🐯 Colab用例与Gemma快速上手指南 🚀
文章目录
- 🐯 Colab用例与Gemma快速上手指南 🚀
- 摘要
- 引言
- 正文
- 📝 **基础使用:Gemma快速上手**
- 环境设置和模型加载
- 安装必要的库
- 加载Gemma模型
- 推理示例
- 🛠 **Gemma微调:使用LoRA技术**
- LoRA微调前后的超参数对比
- 微调代码示例
- 🔗 **分布式微调**
- 分布式训练设置
- 示例:分布式文本生成
- QA环节
- Q1: Gemma模型在Kaggle上的电话验证失败怎么办?
- Q2: LoRA微调的优势在哪里?
- Q3: 分布式训练的常见问题有哪些?
- 小结
- 参考资料
- 表格总结
- 总结
- 温馨提示
摘要
本文旨在向开发者介绍如何在Colab和Kaggle上有效地运用Gemma模型进行机器学习任务。内容涵盖Gemma的基础使用、LoRA微调技术及其对比分析,并提供分布式微调的详细步骤。主要技术关键词包括:Gemma模型, KerasNLP, LoRA微调, 分布式训练, Colab, Kaggle, TPU加速, Python依赖安装, JAX, TensorFlow, 模型微调, 文本生成。本教程适合所有水平的开发者,从初学者到高级技术人员。
引言
随着机器学习技术的不断进步,如何有效地使用和微调大型语言模型成为了开发者社区中的热门话题。Google的Gemma模型作为一种先进的自然语言处理工具,提供了丰富的应用可能性。本文将通过具体的代码示例和操作命令,详细介绍如何在Colab和Kaggle平台上使用Gemma模型,包括基础推理、LoRA微调及分布式训练的实现。
正文

📝 基础使用:Gemma快速上手
环境设置和模型加载
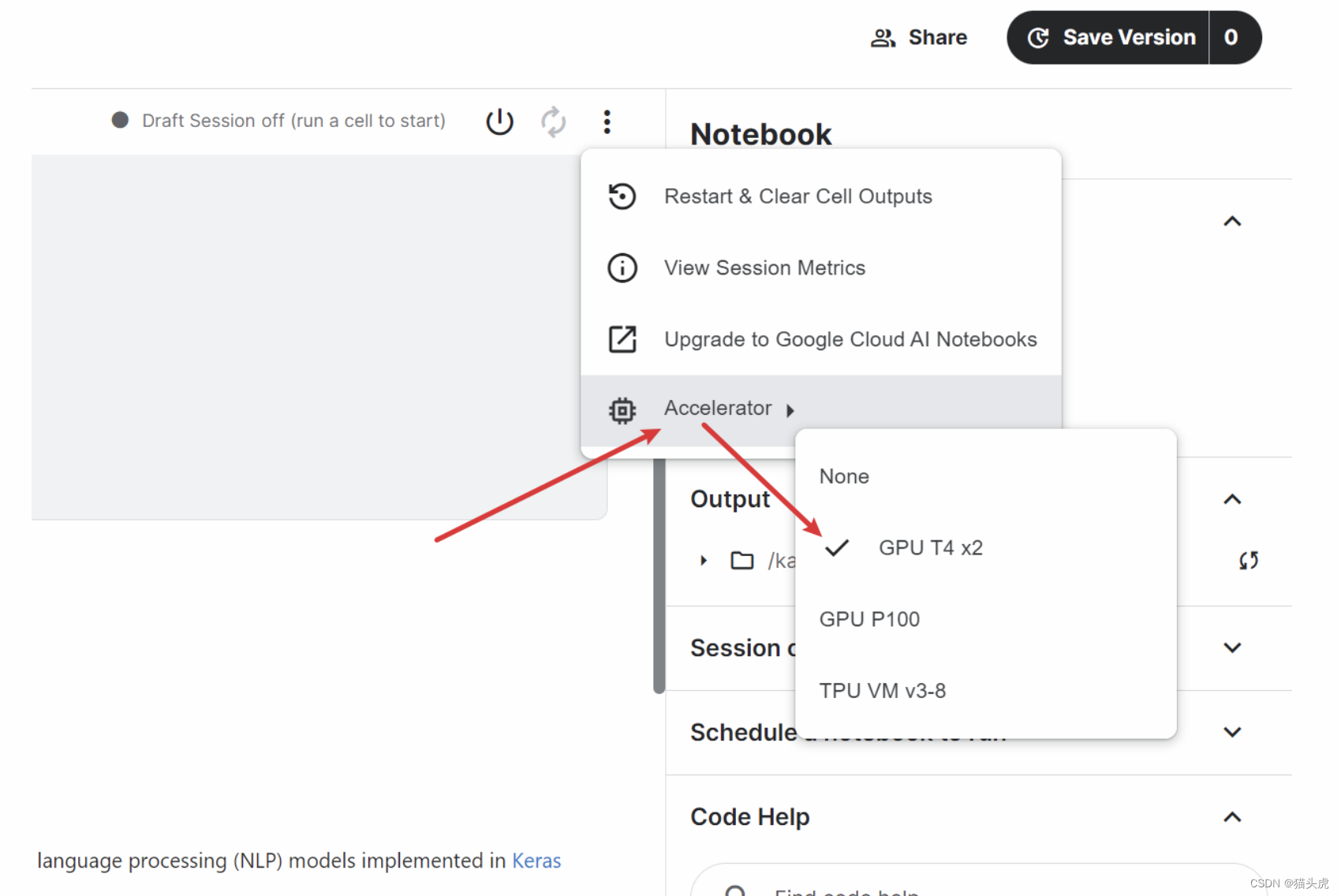
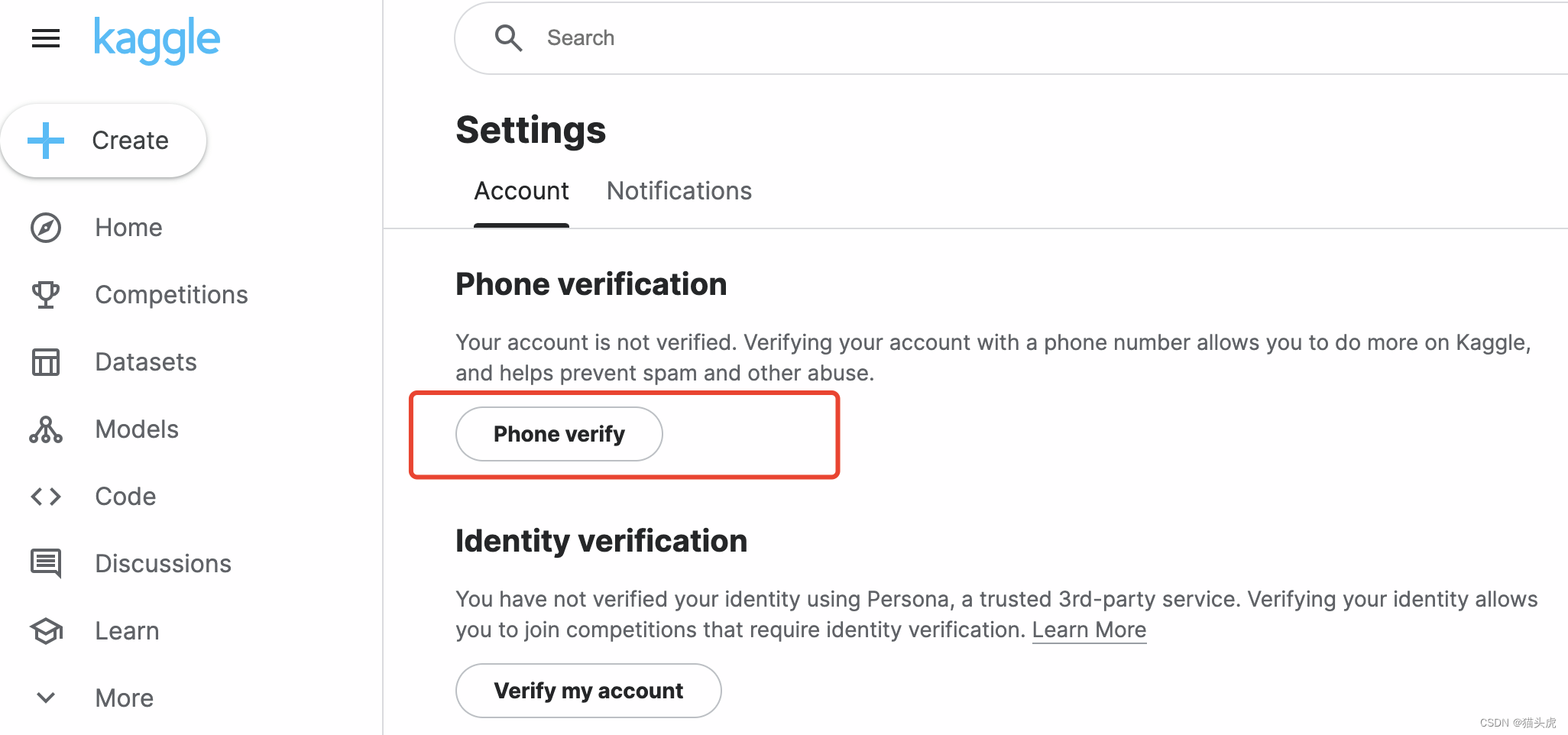
在Kaggle上开始之前,用户需要完成电话验证来启用GPU或TPU加速。验证成功后,可以在项目设置中选择所需的硬件加速选项。
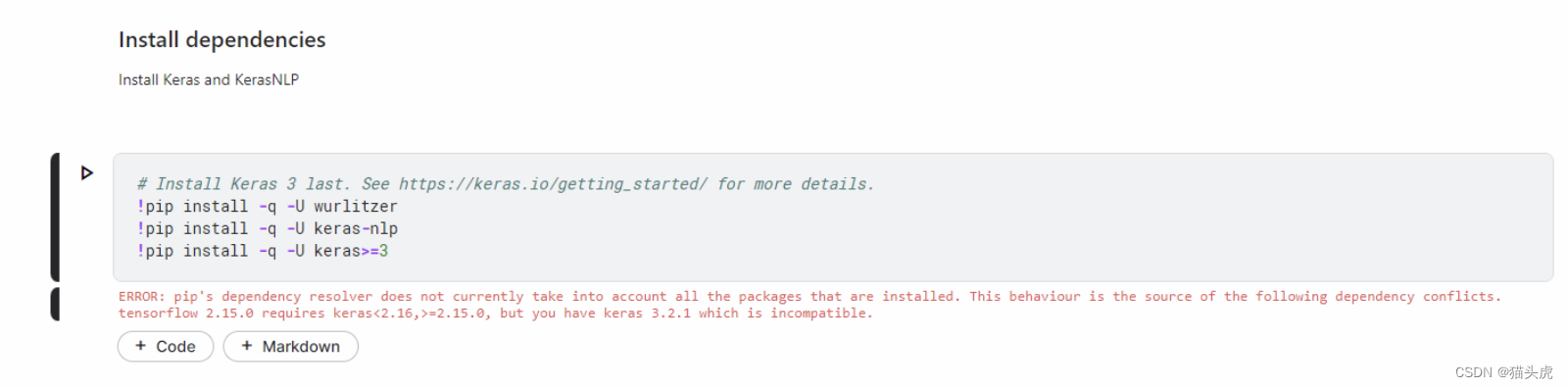
安装必要的库
!pip install keras-nlp
加载Gemma模型
在Kaggle notebook中导入Gemma模型,并选择合适的模型版本进行实验:
from keras_nlp.models import gemma
model = gemma.GemmaModel(model_name="gemma_2b")
推理示例
使用加载的模型进行文本生成:
generated_text = model.generate("Today is a beautiful day")
print(generated_text)
🛠 Gemma微调:使用LoRA技术
LoRA(Low-Rank Adaptation)是一种高效的模型微调技术,通过引入低秩结构来调整模型的权重,既节省了训练资源又保持了模型性能。
LoRA微调前后的超参数对比
在微调前,Gemma模型的参数量为20亿;微调后,通过调整LoRA的参数,参数量略有增加,但通过合理设置,增加的计算负载不会太大。
微调代码示例
from keras_nlp.layers import LoRA
model = gemma.GemmaModel(model_name="gemma_2b")
model.add(LoRA(rank=20))
model.fine_tune(...)
🔗 分布式微调
分布式微调可以在多个处理器上并行处理数据,显著加快训练速度。Google Colab提供了对TPU的支持,极大地提升了训练效率。
分布式训练设置
import tensorflow as tf
resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu='')
tf.config.experimental_connect_to_cluster(resolver)
tf.tpu.experimental.initialize_tpu_system(resolver)
strategy = tf.distribute.TPUStrategy(resolver)
示例:分布式文本生成
在TPU环境下,使用分布式策略运行模型,比较不同配置下的性能差异:
with strategy.scope():
model = gemma.GemmaModel(model_name="gemma_2b")
generated_text = model.generate("How about the weather today?")
print(generated_text)
QA环节
Q1: Gemma模型在Kaggle上的电话验证失败怎么办?
A1: 如果遇到电话验证失败,可以尝试更换电话号码或联系Kaggle客服解决。还可以尝试使用 **** 进行注册。
Q2: LoRA微调的优势在哪里?
A2: LoRA通过引入低秩矩阵,有效减少了参数量的同时保持了模型的表达能力,使得在资源有限的情况下也能进行有效的模型微调。
Q3: 分布式训练的常见问题有哪些?
A3: 分布式训练可能会遇到网络延迟、同步问题等,确保网络稳定和使用高效的同步策略是关键。
小结
本文详细介绍了如何在Colab和Kaggle平台上使用和微调Gemma模型,包括基础使用、LoRA微调技术和分布式训练方法。通过具体的代码示例,帮助开发者快速掌握这些高级功能。
参考资料
- KerasNLP官方文档
- Gemma模型详细文档
表格总结
| 功能 | 描述 | 工具/库 |
|---|---|---|
| 基础使用 | 模型加载和文本生成 | KerasNLP |
| LoRA微调 | 低秩矩阵调整模型权重 | LoRA |
| 分布式训练 | 多TPU并行处理提高训练效率 | TensorFlow, TPU |
总结
掌握Gemma模型的使用和微调技术,将帮助开发者在自然语言处理领域取得更好的成绩。未来的展望中,Gemma模型的应用范围将进一步扩大,包括更多自然语言处理任务和多语言支持。
温馨提示
如果对本文有任何疑问,欢迎点击下方名片,了解更多详细信息!我们非常期待与您的互动,并帮助您解决在使用Gemma模型过程中遇到的问题。