节点的访问顺序是左子树、右子树、根节点,因此我们需要注意入栈的顺序。
-
遍历过程:从根节点开始,将根节点入栈。然后循环执行以下步骤:
- 弹出栈顶节点,将其值加入结果数组。
- 如果节点有右子节点,则将右子节点压入栈中。
- 如果节点有左子节点,则将左子节点压入栈中。
-
结果反转:由于后序遍历的顺序是左子树、右子树、根节点,而我们入栈的顺序是根节点、右子节点、左子节点,因此得到的结果数组需要进行反转。
-
返回结果:最后返回反转后的结果数组即可。
-

代码:
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
stack<TreeNode*> st; // 定义栈用来存储节点指针
vector<int> result; // 定义结果数组
if (root == NULL) return result; // 如果根节点为空则直接返回空数组
st.push(root); // 将根节点压入栈中
while (!st.empty()) {
TreeNode* node = st.top(); // 获取栈顶节点
st.pop(); // 弹出栈顶节点
result.push_back(node->val); // 将节点值加入结果数组
if (node->left) st.push(node->left); // 若左子节点不为空,则压入栈中
if (node->right) st.push(node->right); // 若右子节点不为空,则压入栈中
}
reverse(result.begin(), result.end()); // 将结果数组反转,得到左右中的遍历顺序
return result; // 返回结果数组
}
};3二叉树的中序遍历
给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。
示例 1:
输入:root = [1,null,2,3] 输出:[1,3,2]
示例 2:
输入:root = [] 输出:[]
示例 3:
输入:root = [1] 输出:[1]
提示:
- 树中节点数目在范围
[0, 100]内 -100 <= Node.val <= 100
递归思路 代码:
class Solution {
public:
// 定义一个辅助函数,用来递归遍历二叉树并将节点值存入结果数组(中序遍历)
void traversal(TreeNode* cur, vector<int>& vec) {
if (cur == nullptr) return;
traversal(cur->left, vec); // 递归遍历当前节点的左子树
vec.push_back(cur->val); // 将当前节点的值加入结果数组
traversal(cur->right, vec); // 递归遍历当前节点的右子树
}
// 定义中序遍历函数,返回一个存储节点值的数组
vector<int> inorderTraversal(TreeNode* root) {
vector<int> result;
traversal(root, result); // 开始中序遍历,将结果存入数组
return result;
}
};迭代思路
-
栈的应用:使用栈来辅助实现中序遍历。栈可以帮助我们模拟递归的过程,从而遍历树的节点。
-
指针的运用:我们使用一个指针
cur来遍历节点,初始时指向根节点。 -
循环遍历:我们使用一个while循环来遍历节点,直到当前节点为NULL且栈为空为止。在循环中,我们检查当前节点
cur是否为空,以及栈是否为空。 -
处理当前节点:
- 如果
cur不为空,说明还有左子树未遍历完,此时我们将当前节点入栈,并将cur指向其左子节点,以便继续向左遍历。 - 如果
cur为空,说明左子树已经遍历完毕,我们从栈中取出节点进行处理。这个节点就是当前子树的根节点,我们将其值加入结果数组,并将cur指向当前节点的右子节点。
- 如果
-
遍历过程:
- 不断将左子节点入栈,直到到达最左侧节点。在入栈的过程中,保证了左、中、右的顺序。
- 当一个节点的左子树全部处理完毕后,从栈中取出节点进行处理,然后转向处理右子树。
-
返回结果:最终返回中序遍历的结果数组。
代码:
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int> result; // 定义结果数组
stack<TreeNode*> st; // 定义栈用来存储节点指针
TreeNode* cur = root; // 初始化当前节点为根节点
while (cur != NULL || !st.empty()) {
if (cur != NULL) { // 如果当前节点不为空
st.push(cur); // 将当前节点入栈
cur = cur->left; // 移动到左子节点
} else {
cur = st.top(); // 从栈中取出节点进行处理
st.pop(); // 弹出栈顶节点
result.push_back(cur->val); // 将节点值加入结果数组
cur = cur->right; // 移动到右子节点
}
}
return result; // 返回结果数组
}
};4学生们参加各科测试的次数
学生表: Students
+---------------+---------+ | Column Name | Type | +---------------+---------+ | student_id | int | | student_name | varchar | +---------------+---------+ 在 SQL 中,主键为 student_id(学生ID)。 该表内的每一行都记录有学校一名学生的信息。
科目表: Subjects
+--------------+---------+ | Column Name | Type | +--------------+---------+ | subject_name | varchar | +--------------+---------+ 在 SQL 中,主键为 subject_name(科目名称)。 每一行记录学校的一门科目名称。
考试表: Examinations
+--------------+---------+ | Column Name | Type | +--------------+---------+ | student_id | int | | subject_name | varchar | +--------------+---------+ 这个表可能包含重复数据(换句话说,在 SQL 中,这个表没有主键)。 学生表里的一个学生修读科目表里的每一门科目。 这张考试表的每一行记录就表示学生表里的某个学生参加了一次科目表里某门科目的测试。
查询出每个学生参加每一门科目测试的次数,结果按 student_id 和 subject_name 排序。
查询结构格式如下所示。
示例 1:
输入: Students table: +------------+--------------+ | student_id | student_name | +------------+--------------+ | 1 | Alice | | 2 | Bob | | 13 | John | | 6 | Alex | +------------+--------------+ Subjects table: +--------------+ | subject_name | +--------------+ | Math | | Physics | | Programming | +--------------+ Examinations table: +------------+--------------+ | student_id | subject_name | +------------+--------------+ | 1 | Math | | 1 | Physics | | 1 | Programming | | 2 | Programming | | 1 | Physics | | 1 | Math | | 13 | Math | | 13 | Programming | | 13 | Physics | | 2 | Math | | 1 | Math | +------------+--------------+ 输出: +------------+--------------+--------------+----------------+ | student_id | student_name | subject_name | attended_exams | +------------+--------------+--------------+----------------+ | 1 | Alice | Math | 3 | | 1 | Alice | Physics | 2 | | 1 | Alice | Programming | 1 | | 2 | Bob | Math | 1 | | 2 | Bob | Physics | 0 | | 2 | Bob | Programming | 1 | | 6 | Alex | Math | 0 | | 6 | Alex | Physics | 0 | | 6 | Alex | Programming | 0 | | 13 | John | Math | 1 | | 13 | John | Physics | 1 | | 13 | John | Programming | 1 | +------------+--------------+--------------+----------------+ 解释: 结果表需包含所有学生和所有科目(即便测试次数为0): Alice 参加了 3 次数学测试, 2 次物理测试,以及 1 次编程测试; Bob 参加了 1 次数学测试, 1 次编程测试,没有参加物理测试; Alex 啥测试都没参加; John 参加了数学、物理、编程测试各 1 次。
思路:
使用join语句将学生表 (students) 和课程表 (subjects) 进行连接,以获取学生和课程的相关信息。使用left join语句将考试表 (examinations) 与学生、课程表进行左连接,确保即使某些学生没有参加考试,也能包括在结果中。
在on子句中,通过学生ID和课程名进行连接条件的指定,以便获取正确的考试记录。
使用count()函数统计每位学生在每门课程上参加的考试次数,起别名为attended_exams。
使用group by子句按照学生ID和课程名进行分组,以便对每个学生每门课程进行统计。
最后使用order by子句按照学生ID和课程名进行排序,以便输出结果。
代码:
select st.student_id, st.student_name, su.subject_name, count(e.subject_name) as attended_exams
from Students as st
join Subjects as su -- 连接学生表和课程表
left join Examinations as e -- 左连接考试表
on st.student_id = e.student_id and e.subject_name = su.subject_name -- 根据学生ID和课程名进行连接
group by st.student_id, su.subject_name -- 按学生ID和课程名分组
order by st.student_id, su.subject_name; -- 按学生ID和课程名排序