大家好,我是王有志,一个分享硬核 Java 技术的互金摸鱼侠。
我们书接上回,继续聊 MyBatis 的核心配置,我们今天分享剩下的 5 项核心配置。
不过正式开始前,我会先纠正上一篇文章 MyBatis 核心配置讲解(上)中出现的一个“错误”,并和大家说声抱歉。
勘误
首先和大家说声抱歉,在上一篇文章 MyBatis 核心配置讲解(上)中出现了一个“错误”,在演示自定义 ObjectFactory 时,我只是将数据库中的 gender 字段设置为 null,期望的查询结果中,应该只有 gender 被默认设置为“wyz”,可实际上在展示结果的图中,idNumer (数据库中为 id_number)也被默认设置为了“wyz”,同时查询结果中 idType(数据库中为 id_type)也没有展示出来。

这是因为,MyBatis 中并不会主动开启驼峰命名自动映射,即将数据库中的 id_number 字段映射为 Java 对象中的 idNumber。
要开启这个功能,需要我们在 MyBatis 的核心配置文件中,主动开启设置 mapUnderscoreToCamelCase,配置内容如下:
<configuration>
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
</configuration>
当我们将 MyBatis 与 Spring Boot 进行集成后,这个设置为:
mybatis:
configuration:
map-underscore-to-camel-case: true
对于上面的错误,再次向大家诚挚的说声抱歉!
objectWrapperFactory 元素
objectWrapperFactory 元素用于配置对象包装工厂(ObjectWrapperFactory),而 ObjectWrapperFactory 负责创建对象包装器(ObjectWrapper),ObjectWrapper 负责将 SQL 查询的结果集与 Java 对象的字段进行映射,它在 DTD 中的定义如下:
<!ELEMENT objectWrapperFactory EMPTY>
<!ATTLIST objectWrapperFactory
type CDATA #REQUIRED
>
objectWrapperFactory 元素只有一个子元素 objectWrapperFactory,用于配置 ObjectWrapperFactory 的实现,例如:
<configuration>
<objectWrapperFactory type="com.wyz.customize.factory.wrapper.CustomizeObjectWrapperFactory"/>
</configuration>
可以看到,这里我配置的是 CustomizeObjectWrapperFactory,即自定义的 ObjectWrapper 工厂,那么下面我们就实现这个 CustomizeObjectWrapperFactory。
首先我们要先实现对象包装器,在 MyBatis 中只需要继承 ObjectWrapper 接口即可,这里我们偷个懒,直接继承 ObjectWrapper 的实现类 BeanWrapper,代码如下:
package com.wyz.customize.wrapper.object;
import org.apache.ibatis.reflection.MetaObject;
import org.apache.ibatis.reflection.property.PropertyTokenizer;
import org.apache.ibatis.reflection.wrapper.BeanWrapper;
public class CustomizeObjectWrapper extends BeanWrapper {
public CustomizeObjectWrapper(MetaObject metaObject, Object object) {
super(metaObject, object);
}
@Override
public void set(PropertyTokenizer prop, Object value) {
super.set(prop, value);
}
@Override
public String findProperty(String name, boolean useCamelCaseMapping) {
return super.findProperty(name, useCamelCaseMapping);
}
@Override
public Class<?> getSetterType(String name) {
return super.getSetterType(name);
}
@Override
public boolean hasSetter(String name) {
return super.hasSetter(name);
}
@Override
public boolean hasGetter(String name) {
return super.hasGetter(name);
}
}
这里我只保留了几个关键方法:
BeanWrapper#set,用于将查询到的数据库结果集中字段的值赋值到 Java 对象的实例的指定属性上;BeanWrapper#findProperty,用于获取数据库表中字段在 Java 对象中的映射,例如:数据库表中的 user_id 映射到 Java 对象中的 userId;BeanWrapper#getSetterType,用于获取 Java 对象中字段的类型;BeanWrapper#hasSetter和BeanWrapper#hasGetter,用于判断 Java 对象中的属性是否有 getter 方法和 setter 方法。
接着我们来实现对象包装器工厂,同样的 MyBatis 中也提供了 ObjectWrapperFactory 接口,我这里同样选择继承 ObjectWrapperFactory 接口的实现类 DefaultObjectWrapperFactory,代码如下:
package com.wyz.customize.factory.wrapper;
import com.wyz.customize.wrapper.object.CustomizeObjectWrapper;
import org.apache.ibatis.reflection.MetaObject;
import org.apache.ibatis.reflection.wrapper.DefaultObjectWrapperFactory;
import org.apache.ibatis.reflection.wrapper.ObjectWrapper;
public class CustomizeObjectWrapperFactory extends DefaultObjectWrapperFactory {
public CustomizeObjectWrapperFactory() {
super();
}
@Override
public boolean hasWrapperFor(Object object) {
return true;
}
@Override
public ObjectWrapper getWrapperFor(MetaObject metaObject, Object object) {
return new CustomizeObjectWrapper(metaObject, object);
}
}
ObjectWrapperFactory 接口的核心方法是ObjectWrapperFactory#getWrapperFor,用于从对象包装器工厂中返回对象包装器,因此该方法中我没有直接调用父类的视线,而是返回我们自定义对象包装器 CustomizeObjectWrapper 的实例。
在上一篇MyBatis 核心配置讲解(上)中我们已经知道,ObjectFactory 是用于创建 SQL 语句的结果集映射到的 Java 对象的实例,那么 ObjectWrapper 就是用于为已经创建的 Java 对象实例中的每个字段进行赋值的。
同样的,MyBatis 中提供的 ObjectWrapper 也已经满足了绝大部分场景,因此通常来说,我们也不太需要自定义 ObjectWrapper。
plugins 元素
plugins 元素用于配置 MyBatis 的插件,MyBatis 的插件会在 SQL 语句执行过程中的某一时间点进行拦截调用,它在 DTD 中的定义如下:
<!ELEMENT plugins (plugin+)>
<!ELEMENT plugin (property*)>
<!ATTLIST plugin
interceptor CDATA #REQUIRED
>
plugins 元素只有一个子元素 plugin,用于配置插件的具体实现类,假设我们有一个自定义插件,用来转换查询响应结果中的性别字段,将数据库存储的性别码值转换为“男/女”,该插件的类名为 ConvertGenderPlugin,那么我们可以这样配置:
<configuration>
<plugins>
<plugin interceptor="com.wyz.customize.plugin.ConvertGenderPlugin">
<property name="M" value="男"/>
<property name="F" value="女"/>
<property name="0" value="男"/>
<property name="1" value="女"/>
</plugin>
</plugins>
</configuration>
MyBatis 为插件提供了非常丰富的拦截场景(接口)和拦截时机(方法):
| 场景(接口) | 时机(方法) |
|---|---|
| Executor | update, query, flushStatements, commit, rollback, getTransaction, close, isClosed |
| ParameterHandler | getParameterObject, setParameters |
| ResultSetHandler | handleResultSets, handleOutputParameters |
| StatementHandler | prepare, parameterize, batch, update, query |
自定义插件
接下来我们实现上述的转换性别字段的插件,先说一下整体思路,我这里选择在拦截Executor#query方法,在获取到查询结果后,通过反射获取结果中的性别字段(gender),并将码值转换为“男/女”的文字描述。当然了,这个功能使用其它的方式会更加合理,不过我这里只是为了演示如何自定义插件,就不要求合理性了。
自定义插件需要实现 Interceptor 接口,并通过@Intercepts注解声明被拦截的类型和被拦截的方法,我这里实现的 ConvertGenderPlugin 源码如下:
package com.wyz.customize.plugin;
import lombok.extern.slf4j.Slf4j;
import org.apache.ibatis.executor.Executor;
import org.apache.ibatis.mapping.MappedStatement;
import org.apache.ibatis.plugin.Interceptor;
import org.apache.ibatis.plugin.Intercepts;
import org.apache.ibatis.plugin.Invocation;
import org.apache.ibatis.plugin.Signature;
import org.apache.ibatis.session.ResultHandler;
import org.apache.ibatis.session.RowBounds;
import java.lang.reflect.Field;
import java.util.*;
@Slf4j
@Intercepts({
@Signature(
type = Executor.class,
method = "query",
args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class})
})
public class ConvertGenderPlugin implements Interceptor {
private Map<String, String> genderMap;
@Override
public Object intercept(Invocation invocation) throws Throwable {
log.info("[自定义插件]性别转换,M/F转换为男/女");
Object result = invocation.proceed();
String className = result.getClass().getName();
if (result instanceof Collection<?> results) {
for (Object tempResult : results) {
setGender(tempResult);
}
} else if (className.startsWith("java")) {
return result;
} else {
setGender(result);
}
return result;
}
private void setGender(Object result) throws IllegalAccessException {
Field[] fields = result.getClass().getDeclaredFields();
for (Field field : fields) {
if ("gender".equals(field.getName())) {
Class<?> fieldType = field.getType();
if (String.class.equals(fieldType)) {
field.setAccessible(true);
String value = (String) field.get(result);
field.set(result, this.genderMap.get(value));
}
}
}
}
@Override
public Object plugin(Object target) {
return Interceptor.super.plugin(target);
}
@Override
public void setProperties(Properties properties) {
if (this.genderMap == null) {
this.genderMap = new HashMap<>();
}
properties.forEach((key, value) -> genderMap.put((String) key, (String) value));
}
}
可以看到,在类的声明上,我使用了@Intercepts注解,并通过@Signature注解声明了插件的拦截场景和拦截时机,具体到 MyBatis 的源码中是 Executor 的如下方法:
public interface Executor {
<E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException;
}
结合上述源码,我们能够很清晰的了解到@Signature注解每个参数的意义:
- type,被拦截的接口;
- method,被拦截接口的方法名称;
- args,被拦截方法的参数(用于区分重载方法)。
最后,我们执行单元测试,可以看到查询出来的结果中,gender 字段已经被转换为了“男/女”。

Tips:如果你通过单元测试执行出来的结果没有成功的转换 gender 字段,你可能需要把之前我们在 MyBatis 核心配置中配置的 typeHandlers 元素注释掉。
environments 元素
environments 元素用于配置 MyBatis 应用的运行环境,它在 DTD 中的定义如下:
<!ELEMENT environments (environment+)>
environments 元素只有一个子元素 environment,在 MyBatis 应用中 environment 元素需要至少进行一次配置,但 MyBaits 应用也允许配置多个 environment。另外,environments 元素还有一个属性 defalut,用于指定 MyBatis 应用默认的运行环境,例如:
<environments default="MySQL_environment">
<environment id="MySQL_environment">
<!-- 省略配置-->
</environment>
</environments>
上述的配置中,我们指定了 MyBatis 应用默认的运行环境为“MySQL_environment”。
environment 元素
environment 元素用于配置 MyBaits 应用具体的运行环境,它在 DTD 中的定义如下:
<!ELEMENT environment (transactionManager,dataSource)>
<!ATTLIST environment
id CDATA #REQUIRED
>
environment 元素中有一个属性 id,用于指定该运行环境的 id,以及两个子元素:transactionManager 元素和 dataSource 元素。
transactionManager 元素
transactionManager 元素用于配置数据库事务,它在 DTD 中的定义如下:
<!ELEMENT transactionManager (property*)>
<!ATTLIST transactionManager
type CDATA #REQUIRED
>
MyBatis 的原生应用中提供了两种数据库事务类型:
- JDBC,直接使用 JDBC 的 commit 和 rollback,通过数据库来管理事务,由 MyBatis 中的 JdbcTransactionFactory 和 JdbcTransaction 配合实现;
- MANAGED,commit 和 rollback 时什么也不做,而是交由容器来管理事务,,由 MyBatis 中的 ManagedTransactionFactory 和 ManagedTransaction 配合实现。
通常情况下,在原生 MyBatis 应用中,我们会选择使用 JDBC,而在 MyBatis 与 Spring 或 Spring Boot 集成后,我们不需要配置事务管理,Spring 或 Spring Boot 会托管事务管理的功能。
transactionManager 元素在 MyBatis 核心配置文件中的配置如下:
<configuration>
<environments default="MySQL_environment">
<environment id="MySQL_environment">
<transactionManager type="JDBC"/>
<!-- 省略其它配置 -->
</environment>
</environments>
</configuration>
dataSource 元素
dataSource 元素用于配置数据源信息,它在 DTD 中的定义如下:
<!ELEMENT dataSource (property*)>
<!ATTLIST dataSource
type CDATA #REQUIRED
>
MyBatis 的原生应用中提供了 3 中数据源的配置:
- UNPOOLED,不使用数据库连接池的数据源,每次请求都会开启新的数据库连接,由 MyBatis 中的 UnpooledDataSourceFactory 和 UnpooledDataSource 配合实现;
- POOLED,使用数据库连接池的数据源,利用池化技术控制数据库连接,避免了频繁创建数据库连接带来的性能消耗,由 MyBatis 中的 PooledDataSourceFactory 和PooledDataSource 配合实现;
- JNDI,JNDI 数据源,由容器在外部配置数据源,通过 JNDI 上下文引用,由 MyBatis 中的 JndiDataSourceFactory 实现。
通常情况下,我们首选 POOLED 类型的数据源配置,利用数据库连接池来优化性能。dataSource 元素在 MyBatis 核心配置文件中的配置如下:
<configuration>
<properties resource="mysql-config.properties"/>
<environments default="MySQL_environment">
<environment id="MySQL_environment">
<dataSource type="POOLED">
<property name="driver" value="${mysql.driver}"/>
<property name="url" value="${mysql.url}"/>
<property name="username" value="${mysql.username}"/>
<property name="password" value="${mysql.password}"/>
</dataSource>
</environment>
</environments>
</configuration>
需要注意的是,数据库连接池并不是数据库提供的能力,而是程序在数据源的基础上提供的能力,因此你在阅读 MyBatis 的源码时会发现 POOLED 类型的数据源 PooledDataSource 内部使用了 UnpooledDataSource,PooledDataSource 的部分源码如下:
public class PooledDataSource implements DataSource {
private final UnpooledDataSource dataSource;
public PooledDataSource() {
dataSource = new UnpooledDataSource();
}
public PooledDataSource(String driver, String url, String username, String password) {
dataSource = new UnpooledDataSource(driver, url, username, password);
expectedConnectionTypeCode = assembleConnectionTypeCode(dataSource.getUrl(), dataSource.getUsername(), dataSource.getPassword());
}
}
因此,在 dataSource 元素的配置中,POOLED 和 UNPOOLED 类型的数据源(即 PooledDataSource 和 UnpooledDataSource)会共享部分配置,完整的配置列表如下:
| 配置 | 取值示例 | 说明 | 数据源类型 |
|---|---|---|---|
| driver | com.mysql.cj.jdbc.Driver | 数据库驱动 | POOLED 和 UNPOOLED |
| url | jdbc:mysql://localhost:3306/mybatis | 数据库地址 | POOLED 和 UNPOOLED |
| username | root | 数据库用户名 | POOLED 和 UNPOOLED |
| password | 123456 | 数据库密码 | POOLED 和 UNPOOLED |
| defaultTransactionIsolationLevel | 0 | 默认的事务隔离级别,java.sql.Connection 接口中定义的事务隔离级别 | POOLED 和 UNPOOLED |
| defaultNetworkTimeout | 10000 | 数据库连接的超时时间(单位毫秒) | POOLED 和 UNPOOLED |
| loginTimeout | 10000 | 数据库登录的超时时间(单位毫秒) | UNPOOLED |
| autoCommit | true | 是否自动提交,默认为 false | UNPOOLED |
| poolMaximumActiveConnections | 10 | 数据库连接池最大活跃连接数(默认 10 个) | POOLED |
| poolTimeToWait | 10000 | 获取数据库连接的最大时间,超时会重连(默认 20000 毫秒) | POOLED |
| poolMaximumIdleConnections | 10 | 数据库连接池最大空闲连接数 | POOLED |
| poolPingEnabled | true | 是否开启数据库连接检测(默认 false) | |
| poolPingQuery | select 1 from | 用于检测数据库连接是否正常的 SQL 语句 | POOLED |
| poolPingConnectionsNotUsedFor | 10000 | 检查连接是否可用的时间间隔(单位毫秒) | POOLED |
| poolMaximumLocalBadConnectionTolerance | 3 | 如果从连接池中获取到不可用的连接,允许进行重试的阈值(poolMaximumIdleConnections + poolMaximumLocalBadConnectionTolerance),超过阈值依旧无法获取到可用连接则抛出异常,poolMaximumLocalBadConnectionTolerance 默认值 3 | POOLED |
| poolMaximumCheckoutTime | 20000 | 从数据库连接池获取连接的最长等待时间,默认 20000,单位毫秒 | POOLED |
dataSource 元素的配置项是通过反射读取 DataSource 的实现类中以 set 开头的方法并截取该方法名中 set 之后的内容获取的。注意,PooledDataSource 中有些 set 方法无法通过 MyBatis 的核心配置文件进行配置,例如:logWriter。
因为 UnpooledDataSource 的相关配置较少,我们就以 UnpooledDataSource 的源码为例:
public class UnpooledDataSourceFactory implements DataSourceFactory {
private ClassLoader driverClassLoader;
private Properties driverProperties;
private String driver;
private String url;
private String username;
private String password;
private Boolean autoCommit;
private Integer defaultTransactionIsolationLevel;
private Integer defaultNetworkTimeout;
@Override
public void setLoginTimeout(int loginTimeout){
DriverManager.setLoginTimeout(loginTimeout);
}
@Override
public void setLogWriter(PrintWriter logWriter) {
DriverManager.setLogWriter(logWriter);
}
public void setDriverClassLoader(ClassLoader driverClassLoader) {
this.driverClassLoader = driverClassLoader;
}
public void setDriverProperties(Properties driverProperties) {
this.driverProperties = driverProperties;
}
public synchronized void setDriver(String driver) {
this.driver = driver;
}
public void setUrl(String url) {
this.url = url;
}
public void setUsername(String username) {
this.username = username;
}
public void setPassword(String password) {
this.password = password;
}
public void setAutoCommit(Boolean autoCommit) {
this.autoCommit = autoCommit;
}
public void setDefaultTransactionIsolationLevel(Integer defaultTransactionIsolationLevel) {
this.defaultTransactionIsolationLevel = defaultTransactionIsolationLevel;
}
public void setDefaultNetworkTimeout(Integer defaultNetworkTimeout) {
this.defaultNetworkTimeout = defaultNetworkTimeout;
}
}
其中最明显的是 UnpooledDataSourceFactory 中并没有 loginTimeout 和 logWriter 这两个字段,但是我们却可以在 dataSource 元素中配置。关于 MyBatis 中获取 dataSource 元素配置的具体实现,我会在后续的源码分析篇中和大家分享的。
自定义事务处理器
除了 MyBatis 提供的两种事务处理器外,我们还可以实现自定义的事务处理器。
实现自定义事务处理器,我们需要实现 Transaction 接口,这里我们只是为了展示如何实现自定义事务处理器,所以就偷个懒,选择继承 Transaction 的实现类 JdbcTransaction,并仅仅在获取连接和关闭连接时输出日志,其余方法直接调用 JdbcTransaction,代码如下:
package com.wyz.customize.transaction;
import lombok.extern.slf4j.Slf4j;
import org.apache.ibatis.session.TransactionIsolationLevel;
import org.apache.ibatis.transaction.jdbc.JdbcTransaction;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.SQLException;
@Slf4j
public class CustomizeTransaction extends JdbcTransaction {
public CustomizeTransaction(DataSource ds, TransactionIsolationLevel desiredLevel, boolean desiredAutoCommit) {
super(ds, desiredLevel, desiredAutoCommit);
}
public CustomizeTransaction(DataSource ds, TransactionIsolationLevel desiredLevel, boolean desiredAutoCommit, boolean skipSetAutoCommitOnClose) {
super(ds, desiredLevel, desiredAutoCommit, skipSetAutoCommitOnClose);
}
public CustomizeTransaction(Connection connection) {
super(connection);
}
@Override
public Connection getConnection() throws SQLException {
log.info("[自定义事务管理器]获取连接");
return super.getConnection();
}
@Override
public void close() throws SQLException {
log.info("[自定义事务管理器]关闭连接");
super.close();
}
}
接着我们为 CustomizeTransaction 定义工厂类,这里需要实现 TransactionFactory 接口,我们的实现依旧很简单,打印日志,并且创建事务管理器 CustomizeTransaction,代码如下:
package com.wyz.customize.transaction;
import lombok.extern.slf4j.Slf4j;
import org.apache.ibatis.session.TransactionIsolationLevel;
import org.apache.ibatis.transaction.Transaction;
import org.apache.ibatis.transaction.TransactionFactory;
import org.apache.ibatis.transaction.jdbc.JdbcTransactionFactory;
import org.checkerframework.checker.units.qual.C;
import javax.sql.DataSource;
import java.sql.Connection;
import java.util.Properties;
@Slf4j
public class CustomizeTransactionFactory implements TransactionFactory {
public CustomizeTransactionFactory() {
}
@Override
public Transaction newTransaction(Connection conn) {
log.info("[自定义事务处理器工厂]创建事务处理器");
return new CustomizeTransaction(conn);
}
@Override
public Transaction newTransaction(DataSource ds, TransactionIsolationLevel level, boolean autoCommit) {
log.info("[自定义事务处理器工厂]创建事务处理器");
return new CustomizeTransaction(ds, level, autoCommit);
}
}
最后,我们需要在 MyBatis 的核心配置文件中配置我们的事务处理器。实际上,MyBatis 核心配置文件中配置的是事务处理器工厂,并且我们需要借助 typeAliases 元素,配置如下:
<configuration>
<typeAliases>
<typeAlias alias="CUSTOM" type="com.wyz.customize.transaction.CustomizeTransactionFactory"/>
</typeAliases>
<environments default="MySQL_environment">
<environment id="MySQL_environment">
<transactionManager type="CUSTOM"/>
<dataSource type="POOLED">
<!-- 省略dataSource配置 -->
</dataSource>
</environment>
</environments>
</configuration>
通过测试,我们可以看到日志中正常输出了在自定义事务处理器工厂和自定义事务处理器中的日志:

自定义数据源
自定义数据源的方式与自定义事务处理器的整体流程一致,只不过是需要实现的接口不同。自定义数据源需要实现 Java 提供的 DataSource 接口,而自定义数据源工厂实现的是 MyBatis 提供的接口 DataSourceFactory。
首先,我们实现一个自定义数据源 CustomizeDataSource,同样偷个懒,我们直接继承 PooledDataSource,只修改下获取连接的方法,添加一行日志输出,代码如下:
package com.wyz.customize.source;
import lombok.extern.slf4j.Slf4j;
import org.apache.ibatis.datasource.pooled.PooledDataSource;
import java.sql.Connection;
import java.sql.SQLException;
@Slf4j
public class CustomizeDataSource extends PooledDataSource {
@Override
public Connection getConnection() throws SQLException {
log.info("[自定义数据源]获取链接");
return super.getConnection();
}
}
接着我们实现自定义数据源工厂 CustomizeDataSourceFactory,同样选择继承 MyBatis 已经实现的 PooledDataSourceFactory,依旧是添加一行日志输出,代码如下:
package com.wyz.customize.source;
import lombok.extern.slf4j.Slf4j;
import org.apache.ibatis.datasource.DataSourceFactory;
import org.apache.ibatis.datasource.pooled.PooledDataSource;
import org.apache.ibatis.datasource.pooled.PooledDataSourceFactory;
import javax.sql.DataSource;
import java.util.Properties;
@Slf4j
public class CustomizeDataSourceFactory extends PooledDataSourceFactory {
public CustomizeDataSourceFactory() {
log.info("[自定义数据源工厂]创建数据源");
this.dataSource = new CustomizeDataSource();
}
}
最后的配置方式与自定义事务处理器相同,也是需要通过 typeAliases 元素声明自定义数据源工厂的别名,配置如下:
<configuration>
<typeAliases>
<typeAlias alias="CUSTOM_POOLED" type="com.wyz.customize.source.CustomizeDataSourceFactory"/>
</typeAliases>
<environments default="MySQL_environment">
<environment id="MySQL_environment">
<transactionManager type="CUSTOM"/>
<dataSource type="CUSTOM_POOLED">
<! -- 省略数据源配置 -->
</dataSource>
</environment>
</environments>
</configuration>
通过测试,我们可以看到日志中正常输出了在自定义数据源工厂和自定义数据源中的日志:
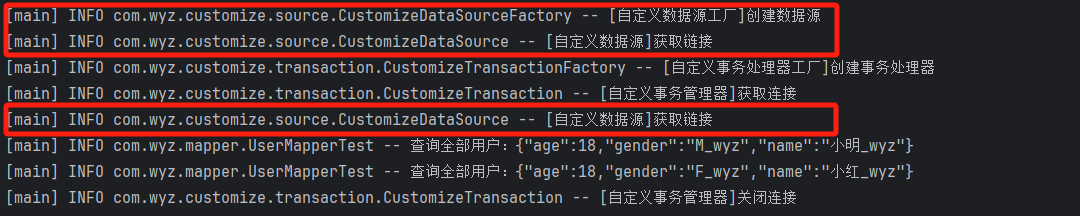
至于为什么自定义事务处理器(工厂)和自定义数据源(工厂)需要借助 typeAliases 元素,这与 MyBatis 的实现方式有关,后面我会在介绍 MyBatis 配置解析的源码中再和大家详细的分析。
配置多数据源
我们注意到 environments 元素是复数形式,并且 MyBatis 对 environments 元素的子元素 environment 的要求是至少进行一次配置,那也就是说我们可以在 MyBatis 的中配置多个运行环境。这里我们为测试程序配置两个不同数据库的运行环境,分别是连接 MySQL 的运行环境和连接 PostgreSQL 的运行环境。
正式配置多数据源之前,我们先要引入 PostgreSQL 的依赖,我们在 POM 文件中做如下配置:
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.7.3</version>
</dependency>
接着我们在 MyBatis 的核心配置文件中配置多数据源,如下:
<configuration>
<environments default="MySQL_environment">
<environment id="MySQL_environment">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis"/>
<property name="username" value="root"/>
<property name="password" value="123456"/>
</dataSource>
</environment>
<environment id="PostgreSQL_environment">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="org.postgresql.Driver"/>
<property name="url" value="jdbc:postgresql://localhost:5432/mybatis"/>
<property name="username" value="postgres"/>
<property name="password" value="123456"/>
</dataSource>
</environment>
</environments>
</configuration>
这里我们已经配置了 MySQL 的运行环境和 PostgreSQL 运行环境,接着我们来写映射器中的 SQL 语句,代码如下:
<mapper namespace="com.wyz.mapper.UserMapper">
<!--MySQL 运行环境的 SQL 语句 -->
<select id="selectAll" resultType="com.wyz.entity.UserDO">
select user_id, name, age, gender, id_type, id_number from user
</select>
<!-- PostgreSQL 运行环境的 SQL 语句 -->
<select id="selectFirstUser" resultType="com.wyz.entity.UserDO">
select user_id, name, age, gender, id_type, id_number from mybatis.user where user_id = 1
</select>
</mapper>
这里我在 PostgreSQL 中创建了于 MySQL 中同样的的 user 表,需要注意,在 PostgreSQL 的 SQL 语句中,我使用的是“mybatis.user”,这是因为 PostgreSQL 的数据库结构与 MySQL 的并不完全相同,PostgreSQL 是 3 层结构,而 MySQL 是两层结构:

最后我们来写单元测试:
package com.wyz.mapper;
import com.alibaba.fastjson2.JSON;
import lombok.extern.slf4j.Slf4j;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.junit.BeforeClass;
import org.junit.Test;
import java.io.IOException;
import java.io.Reader;
import java.sql.SQLOutput;
@Slf4j
public class MultipleDataSourcesTest {
private static SqlSessionFactory mysqlFactory;
private static SqlSessionFactory postgresqlFactory;
@BeforeClass
public static void init() throws IOException {
Reader mysqlReader = Resources.getResourceAsReader("mybatis-config.xml");
mysqlFactory = new SqlSessionFactoryBuilder().build(mysqlReader);
Reader postgresqlReader = Resources.getResourceAsReader("mybatis-config.xml");
postgresqlFactory = new SqlSessionFactoryBuilder().build(postgresqlReader, "PostgreSQL_environment");
}
@Test
public void testSelect() {
SqlSession mysqlSession = mysqlFactory.openSession();
UserMapper mysqlUserMapper = mysqlSession.getMapper(UserMapper.class);
mysqlUserMapper.selectAll().forEach(userDO -> log.info("MySQL 查询结果: {}", JSON.toJSONString(userDO)));
SqlSession postgresqlSession = postgresqlFactory.openSession();
UserMapper postgresqlUserMapper = mysqlSession.getMapper(UserMapper.class);
log.info("PostgreSQL 查询结果:{}", JSON.toJSONString(postgresqlUserMapper.selectFirstUser()));
mysqlSession.close();
postgresqlSession.close();
}
}
可以看到,我们分别为 MySQL 的运行环境和 PostgreSQL 的运行环境创建了 mysqlFactory 和 postgresqlFactory,这是因为,虽然 MyBatis 支持多数据源,但是每一个 SqlSessionFactory 的实例只能使用一个运行环境。
databaseIdProvider 元素
databaseIdProvider 用于指定不同 SQL 语句运行的数据库环境,它在 DTD 中的定义如下:
<!ELEMENT databaseIdProvider (property*)>
<!ATTLIST databaseIdProvider
type CDATA #REQUIRED
>
databaseIdProvider 提供了一个属性 type,通常我们使用 MyBatis 的内置配置“DB_VENDOR”即可,该配置是 VendorDatabaseIdProvider 在 MyBatis 中的别名,提供了获取数据源对应的数据库名称的方法。
同样的,我们可以对 dataBaseIdProvider 进行自定义,只需要实现 DatabaseIdProvider 接口即可,配置流程自定义事务处理器和自定义数据源相同,都需要借助 typeAliases 元素来完成,这里我们就不再展示了。
databaseIdProvider 的使用非常简单,只需要配置数据库名称与别名即可,这里以我们配置多数据源的 MyBatis 应用为例,为 MySQL 和 PostgreSQL 配置别名:
<configuration>
<databaseIdProvider type="DB_VENDOR">
<property name="MySQL" value="mysql"/>
<property name="PostgreSQL" value="postgresql"/>
</databaseIdProvider>
</configuration>
接着我们需要在映射器中,指定 SQL 语句对应的数据库,例如:
<mapper namespace="com.wyz.mapper.UserMapper">
<select id="selectAll" resultType="com.wyz.entity.UserDO" databaseId="mysql">
select user_id, name, age, gender, id_type, id_number from user
</select>
<select id="selectFirstUser" resultType="com.wyz.entity.UserDO" databaseId="postgresql">
select user_id, name, age, gender, id_type, id_number from mybatis.user where user_id = 1
</select>
</mapper>
现在我们使用在配置多数据源时的单元测试进行测试,可以看到测试正常通过。可能有些小伙伴会产生疑惑,这跟不使用 databaseIdProvider 有什么区别?
我们来修改下单元测试,让通过 MySQL 数据源获取到的连接执行UserMapper#selectFirstUser方法,而通过 PostgreSQL 数据源获取到的连接执行UserMapper#selectAll方法,代码如下:
@Test
public void testSelect() {
SqlSession mysqlSession = mysqlFactory.openSession();
UserMapper mysqlUserMapper = mysqlSession.getMapper(UserMapper.class);
log.info("MySQL 查询结果:{}", JSON.toJSONString(mysqlUserMapper.selectFirstUser()));
SqlSession postgresqlSession = postgresqlFactory.openSession();
UserMapper postgresqlUserMapper = postgresqlSession.getMapper(UserMapper.class);
postgresqlUserMapper.selectAll().forEach(userDO -> log.info("PostgreSQL 查询结果: {}", JSON.toJSONString(userDO)));
mysqlSession.close();
postgresqlSession.close();
}
通过测试,可以看到编译没问题,但是执行却报错了。

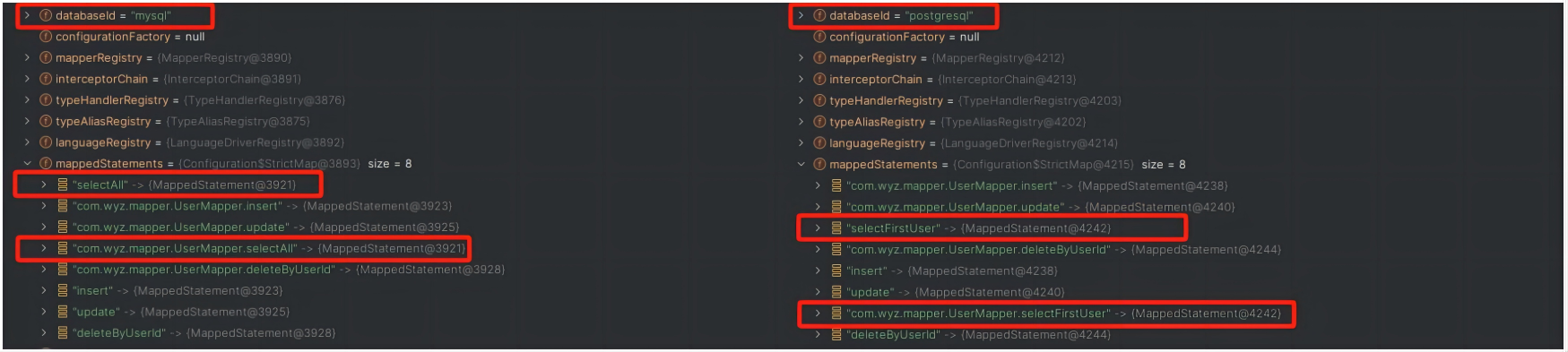
这是因为UserMapper#selectAll方法被绑定到了 MySQL 数据源上,而UserMapper#selectFirstUser方法被绑定到了 PostgreSQL 数据源上,不同数据源的 SqlSessionFactory 在读取映射器文件时,只会读取 dataBaseId 与自己匹配的,或者是没有绑定 dataBaseId 的 SQL 语句,这是在 MyBatis 读取配置构建 SqlSessionFactory 的 Configuration 时处理的,如下图不同数据源构建的 Configuration 所示:
mappers 元素
mappers 元素用于配置 MyBatis 应用的映射器(Mapper.xml),它在 DTD 中的定义如下:
<!ELEMENT mappers (mapper*,package*)>
mappers 元素没有任何属性,只有两个子元素:mapper 元素和 package 元素。
mapper 元素
mapper 元素提供了 3 个属性,它在 DTD 中的定义如下:
<!ELEMENT mapper EMPTY>
<!ATTLIST mapper
resource CDATA #IMPLIED
url CDATA #IMPLIED
class CDATA #IMPLIED
>
mapper 的 3 个属性代表了 3 种配置 MyBatis 映射器的方式。
resource 属性
首先是通过属性 resource 配置,这也是我们在 MyBatis 入门中使用的方式,这种方式我们直接使用映射器文件(Mapper.xml)的相对路径即可,例如:
<mappers>
<mapper resource="mapper/UserMapper.xml"/>
</mappers>
url 属性
使用 url 时,需要使用映射器文件(Mapper.xml)的完全限定资源定位符,例如:
<mappers>
<mapper url="file:///F://Project/MyBatis-Tradition/src/main/resources/mapper/UserMapper.xml"/>
</mappers>
class 属性
class 属性允许我们使用 MyBaits 映射器文件(Mapper.xml)对应的 Java 接口进行配置,例如:
<mappers>
<mapper class="com.wyz.mapper.UserMapper"/>
</mappers>
但是在使用 class 属性配置映射器时,有两点需要注意:
- 映射器文件(Mapper.xml)必须与对应的 Java 接口名称相同;
- 映射器文件(Mapper.xml)必须与对应的 Java 接口位于同一个目录下。
如下,就是一个使用 class 属性配置映射器文件(Mapper.xml)的合法方式:
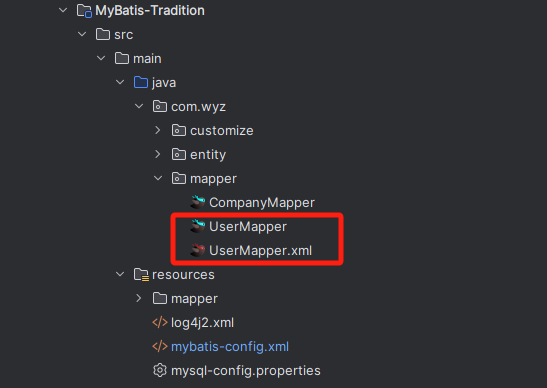
纵观 mapper 元素的属性,3 种配置方式都只能完成一个映射器的配置,如果项目中只有一两个映射器文件的话,我们还能应付的过来,但是如果有几十个上百个映射器文件的话,我们还要一个一个的配置吗?
package 元素
package 元素提供了一个属性,它在 DTD 中的定义如下:
<!ELEMENT package EMPTY>
<!ATTLIST package
name CDATA #REQUIRED
>
package 元素允许我们通过配置映射器文件对应的 Java 接口所在的包名进行统一配置,例如:
<mapper>
<package name="com.wyz.mapper"/>
</mapper>
上述的配置方式,会将 com.wyz.mapper 包下所有的映射器文件对应的 Java 接口加载的 MyBatis 应用程序中,但是与 mapper 元素的 class 属性一样,也需要遵循映射器文件的名称与 Java 接口的名称一致,且位于同一个文件目录下。
使用 package 虽然可以批量加载映射器,但是依旧存在问题,通常 Java 接口与映射器文件不会位于同一个目录下,而 package 元素会破坏这种分开存放的方式,那么有没有办法解决呢?
目前 MyBatis 的原生应用中没有办法解决 Java 接口与映射器分开存放且批量加载的问题,但是一旦将 MyBatis 与 Spring 或 Spring Boot 集成后,我们就可以使用@Mapper注解和@MapperScan注解来解决这个问题,不过这是后话了。
至此,我们就把 MyBatis 的核心配置文件中的所有元素的定义和用法都讲解完了,下一篇我们一起来学习 MyBatis 映射器中的元素。
好了,今天的内容就到这里了,如果本文对你有帮助的话,希望多多点赞支持,如果文章中出现任何错误,还请批评指正。最后欢迎大家关注分享硬核 Java 技术的金融摸鱼侠王有志,我们下次再见!