编者按:云原生平台下芯片的竞争力日渐增强,加速器如何在赛道上体现竞争力。龙蜥社区开发者、阿里云高级研发工程师易兴睿介绍运用龙蜥操作系统提供的解决方案,依靠 Intel SPR 平台专用硬件加速器,实现云原生场景下 Envoy 网关加速,并分享借助与 Intel 的紧密合作,龙蜥社区实现了 Intel SPR 平台加速器全球首发上云的傲人成绩。

(图/龙蜥社区开发者、阿里云高级研发工程师易兴睿)
背景介绍
作为经典的云原生应用 Envoy,在新一代 Intel SPR 平台上将会碰撞出怎样的火花?
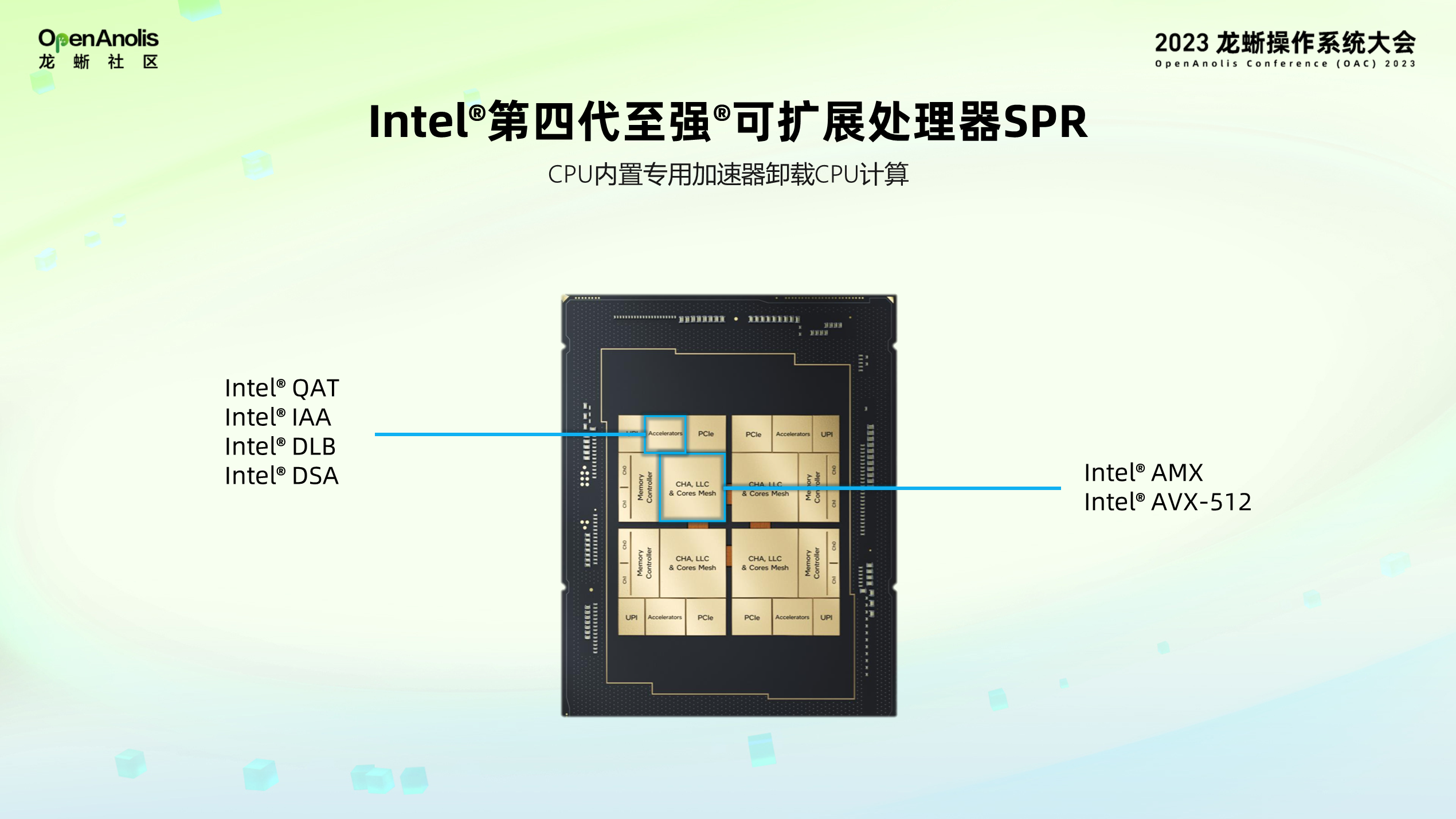
2023 年,Intel 发布了第四代至强可扩展的服务器处理器芯片 - Intel sapphire rapid( 以下简称“Intel SPR” ),其一大特色是集成了多款不同种类的加速器,包括英特尔快速辅助技术(QAT)、英特尔内存分析加速器(IAA)、英特尔动态负载平衡器(DLB)、英特尔数据流加速器(DSA),上图右边是一些指定相关的 MX 和 AVX512 的拓展。
本文主要介绍 QAT、IAA、DLB 和 DSA 四个加速器,它们作为专用设备挂在芯片网格上,本质上是 PCIe 加速器,已经集成到 CPU 芯片本身,因此当用户直接购买使用时,就能够直接享受到这样的设备,而不用额外插加速器卡。
在 Intel SPR 新平台上,可以利用加速器帮助用户突破上层应用的性能瓶颈。Envoy 作为 CNCF 开源旗下的明星项目,是 Service Mesh 的高性能网络代理,也是 Istio 中默认数据面,更是云原生时代的新星,其应用十分广泛。
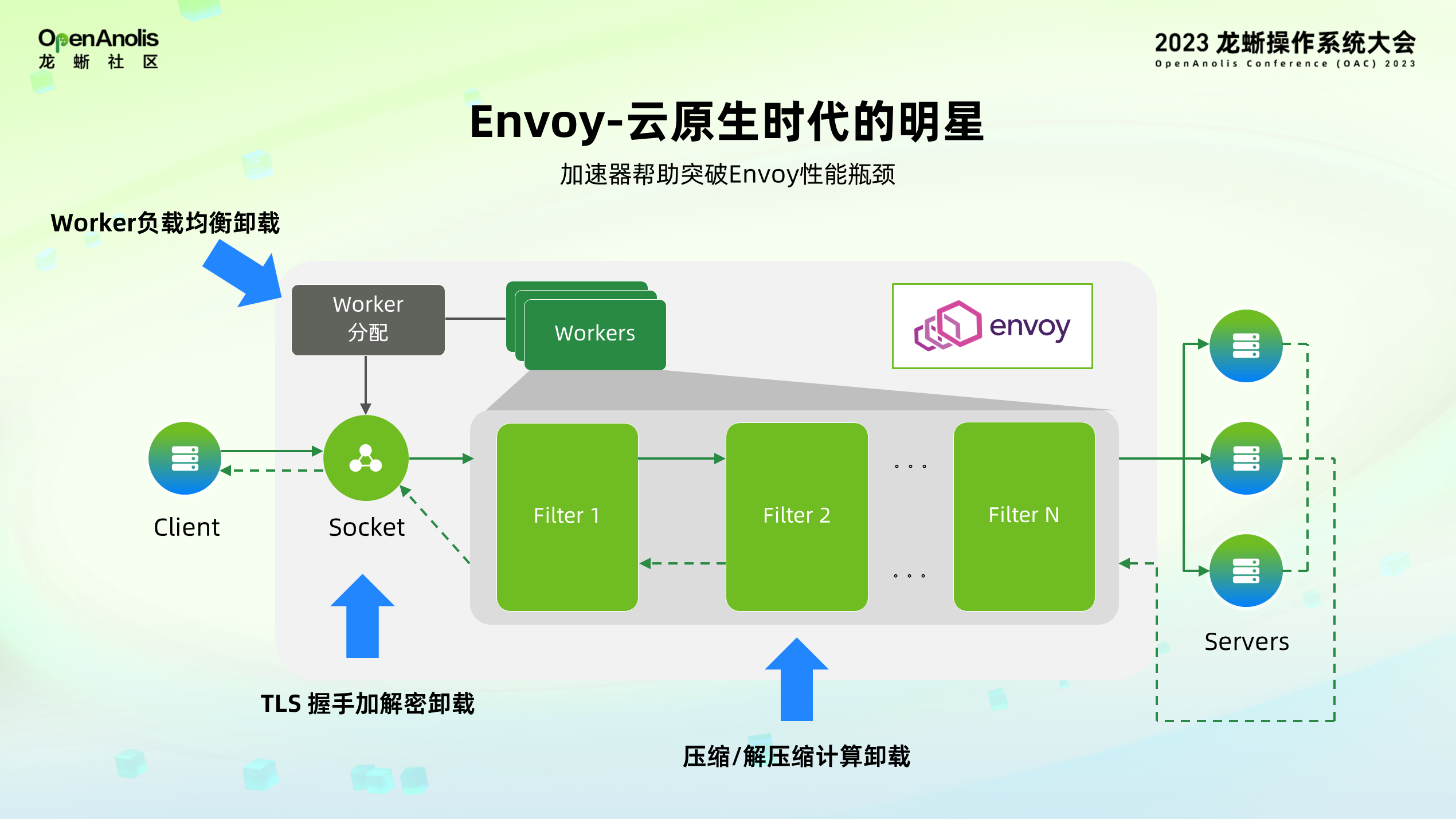
作为一个网络中间件,Envoy 被放置在服务端和客户端之间作为代理服务,上图是 Envoy 工作原理图。首先用户在客户端发起链接请求,请求被 Envoy 接收后,Envoy 用主线程从 Worker 池中安排 Worker 对后续的任务进行处理。然后用户根据业务需要定制各种 filter 进行一系列数据处理过程,包括数据的路由、压缩等操作。最后,将处理后的数据转发到对应的 server 上。
整套计算流程涉及到许多计算操作,包括 Envoy 在建立握手的过程中,比如用 HTTPS 协议做 TLS 链接过程中会涉及计算加解密的计算,亦或者 Worker 处理数据的流程中涉及到压缩或者解压缩的计算。用户有特殊需求在 Worker 间做负载均衡,软件的实现方式需要通过加解锁,这样会带来极大的性能开销。
以上提到的所有计算都可以被卸载到硬件加速器上实现,从而解放 CPU 的算力。
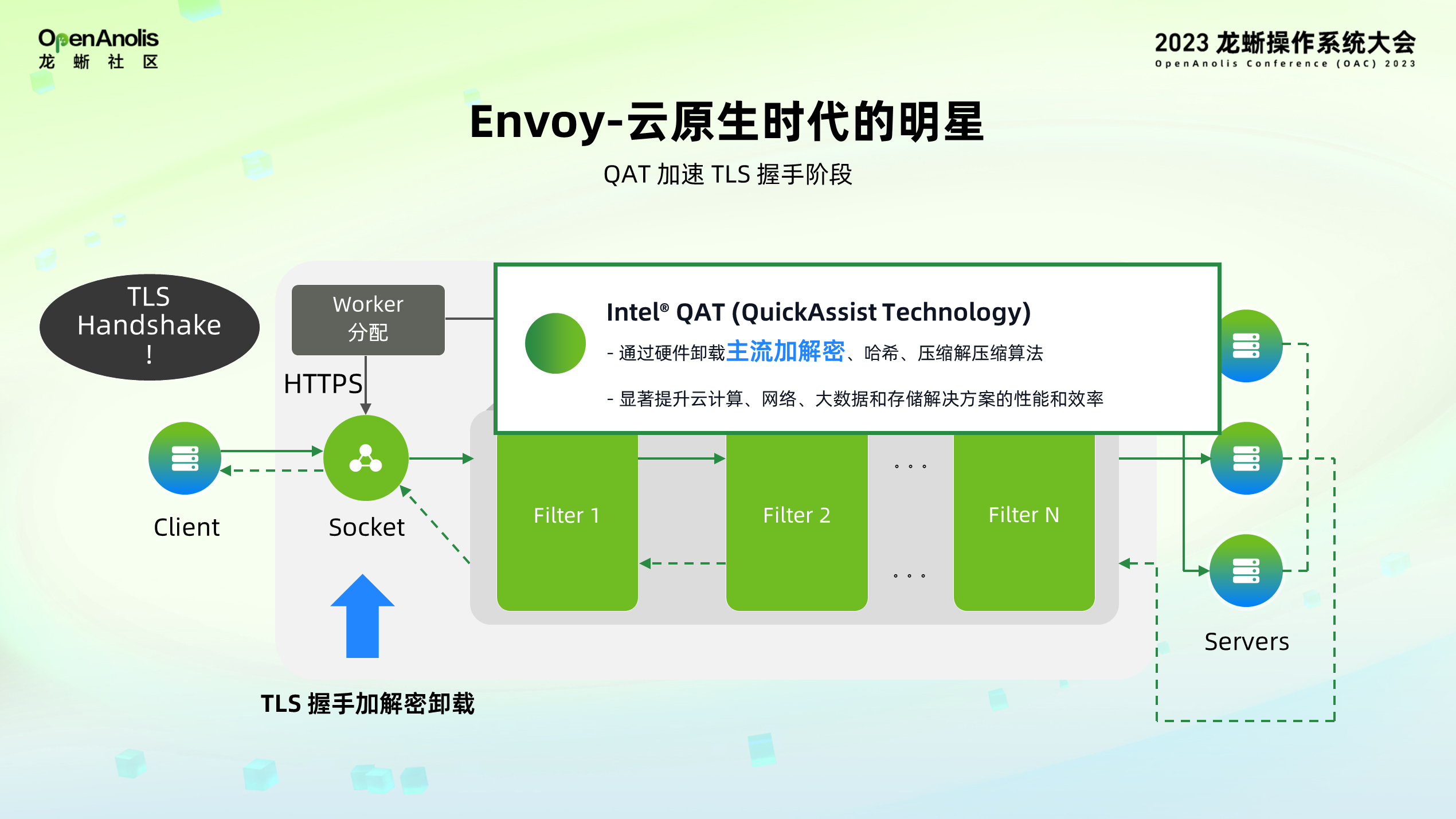
在微服务场景下,Envoy 无论是作为 Ingress Gateway 还是作为微服务的代理,都需要处理大量的 TLS 链接请求,尤其在握手阶段,要处理非常多非对称加解密的操作,需要消耗大量的 CPU 资源,因此在大规模微服务场景下这将成为性能瓶颈。而 Intel QAT 加速器通过硬件卸载主流加解密算法,能够显著提升非对称加解密阶段的计算速度。
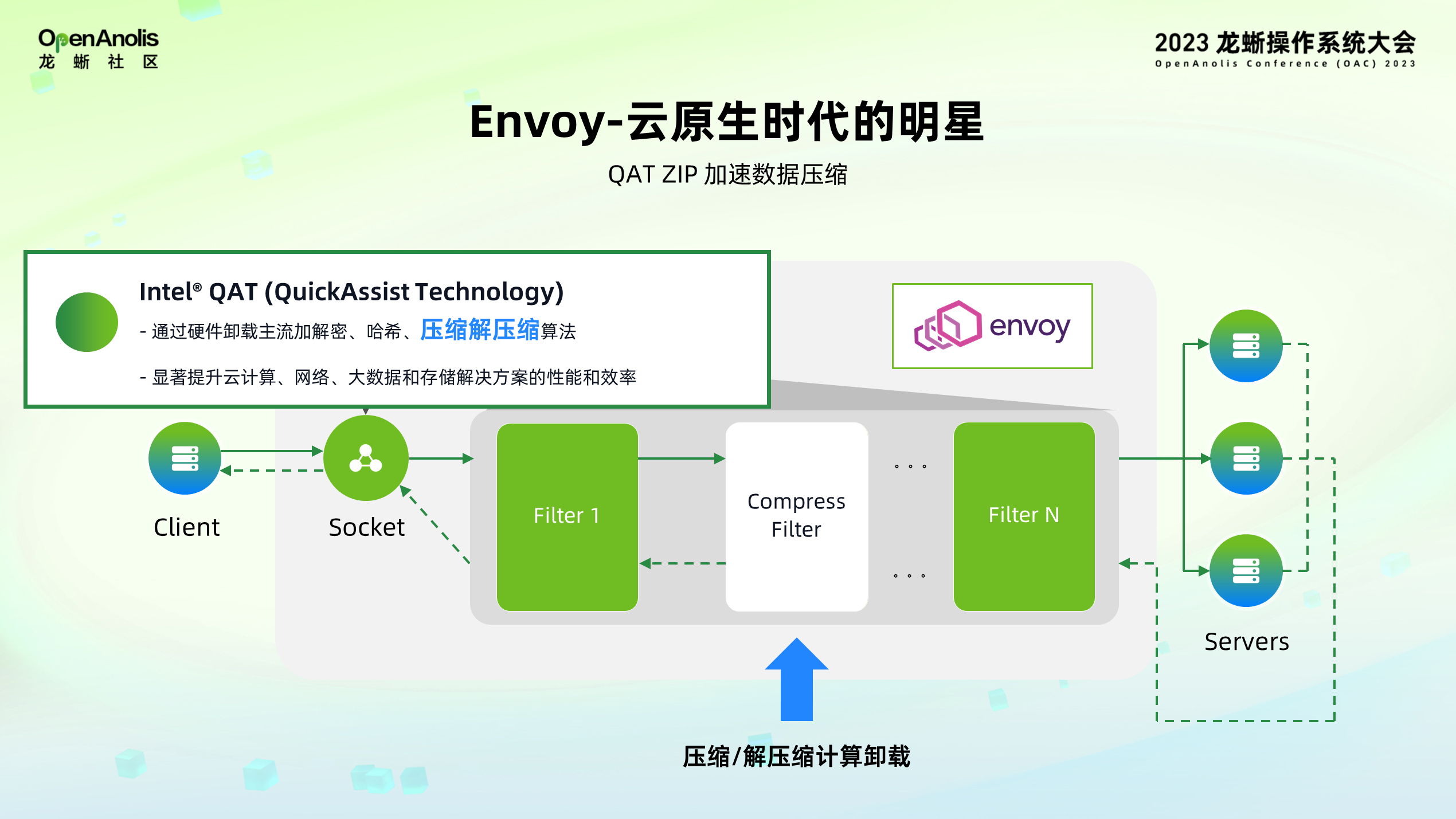
Intel QAT 加速器的另一功能则是支持压缩与卸载解压缩算法。Envoy 在使用过程中往往会加入数据压缩操作,可以显著减少在客户端和服务器之间传输的数据量,从而提高数据传输效率。Intel QAT 支持主流的 deflate 算法和 lz4 算法,能够很好地兼容并卸载 Envoy 原生的压缩操作,从而大大提高数据传输速度。
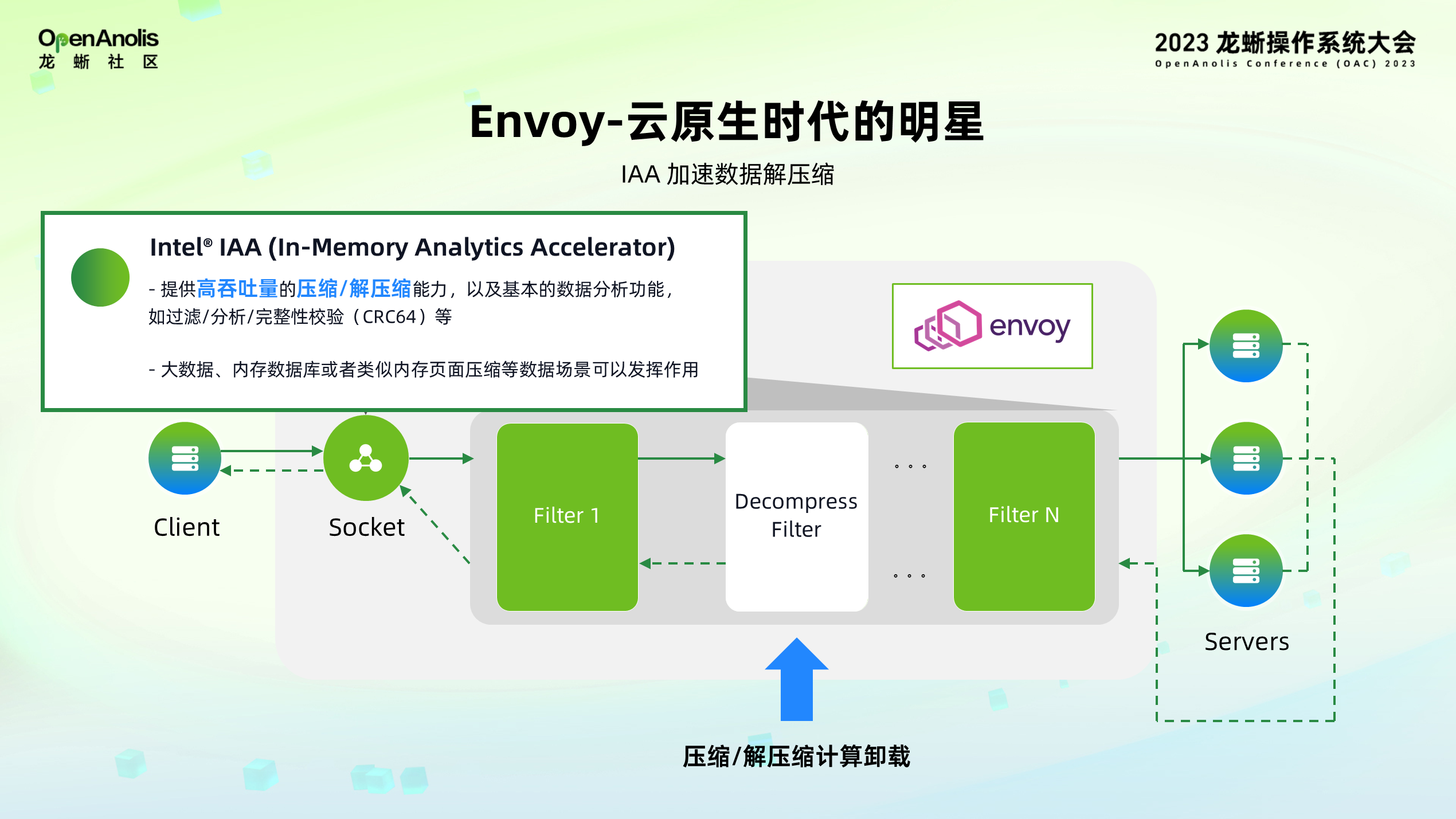
而 Intel IAA 加速器也能够实现数据的压缩与解压缩,与 Intel QAT 的强算力功能不同的是,Intel IAA 的优势在于能够有更快的 IO 吞吐性能,因此在解压缩需要更高吞吐性能的场景下,IAA 有更明显的优势。
我们知道,Envoy 作为中间代理需要接收各种各样的链接,这样会造成 Worker 间负载不均衡,所以 Envoy 提供了软件的负载均衡方式,通过加解锁实现 Worker 间负载的动态平衡,因此,我们也可以使用 Intel DLB 加速 Envoy Worker 分配环节。
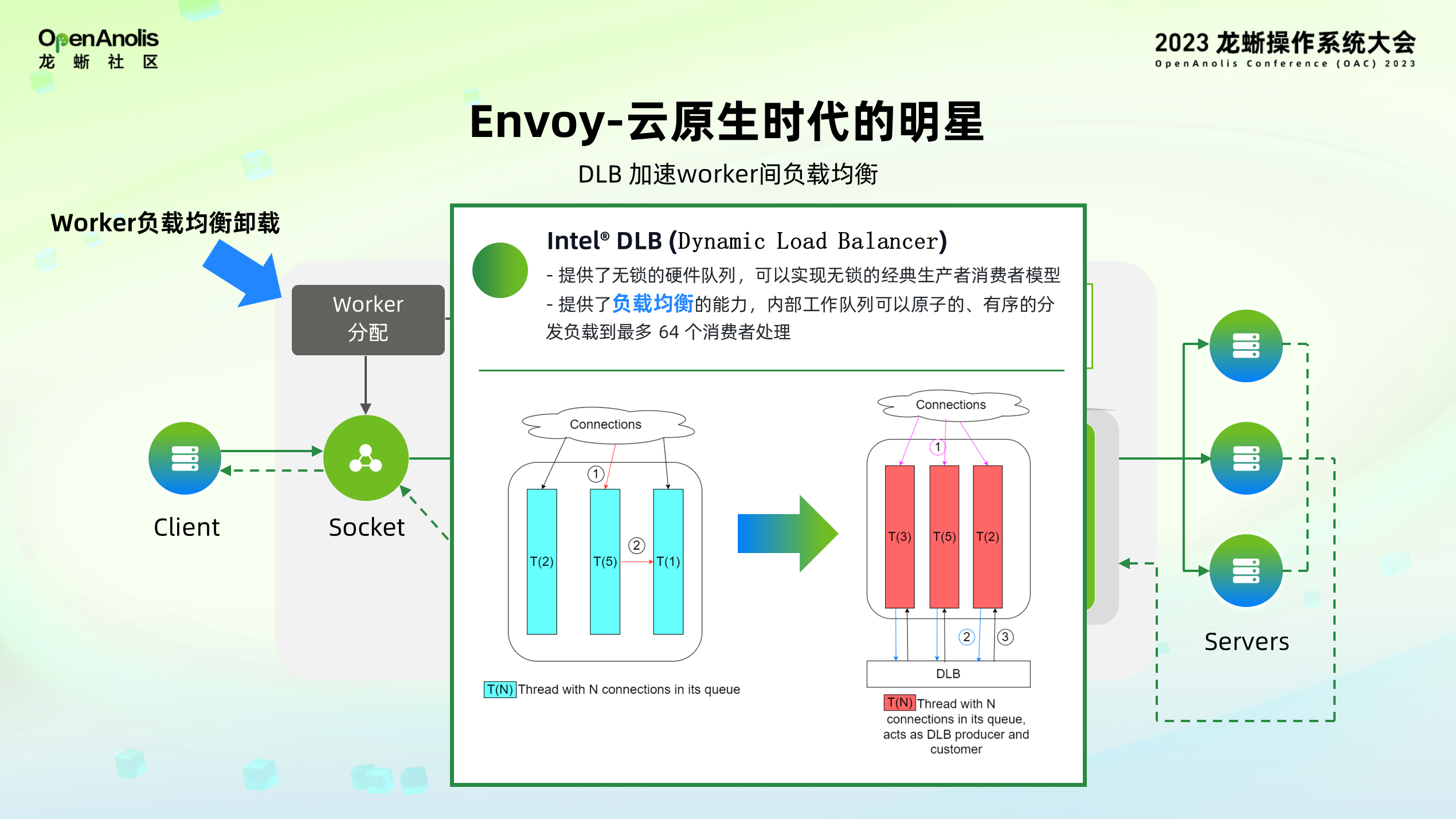
上图蓝色部分所示,目前 Envoy 提供了软件的负载均衡方式,通过加解锁来实现 Worker 间负载的动态平衡,而这样做的代价就是在链接数量较多的情况下,加解锁的开销反而会成为另一个性能瓶颈。Intel DLB 负载均衡加速器便是针对以上场景,提供无锁的负载均衡实现,如上图红色所示,Envoy 接收到链接后,直接把任务发送给 DLB 硬件,用硬件代为做 Worker 间的分配,实现无锁负载均衡,降低加解锁带来的开销。
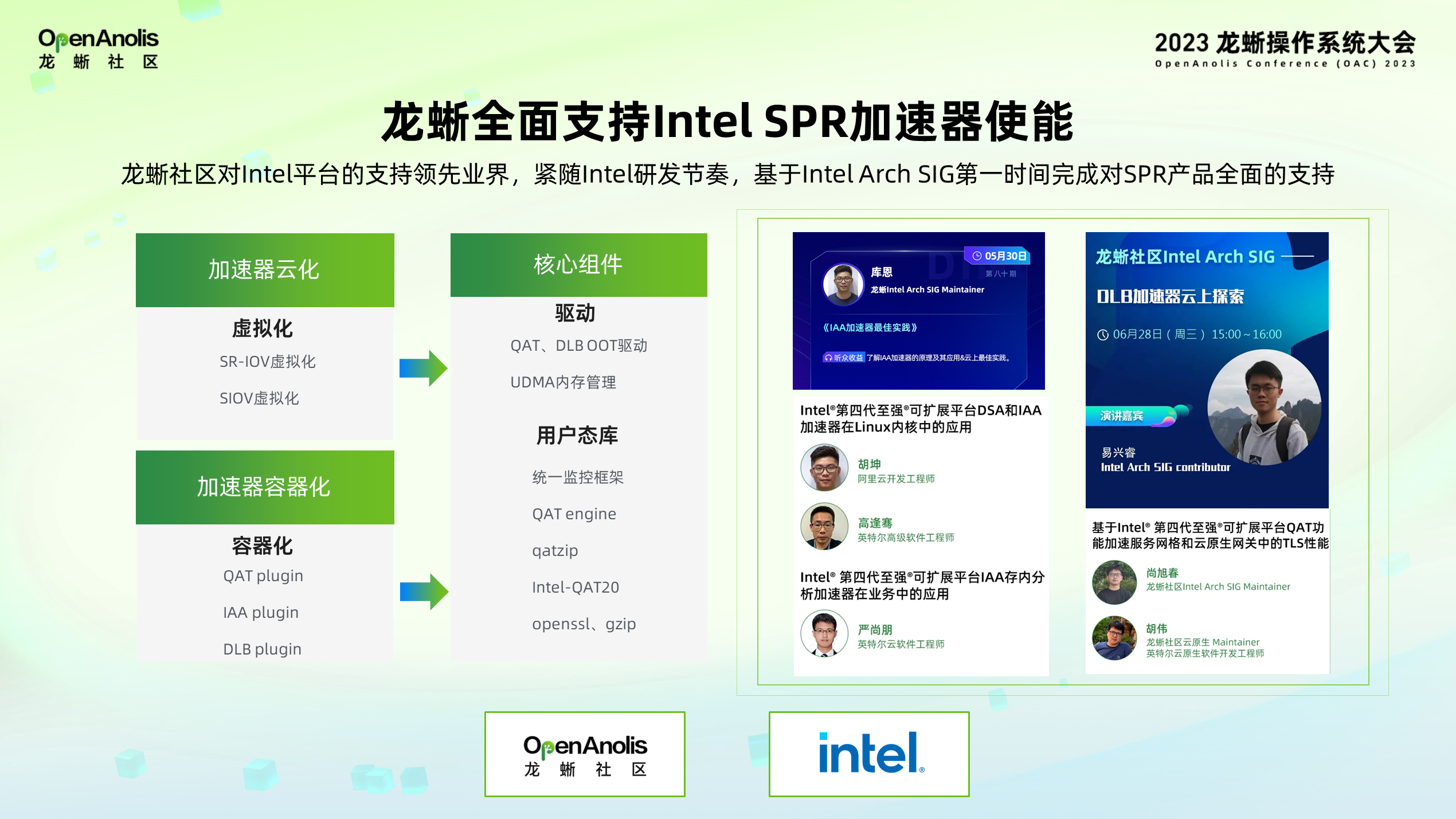
目前,龙蜥社区联合 Intel,基于 Intel Arch SIG 第一时间完成了对 SPR 加速器的全面支持,包括加速器最重要的云化。云化最基本的核心是加速器的虚拟化,包括 SR-IOV、SIOV 虚拟化技术,提供加速器往虚拟机做斜透传调度和加速器在虚拟机之间迁移的核心功能。在云原生场景下,加速器也需要做到容器化以支持云原生平台。
在龙蜥社区,我们维护了加速器的核心组件,包括加速器驱动,用户的库来做适配、维护和更新;也多次基于龙蜥操作系统分享了加速器最佳实践,大家可前往龙蜥官网-龙蜥大讲堂详细查看加速器的具体技术案例和实践应用。
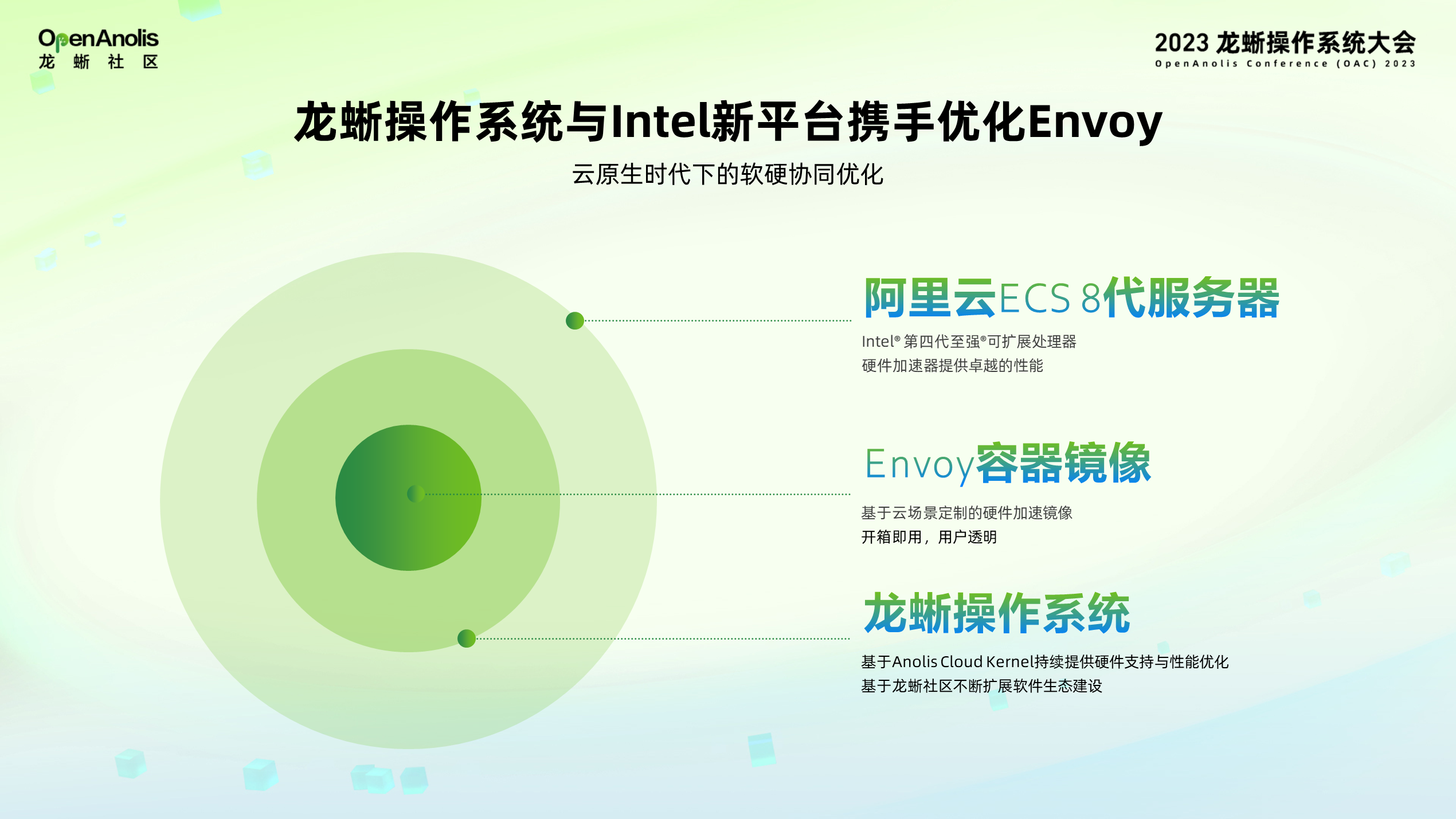
龙蜥社区助力 Intel SPR 加速器全球首发上云,已有基于多款加速器与软件协同优化的 Envoy 加速全链路云上解决方案,以阿里云 ECS 第八代 Intel 服务器为底座,提供相应的硬件支持,搭载龙蜥操作系统的完善软件生态,提供基于云场景定制的 Envoy 加速镜像,做到真正的开箱即用、用户透明。
方案设计
区别于传统的加速器解决方案,龙蜥社区为助力加速器上云,提供了一套用户透明的全栈解决方案。

在传统的云原生场景下,Envoy 运行的流程较为简单。通过 host 上搭载操作系统,部署 k8s 服务提供容器服务,拉取 Envoy 容器。Envoy 通过内置的静态编译库调用算法,从而让 CPU 实现相关计算与 Envoy 转发流程。将 Envoy 的计算卸载到最下面的加速器,需要自下而上,从内核到 k8s 层,到上层的用户态做适配、改造、优化,提供全栈解决方案。
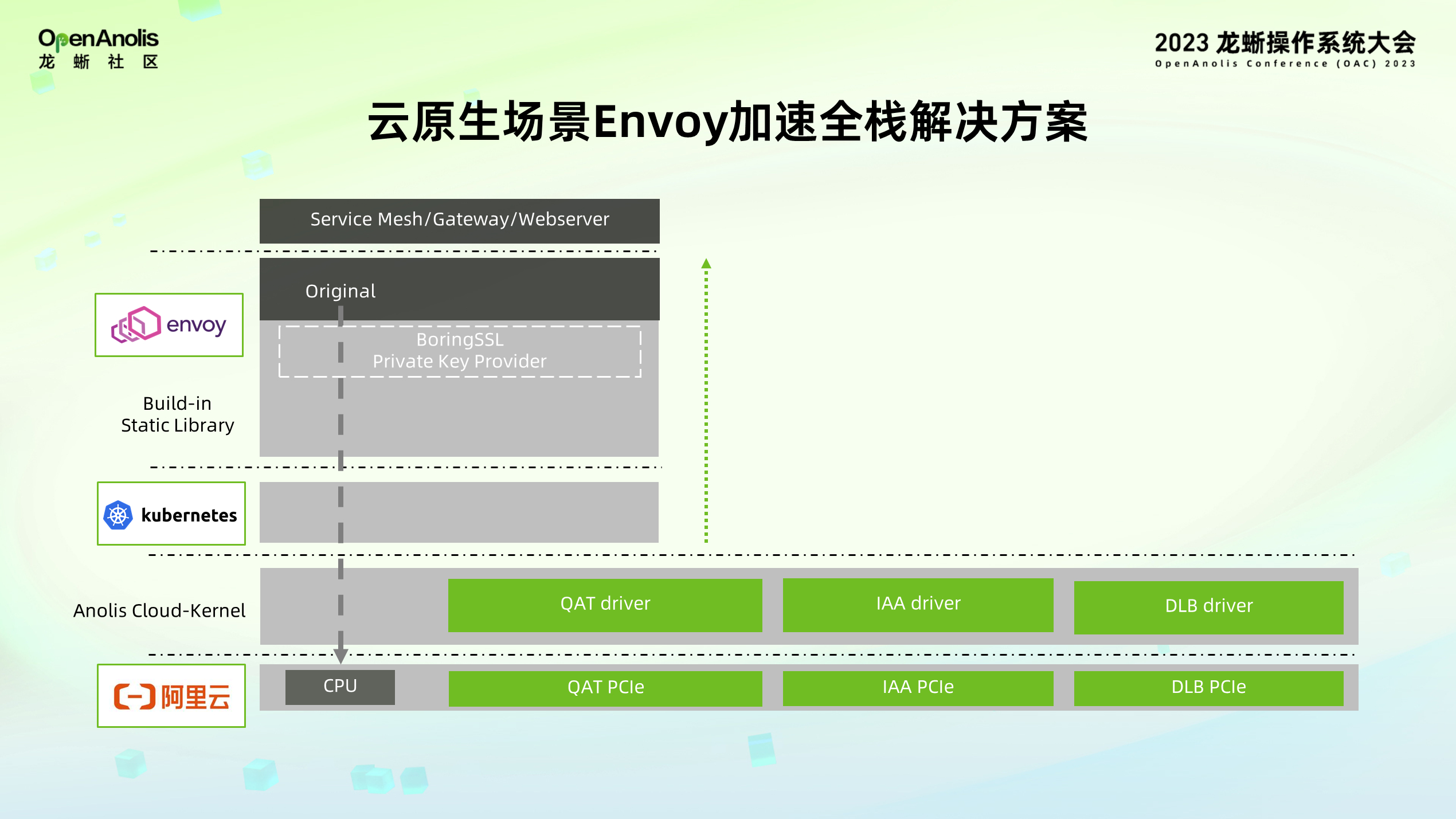
那当我们运用上 Intel 最新平台后,加速器如何在 host 上使能、配置、操作?我们知道,对于 PCle 设备要通过驱动进行管理,龙蜥操作系统提供了相应的加速器驱动实现,并做兼容性改造以兼容云上加速器生态,其中 Intel QAT 与 DLB 加速器以 out of tree 的方式提供,相关的软件包已集成到龙蜥 yum 源上,并提供持续更新与维护;IAA 加速器驱动以 intree 方式提供,则跟随龙蜥 Cloud Kernel 持续维护与更新。
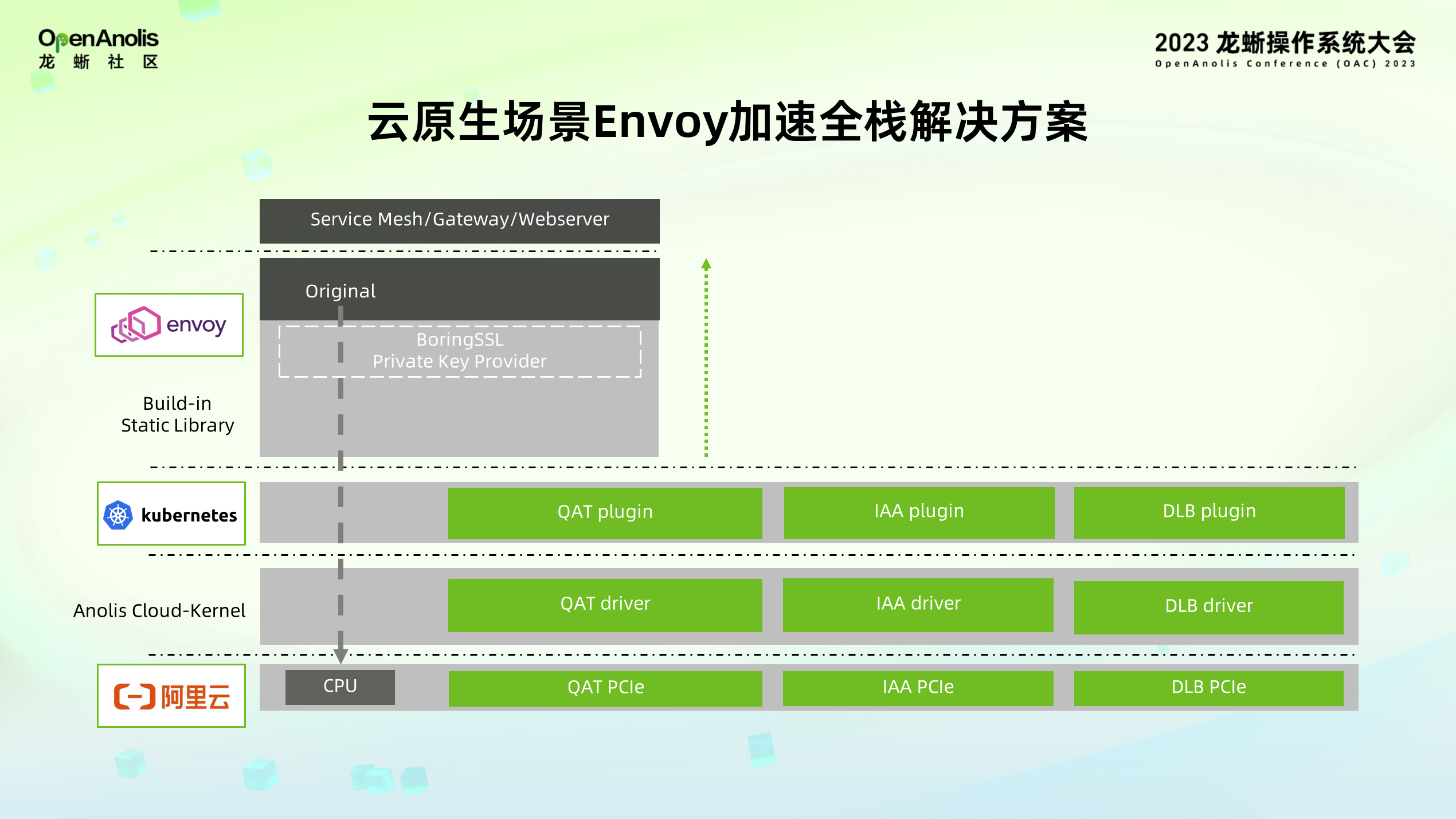
当加速器在 host 上使能后,如何在 k8s 集群中透出与调度?在 k8s 集群中,龙蜥社区提供了相关加速器 plugin 容器镜像,该镜像主要功能是对 host 上加速器设备进行周期性扫描并上报,让加速器作为一种与类似 CPU、memory 一样,可以被集群调度的资源,分配给上层 pod 使用。
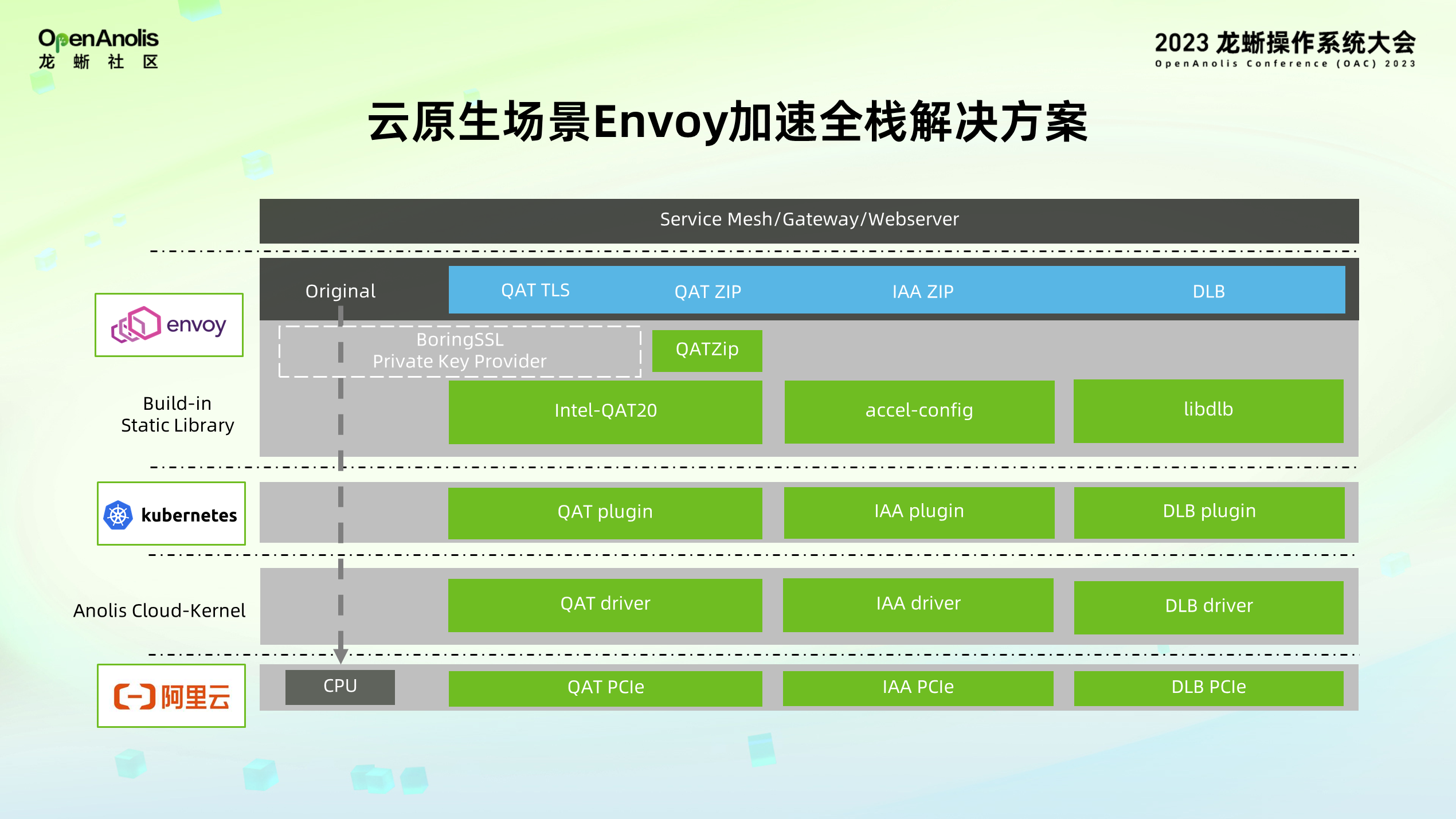
当容器中能够看到加速器设备后,Envoy 的计算任务如何卸载到加速器执行?针对每一个可以被卸载到加速器的任务(上图用蓝色标识表示),包括 QAT 加解密、QAT 压缩、IAA 解压缩、DLB 负载均衡,利用 Envoy 的 filter 机制开发了新的 filter 适配对应的特性。Filter 内部调用对应加速器用户态库的接口,实现将计算任务卸载到加速器进行执行。依照 Envoy 的开发习惯,相关的用户态库以静态库的方式被编译到 Envoy 二进制中,减少 Envoy 使用硬件加速时,需要额外动态库的环境依赖问题。
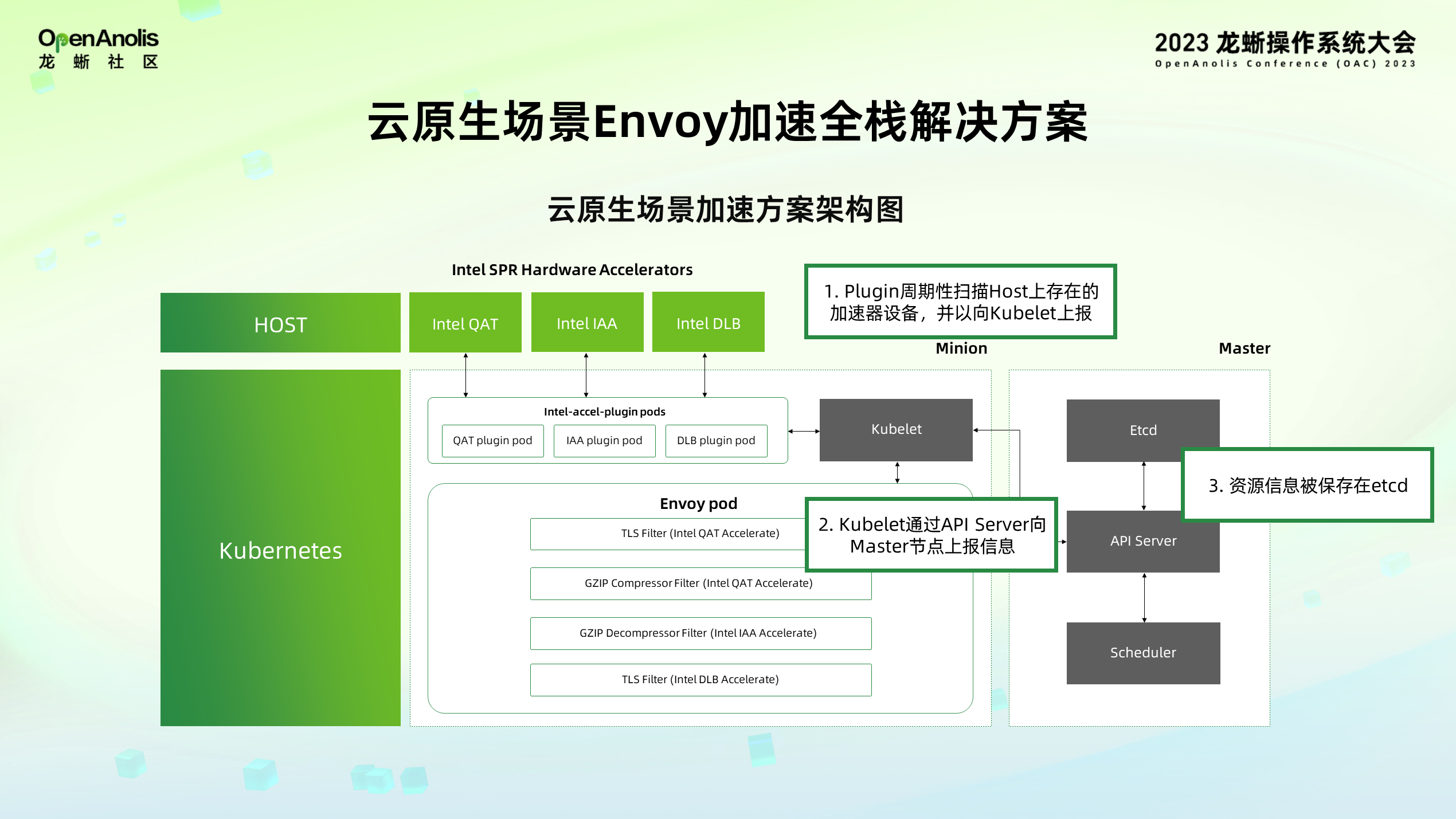
以云原生视角讲解下 Envoy 的加速流程。首先,host 上提供硬件资源供调用,在搭载的 K8s 集群中拉起加速器 plugin 容器镜像,容器镜像会周期性扫描 host 上存在对应的加速器设备节点,把设备节点以 device tree 的方式上报给 kubelet 服务,然后,kubelet 通过 API sever 向 master 节点更新信息,最后资源信息会被汇总到 etcd 中保存。
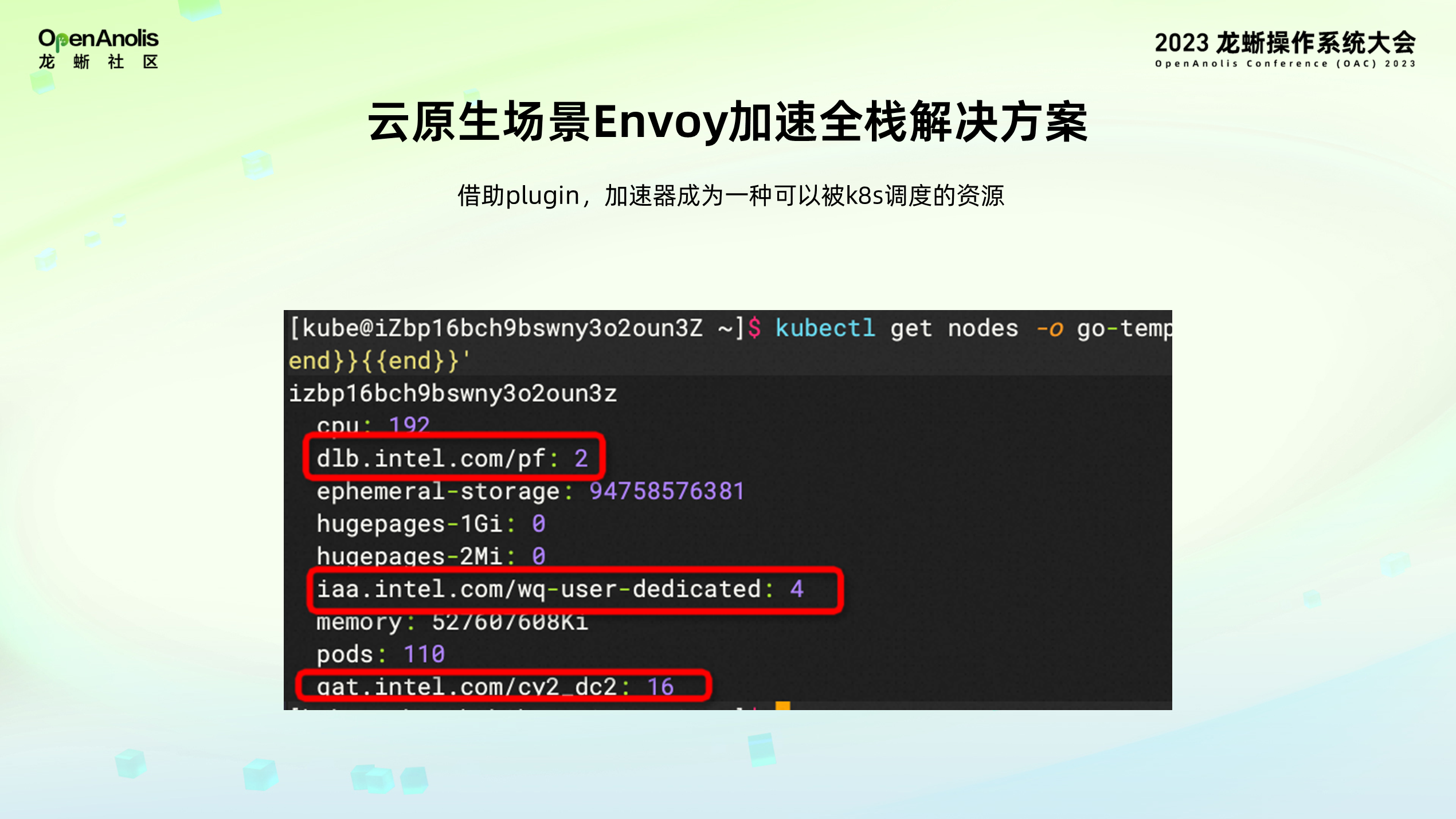
可以从图中看到,借助 plugin 容器镜像,host 上的资源除了 CPU、memory 等常见被调度的资源外,多出来的加速器的信息,包括 DLB 加速器、IAA 加速器、QAT 加速器以及加速器对应使用的数量,用户可以像分配 CPU、内存一样简单地对加速器设备进行分配。

当用户申请带有加速器容器时,会向 master 的 API server 创建 pod,对应的 kubelet 接收到请求,根据用户请求的加速器数量,将相应的设备节点 mount 到容器中,这样,容器中的 Envoy 就通过打开设备节点的方式来访问加速器。
性能测试
借由加速器卸载计算,Envoy 完成了无与伦比的性能飞跃。
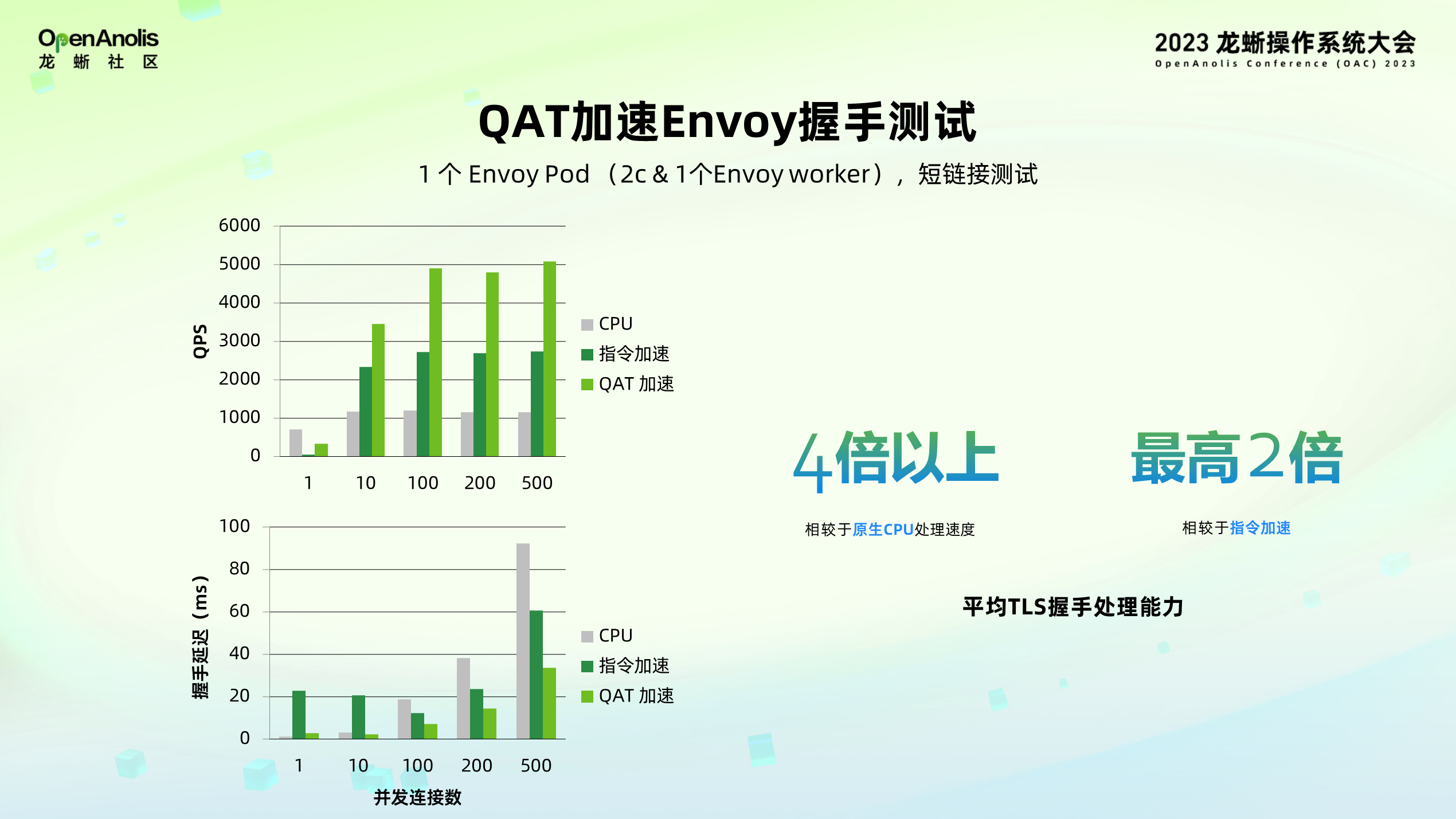
QAT 加速 Envoy 握手测试:在 2 CPU 容器短链接测试 QAT 加速 TLS 握手,性能的提升非常明显。上图中第一个图是 QPS 性能情况,经过 QAT 硬件加速后,其性能达到原本 CPU 的 4 倍以上,相较于上一代 Intel ice lake 的指令加速也达到最高 2 倍的性能。第二个图是关于握手延迟性能表现,从图中看到经过加速后,CPU 延迟降低 50% 以上。
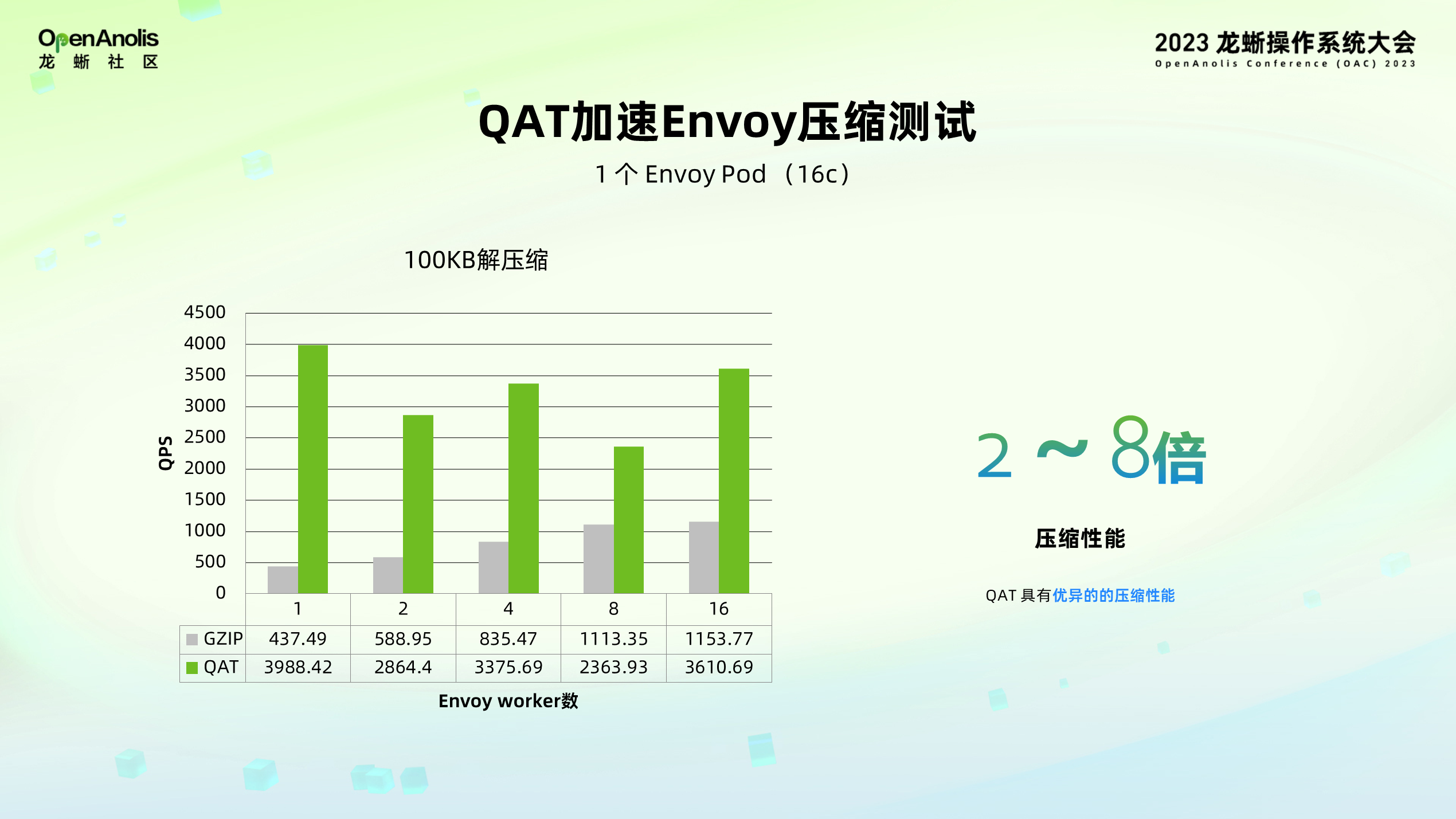
QAT 加速 Envoy 压缩测试:对 100KB 的文件进行压缩,QAT 展示出了强悍的计算性能。上图以 QPS 为指标,在不同负载的情况下, QPS 达到原生 CPU 的 2 - 8 倍。
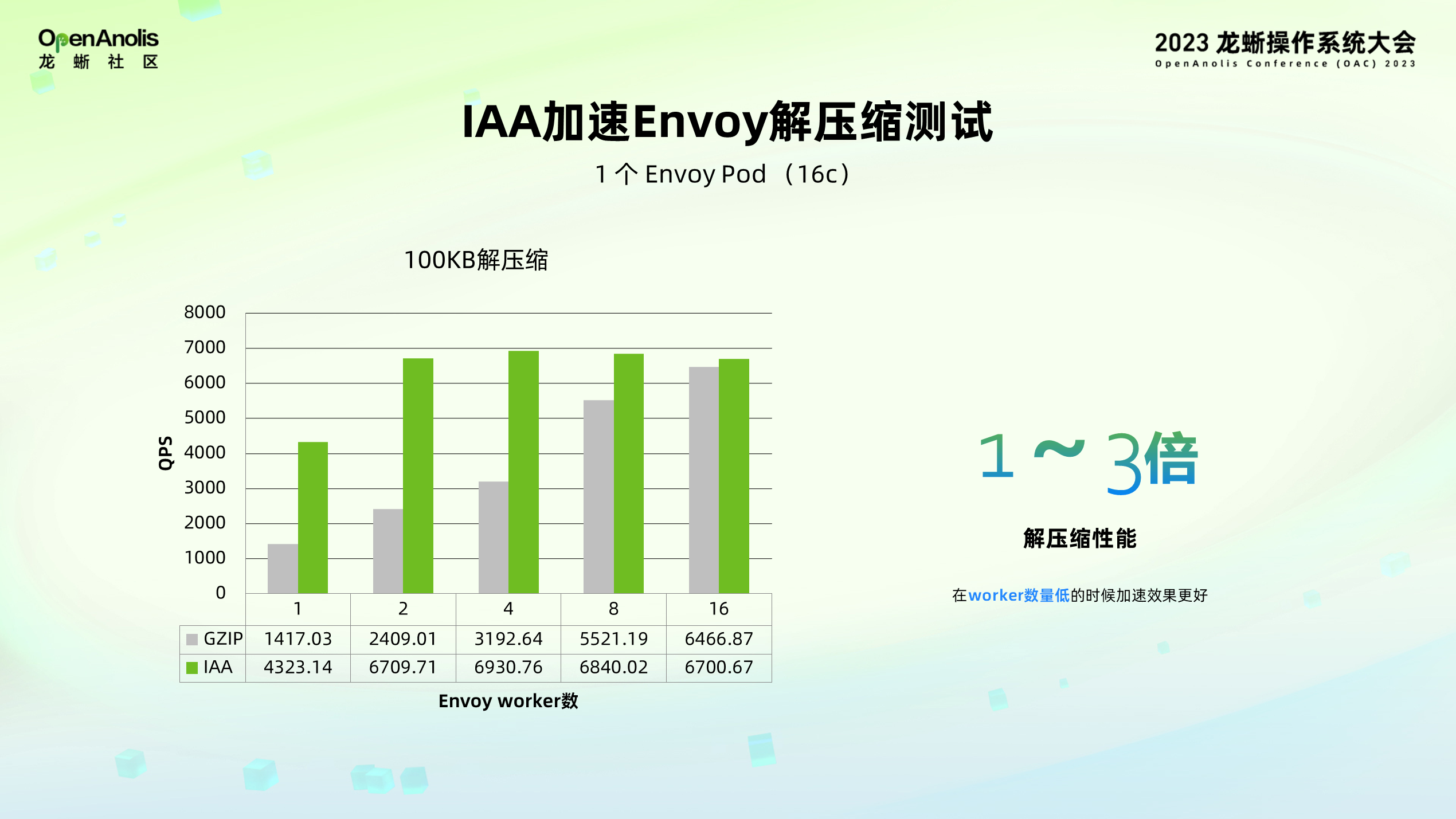
IAA 加速 Envoy 解压缩测试:解压缩相较于压缩需要的 CPU 开销不大,但是借由 IAA 的高吞吐特性,解压缩能够达到 CPU 的 QPS 1~3 倍,并在 Worker 数量较低的场景下提升尤为明显。
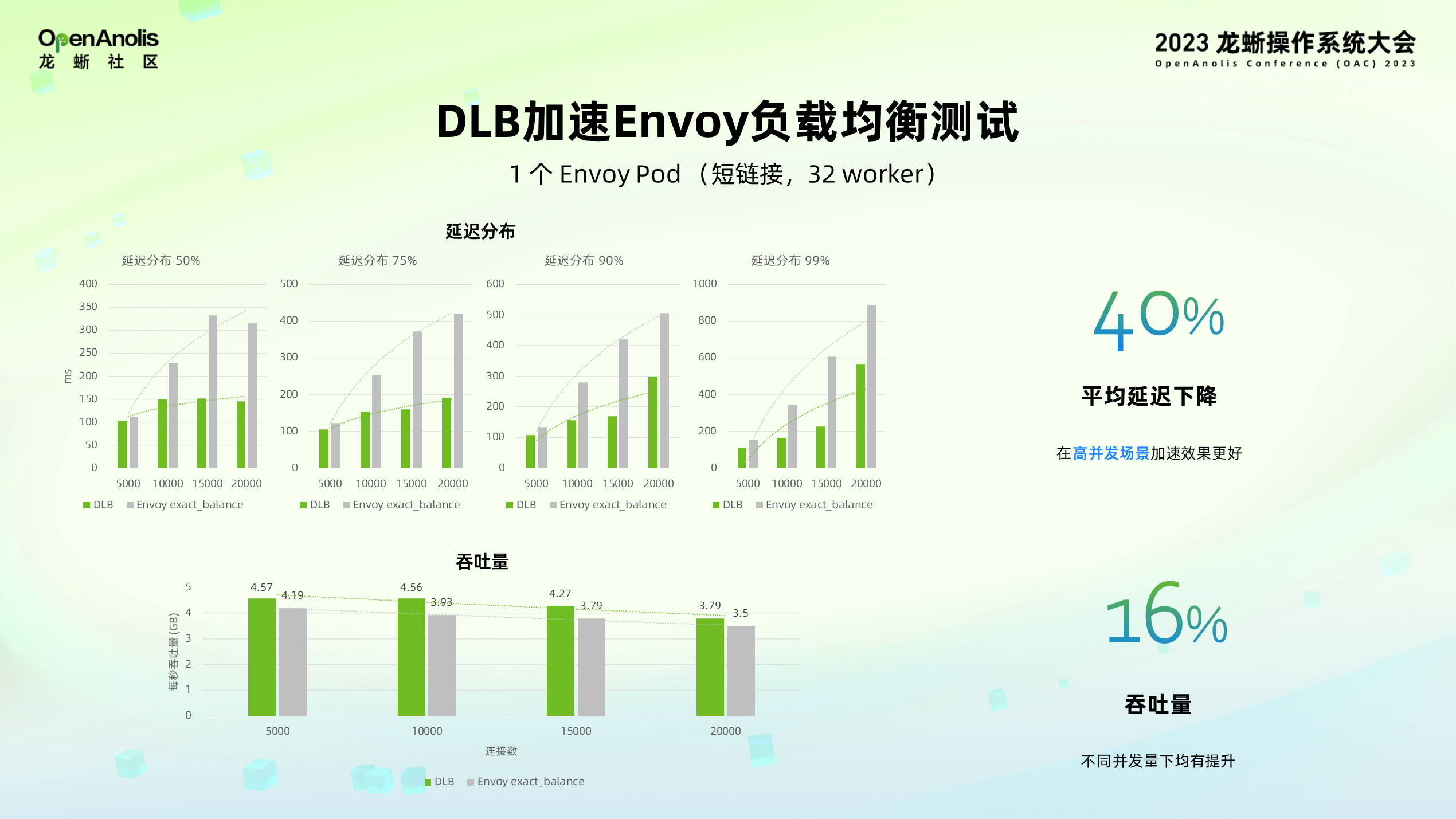
DLB 加速 Envoy 负载均衡测试:针对负载均衡在 32 Worker 的场景下进行测试,借由 DLB 加速器实现的无锁负载均衡,平均延迟下降 40%,吞吐量提升 16%,且 DLB 在高并发的场景下加速效果明显。

Envoy 加速器联合优化测试:为一次性展示以上的全部优化效果,设计了一个比较特殊的案例,本案例仅为展示联合加速效果用,具体用法参照实际业务场景。如上图所示,Client 向 server 申请一个 100kb 文件的下载,文件会被 Envoy 压缩发送到用户端,用户端将压缩后的文件原路返回,再经过一次解压发送到客户端。

上图是加速前后的火焰图对比,可以看出加速器加速效果非常显著,联合加速能够充分解放 Envoy 的性能。大家可以重点关注没有被加速器所加速的 Envoy 计算(灰色部分)。加速前灰色部分占 Envoy 整个时间链路不到 25%,经过加速器加速后,大量的计算时间被压缩,灰色部分在整个链路占比高达 75% 以上,大部分的数据处理被加速器加速后耗时大幅减少。
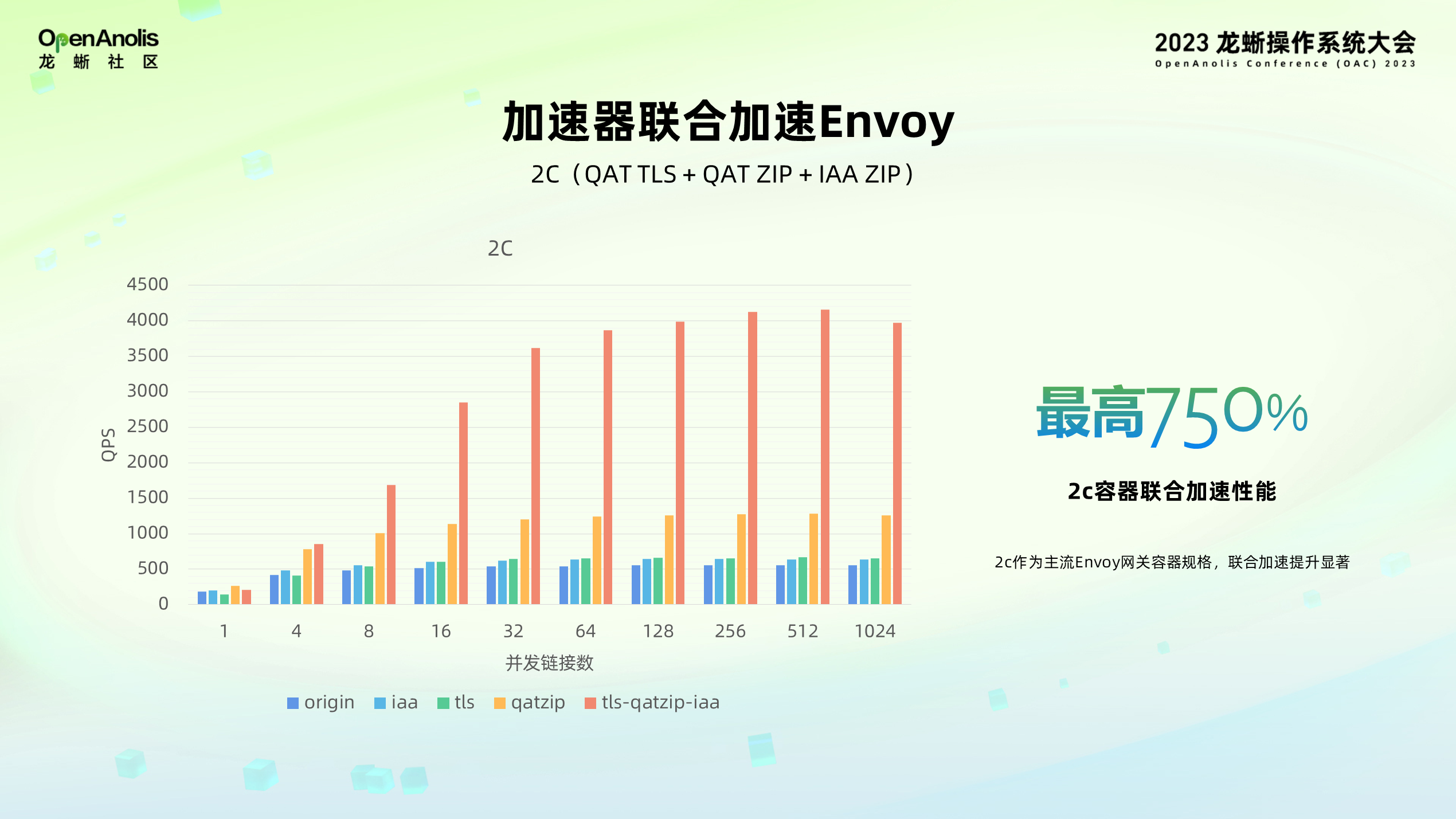
在常见的 2CPU Envoy 容器下,加速器联合加速性能最高可以达到 CPU 的 750%。从上图中可以看到,各个加速器联合优化的效果非常明显,虽然任务更加复杂,每个加速器性能优化在整个链路占比变小了,但是经过加速器优化叠加后能够达到 1+1>2 的效果。
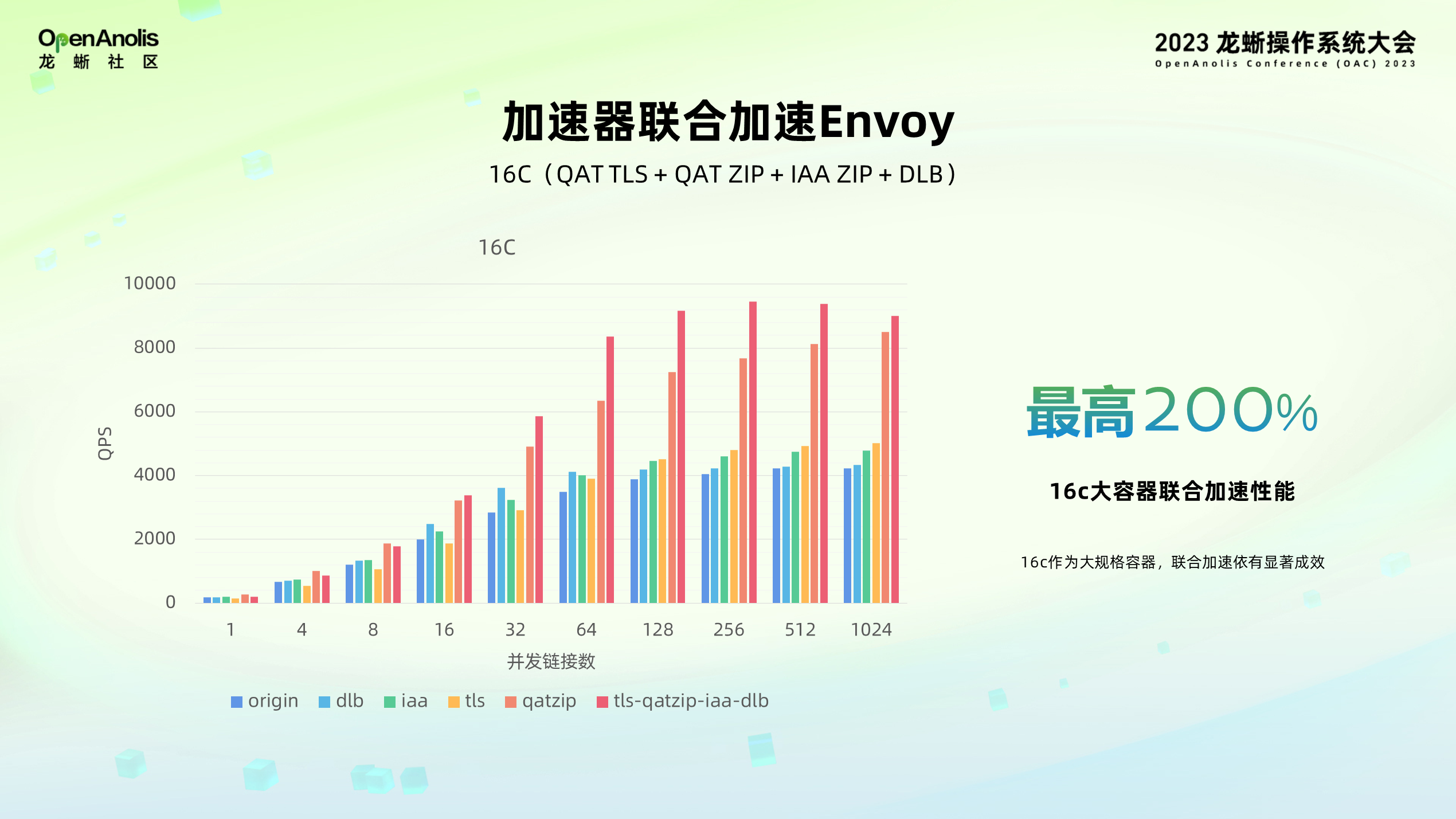
在 16C 大容器的场景下,虽然 Worker 数量变多,CPU 的性能得到了大幅改善,但是经过加速器加速后也有良好的性能表现,最高能够达到原生 Envoy 200% 的性能表现。
用户体验
从上述介绍可以看到,加速器带来的性能提升是显著,但是性能不代表一切,良好的用户体验才是重点。

针对云上场景,龙蜥社区基于阿里云第八代 Intel 实例,在社区版 Anolis OS 23 和商业版 Alibaba Cloud Linux 3 部署了全套解决方案,实现了开箱即用、运维监控、平滑兼容三大能力。

- 开箱即用镜像。龙蜥社区提供了一站式部署的容器镜像与 ECS 镜像,并给予持续支持与更新。Envoy 的加速镜像和加速器 plugin 镜像通过龙蜥社区发布的镜像站供用户下载使用。Envoy 的 ECS Host 侧的加速镜像则是龙蜥社区联合阿里云 ECS 团队,发布了 Host 侧的镜像方案,并提供 KeenTune 软件调优能力,进一步提升了 Envoy 的加速性能,实现软硬协同优化。
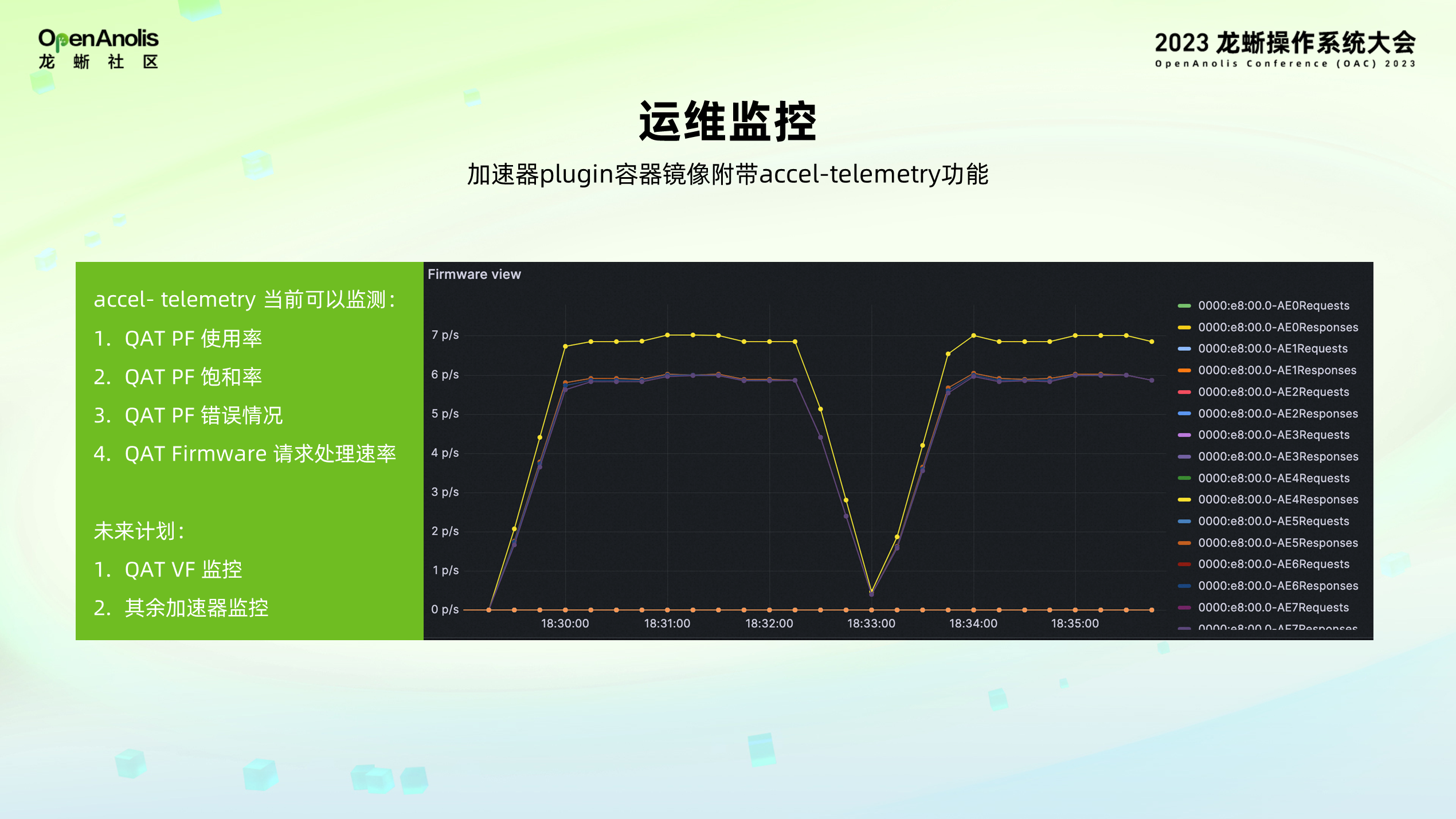
- 运维监控。加速器 plugin 容器镜像附带 accel-telemetry 功能,可以为加速器的硬件状态做一个实时的监测与上报,为加速器问题排查与定位,加速器调度等提供数据支持。

- 平滑兼容。通过 Envoy 配置自适应 Fallback,在硬件不可用情况下仍保留 Envoy 所有原生能力,譬如 QAT 和 IAA 的压缩解压缩则会自动切换到软件 gzip 实现,自适应兼容 ECS 新旧实例。

龙蜥社区在 Intel 平台上和其他业务方有着深度合作,比如龙蜥和阿里云 MSE 云原生网关团队在上一代 Intel ice lake 平台,已经借助 ice lake 指令加速技术加速 Envoy,大幅提升了 TLS 握手性能,为业务节约了大量的成本。未来,龙蜥将会持续与业务团队合作,在 SPR 平台上继续支持和探索,利用 Intel 硬件的新特性,为上层用户带来更加优秀的用户体验。
欢迎大家加入龙蜥社区内核兴趣小组(钉钉群号:30560020601)和 Intel Arch SIG 兴趣小组(钉钉群号: 44569842),共同探讨 Intel 架构的下一代芯片平台及功能。
相关链接:
龙蜥社区官网:OpenAnolis龙蜥操作系统开源社区
龙蜥社区Kernel SIG:Cloud Kernel - OpenAnolis龙蜥操作系统开源社区
龙蜥社区Intel Arch SIG:Intel Arch SIG - OpenAnolis龙蜥操作系统开源社区
—— 完 ——