一、引言
1.1 Python列表简介
在Python编程中,列表(List)是最常用的数据结构之一,它是一个有序的集合,可以容纳任意类型的对象,如数字、字符串甚至其他列表。列表的特点是可变性,这意味着你可以添加、删除或修改列表中的元素。这使得列表成为处理动态数据的理想选择。
# 示例:创建一个包含不同类型的列表
my_list = [1, "two", 3.14, True]
1.2 列表在Python中的重要性
列表的重要性体现在以下几个方面:
- 灵活性:由于列表可以存储不同类型的数据,因此它非常适合用于临时存储各种信息。
- 可变性:与其他不可变数据结构(如元组)相比,列表的可变性使其在需要动态更新数据时更具优势。
- 内置操作:Python提供了丰富的内建方法,如
append(),insert(),sort()等,使得对列表的操作简便高效。 - 索引访问:通过索引,可以快速访问和修改列表中的特定元素。
- 遍历能力:列表是迭代器协议的一部分,可以轻松地遍历每个元素,常用于循环结构中。
列表在实际编程中扮演着核心角色,无论是简单的数据处理还是复杂的算法实现,你都离不开它的身影。
二、创建和初始化列表
2.1 空列表创建
创建一个空列表非常简单,只需一对方括号[]即可:
empty_list = []
2.2 初始化列表的多种方式
2.2.1 直接赋值
你可以直接用逗号分隔的值来初始化列表:
numbers = [1, 2, 3, 4, 5]
2.2.2 重复序列
使用*运算符可以创建包含重复元素的列表:
zeros = [0] * 5 # 创建包含5个0的列表
2.2.3 列表推导式
列表推导式是一种简洁的创建列表的方式,它基于某个条件生成新列表:
even_numbers = [num for num in range(10) if num % 2 == 0]
上述代码将创建一个包含0到9之间所有偶数的列表。
2.3 列表与元组的区别
虽然列表和元组都是序列,但它们有以下关键区别:
- 可变性:列表是可变的,而元组是不可变的。一旦创建,元组的内容不能被修改。
- 语法:列表用方括号
[]定义,元组用圆括号()定义,但单元素元组需要尾随的逗号。 - 性能:由于元组不可变,它们通常比列表更快,尤其是作为字典键或作为集合元素时。
列表的可变性使它在需要动态修改数据的场景中更有优势,而元组则适用于需要保护数据不变的情况。
三、访问列表元素
3.1 切片操作
切片操作允许你获取列表的一部分。基本语法是list[start:end:step]:
fruits = ['apple', 'banana', 'cherry', 'date']
first_two = fruits[0:2] # 获取前两个元素
last_two = fruits[-2:] # 获取最后两个元素
every_other = fruits[::2] # 获取列表中每隔一个元素
3.2 使用索引和负索引
索引从0开始,例如fruits[0]是列表的第一个元素。负索引从-1开始,fruits[-1]是最后一个元素:
first_element = fruits[0]
last_element = fruits[-1]
3.3 列表的长度与索引范围
使用len()函数可以获取列表的长度,即元素个数:
length = len(fruits)
请注意,索引范围是0到length - 1,超出这个范围的索引会引发IndexError。
3.4 列表的下标越界处理
尝试访问不存在的索引会导致IndexError。你可以使用try/except块来捕获并处理这种错误:
try:
out_of_bounds = fruits[len(fruits)]
except IndexError:
print("That index doesn't exist!")
通过这种方式,当试图访问不存在的索引时,程序不会立即崩溃,而是执行异常处理代码。
四、列表的基本操作
4.1 添加元素:append, insert
append()方法在列表末尾添加一个元素:
numbers = [1, 2, 3]
numbers.append(4) # [1, 2, 3, 4]
insert()方法在指定位置插入元素:
numbers.insert(1, "two_point_five") # [1, 'two_point_five', 2, 3, 4]
4.2 删除元素:remove, pop, del
remove()删除第一个匹配的元素:
numbers.remove("two_point_five") # [1, 2, 3, 4]
pop()移除指定索引处的元素并返回该元素;默认移除最后一个元素:
last_number = numbers.pop() # 4, numbers = [1, 2, 3]
del关键字用于删除整个列表或列表的部分:
del numbers[1] # numbers = [1, 3]
del numbers # 删除整个列表
4.3 修改元素
通过索引可以直接修改列表中的元素:
numbers[1] = 2.5 # numbers = [1, 2.5, 3]
4.4 查找元素:index, count
index()返回指定元素的第一个出现的索引:
first_occurrence = numbers.index(3) # 2
count()返回元素在列表中出现的次数:
occurrences = numbers.count(2.5) # 1
这些基本操作构成了列表操作的核心,它们允许你构建、修改和管理列表中的数据。在实际编程中,这些方法经常结合使用,以满足各种需求。
五、列表的排序操作
5.1 sort方法
sort()方法用于就地排序列表。默认按升序排序,也可以指定reverse=True进行降序排序:
unsorted_list = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
unsorted_list.sort() # 升序排序
unsorted_list.sort(reverse=True) # 降序排序
注意,sort()方法会改变原始列表。
5.2 sorted函数
sorted()函数返回一个新的已排序的列表,不会改变原列表:
unsorted_list = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
sorted_list = sorted(unsorted_list) # 不影响原列表
同样,key参数可以指定排序依据,例如按字符串长度排序:
words = ['apple', 'banana', 'cherry']
sorted_words = sorted(words, key=len) # 按长度排序
5.3 排序的稳定性与时间复杂度
- 稳定性:在排序过程中,相等的元素保持原有的相对顺序。
sort()和sorted()在Python 3中都是稳定的排序算法。 - 时间复杂度:
sort()和sorted()的时间复杂度通常是O(n log n),其中n是列表的长度。在大多数情况下,这提供了高效的排序性能。
排序操作对于数据的分析和处理至关重要,尤其是在需要对大量数据进行比较和组织时。理解这些排序方法及其性能特性可以帮助你选择合适的方法来处理列表。
六、列表的组合与拆分
6.1 连接操作:extend, +
extend()方法将一个列表的所有元素添加到另一个列表的末尾:
list1 = [1, 2, 3]
list2 = [4, 5, 6]
list1.extend(list2) # list1 = [1, 2, 3, 4, 5, 6]
+运算符创建一个新的列表,包含两个列表的元素:
list3 = list1 + list2 # list3 = [1, 2, 3, 4, 5, 6, 4, 5, 6]
6.2 切片复制与深浅拷贝
- 切片操作创建的是原列表的一个浅拷贝:
original = [1, 2, [3, 4]]
copy = original[:] # 浅拷贝
- 如果列表包含可变对象(如其他列表),浅拷贝仅复制引用,不复制对象本身。对拷贝的修改会影响原列表:
copy[2].append(5) # original = [1, 2, [3, 4, 5]], copy = [1, 2, [3, 4, 5]]
- 使用
copy()或deepcopy()模块可以创建深拷贝,即使包含可变对象,也完全复制新的对象:
from copy import deepcopy
deep_copy = deepcopy(original) # 深拷贝
deep_copy[2].append(6) # original = [1, 2, [3, 4, 5]], deep_copy = [1, 2, [3, 4, 5, 6]]
6.3 列表分割:split, slice
split()方法通常用于字符串,但在列表中,可以模拟类似行为:
numbers = [1, 2, 3, 4, 5, 6]
part1, part2 = numbers[:3], numbers[3:] # 分割列表
列表的组合与拆分操作在处理数据时非常实用,它们可以让你方便地构建和重组数据结构,以适应不同的需求。
七、高级列表操作
7.1 列表解析
列表解析提供了一种简洁的创建新列表的方式,基于现有列表或其他可迭代对象:
squares = [x**2 for x in range(10)] # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
7.2 filter, map, reduce与列表
filter()返回满足条件的元素:
even_numbers = list(filter(lambda x: x % 2 == 0, range(10))) # [0, 2, 4, 6, 8]
map()将函数应用于列表的每个元素:
squared = list(map(lambda x: x**2, range(10))) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
reduce()(需要functools模块)将列表元素逐步减少到一个单一的值:
from functools import reduce
product = reduce(lambda x, y: x * y, range(1, 6)) # 120
这些函数在处理列表时提供了更高级的抽象,使得代码更简洁,易于理解。
7.3 列表生成器表达式
列表生成器类似于列表解析,但生成的是生成器对象,可以按需生成元素,节省内存:
squares_generator = (x**2 for x in range(10))
通过迭代器或next()函数可以逐个获取生成器的元素。
高级列表操作提供了更强大的工具,帮助你以更高效、更简洁的方式处理列表数据。在编写代码时,考虑使用这些技术可以提高代码的可读性和性能。
八、列表的性能优化
8.1 避免频繁的切片操作
切片操作会产生新的列表对象,如果频繁进行,可能会消耗大量内存。考虑使用islice()(需要itertools模块)或生成器表达式来减少内存开销:
from itertools import islice
large_list = list(range(1000000))
# 使用islice
chunk = list(islice(large_list, 100, 200))
# 或使用生成器表达式
chunk_generator = (x for x in large_list[100:200])
8.2 使用适当的数据结构替代大列表
对于某些特定用途,如存储唯一值,考虑使用set代替list,或者使用collections.Counter来统计元素出现的次数。
unique_values = set(large_list)
value_counts = Counter(large_list)
8.3 列表的内存管理
- 使用
del删除不再需要的列表,释放内存。 - 使用
clear()方法清空列表,而不是创建新列表。 - 对于非常大的列表,考虑分块处理,避免一次性加载所有数据。
性能优化是编写高效代码的关键。理解列表和其他数据结构的内部工作原理,以及何时使用它们,可以帮助你编写出更优化的代码。在处理大量数据时,尤其需要注意内存管理和计算效率。
九、列表在实际项目中的应用示例
9.1 数据存储与处理
列表常用于存储和处理数据,例如日志文件、用户输入或数据库查询结果:
# 日志条目
log_entries = ["User A logged in", "User B updated profile", "User C made a purchase"]
# 数据库查询结果
users_data = [{"id": 1, "name": "Alice"}, {"id": 2, "name": "Bob"}]
# 处理数据
for entry in log_entries:
process_log_entry(entry)
for user in users_data:
send_email(user["name"], "Welcome to our service!")
9.2 文件读写中的应用
在读取文件内容时,可以逐行读入列表:
with open("file.txt", "r") as file:
lines = file.readlines()
for line in lines:
process_line(line.strip()) # 去除行尾的换行符
9.3 网络爬虫中的列表使用
网络爬虫经常使用列表来存储抓取的网页链接或数据:
import requests
from bs4 import BeautifulSoup
urls_to_crawl = ["http://example.com", "http://example.org"]
visited_urls = []
while urls_to_crawl:
url = urls_to_crawl.pop(0)
visited_urls.append(url)
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
new_links = soup.find_all("a", href=True)
urls_to_crawl.extend([link["href"] for link in new_links if link["href"] not in visited_urls])
列表在实际项目中无处不在,它们是数据处理、文件操作和网络编程等任务的基础。理解如何有效地使用列表,可以使你的代码更加灵活和高效。
十、结语
10.1 列表总结
通过本文,我们深入了解了Python列表的各个方面,包括创建、访问、操作、排序、组合拆分、高级操作和性能优化。列表作为Python中最重要的数据结构之一,其灵活性和功能强大性使其在各种编程场景中发挥着至关重要的作用。
10.2 进阶学习推荐
- 链表与内存管理:了解Python列表背后的数据结构,以及如何影响内存分配和性能。
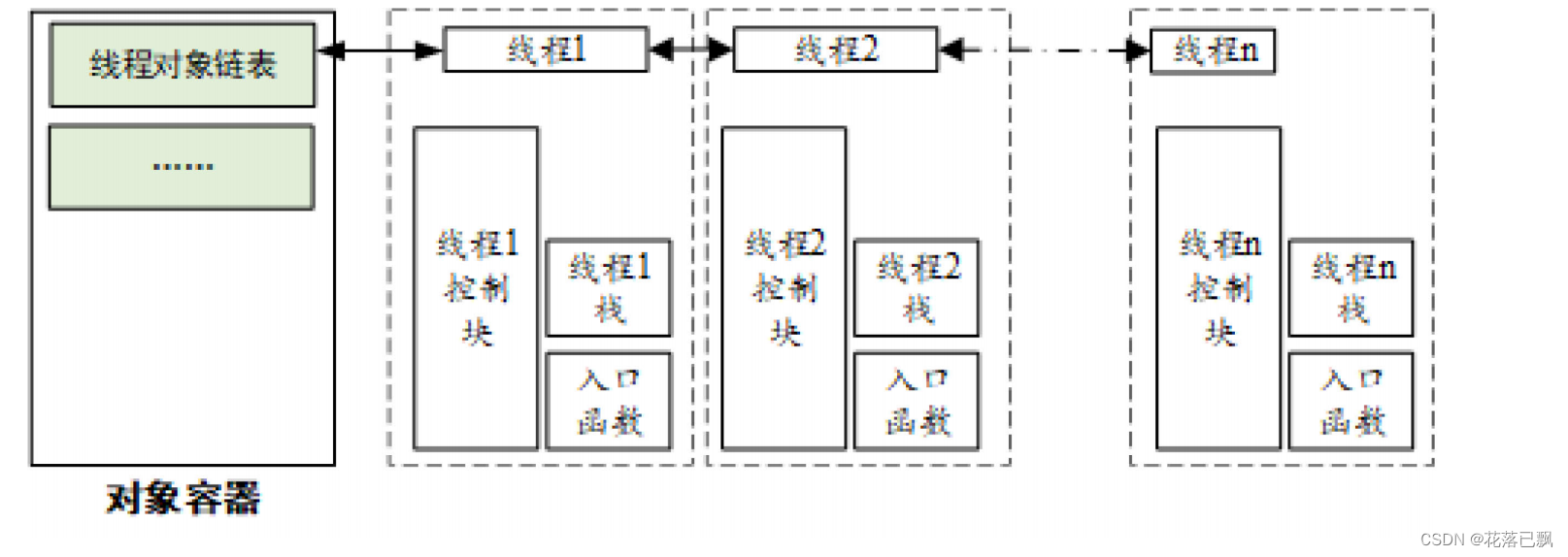
- 多线程与列表:在并发环境中安全地操作列表,了解GIL(全局解释器锁)的影响。
- 容器类和内置类型:研究
tuple,set,dict等其他容器类,了解它们的优缺点和适用场景。 - 算法与数据结构:深入学习排序算法,以及如何根据问题选择最佳的数据结构。
继续深化对Python列表的理解,并将其与其他数据结构结合使用,将有助于你编写出更加高效、优雅的代码。

关注gzh不灵兔,Python学习不迷路,关注后后台私信,可进wx交流群,进群暗号【人生苦短】~~~




![Ubuntu20.04 [Ros Noetic]版本——在catkin_make编译时出现报错的解决方案](https://img-blog.csdnimg.cn/direct/019cebf238d841ccab1fd32b1d89df70.png)