WS-BAN模型(细粒度图像分类)
- 摘要
- Abstract
- 1. WS-BAN
- 1.1 文献摘要
- 1.2 背景
- 1.3 创新点
- 1.4 WS-BAN方法
- 1.4.1 弱监督注意学习
- 1.4.2 注意力丢弃
- 1.5 实验
- 1.5.1 数据集
- 1.5.2 实施细节
- 1.5.3 对比试验结果
- 2. Transformer代码学习
- 3. 细粒度图像分类代码复现
摘要
本周阅读了 Weakly Supervised Bilinear Attention Network for Fine-Grained Visual Classification这篇文献,作者提出了一种新颖的判别部分定位和局部特征提取方法来解决细粒度视觉分类问题, 通过双线性注意力池,判别部分特征矩阵来表示对象。,接下来是弱监督注意力学习,包括注意力正则化和注意力丢失,作者引导每个注意力图关注对象的一个部分并鼓励多重注意力。 最终该方法在细粒度视觉分类数据集中实现了最先进的性能。本文将详细介绍WS-BAN模型
Abstract
This week, I read the paper Weakly Supervised Bilinear Attention Network for Fine-Grained Visual Classification, in which the authors propose a novel discriminative part localization and local feature extraction method to solve the fine-grained visual classification problem by means of a bilinear Attention pooling, discriminative part feature matrix to represent the object. The next step is weakly supervised attentional learning, including attentional regularization and attentional loss, in which the authors direct each attention map to focus on one part of the object and encourage multiple attentions. Ultimately the method achieves state-of-the-art performance on fine-grained visual classification datasets. In this paper, the WS-BAN model is described in detail
1. WS-BAN
文献出处:Weakly Supervised Bilinear Attention Network for Fine-Grained Visual Classification
1.1 文献摘要
对于细粒度视觉分类,目标通常具有相似的几何结构,但呈现出不同的局部外观和不同的姿态。因此,区分局部特征的定位和提取对于准确的类别预测起着至关重要的作用。
本文提出了弱监督双线性注意网络(WS-BAN)。它联合生成一组注意力图(感兴趣区域图)来指示对象各部分的位置,并通过双线性注意池(BAP)来提取连续的部分特征。此外,为了对注意图的生成过程进行弱监督,作者提出了注意规则化和注意丢弃的概念。WS-BAN可以进行端到端的训练,并在多个细粒度分类数据集上取得了最先进的性能。
1.2 背景
尽管基于卷积神经网络(CNN)的基本分类已经取得了很大的成功,但细粒度图像分类仍然具有挑战性,主要原因:
- 类内方差高。属于同一类别的物体通常呈现出显著不同的姿势和视角;
- 类间差异较小。属于不同类别的物体可能非常相似,除了一些微小的差异,例如鸟头的颜色通常可以确定其类别;
- 昂贵的人类标注导致训练数据有限。标注细粒度类别通常需要专业知识和大量的标注时间。
要区分具有非常相似特征的细粒度类别,关键过程是关注对象部分的特征表示。根据该方法是否需要额外的部件位置标注,当前最先进的方法可以分为两组,分别为图像级标注、位置级标注。在训练过程中,前者只需要图像类别标签,而后者需要额外的位置信息,如边界框或关键点的位置。位置标注带来了更昂贵的人工标注成本,使其更难实现。
在细粒度分类任务中,基于图像级的分类方法首先充分利用图像类别预测目标部位的位置,然后提取相应的局部特征。然而,现有的基于图像级的细粒度分类方法通常存在两个问题:
- 它们通常预测少量(1到8个)目标部位的位置,如鸟头、喙和翅膀,这限制了分类的精度。由于这些部分一旦不可见或被遮挡,就会导致特征提取不正确,分类结果很可能是错误的;
- 许多仅由Softmax交叉熵损失训练的方法往往侧重于最具区分性的部分(如鸟头),而忽略了较不具区分性的部分(如鸟腹),从而导致目标定位和特征表示不准确。
1.3 创新点
我们期望第 i i i 个注意力图代表第 i i i 个对象的部分,如果没有约束,注意图往往是稀疏和随机的。在作者提出的方法中
- 通过引入 弱监督注意学习 来避免这个问题。对于属于同一类别的注意部分特征,作者提出了注意正则化,以确保每个部分特征都接近其部分中心
- 为了避免注意力图主要集中在最重要的对象部分而忽略其他较不具区分性的部分,作者提出了 注意力丢弃,在训练过程中随机丢弃一些注意图,以提供任何对象部分不可见的可能情况,并增强较不具区分性的部分的激活值
1.4 WS-BAN方法
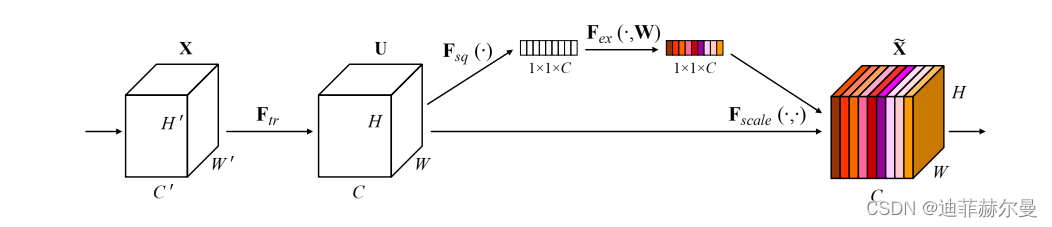
接下来我们详细描述了所提出的WS-BAN,它由BAP、弱监督注意力学习以及用于分类和对象定位的后处理组成,总体网络结构如下图所示。

通过卷积神经网络主干的一个或几个卷积运算生成特征图
F
∈
R
H
×
W
×
N
F∈R^{H×W×N}
F∈RH×W×N和注意图A∈RH×W×M,注意图F和A具有相同的图大小
H
×
W
H×W
H×W,然后注意图被分割成M个图 A={a1,a2,…,am}。我们期望
a
k
a_k
ak能反映第
k
k
k 个物体的区域。然后按元素将特征图F乘以每个关注图
a
k
a_k
ak,以生成M个部分特征图
F
k
F_k
Fk

标注注意网络,通过附加的局部特征提取函数g(·),如全局平均汇集(GAP)、全局最大汇集(GMP)或卷积运算,进一步提取区分性局部特征,以获得第k个部分特征表示
f
k
∈
R
1
×
N
f_k∈R^{1×N}
fk∈R1×N

最终部分特征矩阵
P
∈
R
M
×
N
P∈R^{M×N}
P∈RM×N由这些局部特征串联而成。设
Γ
(
A
,
F
)
Γ(A,F)
Γ(A,F)表示注意图A和特征图F之间的双线性注意集中。P可以由下列表示:

1.4.1 弱监督注意学习
我们期望第k个注意图代表第k个对象的部分。作者提出了注意规则化,注意图学习过程通过惩罚属于同一对象部分的特征的方差来弱监督,这意味着部分特征将接近图3所示的特征中心。正则化损失可以用下列公式中的LA来表示:

其中
c
k
c_k
ck 是每个类别的第k个特征中心。
c
k
c_k
ck 从零开始初始化,并通过移动平均进行更新。
![]()
其中
β
β
β 控制部件中心
c
k
∈
R
1
×
N
c_k∈R^{1×N}
ck∈R1×N 的更新率。提取的细粒度的特征矩阵
P
i
、
P
j
P_i、P_j
Pi、Pj 属于相同的细粒度类别。它们由M个细粒度特征向量组成。我们对属于同一部分的细粒度特征
f
k
f_k
fk进行弱监督,以接近零件特征中心
c
k
c_k
ck。

1.4.2 注意力丢弃
注意图往往在最具辨别力的部分被显著激活,这导致了过度匹配问题。在本文中,作者提出了注意力缺失来分散注意力。注意图在训练期间以固定概率(1−p)(p为保持概率)随机丢弃。当丢弃和忽略最具区分性的部分时,网络被迫增强较不具区分性的部分的激活值,从而增加分类的稳健性和目标定位的准确性。注意力丢失可以用下列等式来表示:
![]()
每个注意力图在训练过程中被随机丢弃,这提供了任何对象部分不可见的所有可能情况,防止了模型只关注最重要的对象部分。

基于区分部分特征矩阵P和注意力图A,可以解决细粒度的视觉分类和目标定位问题。注意图代表了物体的不同部分。为了预测整个物体的位置,首先沿着通道方向对注意力图进行平均,得到物体掩码
S
∈
R
H
×
W
S∈R^{H×W}
S∈RH×W

然后,我们应用同样的策略,基于定位(注意力)图预测对象边界框,接着通过固定阈值θ从背景中分割出前景。最后,我们找到了一个能够覆盖前景像素的边界框。同时为了进一步提高分类准确率。在计算出物体的位置之后。我们裁剪和调整对象区域作为第二阶段的输入,然后对其进行推理以改进预测,如下图所示。这两个阶段共享相同的参数,最终结果是它们的类别概率的平均值。

最终的损失函数由Softmax交叉熵损失和注意规则损失组成。
![]()
其中
L
1
L_1
L1和
L
2
L_2
L2分别是两个阶段的Softmax交叉熵损失,
L
A
L_A
LA是注意规则化损失,
λ
λ
λ 控制它们的比率。
1.5 实验
1.5.1 数据集
作者在三个FGVC数据集上将我们的方法与最先进的方法进行了比较,包括CUB-2002011、Stanford Cars、FGVC-Airways。每个数据集的具体信息如下表所示:

1.5.2 实施细节
在接下来的实验中,作者采用Inception-V3作为骨干网络,选择Mix6e作为特征图,注意图由特征图通过1×1卷积运算得到。注意正则化λ的权重被设置为1.0,注意丢弃因子p被设置为0.8,即随机丢弃20%的注意图。各部件中心β的更新率为0.05%。在训练过程中,原始图像首先被调整到512×512大小,然后随机裁剪到448×448大小。我们在一个P100GPU上使用随机梯度下降方法训练模型,动量为0.9,历元数为80,权重衰减为0.00001,小批量为16。初始学习率设置为0.001,每2个历元后指数衰减为0.9%。
1.5.3 对比试验结果
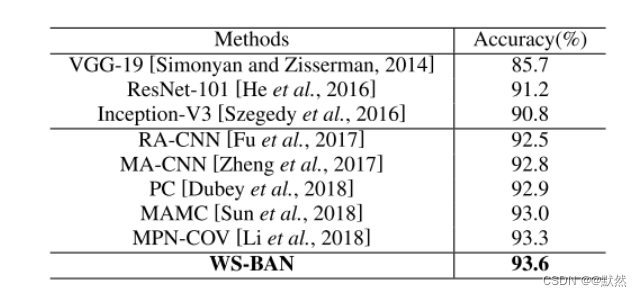
我们在上述细粒度分类数据集上将我们的方法与最先进的基线进行了比较。结果分别如下表所示。WS-BAN在所有这些细粒度数据集上都达到了最先进的性能。特别是,与主干Inception-V3相比,我们显著提高了准确率。

上表为在CUB-2002011测试数据集上与最新方法的比较。

上表为在FGVCAirgraph测试数据集上与最新方法的比较。
ACoL 在 CUB-200-2011 鸟类数据集上提供了基于图像的对象定位的性能。 为了与它们进行比较,作者在相同的数据集上使用相同的指标评估该方法,即计算其边界框与真实情况 IoU 小于 50% 的图像的定位误差(失败百分比)。实验结果如下表所示。在BAP和注意力学习的帮助下,作者的方法大幅度超越了最先进的方法,这表明该方法可以正确地关注对象的各个部分。
2. Transformer代码学习
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import math
import matplotlib.pyplot as plt
import numpy as np
import copy
d_model = 512
vocab = 1000
dropout = 0.1
max_len = 60
# 构建Embedding类来实现文本嵌入层
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
# d_model:词嵌入的维度
# vocab:词表的大小
super(Embeddings, self).__init__()
# 定义Embedding层
self.lut = nn.Embedding(vocab, d_model)
# 将参数传入类中
self.d_model = d_model
def forward(self, x):
# x: 代表输入给模型的文本通过词汇映射后的数字张量
return self.lut(x) * math.sqrt(self.d_model)
x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
emb = Embeddings(d_model, vocab)
emb_result = emb(x)
# print(emb_result, emb)
# print(emb_result.shape)
# 构建位置编码器的类
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
# d_model: 代表词嵌入维度
# dropout: 代表dropout层的置零比率
# max_len: 代表每个句子的最大长度
super(PositionalEncoding, self).__init__()
# 实例化dropout层
self.drouout = nn.Dropout(p=dropout)
# 初始化一个位置编码矩阵,大小是 max_len * d_model
pe = torch.zeros(max_len, d_model)
# 初始化一个绝对位置矩阵, 通过arange方法获得一个连续自然数向量,然后使用unsqueeze方法扩展向量维度,使得向量变成一个 max_len * 1 矩阵
position = torch.arange(0, max_len).unsqueeze(1)
# print(position)
# 绝对位置矩阵初始化之后,接下来就是考虑如何将这些位置信息加入到位置编码矩阵中
# 最简单的思路是先将 max_len*1 的绝对位置矩阵,变换成 max_len*d_model形状,然后覆盖
# 要做这种矩阵变换,就需要一个1*d_model形状的变换矩阵div_term,我们对这个变换矩阵的要求除了形状以为
# 还希望它能够将自然数的绝对位置编码缩放成最够小的数字,有助于在之后的梯度下降过程中的收敛
# 定义一个变换矩阵div_term, 跳跃式的初始化
div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))
# 将前面定义的变换矩阵进行奇数、偶数的分别赋值
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# 将二维张量扩充为三维张量
pe = pe.unsqueeze(0)
# 将位置编码矩阵注册成模型的buffer,这个buffer不是模型中的参数,不跟随优化器同步更新
# 注册成buffer后,我们就可以在模型保存后,重新加载的时候,将这个位置和编码器和模型参数一同加载进来
self.register_buffer('pe', pe)
def forward(self, x):
# x: 代表文本序列的词嵌入表示
# 首先要明确pe的编码太长了,将第二个维度,也就是max_len对应的那个维度缩小成x的句子长度同等的长度
x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)
return self.drouout(x)
x = emb_result
pe = PositionalEncoding(d_model, dropout, max_len)
pe_result = pe(x)
# print(pe_result)
# print(pe_result.shape)
# print(np.triu([[1,2,3],[4,5,6],[7,8,9]], k=-1))
# print(np.triu([[1,2,3],[4,5,6],[7,8,9]], k=0))
# print(np.triu([[1,2,3],[4,5,6],[7,8,9]], k=1))
# 什么是掩码张量?
"""
掩码张量的尺寸不定,里面一般只有1和0的元素,代表位置被遮掩或者不被遮掩,至于是0位置被遮掩还是1被遮掩可以自定义,因此它的作用就是
让另外一个张量中的数值被遮掩
"""
# 构建掩码张量的函数
def subsequent_mask(size):
# size: 代表掩码张量后两个维度,形成一个方阵
attn_shape = (1, size, size)
# 使用np.ones()先构建一个全为1的张量,然后利用np.triu()形成上三角矩阵
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
print(subsequent_mask)
# 使得三角矩阵进行反转
return torch.from_numpy(1 - subsequent_mask)
size = 5
sm = subsequent_mask(size)
# print(sm)
3. 细粒度图像分类代码复现
采用预训练Res2Net50_14w_8s网络模型,数据集采用CUB_200_2011鸟类数据集。采用SGD优化器,优化器学习率设置为0.09,dropout学习率设置为0.04
文件目录结构

datasets.py
import torch
import torchvision
from torch.utils.data import Dataset
import os
from PIL import Image
from torchvision.transforms import transforms
class CUB200(Dataset):
def __init__(self, root, image_size=64, train=True, transform=torchvision.transforms.ToTensor(), target_transform=None):
'''
从文件中读取图像,数据
'''
self.root = root # 数据集路径
self.image_size = image_size # 图像大小(正方形)
self.transform = transform # 图像的 transform
self.target_transform = target_transform # 标签的 transform
# 构造数据集参数的各文件路径
self.classes_file = os.path.join(root, 'classes.txt') # <class_id> <class_name>
self.image_class_labels_file = os.path.join(root, 'image_class_labels.txt') # <image_id> <class_id>
self.images_file = os.path.join(root, 'images.txt') # <image_id> <image_name>
self.train_test_split_file = os.path.join(root, 'train_test_split.txt') # <image_id> <is_training_image>
self.bounding_boxes_file = os.path.join(root, 'bounding_boxes.txt') # <image_id> <x> <y> <width> <height>
imgs_name_train, imgs_name_test, imgs_label_train, imgs_label_test, imgs_bbox_train, imgs_bbox_test = self._get_img_attributes()
if train: # 读取训练集
self.data = self._get_imgs(imgs_name_train, imgs_bbox_train)
self.label = imgs_label_train
else: # 读取测试集
self.data = self._get_imgs(imgs_name_test, imgs_bbox_test)
self.label = imgs_label_test
def _get_img_id(self):
''' 读取张图片的 id,并根据 id 划分为测试集和训练集 '''
imgs_id_train, imgs_id_test = [], []
file = open(self.train_test_split_file, "r")
for line in file:
img_id, is_train = line.split()
if is_train == "1":
imgs_id_train.append(img_id)
elif is_train == "0":
imgs_id_test.append(img_id)
file.close()
return imgs_id_train, imgs_id_test
def _get_img_class(self):
''' 读取每张图片的 class 类别 '''
imgs_class = []
file = open(self.image_class_labels_file, 'r')
for line in file:
_, img_class = line.split()
imgs_class.append(img_class)
file.close()
return imgs_class
def _get_bondingbox(self):
''' 获取图像边框 '''
bondingbox = []
file = open(self.bounding_boxes_file)
for line in file:
_, x, y, w, h = line.split()
x, y, w, h = float(x), float(y), float(w), float(h)
bondingbox.append((x, y, x+w, y+h))
# print(bondingbox)
file.close()
return bondingbox
def _get_img_attributes(self):
''' 根据图片 id 读取每张图片的属性,包括名字(路径)、类别和边框,并分别按照训练集和测试集划分 '''
imgs_name_train, imgs_name_test, imgs_label_train, imgs_label_test, imgs_bbox_train, imgs_bbox_test = [], [], [], [], [], []
imgs_id_train, imgs_id_test = self._get_img_id() # 获取训练集和测试集的 img_id
imgs_bbox = self._get_bondingbox() # 获取所有图像的 bondingbox
imgs_class = self._get_img_class() # 获取所有图像类别标签,按照 img_id 存储
file = open(self.images_file)
for line in file:
img_id, img_name = line.split()
if img_id in imgs_id_train:
img_id = int(img_id)
imgs_name_train.append(img_name)
imgs_label_train.append(imgs_class[img_id-1]) # 下标从 0 开始
imgs_bbox_train.append(imgs_bbox[img_id-1])
elif img_id in imgs_id_test:
img_id = int(img_id)
imgs_name_test.append(img_name)
imgs_label_test.append(imgs_class[img_id-1])
imgs_bbox_test.append(imgs_bbox[img_id-1])
file.close()
return imgs_name_train, imgs_name_test, imgs_label_train, imgs_label_test, imgs_bbox_train, imgs_bbox_test
def _get_imgs(self, imgs_name, imgs_bbox):
''' 遍历每一张图片的路径,读取图片信息 '''
data = []
for i in range(len(imgs_name)):
img_path = os.path.join(self.root, 'images', imgs_name[i])
img = self._convert_and_resize(img_path, imgs_bbox[i])
data.append(img)
return data
def _convert_and_resize(self, img_path, img_bbox):
''' 将不是 'RGB' 模式的图像变为 'RGB' 格式,更改图像大小 '''
img = Image.open(img_path).resize((self.image_size, self.image_size))
# img.show()
if img.mode == 'L':
img = img.convert('RGB')
if self.transform is not None:
img = self.transform(img)
# print(img)
return img
def __getitem__(self, index):
img, label = self.data[index], self.label[index]
label = int(label) - 1 # 类别从 0 开始
if self.target_transform is not None:
label = self.target_transform(label)
return img, label
def __len__(self):
return len(self.data)
# def one_hot_encode(label, num_classes):
# return torch.eye(num_classes)[label]
if __name__ == "__main__":
# num_classes = 200 # 数据集中的类别数
# target_transform = transforms.Compose([transforms.Lambda(lambda x: one_hot_encode(x, num_classes=200))])
train_set = CUB200("./CUB_200_2011", train=True, target_transform=None)
main.py
import torch
import torchvision
from torch import nn
from torch.optim import RMSprop
from torch.optim.lr_scheduler import StepLR, ReduceLROnPlateau
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from res2net import *
from res2net import res2net101_26w_4s, res2net50_48w_2s, res2net50_14w_8s
# from test_ResNet import ResNet18
from datasets import CUB200
data_transforms = {
'train':
transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
}
# 准备数据集
train_data = CUB200("./CUB_200_2011", train=True, transform=data_transforms['train']) # 共 5994 张图片
test_data = CUB200("./CUB_200_2011", train=False, transform=data_transforms['train']) # 共 5794 张图片
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64,shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64,shuffle=True)
# 创建网络模型
Test_module = res2net50_14w_8s(pretrained=True).to(device)
print(Test_module)
# 创建损失函数
loss_fn = nn.CrossEntropyLoss().to(device)
# optimizer = torch.optim.Adam(Test_module.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 200
# 优化器
learning_rate=0.09
# for i in range(epoch):
# if i<30:
# learning_rate = 0.2
# # optimizer = torch.optim.SGD(Test_module.parameters(), lr=learning_rate)
# elif i>30:
# learning_rate = 0.3
# # optimizer = torch.optim.SGD(Test_module.parameters(), lr=learning_rate)
# else:
# learning_rate = 0.1
# optimizer = RMSprop(Test_module.parameters(), lr=learning_rate, momentum=0.1)
optimizer = torch.optim.SGD(Test_module.parameters(), lr=learning_rate)
# 学习率调整器
# scheduler = StepLR(optimizer, step_size=20, gamma=0.1)
# 定义学习率调整器
# scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=5, verbose=True)
# 添加tensorboard
writer = SummaryWriter("./logs_train")
for i in range(epoch):
print("------第 {} 轮训练开始------".format(i+1))
for data in train_dataloader:
# 训练步骤开始
imgs, targets = data
# print(imgs, targets)
outputs = Test_module(imgs.to(device))
loss = loss_fn(outputs, targets.to(device))
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
print("训练次数:{}, loss:{}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_test_step)
# 测试步骤开始
total_test_loss = 0
# 整体的正确率
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
m = nn.Dropout(p=0.004)
datas = m(imgs.to(device))
outputs = Test_module(datas.to(device))
loss = loss_fn(outputs, targets.to(device))
total_test_loss = total_test_loss + loss.item()
# scheduler.step(total_test_loss)
accuracy = (outputs.argmax(1) == targets.to(device)).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step += 1
# # 保存训练的模型
# torch.save(Test_module, "Test_module_{}.pth".format(i))
# print("模型已保存")
writer.close()
res2net.py
import torch.nn as nn
import math
import torch.utils.model_zoo as model_zoo
import torch
import torch.nn.functional as F
__all__ = ['Res2Net', 'res2net50']
model_urls = {
'res2net50_26w_4s': 'https://shanghuagao.oss-cn-beijing.aliyuncs.com/res2net/res2net50_26w_4s-06e79181.pth',
'res2net50_48w_2s': 'https://shanghuagao.oss-cn-beijing.aliyuncs.com/res2net/res2net50_48w_2s-afed724a.pth',
'res2net50_14w_8s': 'https://shanghuagao.oss-cn-beijing.aliyuncs.com/res2net/res2net50_14w_8s-6527dddc.pth',
'res2net50_26w_6s': 'https://shanghuagao.oss-cn-beijing.aliyuncs.com/res2net/res2net50_26w_6s-19041792.pth',
'res2net50_26w_8s': 'https://shanghuagao.oss-cn-beijing.aliyuncs.com/res2net/res2net50_26w_8s-2c7c9f12.pth',
'res2net101_26w_4s': 'https://shanghuagao.oss-cn-beijing.aliyuncs.com/res2net/res2net101_26w_4s-02a759a1.pth',
}
class Bottle2neck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, baseWidth=26, scale=4, stype='normal'):
""" 构造函数
参数:
inplanes: 输入通道维度
planes: 输出通道维度
stride: 卷积步长。替代池化层。
downsample: 当stride = 1时为None
baseWidth: conv3x3的基本宽度
scale: 尺度数量。
type: 'normal': 正常设置。 'stage': 新阶段的第一个块。
"""
super(Bottle2neck, self).__init__()
# 计算卷积核的宽度
width = int(math.floor(planes * (baseWidth / 64.0)))
# 第一个1x1卷积层
self.conv1 = nn.Conv2d(inplanes, width * scale, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(width * scale)
# 计算重复次数
if scale == 1:
self.nums = 1
else:
self.nums = scale - 1
# 如果是新阶段的第一个块,则使用平均池化层进行下采样
if stype == 'stage':
self.pool = nn.AvgPool2d(kernel_size=3, stride=stride, padding=1)
# 定义重复的卷积层和BN层
convs = []
bns = []
for i in range(self.nums):
convs.append(nn.Conv2d(width, width, kernel_size=3, stride=stride, padding=1, bias=False))
bns.append(nn.BatchNorm2d(width))
# 创建了两个 nn.ModuleList 对象 self.convs 和 self.bns,用于存储多个卷积层和批量归一化层。
self.convs = nn.ModuleList(convs)
self.bns = nn.ModuleList(bns)
# 最后一个1x1卷积层
self.conv3 = nn.Conv2d(width * scale, planes * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
# 激活函数
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stype = stype
self.scale = scale
self.width = width
def forward(self, x):
residual = x
# 第一个1x1卷积层的计算
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
# 将输出按照宽度进行分割
spx = torch.split(out, self.width, 1)
for i in range(self.nums):
# 如果是第一个块或者是新阶段的第一个块,则直接取分割后的部分
if i == 0 or self.stype == 'stage':
sp = spx[i]
else:
# 否则,累加之前的部分
sp = sp + spx[i]
# 对部分进行卷积、BN和ReLU操作
sp = self.convs[i](sp)
sp = self.relu(self.bns[i](sp))
if i == 0:
out = sp
else:
# 将处理后的部分拼接起来
out = torch.cat((out, sp), 1)
# 如果尺度不为1且为正常设置,将最后一个部分拼接到一起
if self.scale != 1 and self.stype == 'normal':
out = torch.cat((out, spx[self.nums]), 1)
# 如果尺度不为1且为新阶段的第一个块,则对最后一个部分进行平均池化并拼接
elif self.scale != 1 and self.stype == 'stage':
out = torch.cat((out, self.pool(spx[self.nums])), 1)
# 最后一个1x1卷积层的计算
out = self.conv3(out)
out = self.bn3(out)
# 如果存在下采样,则对输入进行下采样
if self.downsample is not None:
residual = self.downsample(x)
# 残差连接并进行ReLU激活
out += residual
out = self.relu(out)
return out
class Res2Net(nn.Module):
def __init__(self, block, layers, baseWidth=26, scale=4, num_classes=1000):
# 初始化Res2Net模型
self.inplanes = 64 # 设置输入通道数为64
self.baseWidth = baseWidth
self.scale = scale
super(Res2Net, self).__init__() # 调用父类的构造函数
# 定义网络的第一层:7x7的卷积层,输入通道数为3,输出通道数为64,步长为2,填充为3
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
# Batch Normalization层,对每个channel的数据进行标准化
self.bn1 = nn.BatchNorm2d(64)
# 激活函数ReLU
self.relu = nn.ReLU(inplace=True)
# 最大池化层,窗口大小为3x3,步长为2,填充为1
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 定义4个Res2Net的阶段(stage)
self.layer1 = self._make_layer(block, 64, layers[0]) # 第一个阶段,输出通道数为64
self.layer2 = self._make_layer(block, 128, layers[1], stride=2) # 第二个阶段,输出通道数为128,步长为2
self.layer3 = self._make_layer(block, 256, layers[2], stride=2) # 第三个阶段,输出通道数为256,步长为2
self.layer4 = self._make_layer(block, 512, layers[3], stride=2) # 第四个阶段,输出通道数为512,步长为2
# 全局平均池化层,将每个通道的特征图变成一个数
self.avgpool = nn.AdaptiveAvgPool2d(1)
# 全连接层,将512维的特征向量映射到num_classes维的向量,用于分类
self.fc = nn.Linear(512 * block.expansion, num_classes)
# 初始化网络参数
for m in self.modules():
if isinstance(m, nn.Conv2d):
# 使用kaiming正态分布初始化卷积层参数
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
# 将Batch Normalization层的权重初始化为1,偏置初始化为0
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _make_layer(self, block, planes, blocks, stride=1):
# 构建Res2Net的一个阶段(stage),包含多个block
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
# 如果输入输出通道数不一致,或者步长不为1,需要添加下采样层
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
# 构建阶段的每个block
layers = []
layers.append(block(self.inplanes, planes, stride, downsample=downsample,
stype='stage', baseWidth=self.baseWidth, scale=self.scale))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes, baseWidth=self.baseWidth, scale=self.scale))
return nn.Sequential(*layers)
def forward(self, x):
# 定义前向传播过程
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def res2net50(pretrained=False, **kwargs):
"""Constructs a Res2Net-50 model.
Res2Net-50 refers to the Res2Net-50_26w_4s.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = Res2Net(Bottle2neck, [3, 4, 6, 3], baseWidth = 26, scale = 4, **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['res2net50_26w_4s']))
return model
def res2net50_26w_4s(pretrained=False, **kwargs):
"""Constructs a Res2Net-50_26w_4s model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = Res2Net(Bottle2neck, [3, 4, 6, 3], baseWidth = 26, scale = 4, **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['res2net50_26w_4s']))
return model
def res2net101_26w_4s(pretrained=False, **kwargs):
"""Constructs a Res2Net-50_26w_4s model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = Res2Net(Bottle2neck, [3, 4, 23, 3], baseWidth = 26, scale = 4, **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['res2net101_26w_4s']))
return model
def res2net50_26w_6s(pretrained=False, **kwargs):
"""Constructs a Res2Net-50_26w_4s model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = Res2Net(Bottle2neck, [3, 4, 6, 3], baseWidth = 26, scale = 6, **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['res2net50_26w_6s']))
return model
def res2net50_26w_8s(pretrained=False, **kwargs):
"""Constructs a Res2Net-50_26w_4s model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = Res2Net(Bottle2neck, [3, 4, 6, 3], baseWidth = 26, scale = 8, **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['res2net50_26w_8s']))
return model
def res2net50_48w_2s(pretrained=False, **kwargs):
"""Constructs a Res2Net-50_48w_2s model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = Res2Net(Bottle2neck, [3, 4, 6, 3], baseWidth = 48, scale = 2, **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['res2net50_48w_2s']))
return model
def res2net50_14w_8s(pretrained=False, **kwargs):
"""Constructs a Res2Net-50_14w_8s model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = Res2Net(Bottle2neck, [3, 4, 6, 3], baseWidth = 14, scale = 8, **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['res2net50_14w_8s']))
return model
if __name__ == '__main__':
images = torch.rand(1, 3, 224, 224).cuda(0)
model = res2net50_48w_2s(pretrained=False)
model = model.cuda(0)
print(model(images).size())
print(model)
实验结果
准确率稳定在75%