第1关:Scala语言开发环境的部署
相关知识
Scala是一种函数式面向对象语言,它融汇了许多前所未有的特性,而同时又运行于JVM之上。随着开发者对Scala的兴趣日增,以及越来越多的工具支持,无疑Scala语言将成为你手上一件必不可少的工具。
而我们将要学习的大数据框架Spark底层是使用Scala开发的,使用scala写出的代码长度是使用java写出的代码长度的1/10左右,代码实现更加简练。
所以安装与配置Scala的环境是我们在开始学习Spark之前要完成的准备工作。
接下来我们开始安装,分为三个步骤:
下载解压;
配置环境;
校验。
下载解压
在Scala官网根据平台选择下载Scala的安装包,

接下来,解压到/app目录下:
mkdir /app //创建 app 目录
tar -zxvf scala-2.12.7.tgz -C /app
提示:在平台已经将解压包下载在/opt目录下了,就不需要再从网络下载了。
做法:
题目中已经说明在平台已经将spark安装包下载到/opt目录下了,所以不需要再下载了。
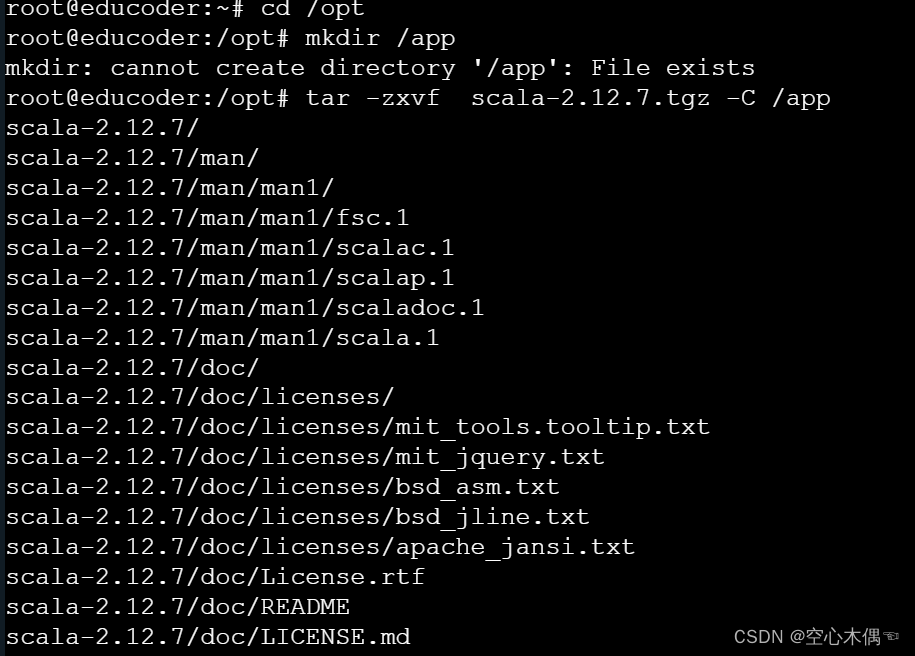
1.所以要先将目录跳转到/opt目录中:
cd /opt2.接下来,解压到/app目录下:
mkdir /app //创建 app 目录
tar -zxvf scala-2.12.7.tgz -C /app
配置环境
接下来我们开始配置环境,在自己本机上需要配置好Java环境,因为Scala是基于jvm的(在平台已经将Java环境配置好了):
vi /etc/profile
#set scala
SCALA_HOME=/app/scala-2.12.7
export PATH=$PATH:$SCALA_HOME/bin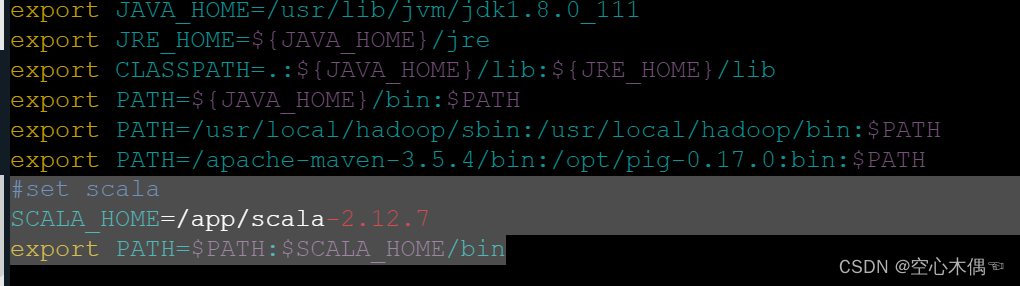
不要忘了配置好之后source /etc/profile
校验
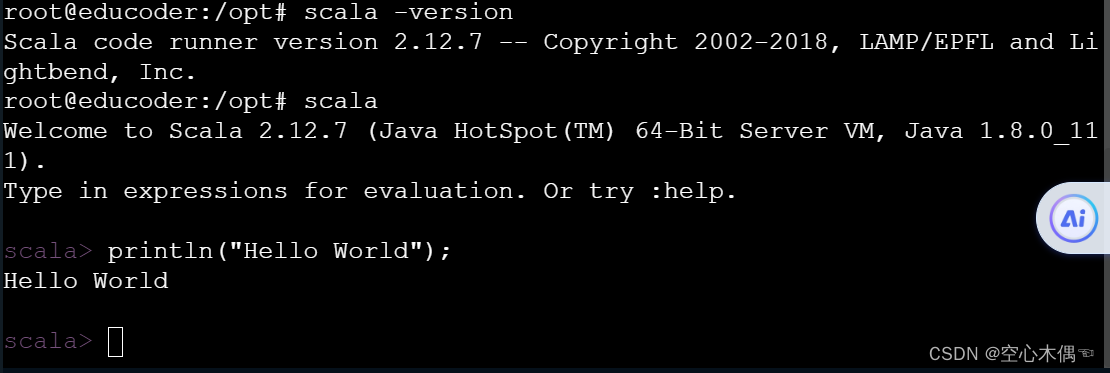
在命令行输入:scala -version出现如下结果就配置成功了

按照惯例,我们在开始一个编程语言要进行一个仪式,哈哈,那就是,Hello World,接下来我们使用Scala输出Hello World:
在命令行中输入scala进入Scala命令行,输入println("Hello World") 就可以啦。
第2关:安装与配置Spark开发环境
300
- 任务要求
- 参考答案
- 评论74
- 任务描述
- 相关知识
- 下载解压安装包
- 配置环境变量
- 修改Spark配置文件
- 校验
- 编程要求
任务描述
本关任务:安装与配置Spark开发环境。
相关知识
Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab(加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
本关我们来配置一个伪分布式的Spark开发环境,与配置Hadoop类似分为三个步骤:
- 下载解压安装包;
- 配置环境变量;
- 配置
Spark环境; - 校验。
下载解压安装包
我们从官网下载好安装包,
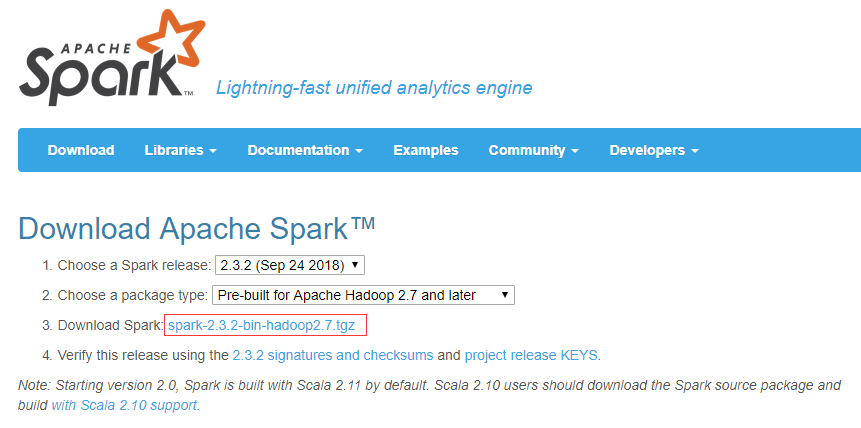
接下来解压,在平台已经将spark安装包下载到/opt目录下了,所以不需要再下载了。
tar -zxvf spark-2.2.2-bin-hadoop2.7.tgz -C /app
将压缩包解压到/app目录下。
配置环境变量
我们将spark的根目录配置到/etc/profile中(在文件末尾添加)。
vim /etc/profile
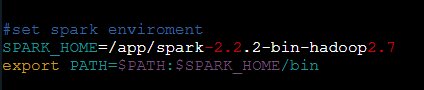
不要忘了source /etc/profile
修改Spark配置文件
切换到conf目录下:
cd /app/spark-2.2.2-bin-hadoop2.7/conf
在这里我们需要配置的是spark-env.sh文件,但是查看目录下文件只发现一个spark-env.sh.template文件,我们使用命令复制该文件并重命名为spark-env.sh即可;
![]()
接下来编辑spark-env.sh,在文件末尾添加如下配置:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_111export SCALA_HOME=/app/scala-2.12.7export HADOOP_HOME=/usr/local/hadoop/export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoopexport SPARK_MASTER_IP=machine_name # machine_name 根据自己的主机确定export SPARK_LOCAL_IP=machine_name # machine_name 根据自己的主机确定
参数解释:
| 参数 | 解释 |
|---|---|
| JAVA_HOME | Java的安装路径 |
| SCALA_HOME | Scala的安装路径 |
| HADOOP_HOME | Hadoop的安装路径 |
| HADOOP_CONF_DIR | Hadoop配置文件的路径 |
| SPARK_MASTER_IP | Spark主节点的IP或机器名 |
| SPARK_LOCAL_IP | Spark本地的IP或主机名 |
如何查看机器名/主机名呢?
很简单,在命令行输入:hostname即可。
校验
最后我们需要校验是否安装配置成功了; 现在我们启动spark并且运行spark自带的demo:
首先我们在spark根目录下启动spark: 在spark的根目录下输入命令./sbin/start-all.sh即可启动,使用jps命令查看是否启动成功,有woker和master节点代表启动成功。
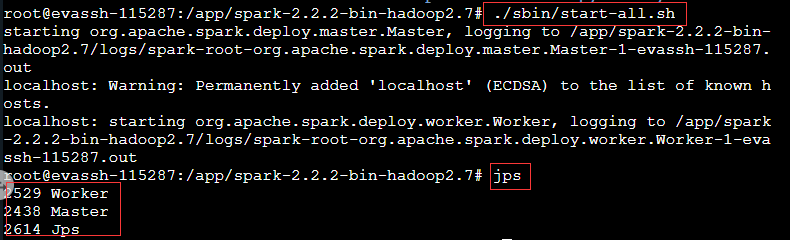
接下来运行demo:
- 在
Spark根目录使用命令./bin/run-example SparkPi > SparkOutput.txt运行示例程序 - 在运行的时候我们可以发现打印了很多日志,最后我们使用
cat SparkOutput.txt可以查看计算结果(计算是有误差的所以每次结果会不一样):
好了,如果你能到这一步就已经完成了伪分布式Spark的安装啦。
编程要求
做法:
题目中已经说明在平台已经将spark安装包下载到/opt目录下了,所以不需要再下载了。
1.所以要先将目录跳转到/opt目录中:
cd /opt2.然后按照步骤解压
tar -zxvf spark-2.2.2-bin-hadoop2.7.tgz -C /app
3.配置环境变量
vim /etc/profile将以下代码加入到编辑文件末尾
#set spark enviroment
SPARK_HOME=/app/spark-2.2.2-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin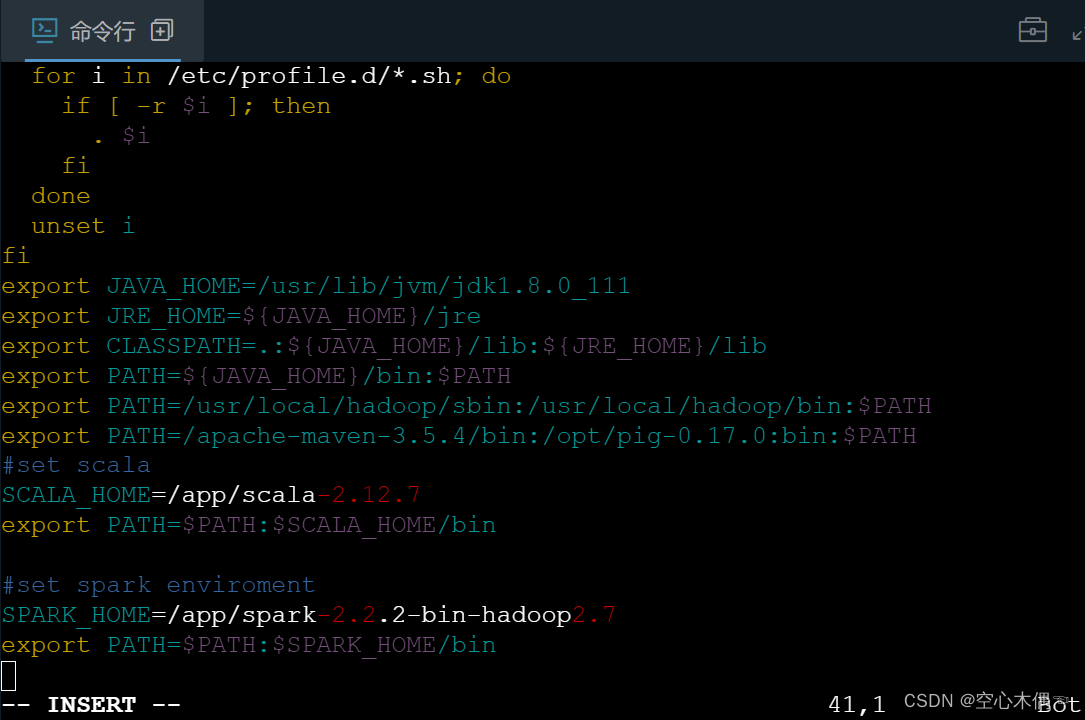
保存后使用以下代码更新环境变量
source /etc/profile
修改Spark配置文件
切换到conf目录下:
cd /app/spark-2.2.2-bin-hadoop2.7/conf
在这里我们需要配置的是spark-env.sh文件,但是查看目录下文件只发现一个spark-env.sh.template文件,我们使用命令复制该文件并重命名为spark-env.sh即可;

接下来编辑spark-env.sh,在文件末尾添加如下配置:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_111
export SCALA_HOME=/app/scala-2.12.7
export HADOOP_HOME=/usr/local/hadoop/
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_IP=machine_name # machine_name 根据自己的主机确定
export SPARK_LOCAL_IP=machine_name # machine_name 根据自己的主机确定
在命令行输入hostname查询自己的主机名

我这里的主机名是educoder
所以将
export SPARK_MASTER_IP=machine_name # machine_name 根据自己的主机确定
export SPARK_LOCAL_IP=machine_name # machine_name 根据自己的主机确定修改为
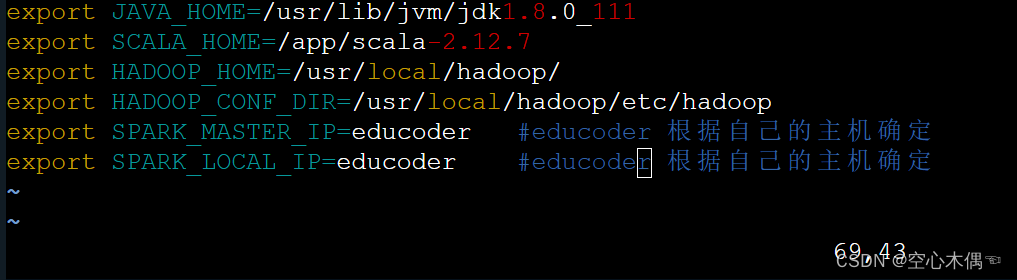
export SPARK_MASTER_IP=educoder # educoder 根据自己的主机确定
export SPARK_LOCAL_IP=educoder # educoder 根据自己的主机确定
参数解释:
参数 解释
JAVA_HOME Java的安装路径
SCALA_HOME Scala的安装路径
HADOOP_HOME Hadoop的安装路径
HADOOP_CONF_DIR Hadoop配置文件的路径
SPARK_MASTER_IP Spark主节点的IP或机器名
SPARK_LOCAL_IP Spark本地的IP或主机名
如何查看机器名/主机名呢?
很简单,在命令行输入:hostname即可。
校验
最后我们需要校验是否安装配置成功了;
现在我们启动spark并且运行spark自带的demo:
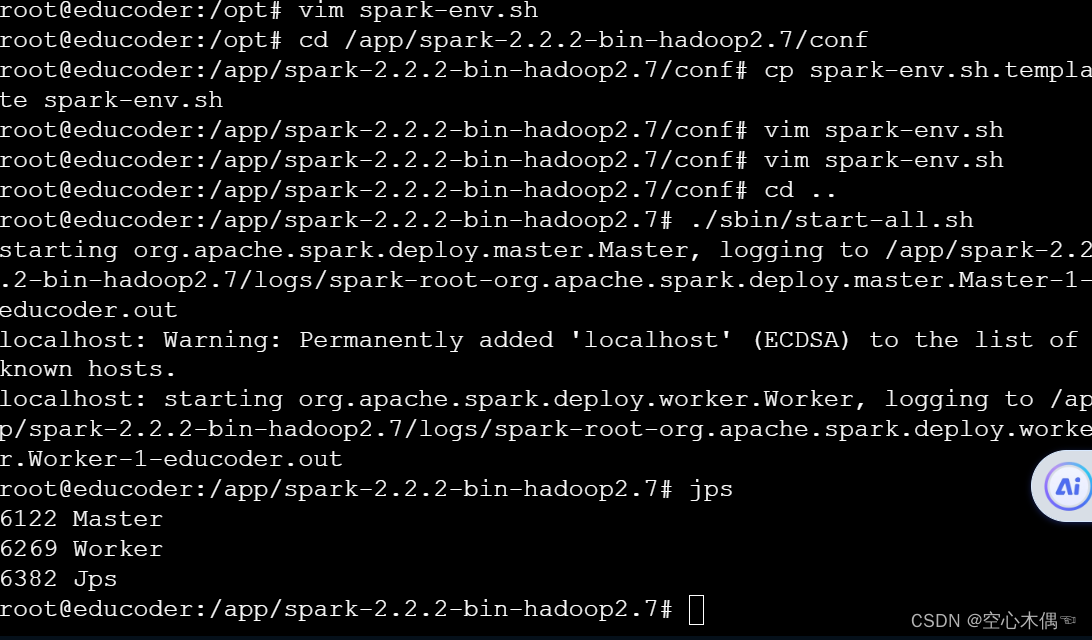
首先我们在spark根目录下启动spark:
在spark的根目录下输入命令./sbin/start-all.sh即可启动,使用jps命令查看是否启动成功,有woker和master节点代表启动成功。
接下来运行demo:
在Spark根目录使用命令./bin/run-example SparkPi > SparkOutput.txt运行示例程序
在运行的时候我们可以发现打印了很多日志,最后我们使用cat SparkOutput.txt可以查看计算结果(计算是有误差的所以每次结果会不一样):









![Ubuntu20.04 [Ros Noetic]版本——在catkin_make编译时出现报错的解决方案](https://img-blog.csdnimg.cn/direct/019cebf238d841ccab1fd32b1d89df70.png)