在人工智能领域,大模型(LLM)的微调是一个关键过程,它使模型能够适应特定的任务和数据集。微调是深度学习中用于改进预训练模型性能的重要技术。通过在特定任务的数据集上继续训练,模型的权重被更新以更好地适应该任务。微调的量取决于预训练语料库和任务特定语料库之间的相似性。随着技术的发展,微调方法也在不断迭代更新,从而提高了模型的性能和参数效率。本文将探讨大模型微调的常见方法,并提供一个实践指南。
PEFT:参数高效的微调工具
PEFT(Parameter-Efficient Fine-Tuning)是由hugging face开源的一个工具,它集成了多种微调方法,能够通过微调少量参数达到接近全量参数微调的效果。这使得在GPU资源受限的情况下也能进行大模型的微调。
微调方法概览
微调可以分为全微调和部分微调两种方法:
全微调(Full Fine-tuning)
全微调是一种彻底的微调方法,涉及对预训练模型的所有参数进行更新。这种方法的目的是在新任务上实现模型的最佳性能,即使这意味着模型的预训练知识可能会被大量修改。
特点:
- 参数更新:模型的所有层和参数都被更新和优化。
- 适用场景:当新任务与预训练任务有较大差异时,或者当任务需要模型具有高度灵活性和自适应能力时。
- 性能:通常可以获得更好的性能,因为模型可以充分适应新任务。
- 资源需求:需要较大的计算资源和时间,因为需要处理模型中的所有参数。
步骤:
- 数据准备:收集与新任务相关的数据集。
- 模型加载:加载预训练模型的参数。
- 训练:使用新任务的数据集对模型进行训练,调整所有参数以最小化损失函数。
- 评估与调整:在验证集上评估模型性能,并根据需要调整超参数或训练策略。
部分微调(Partial Fine-tuning 或 Repurposing)
部分微调是一种更为保守的微调方法,它只更新模型的顶层或少数几层,而保持底层参数不变。这种方法旨在保留预训练模型的通用知识,同时通过微调顶层来适应特定任务。
特点:
- 参数更新:只有模型的顶层或少数几层的参数被更新。
- 适用场景:适用于目标任务与预训练模型有一定相似性,或者任务数据集较小的情况。
- 性能:可能在某些情况下性能略低于全微调,但仍然能够适应新任务。
- 资源需求:相对于全微调,需要较少的计算资源和时间。
步骤:
- 数据准备:同全微调。
- 模型加载:加载预训练模型的参数,并确定哪些层将被微调。
- 训练:使用新任务的数据集对选定的顶层或少数层进行训练,而其他层的参数保持不变。
- 评估与调整:同全微调。
选择微调策略的考虑因素
选择全微调还是部分微调,应考虑以下因素:
- 任务差异:新任务与预训练任务的差异程度。
- 数据集大小:可用的标注数据量。
- 计算资源:可用的计算能力和时间。
- 性能要求:对任务性能的期望水平。
微调预训练模型的策略
微调预训练模型的策略是深度学习中提升模型性能的重要环节,尤其是在自然语言处理领域。以下是一些常见的微调策略,以及它们各自的适用场景和实施步骤:
微调所有层
策略描述:
- 目的:使预训练模型完全适应新任务。
- 适用场景:当新任务与预训练任务差异较大,需要模型在新任务上从头学习时。
实施步骤:
- 数据准备:收集新任务的数据集,并进行必要的清洗和预处理。
- 模型加载:加载预训练模型的参数。
- 训练:使用新数据集对模型进行端到端训练,更新模型所有层的参数。
- 超参数调整:选择合适的学习率、批量大小等,并在训练过程中可能需要调整。
- 正则化:使用如Dropout、权重衰减等技术防止过拟合。
- 评估与调优:在验证集上评估模型性能,并根据反馈调整模型结构或超参数。
微调顶层
策略描述:
- 目的:只更新模型的顶层,以适应新任务,而保留底层的通用知识。
- 适用场景:当新任务与预训练任务有相似性,且数据集相对较小时。
实施步骤:
- 数据准备:同上。
- 模型选择:选择适合的预训练模型,并确定顶层的范围。
- 冻结底层:冻结模型的底层参数,只对顶层进行微调。
- 训练顶层:使用新数据集训练顶层,可能需要较低的学习率。
- 评估顶层:在验证集上评估顶层的微调效果。
- 迭代优化:根据评估结果,可能需要调整顶层结构或超参数。
冻结底层
策略描述:
- 目的:保持模型底层参数不变,只对顶层进行微调,以快速适应新任务。
- 适用场景:当底层参数对新任务有较大帮助,而顶层需要调整以适应任务特性时。
实施步骤:
- 模型加载:加载预训练模型的参数,并标记底层参数为冻结状态。
- 顶层微调:只对顶层进行微调,调整其参数以适应新任务。
- 训练:在新数据集上训练模型,只有顶层参数会被更新。
- 评估:在验证集上评估模型性能,并监控底层参数的表现。
逐层微调
策略描述:
- 目的:从模型的底层开始,逐层进行微调,直到所有层都被微调。
- 适用场景:当需要模型在新任务上逐步适应,且希望保留底层的预训练信息时。
实施步骤:
- 冻结顶层:开始时冻结顶层以外的所有层。
- 逐层解冻:逐层解冻并微调模型的参数,从底层开始。
- 训练:每解冻一层,就在新数据集上训练该层。
- 评估与调整:在验证集上评估每一层的微调效果,并根据需要调整。
迁移学习
策略描述:
- 目的:利用预训练模型在大型数据集上学到的知识,通过微调顶层或冻结底层来适应新任务。
- 适用场景:当新任务的数据量有限,但希望利用模型在预训练阶段获得的知识时。
实施步骤:
- 预训练模型:使用在大规模数据集上预训练的模型。
- 迁移:将模型的知识迁移到新任务上,可能涉及顶层微调或底层冻结。
- 训练与评估:在新数据集上训练模型,并定期评估性能。
- 调参:根据评估结果调整超参数,如学习率和正则化强度。
微调策略的选择
在选择微调策略时,需要考虑以下因素:
- 任务特性:新任务与预训练任务的相似度。
- 数据集大小:可用的标注数据量。
- 资源限制:可用的计算资源,包括时间、内存和处理器。
- 性能要求:对模型性能的具体期望。
综合这些因素,可以选择最适合的微调策略,以达到在资源消耗和性能提升之间取得平衡的目的。
Prompt Tuning(P-Tuning)
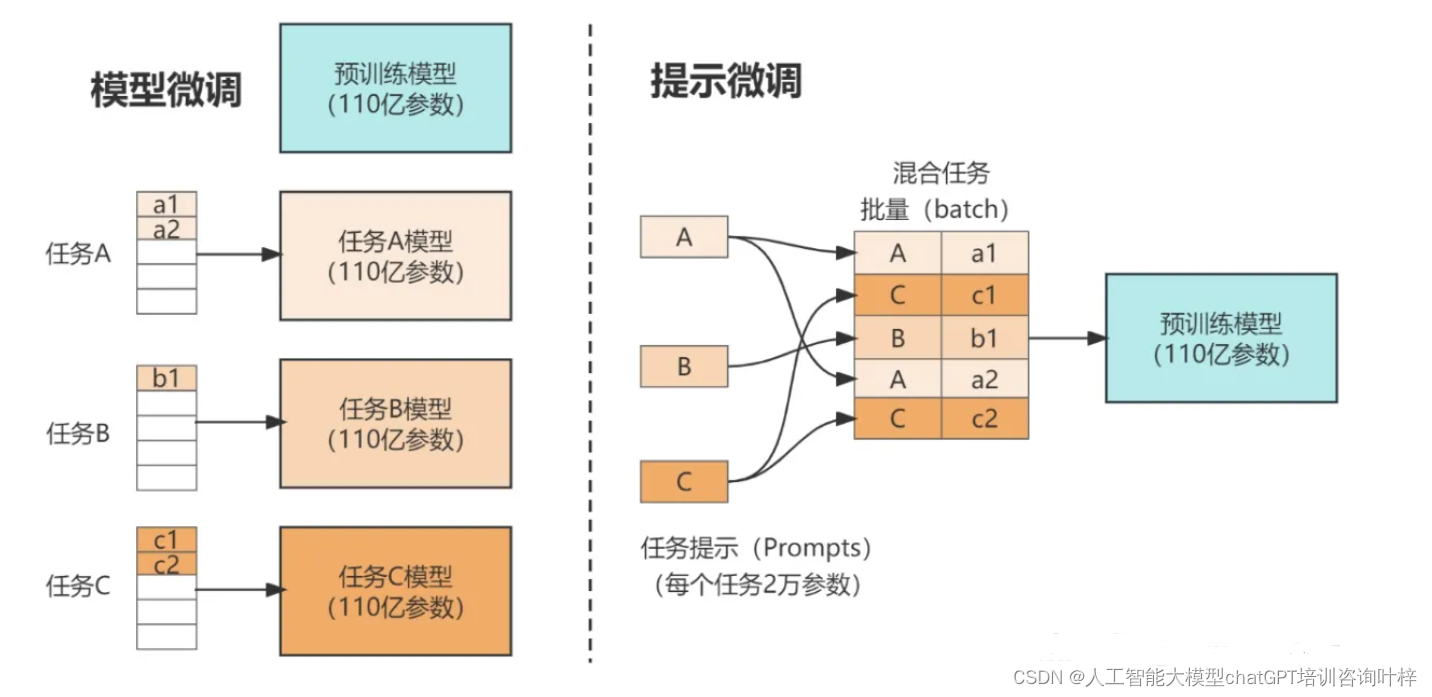
Prompt Tuning(P-Tuning)是一种参数高效的微调方法,特别适用于大型语言模型(LLM)。这种方法的核心思想是在模型的输入中引入一个可训练的提示(prompt),用以指导模型生成或分类任务所需的特定输出,而不需要对模型的其他参数进行大规模更新。以下是Prompt Tuning的详细说明:
基本原理
Prompt Tuning利用了预训练模型的生成能力,通过在输入数据前添加一个可训练的提示(prompt),来引导模型的输出。这个提示是一个连续的向量表示,可以在训练过程中调整,以便更好地适应特定的下游任务。
适用场景
- 生成任务:如文本生成、问答、摘要等。
- 分类任务:如情感分析、文本分类等。
- 参数效率:希望以较低的计算成本调整预训练模型以适应新任务。
实施步骤
- 预训练模型加载:选择一个适合的预训练模型作为基础。
- 任务数据准备:为下游任务准备数据集,包括输入文本和期望的输出。
- 设计提示模板:创建一个或多个提示模板,这些模板将作为输入的一部分。提示模板可以是简单的文本字符串,也可以是更复杂的结构,如特定格式的指令。
- 嵌入提示:将设计的提示转换为可训练的嵌入向量。
- 模型输入:将提示嵌入与输入数据拼接,形成完整的模型输入。
- 训练:使用下游任务的数据集对模型进行训练。在训练过程中,只有提示嵌入会被更新,而预训练模型的其他参数保持不变。
- 超参数调整:选择合适的学习率、批量大小等超参数,并在训练过程中根据模型表现进行调整。
- 模型评估:在验证集上评估模型性能,确保模型没有过拟合,并能够泛化到未见过的数据。
- 迭代优化:根据评估结果,可能需要返回并调整提示的设计、模型结构或超参数,进行多次迭代优化。
优势与挑战
优势:
- 参数效率:只需更新少量参数,减少了计算资源的需求。
- 灵活性:提示可以灵活设计,以适应各种不同的任务。
- 快速部署:相比于全参数微调,Prompt Tuning训练更快,可以快速适应新任务。
挑战:
- 设计难度:需要精心设计提示模板,以便有效地引导模型的输出。
- 任务通用性:在一些复杂的任务上,简单的提示可能难以达到与全参数微调相媲美的性能。
代码示例
以下是一个简化的Prompt Tuning的代码示例,展示了如何为一个预训练模型添加可训练的提示:
from transformers import AutoModel, AutoTokenizer
from peft import PromptTuningConfig, get_peft_model
# 加载预训练模型和分词器
model_name_or_path = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModel.from_pretrained(model_name_or_path)
# 设计Prompt Tuning配置
peft_config = PromptTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=10)
# 应用Prompt Tuning配置
model = get_peft_model(model, peft_config)
# 接下来,使用模型进行训练...Prefix Tuning
Prefix Tuning 是一种针对大型语言模型(LLM)的参数高效微调方法,由斯坦福大学研究人员在 2021 年提出。这种方法的核心在于在模型的输入序列前添加一个可学习的前缀(Prefix),该前缀是一组连续的虚拟标记(virtual tokens),它们在模型训练过程中被优化,以适应特定的下游任务。以下是 Prefix Tuning 的详细说明:
基本原理
Prefix Tuning 的思想是在模型的输入中引入一个可训练的前缀,这个前缀可以看作是一种隐式的提示(prompt),它能够指导模型生成或分类任务所需的特定输出。与 Prompt Tuning 不同,Prefix Tuning 中的前缀是模型内部的一部分,可以与模型的其他部分一起进行端到端的训练。
适用场景
- 文本生成任务:如文本摘要、问答系统、对话生成等。
- 文本分类任务:如情感分析、主题分类等。
- 参数效率:希望以较低的计算成本调整预训练模型以适应新任务。
实施步骤
- 预训练模型加载:选择一个适合的预训练模型作为基础。
- 任务数据准备:为下游任务准备数据集,包括输入文本和期望的输出。
- 设计前缀结构:确定前缀的长度,即需要多少个虚拟标记。
- 初始化前缀参数:随机初始化前缀的参数,或者使用其他预训练的嵌入。
- 模型输入:将设计的前缀与输入数据拼接,形成完整的模型输入。
- 训练:使用下游任务的数据集对模型进行训练。在训练过程中,前缀参数会被更新,而预训练模型的其他参数保持不变或根据需要进行微调。
- 超参数调整:选择合适的学习率、批量大小等超参数,并在训练过程中根据模型表现进行调整。
- 模型评估:在验证集上评估模型性能,确保模型没有过拟合,并能够泛化到未见过的数据。
- 迭代优化:根据评估结果,可能需要返回并调整前缀的设计、模型结构或超参数,进行多次迭代优化。
优势与挑战
优势:
- 参数效率:只更新模型输入部分的参数,减少了计算资源的需求。
- 端到端训练:前缀与模型其他部分一起进行端到端的训练,有助于更好地整合知识。
- 适应性:通过训练前缀,模型可以适应各种不同的任务。
挑战:
- 设计难度:需要确定前缀的长度和结构,这可能需要实验来确定。
- 任务通用性:在一些复杂的任务上,前缀可能难以捕捉足够的信息来指导模型。
代码示例
以下是一个简化的 Prefix Tuning 的代码示例,展示了如何为一个预训练模型添加可训练的前缀:
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PrefixTuningConfig, get_peft_model
# 加载预训练模型和分词器
model_name_or_path = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path)
# 设计Prefix Tuning配置
peft_config = PrefixTuningConfig(task_type="CAUSAL_LM", num_virtual_tokens=20)
# 应用Prefix Tuning配置
model = get_peft_model(model, peft_config)
# 接下来,使用模型进行训练...AdaLoRA
AdaLoRA(Adaptive Low-Rank Adaptation)是一种参数高效的微调方法,用于大型语言模型(LLM)。AdaLoRA 通过低秩矩阵分解技术,对模型中的权重矩阵进行智能调整,从而在微调过程中只更新那些对模型性能贡献较大的参数。以下是 AdaLoRA 的详细说明:
基本原理
AdaLoRA 的核心思想是利用矩阵分解技术,如奇异值分解(SVD),将模型中的权重矩阵分解为多个低秩矩阵的乘积。在微调过程中,AdaLoRA 只更新这些低秩矩阵中的部分参数,而不是整个权重矩阵,从而减少了模型的参数更新量和计算成本。
适用场景
- 大型模型微调:适用于需要大量计算资源的大型语言模型微调。
- 参数效率:希望以较低的计算成本调整预训练模型以适应新任务。
- 性能提升:在保持模型性能的同时,减少参数更新量。
实施步骤
- 预训练模型加载:选择一个适合的预训练模型作为基础。
- 矩阵分解:对模型中的权重矩阵进行低秩分解,如奇异值分解,得到多个低秩矩阵。
- 参数选择:根据新的重要性度量动态地调整每个低秩矩阵中参数的大小,选择性地更新那些对模型性能贡献较大的参数。
- 微调策略:设计微调策略,确定在微调过程中需要更新的参数。
- 训练:使用下游任务的数据集对模型进行训练,只更新选定的低秩矩阵中的参数。
- 超参数调整:选择合适的学习率、批量大小等超参数,并在训练过程中根据模型表现进行调整。
- 模型评估:在验证集上评估模型性能,确保模型没有过拟合,并能够泛化到未见过的数据。
- 迭代优化:根据评估结果,可能需要返回并调整微调策略、模型结构或超参数,进行多次迭代优化。
优势与挑战
优势:
- 计算效率:通过只更新部分参数,减少了模型微调的计算成本。
- 性能保持:智能地选择更新的参数,有助于保持甚至提升模型性能。
挑战:
- 参数选择:需要确定哪些参数对性能贡献较大,这可能需要复杂的分析和实验。
- 微调难度:相比于全参数微调,参数选择和更新策略的设计可能更加复杂。
代码示例
AdaLoRA 的实现通常需要对模型的权重矩阵进行特定的处理,这可能涉及到自定义的优化器或训练循环。以下是一个简化的 AdaLoRA 概念示例,展示了如何为一个预训练模型的权重矩阵应用低秩分解:
import torch
from transformers import AutoModel
# 加载预训练模型
model_name_or_path = "bert-base-uncased"
model = AutoModel.from_pretrained(model_name_or_path)
# 假设我们对模型的第一个线性层进行低秩分解
W = model.bert.embeddings.word_embeddings.weight
U, S, V = torch.linalg.svd(W, some='right')
# 选择性更新参数,例如,只更新前几个奇异值对应的矩阵
r = 8 # 选择更新的秩
W_updated = torch.mm(U[:, :r], S[:r, :r] * V[:r, :])
# 应用更新后的权重矩阵
model.bert.embeddings.word_embeddings.weight = W_updated
# 接下来,使用模型进行训练...微调步骤总结
大模型微调的主要步骤包括:
1. 准备数据集
- 收集数据:获取与特定任务相关的数据集。
- 数据清洗:清理数据,移除噪声和不一致性。
- 标注:确保数据集包含正确的标签,对于无监督任务则不需要。
- 分割:将数据集划分为训练集、验证集和测试集。
2. 选择预训练模型/基础模型
- 模型调研:了解不同预训练模型的特性和它们在类似任务上的表现。
- 资源适配:根据可用的计算资源选择合适大小的模型。
3. 设定微调策略
- 全微调:如果任务差异大,可能需要对模型的所有参数进行微调。
- 部分微调:当任务与预训练任务相似时,可以选择只微调模型的顶层或某些层。
4. 设置超参数
- 学习率:选择一个适当的初始学习率,并考虑学习率调度策略。
- 批量大小:确定每个训练步骤中样本的数量。
- 训练周期:设定训练的轮数(epochs)。
5. 初始化模型参数
- 加载权重:加载预训练模型的权重。
- 随机初始化:如果进行部分微调,可能需要对新加入的层或参数进行随机初始化。
6. 进行微调训练
- 前向传播:在训练集上运行模型,计算预测输出。
- 计算损失:使用损失函数评估预测输出和真实标签之间的差异。
- 反向传播:根据损失值调整模型参数。
7. 模型评估和调优
- 验证集评估:定期在验证集上评估模型性能。
- 性能监控:关注准确率、召回率、F1分数等指标。
- 超参数调整:根据评估结果调整学习率、批量大小或其他超参数。
通过这些步骤,可以有效地对大模型进行微调,以适应各种特定的任务需求。随着技术的不断进步,微调方法也在不断优化,为AI领域带来了更多的可能性。