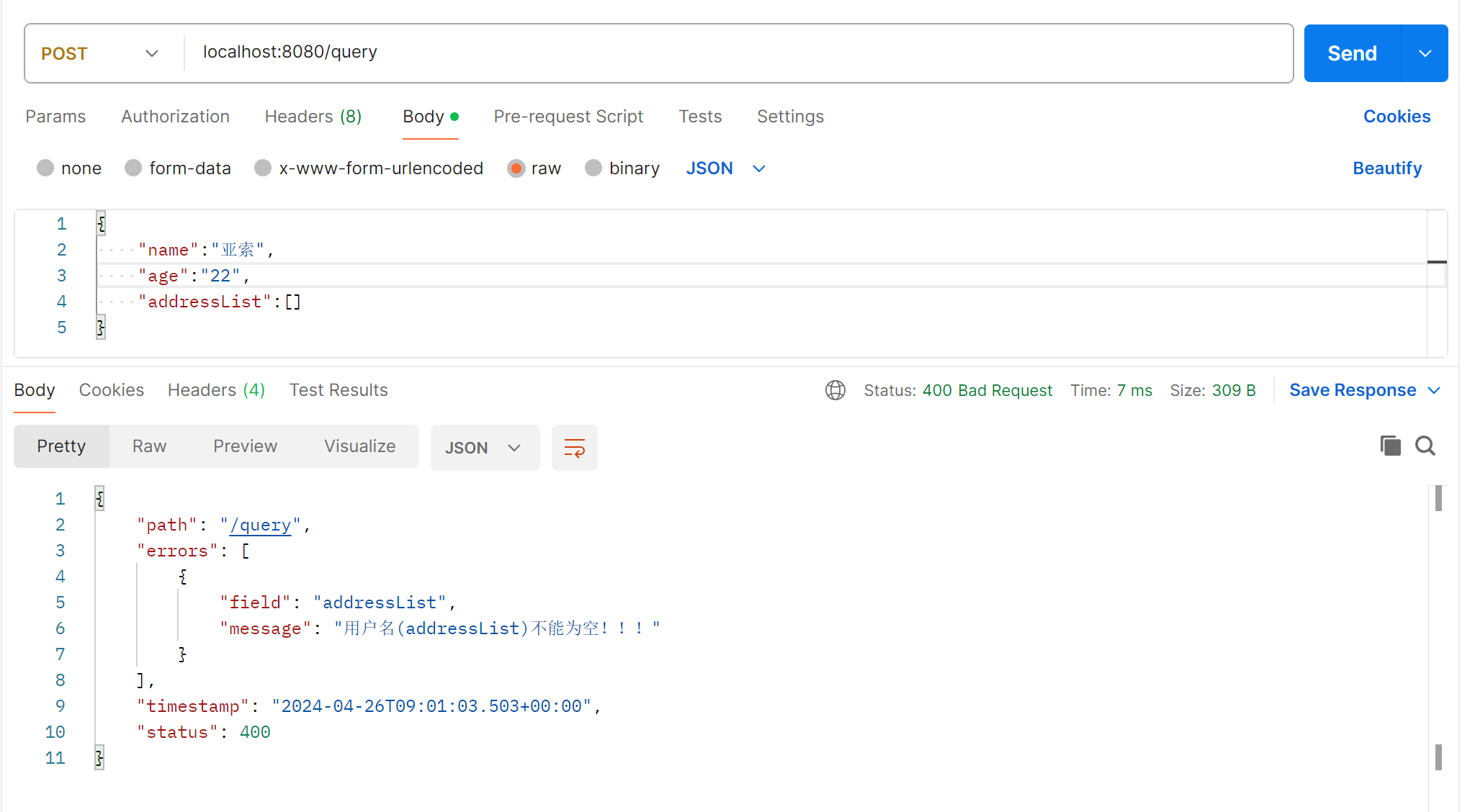
🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
2.数据集介绍
3.技术工具
4.导入数据
5.数据可视化
源代码
1.项目背景
研究全球表面温度数据的可视化分析是一项重要的工作,它有助于我们更深入地了解地球气候系统的变化趋势、模式和影响因素。
-
气候变化关切全球: 近年来,人们越来越关注气候变化的严重性以及其对全球生态系统、社会和经济的潜在影响。全球表面温度是气候系统中一个关键的指标,因为它直接反映了地球的能量平衡状态。通过对全球表面温度数据进行可视化分析,我们能够识别长期趋势、季节性变化以及异常事件,为更全面的气候变化研究提供基础。
-
气象观测网络的建立: 随着时间的推移,地球上建立了广泛而密集的气象观测网络,这包括地面站、卫星观测、浮标和飞机观测等。这些观测数据提供了全球各地的温度信息,形成了庞大的数据集。通过对这些数据进行可视化分析,我们能够更好地理解地球各地的气温分布和演变。
-
自然灾害与气候变化的关联: 过去几十年,全球范围内发生了多起极端气候事件,如极端高温、洪水和飓风。这些事件的频率和强度的变化引起了人们的关注,因为它们可能与气候变化有关。通过对全球表面温度数据进行可视化分析,我们可以研究这些事件的时空分布,为理解气候变化与自然灾害之间的关系提供线索。
-
国际合作和政策制定的支持: 国际社会越来越认识到气候变化的全球性挑战,因此在全球范围内推动气候研究、信息共享和政策制定变得至关重要。通过开展全球表面温度数据的可视化分析,可以促进国际间的合作,加强对气候变化的全球性认知,并为制定全球性的气候政策提供支持。
总的来说,全球表面温度数据的可视化分析对于深入理解气候系统的运行机制、监测气候变化趋势以及制定应对气候变化的政策具有重要意义。这项研究将为科学界、政策制定者和公众提供有关地球气候状态的关键信息。
2.数据集介绍
本数据集来源于Kaggle,原始数据集共有144条,19个变量。
关于本数据集
数据来自美国国家航空航天局GISS表面温度分析(GISTEMP v4)。这些数据集是全球和半球月平均值和区域年平均值的表。他们结合了陆地表面、空气和海洋表面的水温异常(陆地-海洋温度指数,L-OTI)。表中的数值是与相应的1951-1980年平均值的偏差。
GISS地表温度分析版本4 (GISTEMP v4)是对全球地表温度变化的估计。图表和表格在每个月中旬左右更新,使用来自NOAA GHCN v4(气象站)和ERSST v5(海洋区域)的当前数据文件,并结合其出版物Hansen et al.(2010)和Lenssen et al.(2019)中的描述。这些更新的文件包括上个月的报告和前几个月的后期报告和更正。
在比较季节温度时,方便地使用基于温度的“气象季节”,并将其定义为整月的分组。因此,12 - 1 - 2月(DJF)为北半球气象冬季,3 - 4 - 5月(MAM)为北半球气象春季,6 - 7 - 8月(JJA)为北半球气象夏季,9 - 10 - 11月(SON)为北半球气象秋季。把这四个季节连在一起,你就得到了从12月1日开始到11月30日结束的气象年(北纬)。一整年是从一月到十二月(J-D)。
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.导入数据
导入第三方库并加载数据集
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
df = pd.read_csv('global_temps.csv')
df.head()
查看数据大小

查看数据基本信息

查看数据描述性统计

统计缺失值情况

处理缺失值


5.数据可视化
# 将列映射到季节名称和标题
season_info = {
'J-D': 'All Year Around',
'DJF': 'Dec-Jan-Feb (Northern Hem\'s meteorological Winter)',
'MAM': 'Mar-Apr-May (Northern Hem\'s meteorological Spring)',
'JJA': 'Jun-Jul-Aug (Northern Hem\'s meteorological Summer)',
'SON': 'Sep-Oct-Nov (Northern Hem\'s meteorological Fall)'
}
sns.set_palette("colorblind")
for i, (col, title) in enumerate(season_info.items()):
plt.figure(figsize=(12,6))
plt.plot(df['Year'], df[col], marker='o', color=sns.color_palette()[i])
plt.title(title)
plt.xlabel('Year')
plt.ylabel('Temperature Anomaly (°C)')
plt.grid(True)
plt.show()




异常值可视化 ——IQR Method
# 寻找和可视化异常值
# IQR Method
Q1 = df['J-D'].quantile(0.25)
Q3 = df['J-D'].quantile(0.75)
IQR = Q3 - Q1
# 定义异常值的界限
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# 发现异常值
outliers = df[(df['J-D'] < lower_bound) | (df['J-D'] > upper_bound)]
print("Outliers:\n", outliers)
Z-Score Method
# Z-Score Method
from scipy.stats import zscore
z_score = zscore(df['SON'])
print(z_score)
threshold = 3
ol = df[abs(z_score) > threshold]
print(ol)
sns.boxplot(y=df['J-D'], color=sns.color_palette()[0])
plt.show()
# 将调色板设置为'colorblind'
palette = sns.color_palette("colorblind")
plt.figure(figsize=(20,10))
# 循环遍历每一列(不包括'Year')
for i, column in enumerate(df.columns.drop('Year')):
# 为每一列创建一个子图
plt.subplot(3, 6, i+1)
color = palette[i % len(palette)]
sns.boxplot(y=df[column], color=color)
plt.title(column)
plt.tight_layout()
plt.show()
相关系数热力图
# 相关的热图
months_columns = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec']
df_months = df[months_columns]
corr_matrix = df_months.corr()
plt.figure(figsize=(12,8))
sns.heatmap(corr_matrix,
annot = True,
cmap='flare',
linewidth=3,
square=True)
plt.title('Correlation Matrix Heatmap for January to December (1880-2023)')
plt.show()
season_columns = ['DJF', 'MAM', 'JJA', 'SON']
df_seasons = df[season_columns]
corr_matrix_seasons = df_seasons.corr()
season_labels = ['Winter (DJF)', 'Spring (MAM)', 'Summer (JJA)', 'Fall (SON)']
plt.figure(figsize=(12,8))
sns.heatmap(corr_matrix_seasons,
annot = True,
cmap='crest',
linewidth=3,
xticklabels=season_labels,
yticklabels=season_labels,
square=True)
plt.title('Correlation Matrix Heatmap for Each Seasons (1880-2023)')
plt.show()
new_df = df.drop(columns=['Year'])
corr_matrix2 = new_df.corr()
plt.figure(figsize=(12,8))
sns.heatmap(corr_matrix2,
annot = True,
cmap='Blues',
square=True)
plt.title('Correlation Matrix Heatmap at Large')
plt.show()
热图观测
月份之间的高度相关性:单个月份之间存在高度相关性,但在时间序列数据中,特别是气候或环境数据中,这是预期的,其中相邻的月份通常具有相似的条件或模式。
季节相关性:季节指标(DJF, MAM, JJA, SON)也显示出与组成每个季节的单个月份的高度相关性。这也是意料之中的,因为这些是它们所代表的月份的总和。
多重共线性考虑:在线性模型的上下文中,多重共线性可能是有问题的,因为它增加了系数估计的方差,并使模型对模型规格的变化敏感。变量之间的高度相关表明多重共线性。如果我要在预测模型中使用这些变量,我就需要解决这个问题。(降维,变量选择,正则化)
相关性并不意味着因果关系!
变化率
从时间序列图的目测可以看出,全球地表温度有较强的上升趋势。接下来,我将使用各种统计方法进行趋势分析,以进一步分析这一现象。
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
import numpy as np
# 将列映射到季节名称
season_names = {
'J-D': 'All Year',
'DJF': 'Winter',
'MAM': 'Spring',
'JJA': 'Summer',
'SON': 'Fall'
}
X = df['Year'].values.reshape(-1, 1)
for col, season in season_names.items():
y = df[col]
model = LinearRegression().fit(X, y)
print(f"\nTrend Analysis for {col}:")
print(f"Slope: {model.coef_[0]}")
print(f"Intercept: {model.intercept_}")
y_pred = model.predict(X)
plt.figure(figsize=(10, 6))
plt.scatter(df['Year'], y, label='Observed')
plt.plot(df['Year'], y_pred, color='red', label='Fitted Line')
plt.xlabel('Year')
plt.ylabel(f'Temperature Anomaly ({season})')
plt.title(f'Temperature Anomaly with Linear Trend Line ({season})')
plt.legend()
plt.show()









# 移动平均法
palette = sns.color_palette("colorblind", 3)
window_size = 10
df['Moving_Avg'] = df['J-D'].rolling(window=window_size).mean()
plt.figure(figsize=(10,6))
plt.scatter(df['Year'], df['J-D'], alpha=0.6, label='Observed Anomaly')
plt.plot(df['Year'], df['Moving_Avg'], color=palette[1], label=f'{window_size}-Year Moving Average')
plt.plot(df['Year'], y_pred, color=palette[2], label='Linear Trend Line')
plt.xlabel('Year')
plt.ylabel('Temperature Anomaly')
plt.title(f'Temperature Anomaly with {window_size}-Year Moving Average')
plt.legend()
plt.show()
palette = sns.color_palette("colorblind", 3)
window_size = 10
df['Moving_Avg_S'] = df['MAM'].rolling(window=window_size).mean()
plt.figure(figsize=(10,6))
plt.scatter(df['Year'], df['MAM'], alpha=0.6, label='Observed Anomaly')
plt.plot(df['Year'], df['Moving_Avg_S'], color=palette[1], label=f'{window_size}-Year Moving Average')
plt.plot(df['Year'], y_pred, color=palette[2], label='Linear Trend Line')
plt.xlabel('Year')
plt.ylabel('Temperature Anomaly')
plt.title(f'Temperature Anomaly with {window_size}-Year Moving Average (Spring)')
plt.legend()
plt.show()
单因素方差分析适用于以下情况:
组比较:有多个组进行比较
一个因素:可以按一个因素分类的组
观察结果的独立性:假设每组中的观察结果彼此独立
正态性:假设残差正态分布,组的方差相等。
方差分析前的正态性检验
# 方差分析前的正态性检验
# Q-Q图
import scipy.stats as stats
seasons = ['DJF', 'MAM', 'JJA', 'SON']
for season in seasons:
plt.figure()
stats.probplot(df[season], dist="norm", plot=plt)
plt.title(f'Q-Q Plot for {season}')
plt.show()



from scipy.stats import shapiro
for season in seasons:
stat, p = shapiro(df[season])
print(f'{season}: Statistics={stat}, p={p}')
if p > 0.05:
print('Sample looks Gaussian (fail to reject H0)')
else:
print('Sample does not look Gaussian (reject H0)')
通过对Q-Q图的目视检查和Shapiro-Wilk检验,结果表明季节数据组不服从正态分布。考虑到小样本量,使用单向方差分析可能不合适,尽管方差分析已知对违反正态性假设具有鲁棒性,但样本量较大时确实如此。
由于方差分析可能不是合适的方法,我将选择Kruskal-Willis h检验,这是方差分析的非参数替代方法,它不假设残差的正态分布。
Kruskal-Willis测试
零假设(H0):四季平均气温异常无显著差异。
备选假设(H1):至少有一个季节的平均温度异常与其他季节显著不同,这表明并非所有季节平均值都是相等的。
season_data = df[['DJF', 'MAM', 'JJA', 'SON']].stack()
season_df = pd.DataFrame({'Season': season_data.index.get_level_values(1), 'Anomaly': season_data.values})
print(season_df)
# Kruskal-Wallis test
h_stat, p_value = stats.kruskal(season_df[season_df['Season'] == 'DJF']['Anomaly'],
season_df[season_df['Season'] == 'MAM']['Anomaly'],
season_df[season_df['Season'] == 'JJA']['Anomaly'],
season_df[season_df['Season'] == 'SON']['Anomaly'])
print("Kruskal-Wallis Test Results: H-Stat =", h_stat, ", P-value =", p_value)
H-Stat:对零假设的总体偏差的度量。观察到的H-Stat值相对较低,表明与原假设的偏差不大。
p值:观察到与零假设下观察到的检验统计量一样极端或更极端的概率的度量。观察到的p值远高于阈值(0.05),表明观察到的数据很可能在零假设下。
解释
观察到的p值远高于常用的阈值0.05。因此,我没有足够的证据来拒绝零假设,这意味着不同季节的平均温度异常在统计上没有显著差异。季节间平均温度异常的变化可能是由于随机的机会,而不是由于其潜在平均值的真正差异。
时间序列分解
时间序列分解涉及将时间序列分离为几个组件(趋势、季节和残差)。
from statsmodels.tsa.seasonal import seasonal_decompose
df['Year'] = pd.to_datetime(df['Year'], format='%Y')
df.set_index('Year', inplace=True)
result = seasonal_decompose(df['J-D'], model='additive')
result.plot()
plt.show()
趋势分量:即使呈之字形,也可以看到增加的趋势,这表明随着时间的推移,气温异常普遍呈上升趋势。这是一个明显的变暖趋势,这与全球变暖的观测结果是一致的。
季节性成分:季节性成分在水平线上保持在0附近,表明数据中不存在强烈的季节性周期。
残差成分:残差在0.00附近用粗线表示在考虑趋势成分和季节成分后数据中的随机或无法解释的变化。虽然模型已经捕获了一般模式,但数据中仍然存在一些模型无法解释的波动性或噪声。这可能是由许多潜在因素造成的,包括气候数据的意外变化。
Mann-Kendall趋势检验
Mann-Kendall趋势检验是一种非参数检验,用于识别和确认时间序列数据的趋势。它可以帮助确认趋势是否具有统计显著性,而不需要对数据的具体分布进行任何假设。
零假设(H0):给定季节的温度异常没有随时间变化的趋势。
备选假设(H1):给定季节的温度异常有随时间变化的趋势。
全年M-K趋势检验
import pymannkendall as mk
result = mk.original_test(df['J-D'])
print(f"Trend: {result.trend}")
print(f"P-value: {result.p}")
print(f"Z-value: {result.z}")
print(f"Slope (Sen's slope): {result.slope}")
趋势正在增加。
观测到的p值表明观测到的增加趋势具有统计学意义。在温度异常中随机观察到这种趋势的可能性极小。
观察到的z值,由于其大小远离0,表明一个强烈的趋势。在这种情况下,正z值支持增加趋势的发现。
森氏斜率表示每年温度异常的变化幅度。观测值表明,气温异常以每年0.0079℃的速度递增。
解释:M-K检验结果强烈表明,多年来气温异常有统计学上显著的增加趋势,p值非常低,z值很高。
季节性的M-K趋势检验
不同的季节受气候变化的影响可能不同。
seasons = ['DJF','MAM','JJA','SON']
mk_results = {}
for season in seasons:
result = mk.original_test(df[season])
mk_results[season] = {
'Trend': result.trend,
'P-value': result.p,
'Z-value': result.z,
'Slope': result.slope
}
print(mk_results[season])
for season, results in mk_results.items():
print(f"Season: {season}, Results: {results}")
解释:
所有季节的温度异常在统计上都有显著的增加趋势,这证实了全球变暖正在以略有不同的速度影响一年中的所有部分。各季节的斜率值表明,增加的速度是一致的。所有季节的一致性显著性表明变暖趋势的稳健性。
变化点分析
确定时间序列的统计特性发生变化的时间点
import ruptures as rpt
df = pd.read_csv('global_temps.csv')
points = df["J-D"].values
print(points)
# 搜索,二值分割
algo = rpt.Binseg(model="rank").fit(points)
result = algo.predict(n_bkps=5) # 要检测的断点数目
print(result)
plt.figure(figsize=(10,6))
plt.plot(df['Year'], points, label='J-D')
palette = sns.color_palette("colorblind")
# 为更改点添加垂直线
for i, cp in enumerate(result[:-1]):
year = df['Year'].iloc[cp]
color = palette[i+1]
plt.axvline(x=year, color=color, linestyle='--', label=f'Change Points {i+1}')
plt.text(year, max(points), f'{year}', color=color, verticalalignment='top', horizontalalignment='right')
print(f"Change Point {i+1}: Year {year}, Position {cp}")
plt.xlabel('Year')
plt.title('Change Point Detection for All-Year')
plt.legend()
plt.show()

解释:
变化点1——1930年:这个点可能表明一个显著变暖阶段的开始。这可能是由于工业化的早期影响。
变化点2——1940年:十年后,这一点表明了温度趋势的另一个变化。1940年前后标志着短期降温阶段的开始,随后迅速增加。这可以归因于自然气候变化等因素。
变化点3 - 1945年:由于历史原因,包括第二次世界大战的结束,20世纪40年代中期是重要的,这可能通过战争期间的工业活动影响了大气条件。
变化点4—1980年:20世纪80年代初标志着全球变暖的开始,到20世纪末,全球变暖趋势一直持续到21世纪。
变化5 - 2000年:关键的变化点出现在2000年。21世纪初,全球出现了有记录以来最温暖的年份,这表明气候变化的影响正在加速。
# 每个季节的变化点检测
season_names = {'DJF': 'Winter', 'MAM': 'Spring', 'JJA': 'Summer', 'SON': 'Fall'}
for abb, season in season_names.items():
points = df[abb].values
print(points)
algo = rpt.Binseg(model="rank").fit(points)
result = algo.predict(n_bkps=5)
print(result)
plt.figure(figsize=(10,6))
plt.plot(df['Year'], points, label=f'{season}')
palette = sns.color_palette("colorblind")
for i, cp in enumerate(result[:-1]):
year = df['Year'].iloc[cp]
color = palette[i+1]
plt.axvline(x=year, color=color, linestyle='--', label=f'Change Points {i+1}')
y_pos = max(points)
plt.text(year, y_pos, f'{year}', color=color, verticalalignment='top', horizontalalignment='right')
print(f"Change Point {i+1}: Year {year}, Position {cp}, Y-Position {y_pos}")
plt.xlabel('Year')
plt.title(f'Change Point Detection for {season}')
plt.legend()
plt.show()







源代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
df = pd.read_csv('global_temps.csv')
df.head()
df.shape
df.info()
df.describe().T
df.isnull().sum()
# 处理丢失的数据点与线性插值
for column in df.columns:
if df[column].isnull().any():
df[column] = df[column].interpolate(method='linear')
print(df.isnull().sum())
# 处理第一行丢失的数据点
# 用第二行和第三行的平均值填充第一行的NaN值
if df.iloc[0].isnull().any():
mean_val = df.iloc[1:3].mean()
df.iloc[0] = df.iloc[0].fillna(mean_val)
print(df.isnull().sum())
# 将列映射到季节名称和标题
season_info = {
'J-D': 'All Year Around',
'DJF': 'Dec-Jan-Feb (Northern Hem\'s meteorological Winter)',
'MAM': 'Mar-Apr-May (Northern Hem\'s meteorological Spring)',
'JJA': 'Jun-Jul-Aug (Northern Hem\'s meteorological Summer)',
'SON': 'Sep-Oct-Nov (Northern Hem\'s meteorological Fall)'
}
sns.set_palette("colorblind")
for i, (col, title) in enumerate(season_info.items()):
plt.figure(figsize=(12,6))
plt.plot(df['Year'], df[col], marker='o', color=sns.color_palette()[i])
plt.title(title)
plt.xlabel('Year')
plt.ylabel('Temperature Anomaly (°C)')
plt.grid(True)
plt.show()
# 寻找和可视化异常值
# IQR Method
Q1 = df['J-D'].quantile(0.25)
Q3 = df['J-D'].quantile(0.75)
IQR = Q3 - Q1
# 定义异常值的界限
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# 发现异常值
outliers = df[(df['J-D'] < lower_bound) | (df['J-D'] > upper_bound)]
print("Outliers:\n", outliers)
# Z-Score Method
from scipy.stats import zscore
z_score = zscore(df['SON'])
print(z_score)
threshold = 3
ol = df[abs(z_score) > threshold]
print(ol)
sns.boxplot(y=df['J-D'], color=sns.color_palette()[0])
plt.show()
# 将调色板设置为'colorblind'
palette = sns.color_palette("colorblind")
plt.figure(figsize=(20,10))
# 循环遍历每一列(不包括'Year')
for i, column in enumerate(df.columns.drop('Year')):
# 为每一列创建一个子图
plt.subplot(3, 6, i+1)
color = palette[i % len(palette)]
sns.boxplot(y=df[column], color=color)
plt.title(column)
plt.tight_layout()
plt.show()
# 相关的热图
months_columns = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec']
df_months = df[months_columns]
corr_matrix = df_months.corr()
plt.figure(figsize=(12,8))
sns.heatmap(corr_matrix,
annot = True,
cmap='flare',
linewidth=3,
square=True)
plt.title('Correlation Matrix Heatmap for January to December (1880-2023)')
plt.show()
season_columns = ['DJF', 'MAM', 'JJA', 'SON']
df_seasons = df[season_columns]
corr_matrix_seasons = df_seasons.corr()
season_labels = ['Winter (DJF)', 'Spring (MAM)', 'Summer (JJA)', 'Fall (SON)']
plt.figure(figsize=(12,8))
sns.heatmap(corr_matrix_seasons,
annot = True,
cmap='crest',
linewidth=3,
xticklabels=season_labels,
yticklabels=season_labels,
square=True)
plt.title('Correlation Matrix Heatmap for Each Seasons (1880-2023)')
plt.show()
new_df = df.drop(columns=['Year'])
corr_matrix2 = new_df.corr()
plt.figure(figsize=(12,8))
sns.heatmap(corr_matrix2,
annot = True,
cmap='Blues',
square=True)
plt.title('Correlation Matrix Heatmap at Large')
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
import numpy as np
# 将列映射到季节名称
season_names = {
'J-D': 'All Year',
'DJF': 'Winter',
'MAM': 'Spring',
'JJA': 'Summer',
'SON': 'Fall'
}
X = df['Year'].values.reshape(-1, 1)
for col, season in season_names.items():
y = df[col]
model = LinearRegression().fit(X, y)
print(f"\nTrend Analysis for {col}:")
print(f"Slope: {model.coef_[0]}")
print(f"Intercept: {model.intercept_}")
y_pred = model.predict(X)
plt.figure(figsize=(10, 6))
plt.scatter(df['Year'], y, label='Observed')
plt.plot(df['Year'], y_pred, color='red', label='Fitted Line')
plt.xlabel('Year')
plt.ylabel(f'Temperature Anomaly ({season})')
plt.title(f'Temperature Anomaly with Linear Trend Line ({season})')
plt.legend()
plt.show()
# 移动平均法
palette = sns.color_palette("colorblind", 3)
window_size = 10
df['Moving_Avg'] = df['J-D'].rolling(window=window_size).mean()
plt.figure(figsize=(10,6))
plt.scatter(df['Year'], df['J-D'], alpha=0.6, label='Observed Anomaly')
plt.plot(df['Year'], df['Moving_Avg'], color=palette[1], label=f'{window_size}-Year Moving Average')
plt.plot(df['Year'], y_pred, color=palette[2], label='Linear Trend Line')
plt.xlabel('Year')
plt.ylabel('Temperature Anomaly')
plt.title(f'Temperature Anomaly with {window_size}-Year Moving Average')
plt.legend()
plt.show()
palette = sns.color_palette("colorblind", 3)
window_size = 10
df['Moving_Avg_S'] = df['MAM'].rolling(window=window_size).mean()
plt.figure(figsize=(10,6))
plt.scatter(df['Year'], df['MAM'], alpha=0.6, label='Observed Anomaly')
plt.plot(df['Year'], df['Moving_Avg_S'], color=palette[1], label=f'{window_size}-Year Moving Average')
plt.plot(df['Year'], y_pred, color=palette[2], label='Linear Trend Line')
plt.xlabel('Year')
plt.ylabel('Temperature Anomaly')
plt.title(f'Temperature Anomaly with {window_size}-Year Moving Average (Spring)')
plt.legend()
plt.show()
# 方差分析前的正态性检验
# Q-Q图
import scipy.stats as stats
seasons = ['DJF', 'MAM', 'JJA', 'SON']
for season in seasons:
plt.figure()
stats.probplot(df[season], dist="norm", plot=plt)
plt.title(f'Q-Q Plot for {season}')
plt.show()
from scipy.stats import shapiro
for season in seasons:
stat, p = shapiro(df[season])
print(f'{season}: Statistics={stat}, p={p}')
if p > 0.05:
print('Sample looks Gaussian (fail to reject H0)')
else:
print('Sample does not look Gaussian (reject H0)')
season_data = df[['DJF', 'MAM', 'JJA', 'SON']].stack()
season_df = pd.DataFrame({'Season': season_data.index.get_level_values(1), 'Anomaly': season_data.values})
print(season_df)
# Kruskal-Wallis test
h_stat, p_value = stats.kruskal(season_df[season_df['Season'] == 'DJF']['Anomaly'],
season_df[season_df['Season'] == 'MAM']['Anomaly'],
season_df[season_df['Season'] == 'JJA']['Anomaly'],
season_df[season_df['Season'] == 'SON']['Anomaly'])
print("Kruskal-Wallis Test Results: H-Stat =", h_stat, ", P-value =", p_value)
from statsmodels.tsa.seasonal import seasonal_decompose
df['Year'] = pd.to_datetime(df['Year'], format='%Y')
df.set_index('Year', inplace=True)
result = seasonal_decompose(df['J-D'], model='additive')
result.plot()
plt.show()
import pymannkendall as mk
result = mk.original_test(df['J-D'])
print(f"Trend: {result.trend}")
print(f"P-value: {result.p}")
print(f"Z-value: {result.z}")
print(f"Slope (Sen's slope): {result.slope}")
seasons = ['DJF','MAM','JJA','SON']
mk_results = {}
for season in seasons:
result = mk.original_test(df[season])
mk_results[season] = {
'Trend': result.trend,
'P-value': result.p,
'Z-value': result.z,
'Slope': result.slope
}
print(mk_results[season])
for season, results in mk_results.items():
print(f"Season: {season}, Results: {results}")
import ruptures as rpt
df = pd.read_csv('global_temps.csv')
points = df["J-D"].values
print(points)
# 搜索,二值分割
algo = rpt.Binseg(model="rank").fit(points)
result = algo.predict(n_bkps=5) # 要检测的断点数目
print(result)
plt.figure(figsize=(10,6))
plt.plot(df['Year'], points, label='J-D')
palette = sns.color_palette("colorblind")
# 为更改点添加垂直线
for i, cp in enumerate(result[:-1]):
year = df['Year'].iloc[cp]
color = palette[i+1]
plt.axvline(x=year, color=color, linestyle='--', label=f'Change Points {i+1}')
plt.text(year, max(points), f'{year}', color=color, verticalalignment='top', horizontalalignment='right')
print(f"Change Point {i+1}: Year {year}, Position {cp}")
plt.xlabel('Year')
plt.title('Change Point Detection for All-Year')
plt.legend()
plt.show()
可供选择的型号:
L1, l2, rbf,线性,法线,ar,秩,马氏
# 每个季节的变化点检测
season_names = {'DJF': 'Winter', 'MAM': 'Spring', 'JJA': 'Summer', 'SON': 'Fall'}
for abb, season in season_names.items():
points = df[abb].values
print(points)
algo = rpt.Binseg(model="rank").fit(points)
result = algo.predict(n_bkps=5)
print(result)
plt.figure(figsize=(10,6))
plt.plot(df['Year'], points, label=f'{season}')
palette = sns.color_palette("colorblind")
for i, cp in enumerate(result[:-1]):
year = df['Year'].iloc[cp]
color = palette[i+1]
plt.axvline(x=year, color=color, linestyle='--', label=f'Change Points {i+1}')
y_pos = max(points)
plt.text(year, y_pos, f'{year}', color=color, verticalalignment='top', horizontalalignment='right')
print(f"Change Point {i+1}: Year {year}, Position {cp}, Y-Position {y_pos}")
plt.xlabel('Year')
plt.title(f'Change Point Detection for {season}')
plt.legend()
plt.show()
资料获取,更多粉丝福利,关注下方公众号获取