前言
ElasticSearch考虑到大数据量的情况,集群有很多的部署模式,本篇不会具体进行演示了,只是说明一下有哪些架构可以选,及一些原理的简单介绍,如果要看具体操作的那么可以自行进行搜索,这不是本篇博客要介绍的内容
集群架构
普通集群
这个在我之前的文章中已经花了很大时间介绍了,而且对一些基础概念也进行了介绍,可以先看看那篇文章再回来看后面的东西:https://blog.csdn.net/zxc_user/article/details/128683854
单一职责集群

这群集群比普通集群就要好多了,不过也需要更多的服务器来支撑,如果你在同一个服务器部署多个es来模拟这种架构模式,那就没啥意义了
读写分离架构
在单一职责上对协同节点进行隔离,这是针对协调节点的

Hot & Warm 架构
冷热数据分离,这是对于数据节点来说的,有些数据可能没啥人访问,那么就可以归为冷数据,一些常访问的数据可以归为热数据,所谓的冷热是你业务上来决定的

ES跨集群搜索(CCS)
这也是ElasticSearch支持的一大特性,有时候我们一个es集群存的数据已经很大了,但是节点太多了,此时我们可以利用CCS这种机制再部署一个新的集群,当我们查询数据时根据elasticsearch提供的功能从多个不一样的集群获取数据

ES底层读写工作原理
ES写入数据的过程
1. 客户端发生数据key给coordinating节点
2. coordinating节点通过对key进行hash找到合适的node2节点处理
3. node2先写到主分片,然后再同步给副本分片
4. 副本分片数据处理完成返回给主分片信息
5. 主分片告诉客户端处理完成
ElasticSearch读数据原理
分两种模式
Id:直接找
全文索引:先从倒排索引表获取到id,再从id获取数据

写数据底层原理
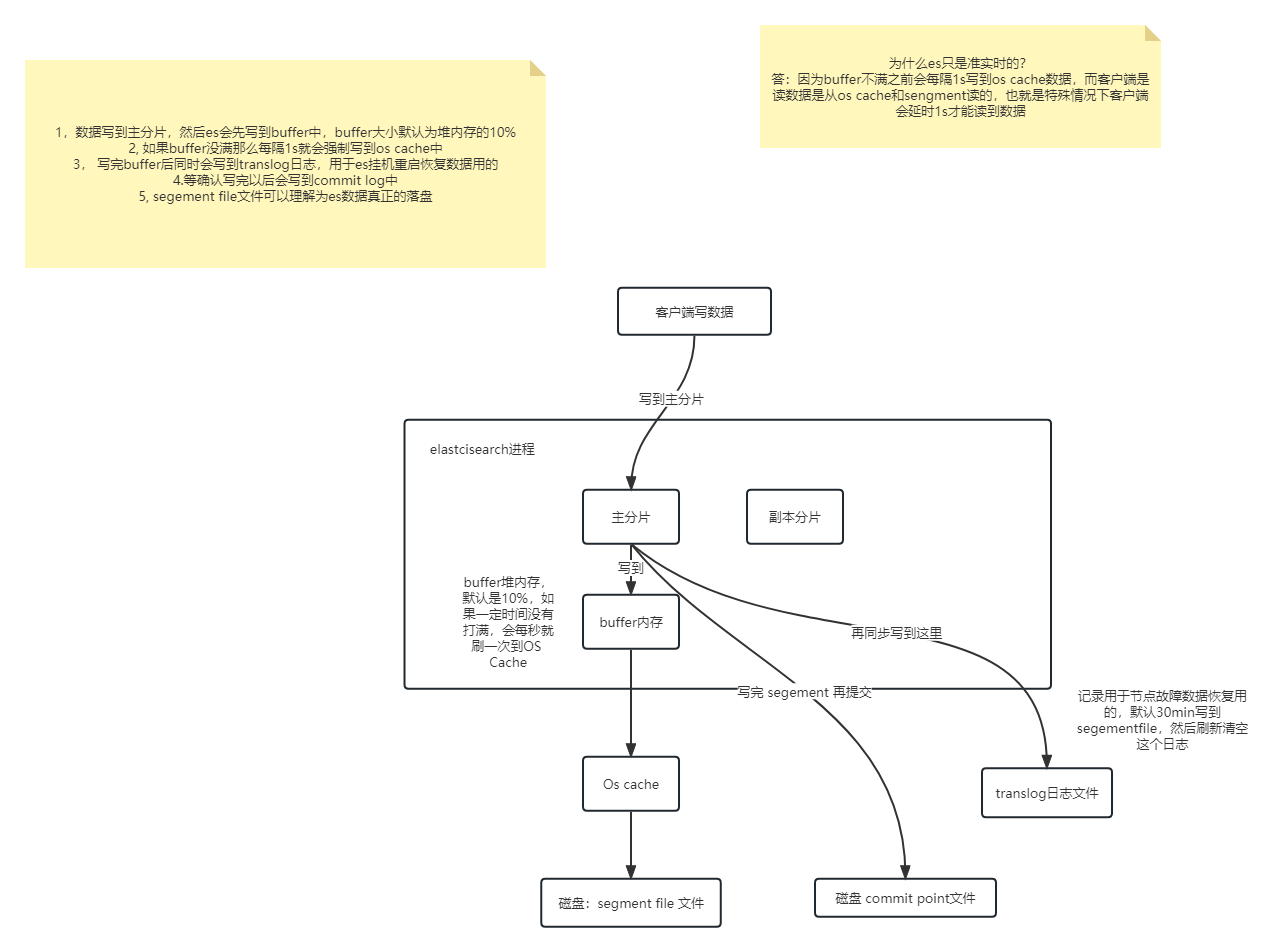
上面说的是宏观层面的数据写逻辑,这里是微观层面的写逻辑
segment file: 存储倒排索引的文件,每个segment本质上就是一个倒排索引,每秒都会生成一个segment文件,当文件过多时es会自动进行segment merge(合并文件),合并时会同时将已经标注删除的文档物理删除。
commit point: 记录当前所有可用的segment,每个commit point都会维护一个.del文件,即每个.del文件都有一个commit point文件(es删除数据本质是不属于物理删除),当es做删改操作时首先会在.del文件中声明某个document已经被删除,文件内记录了在某个segment内某个文档已经被删除,当查询请求过来时在segment中被删除的文件是能够查出来的,但是当返回结果时会根据commit point维护的那个.del文件把已经删除的文档过滤掉
translog日志文件: 为了防止elasticsearch宕机造成数据丢失保证可靠存储,es会将每次写入数据同时写到translog日志中。
os cache:操作系统里面,磁盘文件其实都有一个东西,叫做os cache,操作系统缓存,就是说数据写入磁盘文件之前,会先进入os cache,先进入操作系统级别的一个内存缓存中去
Refresh
将文档先保存在Index buffer中,以refresh_interval为间隔时间,定期清空buffer,生成 segment,借助文件系统缓存的特性,先将segment放在文件系统缓存中,并开放查询,以提升搜索的实时性
Translog
Segment没有写入磁盘,即便发生了当机,重启后,数据也能恢复,从ES6.0开始默认配置是每次请求都会落盘
Flush
删除旧的translog 文件
生成Segment并写入磁盘│更新commit point并写入磁盘。ES自动完成,可优化点不多
如何提升集群的读写性能
基于上面的底层原理可以有一定的优化方式
提升集群读取性能的方法
如果有查询需要用script查询,可以考虑把对应数据存起来,然后查的时候直接查该值就行了
不需要进行全文索引的可以关闭这个功能
不需要进行算分时查询的时候尽量带上
尽可能避免数据的分片
提升写入性能的方法
这个可以结合写底层原理进行考虑,写就是要提高响应客户端的能力,可以从以下的方面考虑
增加buffer
buffer是基于内存的,所以很明显可以加大这个内存,响应客户端肯定会更快,这是一定的
降低 Refresh的频率
默认buffer1s就刷过去,可以考虑设置长点,因为刷这个过程肯定也是要消耗一定性能的
降低Translog写磁盘的频率,但是会降低容灾能力
Index.translog.durability: 默认是request,每个请求都落盘。设置成async,异步写入
lndex.translog.sync_interval:设置为60s,每分钟执行一次
Index.translog.flush_threshod_size: 默认512 m,可以适当调大。当translog 超过该值,会触发flush
等等,其他方案还是可以基于底层原理进行设置
总结
到这里就结束了,主要是讨论下elasticsearch的一些底层原理,主要还是要根据实际业务进行合理的设计
![[LCTF]bestphp2022安洵杯 babyphp](https://img-blog.csdnimg.cn/98d257bb00534a9796c442cb1cd0a2ad.png)
![[极客大挑战 2019]Secret File](https://img-blog.csdnimg.cn/526ac40f7e97411aa1dc2c499a263214.png)